
개발자로 후회없는 삶 살기
[22.08.16] 딥러닝 PART.Batch Normalization 본문
서론
GAN 스터디 그룹에서 별도로 공부 및 발제한 내용입니다.
본론
- 신경망에서의 학습
1. 학습 시 Gradient 기반의 방법들은 파라미터 값의 작은 변화가 신경망 출력에 얼마나 영향을 미칠 것인가를 기반으로 파라미터 값을 학습합니다.
2. 변화가 신경망 결과에 매우 작은 변화를 미치게 될 경우 효과적인 학습 불가합니다.
3. Gradient라는 것은 변화량으로 변화량이 매우 작아지거나(Vanishing) 커진다면(Exploding) 신경망 학습이 불가합니다.
- 안정적인 학습을 위한 간접적인 방법
1. Sigmoid, tanh : 매우 비선형적인 방식으로 입력 값을 매우 작은 출력값의 범위로 squash
e.g. sigmoid는 실수 범위의 수를 [0, 1]로 맵핑
2. 위의 문제점 :
1) 출력의 범위를 설정하여 매우 넓은 입력 값의 범위가 극도로 작은 범위의 결괏값으로 매핑합니다.
2) 이러한 현상은 비선형성 레이어들이 여러 개 있을 때 더욱 학습이 악화됩니다.
-> 첫 layer의 입력 값에 대해 매우 큰 변화량이 있더라도 결괏값의 변화량은 극소입니다.
3) 간접 X -> 직접적으로 "학습하는 과정 자체를 전체적으로 안정화"하여 학습 속도를 가속시킬 수 있는 근본적인 방법인 "배치 정규화(Batch Normalization)"를 사용합니다.
- 정규화를 하는 이유
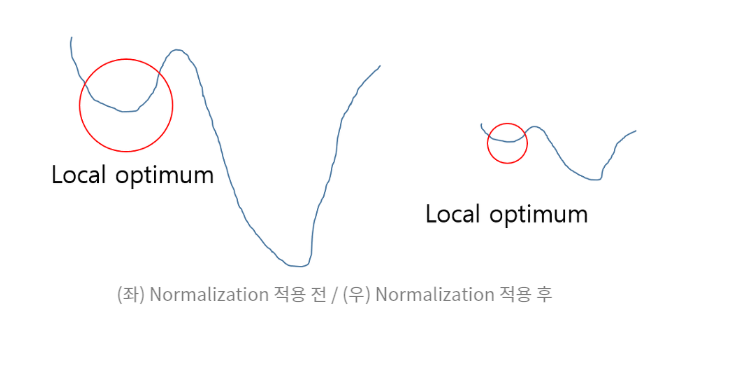
1. 그래프를 왼쪽에서 오른쪽으로 만들어, 로컬 옵티멈에 빠질 수 있는 가능성을 낮춥니다.
2. 로컬 옵티멈에 빠지는 것이 Gradient가 매우 작아져서 신경망 결과에 매우 작은 영향을 주게 되어 발생합니다.
3. 학습 자체에서 안정화를 시켜버립니다.
- 학습 불안정화가 일어나는 이유
각 layer나 activation 마다 입력값의 분산이 달라지기 때문입니다.
1. Covariate Shift : 이전 레이어의 파라미터 변화로 인하여 현재 layer의 입력의 분포가 바뀌는 현상
2. Internal Covariate Shift : layer를 통과할 때마다 Covariate Shift 가 일어나는 현상
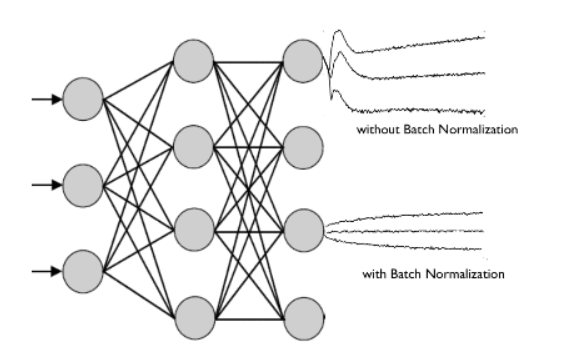
- 배치정규화
1. 정의 : 각 batch 별 평균과 분산을 기준으로 각 layer에서 나오는 output을 정규화하는 기법
2. 평균과 분산을 조정하는 과정이 별도의 과정으로 떼어진 것이 아니라, 신경망 안에 포함되어 학습 시 평균과 분산을 조정하는 과정 역시 같이 조절합니다.
3. 즉, 각 layer마다 정규화 하는 layer를 두어, 변형된 분포가 나오지 않도록 조절
1) layer를 통과할 때마다 이전 layer와 값들이 너무 심하게 차이 나는 정도를 줄이고자 사용합니다.
