
개발자로 후회없는 삶 살기
[22.09.14] 딥러닝 PART.교과목(퍼셉트론, 과적합 해소) 본문
서론
교과목 1, 2주차 퍼셉트론에 관한 내용을 정리합니다.
목적 : 김인철 교수님의 강의는 무조건 남겨야 하는 값진 교육이다.
본론
1주차
- 퍼셉트론이란?

N차원의 입력을 받아서 0, 1의 출력을 내는 하나의 뉴런입니다. 깨끗한 선형 분류는 가능하나 비선형 분류는 못합니다. ∴ 딥러닝의 최종 학습은 퍼센트론의 파라미터를 갱신하는 퍼센트론 러닝입니다.
=> MLP(multi layer perceptron)
퍼셉트론을 여러 개 연결하여 선형을 비선형으로 꺾는 퍼셉트론이다. 안에서 복잡한 일을 해야 곡선의 일(비선형)을 할 수 있습니다.
=> 퍼셉트론의 한계
1. 경계에서 확 뛴다 > 안정적인 수렴이 어렵습니다.
2. 그래프 중간이 연속적이지 않아서 > 안정적인 수렴이 어렵습니다.
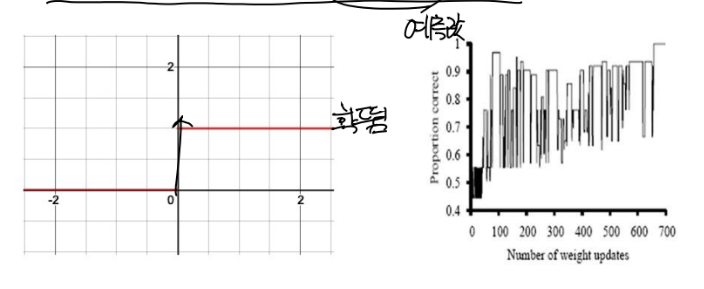
=> 퍼셉트론의 활성화 함수
1. 처음엔 하드스레시 홀드를 씁니다.(한계점)
2. 그래서 다양한 활성화 함수를 씁니다.
- 손실함수

1. L1 : mae에서 m을 제거한 것입니다.
2. L2 : mse에서 m을 제거한 것입니다. ∴ L1, 2를 안 쓰고 mse, mae를 씁니다.
- one-hot encoding

one-hot encoding을 하는 이유 : 희소한데 이 희소가 학습에 도움이 됩니다. 메모리가 많이 들어도 0과 1로 딱 구분이 되고 출력이 확실하게 정해져있습니다.
2주차
- 과적합이란?
1. 학습이란 : 훈련 데이터에 모델을 맞추는 과정/ 언더 피팅 : 모델이 너무 단순!
2. 오버 피팅 : 모델이 너무 복잡! -> 구부러지는 것을 보면 구부러지는 횟수가 파라미터 개수입니다. (차원에 따라 구부러집니다. ex) 300차원)
3. 오버 피팅 되면 안 되는 이유 : 모델을 일반화할 수 없습니다.
-> 쓰레기 데이터 :
1. 데이터 미싱이 많습니다. 컬럼에 비어있는 것을 다 지우면 별로 안 남습니다. 그거로 예측하면 예측 조작입니다.
2. 데이터 라벨링 수준이 별로입니다. 돈 주고 사람 시켜서 해놨는데 빈 곳도 많고 대충 라벨링하고 건수만 채우고 딴짓하는 게 현실입니다. + 라벨링이 쉬운 게 아닙니다.
ex) 판례 데이터라면 뭐가 옳은지? 의료 데이터라면 진짜 맞는 진단이지 전문가의 지식이 수반됩니다.
- 오버피팅 정의
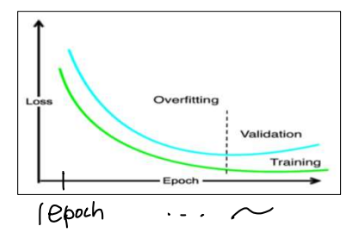
검증 과정에서 그림의 점선을 넘은 것입니다.
- 과적합 방지 기법
신경망 구조는 인간이 이미 정해서 fix 했습니다. 이미 구조는 끝났다고 하고 다른 시선으로 보겠습니다.
1. 드랍아웃
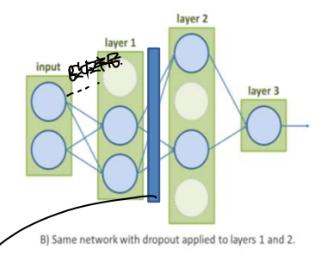
구조를 바꾸는 게 아니고 학습 도중에 몇 개의 링크를 일시적으로 없는 듯이 취급합니다. > 역전파 할 때 링크를 끊은 것 들을 빼고 나머지를 학습합니다. > 링크를 끊은 것들의 파라미터는 안 바뀝니다.
