
개발자로 후회없는 삶 살기
딥러닝 PART.교과목 transformer, BERT 본문
서론
교과목 9주차 트랜스포머 내용을 정리합니다.
본론
- 정적 임베딩의 문제점
이건 한 번 학습이 끝나서 벡터화되면 새로운 문장이 들어와도 동일 단어는 동일한 벡터가 됩니다. 내가 과학 문서로 W2V를 학습시켰는데 법률 문서의 같은 단어를 가져와도 W2V를 적용하면 과학 문서에서 임베딩한 결과와 같은 결과가 나옵니다.

-> 우리가 기대하는 것은 테스트 데이터(새로운 데이터)를 임베딩하라고 넣었을 때 ★주변의 단어에 따라서 같은 단어를 기존의 벡터와는 다른 벡터로 바꾸는 것을(임베딩) 기대합니다★ = 동적 임베딩
-> 단순 단어의 예측이 아니고 언어 구조와 문법을 다 익힌 것으로 연상 가능합니다.
- 동적 임베딩
중의어, 동음이의어 : 다 다른 은행인데 옆의 의미를 보지 않고 무조건 (ex 101010)의 형태로 임베딩하면 단어의 의미를 모르는 것입니다. 따라서 동적 임베딩이 필요합니다. = 임베딩 적용 시점의 문맥에 따라서 적용시점의 타겟 단어를 같은 단어라고 해도 다른 코드로(ex 111111)로 변형될 수 있습니다.

= 앞의 단어의 의미를 반영하여 "현재 단어"를 벡터화시킵니다. 그 시점에 임베딩을 다르게 하는 거니 '동적'입니다. -> 시점과 현재라는 말이 중요합니다. 현재마다 다르고, 시점마다 다릅니다.
=> 구닥다리 동적 임베딩

※ 중요 방법(구닥다리 방법) : 순환 신경망 -> 들어간 입력의 단어만 벡터화하는 게 아니고 앞의 단어의 hidden state를 봐서 벡터화에 적용합니다. = 안의 hidden state를 다 모아서 마지막에 나오는 hidden state를 사용할 수도 있고(ex 감정분석) 매 입력마다 hidden state를 계속 출력에 사용할 수도 있는데(ex 번역) 히스토리 정보가 바뀌어서 단어가 들어오면 벡터가 나오고 다음 단어가 또 들어오면 나오는데 앞의 히스토리 정보도 바뀌어서 임베딩에 적용하니 임베딩 결과가(벡터) 앞의 정보에 따라서 달라집니다.
+ 앞의 히스토리 정보가 바뀌어서 임베딩에 적용하니 임베딩 결과가 동일 단어라도 달라집니다.
※ imdb 감정분석에 대입해보면 문장에서 단어 하나 하나를 넣을 텐데 처음에는 첫 번째 단어만 넣고(hidden state를 0으로 하기 때문!) 두 번째 단어를 넣을 때는 첫 번째 단어를 넣어서 만든 hidden state와 두 번째 단어를 함께 받아서 또 hidden state를 만들고 끝까지 가면 마지막 단어(t)가 들어왔을 때는 t-1번째 단어를 넣어서 만든 hidden state와 t번째 단어를 받아서 마지막 hidden state를 뽑고 그것의 숫자 값들을 봐서 마지막 출력층에 dense 뉴런 수 1로 하여 긍정이냐 부정이냐를 판단한다고 보면 됩니다.
-> 왜 양방향이에요? : 현재 단어를 바꿀 때 앞 문맥과 뒤 문맥을 다 알 수 있으면 현재 단어의 의미를 더 잘 알 수 있습니다. ex) cctv 녹화본을 보는데 비디오를 앞의 장면과 뒤의 장면을 둘 다 보면 현재 장면을 이해하기 쉽습니다.
-> 임베딩 된 단어를 보고 문맥을 봐서 다시 임베딩합니다. > 들어오는 단어들이 쌩 one-hot encoding단어를 넣는게 아니고 정적 임베딩된 단어를 넣어서 동적으로 바꾸는 것입니다. (그럴 수도 있는 거지 꼭 그렇단 건 아닙니다!) > 이러한 구닥다리 방식도 말뭉치로부터 lstm을 돌려서 문맥을 이해합니다.
- 언어 모델
※ 모델이 만들어지면 주어진 특정 단어 시퀸스에 대해 다음 단어를 예측해볼 수 있습니다. 전통적인 정적 및 동적 단어 임비딩과 유사하게 말뭉치의 부분 문장이 주어지면 다음 단어를 예측하도록 훈련됩니다. + 양방향인 경우 이전 단어도 예측하도록 훈련됩니다.
넓은 의미 : 엄청난 문서로부터 배웁니다. = 마치 영어를 아예 이해했다고 볼 수 있습니다. > 영어를 이해하면 좁은 능력 말고도 많은 것을 할 수 있습니다.
좁은 : 앞의 문자을 보고 뒤의 단어를 예측합니다. > 가장 기본적인 능력입니다.

