
개발자로 후회없는 삶 살기
딥러닝 PART.교과목 RNN 본문
서론
교과목 9주차 순환 신경망 활용에 관한 내용을 정리합니다.
본론
- rnn이란?
앞에서 배운 건 모두 다 feed forward입니다. > 입력에 따라서만 출력이 결정되지 다른 요인으로는 출력에 영향을 받지 않고 내부에 시간이 흘러도 기억하고 있는 정보가 있어서 뭐 새로 들어온 데이터랑 결합해서 출력하는 그런 일이 없습니다.

+ dnn은 입력이 서로 독립적이라고 가정합니다. 이 가정은 시퀀스 데이터에는 해당되지 않습니다. 예를 들어 문장의 단어, 작곡의 음표, 시간에 따른 주가는 요소들이 이전 요소에 종속성을 나타내는 시퀀스의 예입니다.
rnn은 순차 데이터를 처리합니다 : 입력 데이터가 순서가 있는 시퀀스 데이터입니다. 혹은 출력이 순서가 있는 시퀀스입니다 혹은 양쪽 다 순서가 있는 시퀀스 데이터입니다. > 시퀀스의 패턴을 학습하고 출력을 하는 망입니다.
+ 신경망 내부에 (hidden) 상태를 저장하고 있습니다. > 입력이 매 순간 0, 1, 2 타임으로 들어오고 입력에 따라 은닉 + 새로 들어온 거를 결합해서 은닉을 업데이트하고 출력도 나갑니다. > 은닉은 다음 입력과 결합해서 갱신됩니다. ★ 실제로는 하나의 셀만 존재하고 시간마다 처리하는 것을 펼쳐보면 이렇게 보이는 것입니다.
※ rnn의 각 셀은 시퀀스의 연속된 요소에 동일한 연산을 수행합니다. = 가중치 행렬 U, V, W(=입력, h, y에 붙는 가중치)가 각 타임 스텝간에 공유됩니다. 모든 타임 step에서 가중치를 공유할 수 있으면 RNN이 학습해야 하는 매개변수 수가 크게 줄어듭니다.
- 바닐라 RNN
매 순간마다 t타임마다 입력이 들어오고 hidden state t-1인 한 스탭 전의 hidden state와 결합해서 다음 타임의 ht가 먼저 바뀌고 그 바뀐 hidden을 봐서 yt가 나옵니다. > ★ ht가 먼저 나오고 그걸 봐서 yt가 나옵니다. > 입력이 (x) + 원래 저장하고 있었던 (h)를 봐서 다음 정보를 갱신하고 그것을 y를 뽑는데 새로 갱신된 은닉값을 w를 곱해서 (선형 결합) 내보냅니다. (모든 가중치의 학습이 필요합니다.)
※ 시간 t에서의 출력 벡터 yt는 가중치 벡터 V와 softmax 활성화 함수를 거친 은닉 상태 ht의 곱으로 그 결과 클래스의 확률로 나옵니다.
- 역전파
순전파 : loss를 구합니다. > 손실이 발생하고 그 손실을 줄이기 위해서 파라미터를 갱신해야합니다.
> 순환 신경망에서의 역전파는 매 순간마다 입력이 들어갑니다. 은닉값이 바뀌고 출력이 결정되는데 매 순간 출력을 낸다고 보면(매니투 매니처럼) > 정답이 매번 있을 텐데 > 그 차가 0타임에서의 손실, 1 타임일 때의 손실 그렇게 다 손실이 발생합니다. > 그 손실을 다 합치면 전체 손실이 나옵니다. 그 전체 손실을 줄일 수 있도록 파라미터를 고칩니다.
=> 역전파 :
l2-y2의 오차로 고치면 이놈의 파라미터가 바뀝니다. 근데 여기서는 항상 은닉 상태를 생각해야합니다. = 은닉은 다음 단계의 출력에 영향을 주고 시간적으로 앞쪽에 있는 놈은 자기 자신의 손실도 책임을 줘야 하지만 다음 단계에서의 오차에도 발 뺄 수 없고 책임이 있습니다. feed forward는 순전파에서 loss가 나오면 역으로 뒤로 뒤로 해서 파라미터를 갱신하는데 얘는 경로가 2개다 내 직접 손실과 앞에서 발생한 손실입니다.
- BI-LSTM
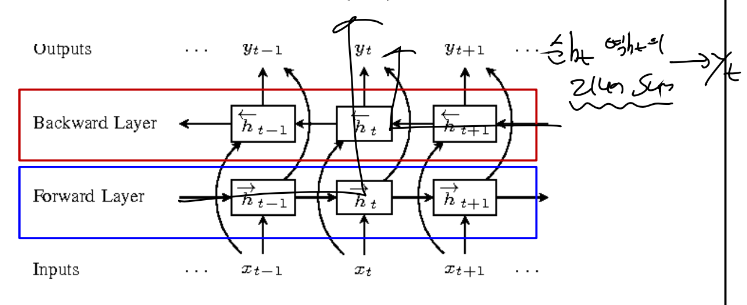
-> 이미 수집되어있는, 기록되어있는 문장이라면, 이미 확보된 뭔가를 가지고 일을 하려고 하면 가능합니다. > 문서 중간에 영어를 불어로 바꾸려면 그 중간 단어의 앞과 뒤를 봐서 번역이 가능합니다. = 과거만 보는 것이 아닌 미래를 잠깐 훔쳐보고 결정합니다.
+ ex)
t 타임에 정보가 과거에는 ht로만 yt를 만들었는데 이제는 ht가 두개로 역방향, 순방향의 은닉에서 yt가 나와서 두 가중치의 linear summation을 해서 yt를 구합니다. = 앞은 어떤 문맥인지 뒤의 문맥은 어떤지의 압축 정보를 다 참고해서 출력을 결정합니다. > 단방향보다 성능이 훨씬 좋습니다.
※ 많은 경우 bi-lstm을 가장 많이 씁니다. (하드가 별로면 gru 쓰고 웬만하면 이거 쓴다고 합니다.)
- 코드 분석
class SentimentAnalysisModel(tf.keras.Model):
def __init__(self, vocab_size, max_seqlen, **kwargs):
super(SentimentAnalysisModel, self).__init__(**kwargs)
self.embedding = tf.keras.layers.Embedding(vocab_size, max_seqlen) # 어휘 크기 vocab_size 만큼의 벡터로 임베딩
self.bilstm = tf.keras.layers.Bidirectional(
tf.keras.layers.LSTM(max_seqlen) # dense와 마찬가지로 입력층 이후에 있는 사이즈는 출력 사이즈로 64 벡터로 변환
)
self.dense = tf.keras.layers.Dense(64, activation="relu") # 각 타입스탭에서의 출력이 Dense로 계속 들어가나봐
self.out = tf.keras.layers.Dense(1, activation="sigmoid") # 그리고 시그모이드로 분류
def call(self, x):
x = self.embedding(x)
x = self.bilstm(x)
x = self.dense(x)
x = self.out(x)
return x
'[AI] > [교과목 | 학습기록]' 카테고리의 다른 글
| 딥러닝 PART.교과목 오토인코더(Ae) (0) | 2022.11.16 |
|---|---|
| 딥러닝 PART.교과목 단어 임베딩 (0) | 2022.11.08 |
| 딥러닝 PART.교과목 transformer, BERT (0) | 2022.10.25 |
| 딥러닝 PART.교과목 VQA, CNN text에 활용 (0) | 2022.10.23 |
| 딥러닝 PART.교과목 yolo, segmentation (0) | 2022.10.11 |