-> 그러면 링크를 끊은 것들은 학습을 어떻게 할까요? batch 1에서는 몇 개 랜덤으로 골라서 없는 듯이 취급하고 batch 2에서는 바꿔서 합니다.
+ 드롭아웃은 dense와 dense 사이에 두는 거라서 은닉 2, 3층에 세우면 3, 4층은 드랍아웃 안됩니다. 따라서 원하는 층 사이에 따로따로 넣어줘야 합니다.
2. 정규화(Regularization)

모델 정규화! > (엄청 중요한 개념입니다!!) 이름을 모델 정규화라고 보겠습니다. 신경망 모델 구조에 대한 정규화입니다. > 모델을 간소화하게 하는 것입니다. (모델이 복잡하면 위에서 오버피팅이라고 했습니다.), 이것 또한 사람이 준 모델 구조를 바꾸는 게 아니라 학습 시에 링크를 날린다고 하는데 -> 드롭아웃과의 차이를 보겠습니다.
결론을 보면 w가 0되면 w*x하면 0이 됩니다. > 링크는 그대로 있는데 w를 0에 가깝게 만들면 링크가 날라가버립니다. (0이 되면 링크가 날라가는 효과입니다.) > ★ 가급적이면 모든 w를 다 배우게 하지 말고 w를 0으로 만들어서 링크를 자르게 하자는 것입니다.
3. 정규화(Normalization)
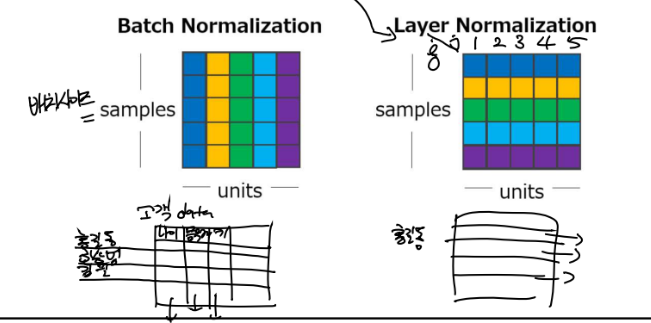
정의 : 데이터가 팍팍 변하는 것을 줄이기 위해서 안정적으로 데이터를 만들어주자! > (batch normalization의 역할이 이거였습니다.) 데이터가 확확 변하면 학습에 팍팍 뛴다고 했습니다. 그래서 그걸 막는 게 정규화이고 그러면 학습이 잘됩니다.
=> 종류
1. batch normalization
전체가 batch 사이즈입니다. 그 batch를 전체 사이즈로 봐서 평균과 분산을 구하고 정규화하는 것입니다. > 나이는 나이대로 정규화하고 키는 키대로 정규화합니다.
-> 나이는 나이끼리 다 비슷하게 되겠고 몸무게는 몸무게끼리 다 비슷할 것입니다. (gan 스터디에서 공부한 게 [4차원 공간을 창처럼 뚫는 것 각 샘플의 픽셀이 각 행의 측정치입니다.] 완벽히 맞는 말입니다! 링크를 참고하시길 바랍니다.)
-> 거기다가 학습 가능한 scale and shift까지 줘서 확확 바뀌는 것을 막습니다.
+ 보통 정규화는 normalize에서 끝납니다. 근데 batch normalization만 감마와 베타로 0~1사이 정규화 값을 다시 입력으로 넣기 전에 (0~1이 아닌) 좋은 값으로 바꿔서 입력으로 넣어줍니다. 그 좋은 값은 학습으로 감마와 베타를 구해서 결정합니다.
-> 이게 어떻게 적용되냐면 batch 사이즈만큼 들어오면 batch normalization해서 다음 노드로 보내고 보내고 보내고 갱신하고 또 다음 batch 사이즈만큼 들어오면 batch normalization해서 동일하게 동작하도록 하는 것입니다.
2. layer normalization
한 행으로 정규화합니다. 고객 데이터라면 홍길동의 키, 나이, 몸무게로 정규화합니다. > 홍길동의 데이터는 다 비슷할 것입니다. 한상범의 데이터는 다 비슷할 것입니다.