-> 사전학습 모델인데 위키피디아로 학습하고 내가 법률 문서로 재학습하고 싶다면 다시 미세조정을 해야 합니다.
- 언어 모델 기반의 임베딩

-> 조그마한 프로젝트는 lstm을 써서 좁은 의미의 문제를 풀겠지만 모든 문제를 포괄적으로 다 해결하기 위해서는 BERT와 GPT를 씁니다. > 둘 다 트랜스포머를 쓰니 이를 알아야 합니다.
※ 엘모는 대량의 데이터로 학습한 게 아니므로 언어 모델로 치지 않습니다. ∴ 포괄적으로 모든 문제를 다 해결할 수 없습니다. 근데 ULMFit는 엘모와 같은 방식으로 LSTM 기반 모델인데 왜 언어모델로 치나요? 대용량 위키피디아로 대량 학습을 했습니다.
+ 외에 BERT와 GPT가 있다 -> BERT : lstm으로 임베딩하지 않고 transformer의 인코더 스택을 사용하여 임베딩하는 것입니다.
-> BERT base는 적은 문서로 학습하고 적은 파라미터를 학습시킨 거고 BERT large가 큰 모델인데 large가 더 포괄적이지만 그만큼 파라미터가 더 많고 학습이 더 오래 걸립니다.
- 트랜스포머

translate인 번역을 위해 만들어진 모델이었습니다.
-> ex) 인코더에 입력으로 불어가 들어오면 디코더에서 영어로 해석이 됩니다. > 불어도 이해 못 하면서 영어로 번역할까요? 절대 불가능합니다. ① 영어도 잘해야 하고, ② 불어를 다 잘해야하고 ③ 영어와 불어의 관계도 알아야 합니다.
∴ ② 인코더에서 불어를 잘 알아야 하며, ① 타깃은 영어니 디코더에서 책임집니다. ③ 디코더는 영어만 책임지는 게 아니고 불어와 영어의 관계를 봐서 영어를 만드니 두 관계의 연관을 익혀야 합니다.
※ 임베딩은 단어의 표현이지 번역이 아닙니다.(단어의 의미를 알아서 벡터화하는 것이지 트랜스포머가 번역 모델이라고 해서 임베딩이 번역이라고 생각하면 안 됩니다.) > BERT는 인코더만 쓰고 GPT는 디코더만 쓴 것으로 단어의 표현(단어의 의미만 안 것이지 specific task에 적용하기 위해선 더욱 학습을 해야 합니다 -> 이런 게 포괄적인 모델이기에 다양한 일을 목적으로 학습시킬 수 있는 것입니다.)
=> 트랜스포머 구조
같은 놈이 여러 번의 블록을 반복합니다. 인코더 n개 디코더 n개, n개의 블락의 내부는 같은 구조를 가집니다 > 하나의 블락도 여러 개의 층이 있습니다 > 중간 encoding 블럭의 값을 쓰진 않습니다. cnn처럼 출력 단의 출력만 씁니다. = 가장 곱데기 값만 씁니다.
ex) 밑에 그림을 보면 encoding의 입력 단어는 3개다 encoding에서는 3개의 단어가 입력되고 출력으로 각각의 벡터가 나옵니다. k개의 단어가 들어가면 k개의 임베딩 벡터가 나옵니다. > lstm은 매 순간 단어를 한 개씩 넣습니다. 200 단어면 1개씩 200번 넣어서 돌립니다. > 얘는 200개 단어를 한 번에 넣고 200개 단어의 임베딩 결과가 나옵니다. > seq가 들어가서 병렬 처리해서 한번에 짠하고 나옵니다. (= 속도가 빠릅니다.)