2) 통과할 때마다 변형된 분포가 나오지 않게 하여 Covariate Shift가 일어나지 않게 해 줍니다.
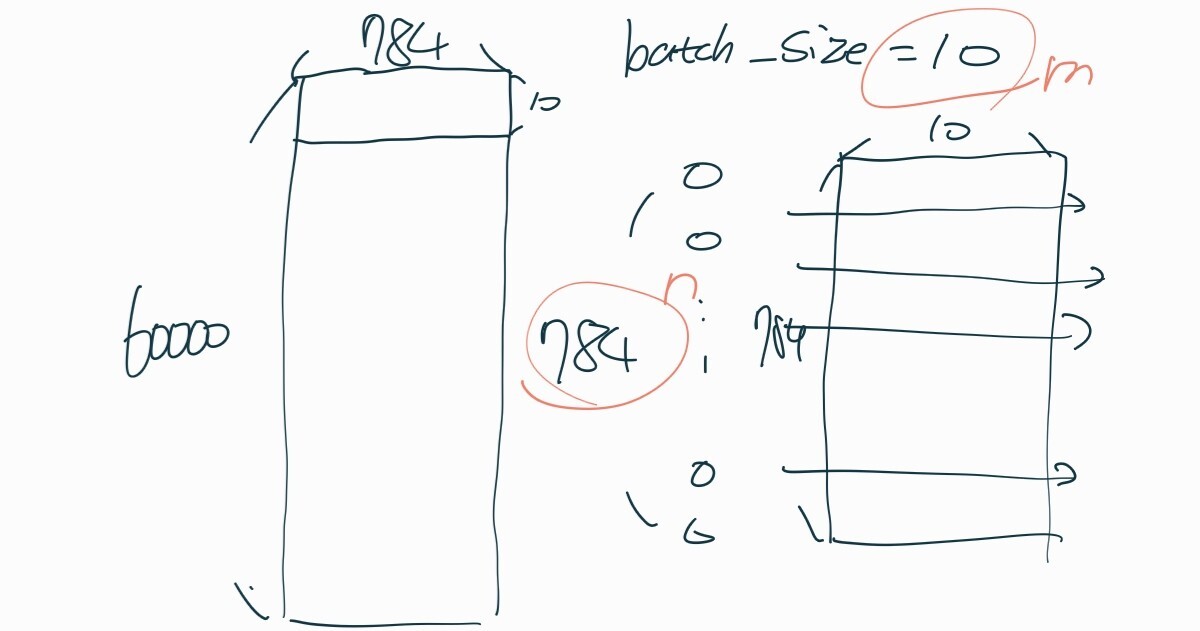
4. 배치란? : 모델의 가중치를 한번 업데이트시킬 때 사용되는 샘플들의 묶음입니다.
-> 헷갈렸던 부분 : cnn의 배치란 batch_size = 10이면 mnist 데이터의 0~9행
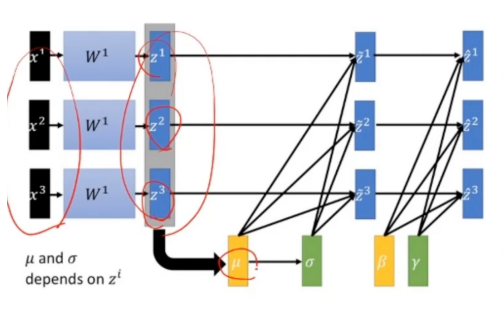
5. 수식

1. 미니 배치의 평균과 분산을 이용해서 정규화 한 뒤 scale 및 shift를 감마(γ) 값, 베타(β) 값을 통해 실행
> 미니 배치의 평균과 분산으로 정규화하는 것은 말 그대로 전체 데이터의 측정치로 정규화하는 것이 아니라는 의미
+ 중요 포인트는 감마(γ) 값, 베타(β) = 일반 정규화와 다른 부분입니다.
2. 감마와 베타는 학습 가능한 변수. 즉, 역전파에서 같이 학습됩니다.
3. 이렇게 정규화된 값을 활성화 함수의 입력으로 사용하고, 최종 출력 값을 다음 layer의 입력으로 사용합니다. (활성화 함수의 출력을 정규화의 입력으로 사용하면 위의 간접적인 방법과 같은 결과)
=> 특징
1. 활성화 함수 앞쪽에 배치
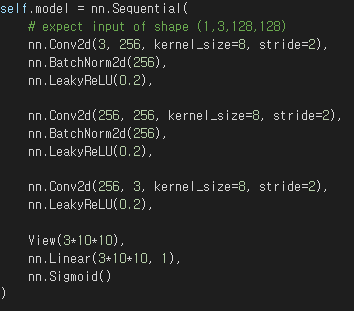
2. 신경망에 포함되어 역전파를 통해 학습됩니다.