하는 이유 : 시력은 0.1, 키는 170 이럴 것입니다. > 시력은 1차이 나는데 몸무게 차이는 5라면 숫자 상에서는 몸무게 차이가 더 큰데 실제 5kg은 큰 차이가 아닙니다. > 근데 시력은 1이 엄청난 차이입니다. 단위에 따라서 이게 1이 사실은 더 큰 것입니다. > 이걸 다 그냥 동일하게 처버려서 시력이 더 가깝다고(유클리디안 거리) 보는 것입니다. 이러면 절대 안 되는 것입니다! > 그래서 키는 키끼리 몸무게는 몸무게끼리 하지 말고 한 고객(홍길동)에서 키, 시력, 몸무게 다 0~1사이 값으로 축소하는 것입니다.
둘의 차이 : batch와 layer의 차이는 누구의 평균이냐 누구의 분산이냐의 차이입니다.
- 학습률
너무 작으면 느리고, 너무 크면 폭발합니다. > 그래서 학습을 하면서 점점 학습률을 줄이는 방법이 있습니다. = 처음엔 멀다 싶으니 크게 하다가 점점 줄이는 미세 조정합니다. (decay)
-> 로컬 미니마 문제
시작점이 랜덤이라서 어디에 시작하느냐에 따라 운 나쁘면 local minima에 빠집니다. (그래서 처음 학습엔 로컬에 빠졌는데 다음 학습에선 글로벌에 잘 갈 수도 있습니다!) -> 제일 좋은 방법은 로컬에 빠졌을 때 거기에서는 제일 에러가 낮은 상황일 텐데 그래도 참고 더 밀어봅니다. 그러면 나중에 global minima에 갈 수도 있습니다! = momentum(관성)
-> momentum(관성)
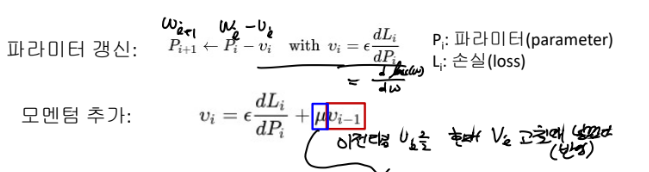
sgd나 gd로 기울기 하강을 할 건데 관성을 갱신 범위인 vi에 줍니다. 뮤는 '기울기보다 이전 타임 vi를 얼마나 크게 볼 것인가'로 아까 R과 같은 생각입니다.
-> adaptive learning rate
위에서 한 경사하강을 할 때 보폭(스탭사이즈, lr)이나 관성(스탭 방향) 사이즈 등을 스스로가 알아서 다 고치겠다는 것입니다.
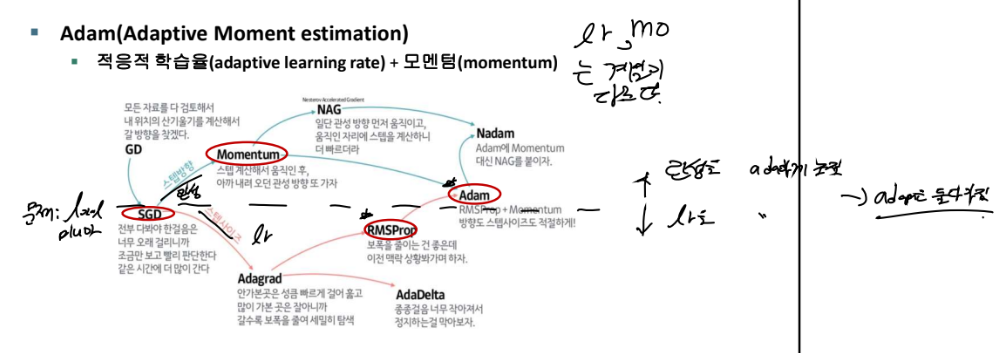
1) 파란색 화살표는 관성을 중요하게 생각한 계열
2) 빨간색은 보폭을 중요하게 생각하는 lr 계열
+ RMSProp과 Adam이 제일 많이 쓰입니다! 그만큼 두 관점을 중요하게 봐서 발전시킨 결과물이라는 것입니다.
'[AI] > [교과목 | 학습기록]' 카테고리의 다른 글
| [22.10.11] 딥러닝 PART.교과목 CNN, 고급 신경망 활용 (0) | 2022.12.27 |
|---|---|
| [22.09.24] 딥러닝 PART.교과목(콜백, 모델 저장, tfds) (0) | 2022.12.27 |
| 딥러닝 PART.교과목 오토인코더(Ae) (0) | 2022.11.16 |
| 딥러닝 PART.교과목 단어 임베딩 (0) | 2022.11.08 |
| 딥러닝 PART.교과목 RNN (0) | 2022.11.08 |