인코더의 가장 곱데기에서 나온 임베딩 값을 매 layer 마다의 디코더에 다 줍니다. > 디코더 모든 블락은 encoding한 것을 다 씁니다. > 출력은 encoding에서는 동시에 한 번에 짠하고 나왔는데 디코더는 RNN 스타일로 번역할 단어 하나씩만 나옵니다. 매번 한번에 하나의 단어만 출력(번역)합니다. ∴ 디코더는 speed의 보틀넥이 됩니다.
>
디코더에도 입력이 있습니다. I am a student인 디코더가 출력한 값을 입력으로 넣는데 처음에는 I도 없으니 0을 넣습니다. 따라서 I는 encoding을 참조해서 생성(generative pretraining = gpt)됩니다. (= 생성된 단어가 없으니 encoding을 참조합니다.) > 다음 단어를 예측할 때는 i와 encoding값을 같이 넣습니다. (이게 번역입니다.) > student를 예측할 때는 지금까지 출력한 i am a를 다 넣습니다.
-> 내 생각 : 이미 학습이 끝난 상태로 인코더의 최 곱데기에서 나온 임베딩 결과를 가지고 있고(임베딩은 끝났습니다!) 디코더에서는 출력을 한 글자 한 글자 씩 한다고 했으니 처음에는 디코더의 입력으로 0과 임베딩 결과를 넣어서 i를 뽑고 다음엔 i와 임베딩 결과를 넣어서 am을 뽑고 그렇게 인코더에서 알게 된 단어 임베딩 즉 ② encoding에서는 불어의 의미(단어의 표현 = 의미가 담긴 임베딩 결과)를 잘 알고 있고 > 디코더의 입력으로 생성한 영어를 또 넣어주니 ① 디코더는 영어를 잘 알고 > 이때 같이 인코더에서 임베딩한 값을 디코더에 모든 layer에 넣어주니 ③ 영어와 불어와의 관계를 디코더가 잘 알 수 있겠습니다.
- BERT
임베딩 모델로 트랜스포머의 인코더만 사용합니다.
=> 인코더 내부 구조

영어 단어의 시퀀스를 병렬로 한 번에 줍니다. > 그때 문장의 시작과 끝을 표시하기 위해 cls를 줘서 문장과 문장사이의 분리자를 줍니다. > 근데 단어는 정적 임베딩된 애를 넣을 수도 있습니다. (원래 단어가 아니고 정적 임베딩된 단어를 넣을 수도 있는 것입니다. = 정적 임베딩된 단어를 동적 임베딩으로 내는 것입니다.) > 가장 곱데기는 동적 임베딩된 벡터가 독립적으로 나옵니다. > 중간 중간에서도 임베딩이 나옵니다.
-> 인코더 내부 : self-attention과 feed forward
-> self-attention : 생각과 머신을 입력으로 넣습니다. > cls와 position도 넣습니다. > 인코더 한 개 안에서는 self-attention 된 블록이 나오고 x에서 z로 나옵니다. z가 임베딩된 것이고 그 z를 feed forward를 거칩니다.
feed forward : 단어 별로 따로따로 fcn를 합니다. (z1과 z2를 같이 fcn 하는 게 아니고 z1만 따로따로 fcn을 합니다.) > z -> r이 됩니다. > 모두 독립적으로 변환이 됩니다. (임베딩이 되고+ 매 인코더[총 12개]에서 임베딩된 결과 r이 계속 나오고 또 다음 인코더로 들어갑니다.) > 역시 self-attention와 feed forward의 결과도 벡터입니다. > ★★ 동적으로 참조를 어떻게 할까요? 병렬로 독립적인데요? (★ 참조가 self-attention에서 일어납니다. ★)
=> attention