- 이전 스터디에서!
1. 정규화 : 학습 셋 전제 집합에 정규화 실시합니다.
2. 배치 정규화 : 미니 batch 단위로 정규화 실시 근데 cnn에 적용하고자 할 때는 cnn의 특성을 고려해 줘야 합니다.
=> DNN의 배치 정규화
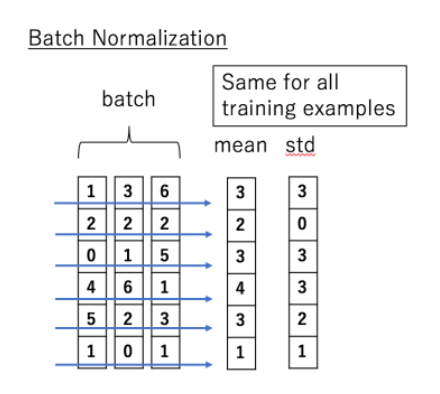
-> 발제자분 : "각 feature의 평균과 분산을 구해서 batch에 있는 각 특성(feature)을 정규화, batch 전반에 걸쳐서 처리되므로 batch size와 관련이 깊다."
1. 세로 120451이 하나의 샘플입니다.
2. 가로 1, 3, 6이 feature가 됩니다. (여기서 feature란 cnn의 feature 맵이랑 연결시켜 보면 하나의 픽셀을 feature라고 하고 feature들이 모여서 feature 맵이라고 하는 것 같습니다.)
∴ BN은 batch에 있는 “모든” sample 들에 대해서 “각 feature의 평균과 분산”을 구하여 정규화합니다.
> batch_size = m/ 입력 사이즈 = n
-> CNN의 배치 정규화

1. 위의 모양으로 입력 x와 가중치 w의 곱(wixi+b)이 생깁니다.
2. CNN의 경우 컨볼루션 성질을 유지시키고 싶기 때문에 각 채널을 기준으로 각각의 감마와 베타를 만들게 됩니다.(★ 채널을 따져야 합니다.)
batch_size = m
필터 사이즈 = p x q
채널 개수 = n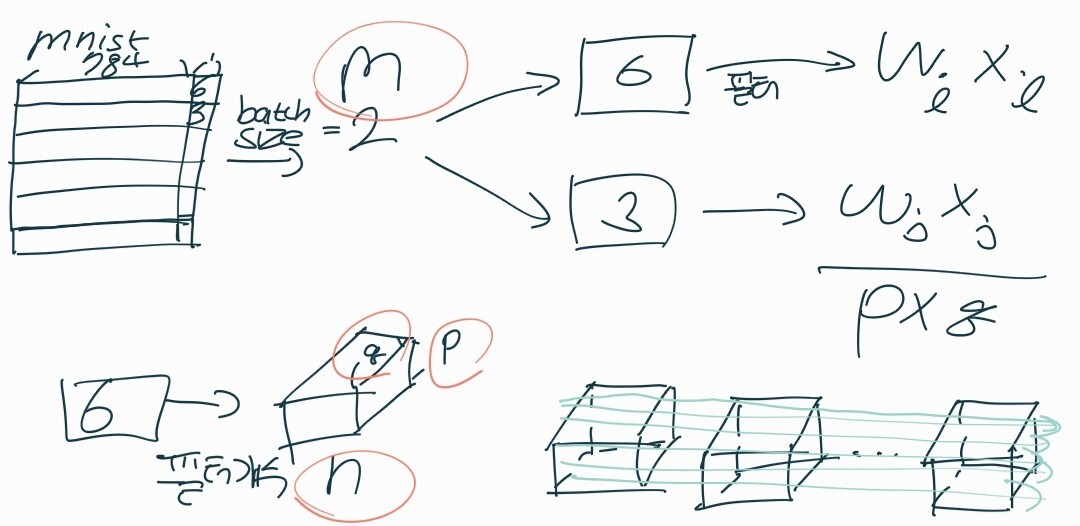
'[AI] > [네이버 BoostCamp | 학습기록]' 카테고리의 다른 글
| [22.09.15] GAN PART.훈련과정 (0) | 2022.12.27 |
|---|---|
| [22.09.13] GAN PART.GAN 시스템 (0) | 2022.12.27 |
| [22.02.11] 딥러닝 PART. 밑바닥부터 시작하는 딥러닝 발제 (0) | 2022.12.27 |
| [22.04.27] 딥러닝 PART.CS231n 6강 (0) | 2022.12.27 |
| [22.01.19] 딥러닝 PART.CS231n 2강 (0) | 2022.12.27 |