-> 이미지 캡셔닝에서 먼저 사용
영상을 입력으로 하여 영상의 특정 부분을 봐야만 그에 대응하는 단어로 문장을 만들 수 있습니다. > 지금 말하고 있는 단어는 영상에서 거기만 보고 말해야 하는 것입니다. 진짜 사람 눈처럼 영상에서 그 영역만 보면서 그 영역에 해당하는 단어를 만듭니다. (사람이 풍경사진을 보면서 구름을 보면 구름이라고 쓰고 산을 보면 산이라고 쓰는 것과 같은 것으로 '보면'이 attention입니다.)
> 그러면 왜 self인가요? attention이 집중할 대상인데 어디에 집중할까를 판단하기는 다른 소스가 있어야 합니다. bird라고 알려줘야 bird를 집중할 수 있습니다. 어디에 집중하느냐는 영상 보고가 아니고 단어(다른 소스)를 보고 집중을 하게 됩니다.= 소스를 알려줘야 합니다. (풍경 사진에서 새를 가리키며 bird라고 알려줘야 새로운 이미지가 왔을 때를 새를 보고 bird라고 할 수 있습니다.)
> 그렇지 않은 경우를 self-attention입니다. = 기존엔 영상에 집중하고 싶은데 영상만으로는 집중을 못해서 다른 소스가 필요했습니다. > self-attention는 영상을 참조하고 싶은데 영상이 결정 요소입니다. nlp로 돌아오면 문장의 어디를 집중하는지를 문장에서 구합니다.
-> 입력이 우측 문장으로 > 단어를 임베딩하고 싶습니다. (= 벡터로 바꿉니다.) it을 벡터로 바꾸고 싶은데 (= it의 의미를 알고 싶습니다.) > it이 무엇이고 누구를 보고 참조를 해서 벡터화되어야 하는지를 self-attention에서 구합니다.
> 이웃 단어로부터 참조를 합니다. > it을 벡터로 바뀌는데 자기 문장 안에 있는 다른 단어를 참조합니다. > 색은 진한 게 attention이 강한 것입니다. (= 주의 집중이 강한 것입니다. = 참조를 더 강하게 하는 것입니다.) it의 의미를 살려서 벡터를 만들어야 하는데 그 결정에 영향을 많이 주는 게 누구냐면 결국은 가중치 w입니다. 어떤 단어의 값을 더 많이 반영할 거냐를 배우게 하는 건데 그게 w를 배우는 것으로 얼마나 영향을 줄 것 인가(얼마나 주의 집중할 것인가!)를 학습합니다.
+ 얼마나 주의 집중할 것이냐가 쿼리 * 키 연산이니 쿼리와 키를 만드는 것을 학습하는 것입니다. 쿼리와 키는 입력 단어와 W의 연산으로 만들어지니 결국 영향을 얼마나 줄지 W에 따라 달라지니 그 W를 학습하는 것입니다.
-> 이것을 어떻게 수행할까요?

q, k, v(쿼리 키 벨류)로 > 쿼리는 질의입니다., k v는 자료구조에서도 k v가 있습니다. > 해시를 보면 질문하는 것이 쿼리입니다. > 질의와 키를 다 비교하고 가장 근접한 벨류를 리턴합니다. > 가장 가까운 것만(근접) 리턴을 합니다.(자료구조에서는 그렇습니다.)
> hard attention이면 가장 근접한 하나만 벨류로 리턴합니다. > 근데 이렇게 하면 안 되고 지금 단어를 임베딩하는데 여러 단어를 참조해서 임베딩할 건데 가장 가까운 단어만 리턴할 거면 참조의 의미가 없습니다.
> 키값마다 질의와의 관련도를 계산합니다. (질의와 키를 모두 코사인 계산) > 관련이 있는 만큼 키를 다 찾아서 한 놈만 꺼내지 말고 다 관련 있다고 보고 어떤 애는 0.9, 0.7, 0.6, 0.5에서 어떤 키가 0.5 정도 관련 있다면 그 키의 벨류는 0.5 w(가중치)를 곱해서 v를 반환합니다. > 따라서 벨류 하나가 아니고 모든 벨류를 구합니다. w와 곱해서 모든 v를 다 합해서 꺼냅니다. > 자료구조처럼 v를 하나만 뽑는 게 아니고 다 뽑습니다.
> q, k, v는 다 행렬로 다 파라미터 행렬입니다. > 그러니 이것도 배우는 것입니다 > wq, wk, wv 행렬을 바탕으로 단어(x)와 곱하면 그 결과 그 단어에 해당하는 q , k, v가 나옵니다. > 그니깐 우측에 행렬은 공유하고 단어마다 그 공유한 행렬과 곱해서 q, k, v가 나옵니다.
+ 본격적인 계산
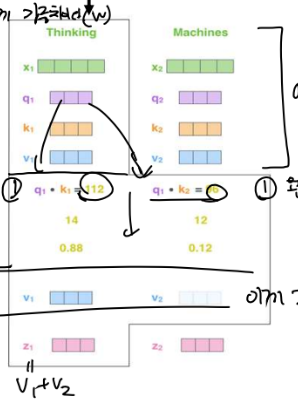
단어마다 q, k, v가 생기는데 지금 임베딩하고자 하는 단어의 질의를 봐서 각각의 다른 모든 단어의 k들과 얼마나 관련 있나 행렬 곱으로 계산합니다. > 첫 번째 단어와 다른 단어들이 얼마나 관련 있을까를 구해보면 thinking이 q와 나머지 단어들의 k와 연산을 곱해보는 것입니다.
> thinking, machine이면 thinking이 질의가 되어서 thinking과 thinking이 얼마나 비슷한지(나 자신과도 score를 구합니다.) q와 k를 곱합니다. > 또 thinking이 질의가 된고 machine이 키가 되어서 곱해서 얼마나 관련 있나를 구합니다. = 값이 크면 자신하고 얼마나 관련 있는지(관련도)가 높습니다. (타겟 단어[임베딩하려고 하는 단어]의 질의와 타겟단어 포함 나머지 단어의 k를 곱해서 score(타겟 단어와의 관련도)를 구합니다.)
> 관련도를 하나의 문장에서 모든 단어들에 대한 관련도를 확률화해서 합이 1이 되게 합니다. > 생각과 다른 단어와의 연관성을 확률로 구합니다. > 그 확률이 가장 높은 애의 v를 보면 > 앞에서 구한 관련도 확률을 v와 곱해서 가져옵니다. > v1은 88퍼 비슷하고 확률과 v1을 곱해서 가져옴, v2는 12퍼 가까워서 v2와 확률을 곱해서 가져와야 합니다.
> 가져온 V들을 다 더해서 sum인 z를 구합니다. (= 해시처럼 가장 가까운 v만 가져오는 게 아니라 모든 v를 다 가져오는데 관련도에 따라서 v에 가중치를 곱합니다.)
-> ★ x1이 중심이 되어서 이웃 단어와의 관련성의 확률을 구해서 확률값과 이웃 단어의 v를 곱하고 그 v들을 다 더해서 이 단어를 표현하는 벡터 z를 만듭니다. > z가 이웃 놈과 영향을 받아서 만들어진 x의 임베딩 벡터 결과입니다. > ★ 나와 같이 들어온 단어들과의 가까운 정도를 다 구해서 걔들이 나를 표현하는데 얼마나 영향을 주는지 구하니 내가 모든 단어들을 참조해서 임베딩 됩니다. (인코더가 독립된 입력처럼 보였는데 다 참조를 합니다. 어떻게 하나요? attention 개념을 사용합니다.) > 다음은 x2가 중심이 되어서 x2의 z(임베딩 결과)를 구하고 모든 단어를 중심에 두면 모든 단어의 임베딩이 됩니다.
- LSTM과의 차이
1. 아무리 멀리 있어도 관계가 가까우면 큰 영향을 미칩니다. (같이 들어온 단어들의 관련성을 전부 봅니다.)
-> lstm에서 압축된 것(context vector)이 희석되는 것은 시간적 거리가 먼 단어(지금 임베딩을 하고 싶은 단어가 입력으로 들어왔을 때보다 너무 앞에 이미 들어갔던 단어)는 나에게 영향을 못 미치는 것 때문에 발생합니다. > 인코더는 너무 멀어도 단어를 시간 순이 아니라 관련도에 따라서 모두 봐서 입력 z를 만들기 때문에 시간의 의존도가 없습니다. = 기억 상실을 막는 트랜스포머의 장점입니다.
2. 단어들을 다 병렬처리합니다.
=> multi head attention

셀프의 출발이 뭔가요? 공유할 wq, wk, wv행렬이 있었는데 > 이 공유 행렬 세트를 한 개만 하면 single head attention, 두 개면 double head attention입니다. > 저 행렬이 바뀌면 q, k, v가 다 바뀝니다. x와 행렬이 곱해져서 단어별 q, k, v가 나오는 거니 > 행렬 3개가 정말 중요한 것입니다. 근데 이 행렬도 난수로 주고 이걸 학습하는 것인 파라미터 행렬이라고 했고 이걸 역전파로 다 고치는 건데 만약 이걸 다른 세트를 3개 더 두면 cnn에서 커널의 개수가 되는 것으로 파라미터 셋이 또 있는 거니 다른 커널이 있는 것으로 다양한 관점으로 feature를 뽑는 것입니다. = q, k, v가 입력(x) * 커널(w)로 뽑은 feature입니다!! ★
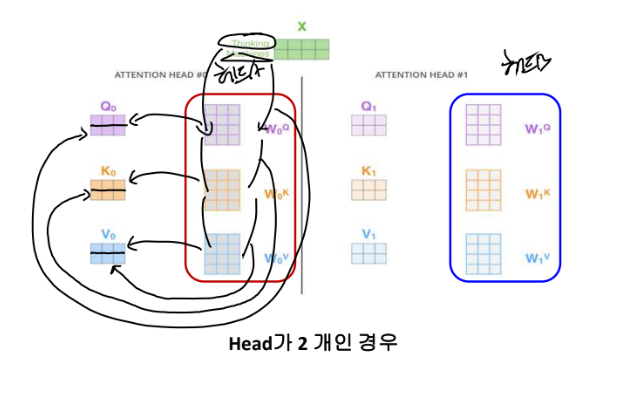
> 다양한 관점으로 attention 메커니즘을 해보자는 것입니다. it을 벡터화할 건데 행렬 셋을 하나만 만들면 A로 되는데 그게 정확히 맞는 임베딩 결과일까요? (그니깐 cnn에서 커널을 하나만 한 것!) > 모릅니다. 그러니 셋을 하나 더 두면 행렬 셋 B입니다. 벡터 2행 중 1행이가 thinking의 q, k, v 2행이가 machine의 q, k, v 입니다.
> 연산 과정 : 단어가 두 개입니다. thinking이면 행렬 A와 thinking이랑 해서 q, k, v가 나오고 행렬 A와 machine이랑 해서 q,k,v가 나오고 그 결과 z가 2행이 나옵니다. > 행렬 B와 thinking이랑 해서 q,k,v가 나오고 행렬 B와 machine이랑 해서 q,k,v가 나오고 그 결과 z가 2행이 나옵니다. > 행렬 C와 thinking이랑 해서 q,k,v가 나오고 행렬 C와 machine이랑 해서 q,k,v가 나오고 그 결과 z가 2행이 나옵니다.
> 이 z들을 어떻게 융합할지를 구할 마지막 w가 또 있습니다. = z0,1,2,3중 누구에 가중치를 더 많이 주어서 최종 Z를 만들까를 할 WO가 있습니다. = Z를 하나로 융합합니다. > multi head attention 안 쓰면 그냥 Z0가 임베딩 결과입니다. 그러니 멀티를 쓰면 최종 Z가 임베딩 결과입니다.
=> feed forward

그냥 fcn입니다. 모든 단어가 병렬이라서 모든 단어를 fcn에 넣는 게 아니고 그냥 단어 하나만 fcn으로 받습니다. > 여기를 보면 add norm을 하는데 이 layer를 거칠 단어 데이터와 아닌 데이터가 있습니다. resnet처럼 attention을 통과가 가능합니다. attention 한 것과 안 한 것을 add 하여 bit wise sum 합니다. > 그러니 이 벡터들을 정규화해줘야 합니다. 그게 끝나야 feed forward로 들어갑니다. 그러면 feed forward를 안 거친 데이터와 거친 데이터를 다 bit wise를 해서 add 하고 정규화합니다. ★ 이게 매 encoding 블락마다 있습니다.
- BERT
지금까지는 신경망의 구조를 보았고 그럼 이 구조 위에서 학습을 어떻게 시킬까요? 데이터는 뭔가요? 방식은 뭔가요?
=> 학습
self 슈퍼바이즈입니다. = 사람은 라벨을 안 줬는데 모델이 알아냅니다. (진짜 너무 좋은 거 아니에요?) > 인간이 준 건 위키페이아 문장만 주고 라벨은 없고 학습하는 애가 데이터와 라벨로 만듭니다.
-> 사전 학습 작업들 : 학습 전에 이 두 개를 해야 합니다.
1번 MLM : 아까 좁은 게 앞의 단어로 다음 단어 예측이라면 마스크로 문장의 단어를 지우고 지워지지 않은 단어를 가지고 지워진 단어를 예측합니다.

마스크 된 단어가 데이터고 우리가 준 입력이 답입니다. 모델이 마스크를 알아서 다 채우는 것입니다. 원래는 입력이 the, cook인데 지가 마스크해서 가립니다. > BERT는 전체 단어 중 10, 20 퍼를 랜덤 하게 마스킹을 하고 원래 데이터를 라벨로하고 예측값과 오차로 학습합니다.

the movie에서 단어와 단어의 위치값을 임베딩해서 BERT의 인코더 쌍으로 같이 줍니다. 왜냐면 rnn은 저절로 위치가 암시가 됩니다. 순서대로 넣으니깐 넣는 순서가 위치 그 자체입니다. 근데 얘는 통째로 넣으니 포지션을 별도로 명시를 해야 합니다. > 이걸 영상에 적용해서 영상 조각을 단어 대신에 넣습니다.(visual transform)
2. NSP : 줄 때 문장 하나를 준 게 아니고 문장을 두 개를 줍니다. > "문장 A sep 문장 B"를 줍니다. > A와 B에서 랜덤 하게 둘 다 마스킹해서 예측하라고 합니다. > 그리고 내가 A와 B를 줬는데 B가 A다음으로 합당하냐고 물어봐서 합당하면 1, 아니면 0으로 합니다.

-> 데이터는 어떻게 만들어요? 위키피디아의 첫 번째 두번째 문장을 next sentense yes, 첫번째 다섯 번째 문장을 next sentense no로 한다 인간이 만들어 놓았습니다.
- Specific Task
그럼 이거를 그대로 쓰면 단어에서 의미를 찾는 게 끝입니다. (이것만 하면 그냥 임베딩 좋고 주변 단어를 보고 가운데 단어를 예측하는 좁은 의미의 언어 모델입니다.)

-> 오른쪽에 스쿼드가 Q/A 데이터로 BERT를 파인튜딩하도록하는 데이터입니다.
결론
- 느낀 점 : BERT를 왜 쓸까를 생각해 봐야 합니다.
1. 임베딩 모델입니다 : 그러면 imdb에서 임베딩을 하고 감정분석인 분류를 했는데 임베딩을 keras로 하지 말고 BERT로 한 것입니다. = BERT의 동적 참조 임베딩을 사용한 것입니다.
2. BERT의 특징을 이해해야 할 것 같습니다. (동적 참조 임베딩 등등) > BERT를 QA에 쓰는 이유가 BERT의 장점을 가지고 specific task에 fine tuning 했을 때 좋은 무언가가 있기에 하는 거일 것입니다.
'[AI] > [교과목 | 학습기록]' 카테고리의 다른 글
| 딥러닝 PART.교과목 오토인코더(Ae) (0) | 2022.11.16 |
|---|---|
| 딥러닝 PART.교과목 단어 임베딩 (0) | 2022.11.08 |
| 딥러닝 PART.교과목 RNN (0) | 2022.11.08 |
| 딥러닝 PART.교과목 VQA, CNN text에 활용 (0) | 2022.10.23 |
| 딥러닝 PART.교과목 yolo, segmentation (0) | 2022.10.11 |



