
개발자로 후회없는 삶 살기
[22.09.13] GAN PART.GAN 시스템 본문
서론
동아리 프로젝트를 위해 GAN 심화 공부를 시작합니다.
※ 이 포스트는 다음 교재의 학습이 목적임을 밝힙니다.
https://tensorflow.blog/gan-in-action/
GAN 인 액션
★★★★★ GAN 을 철저하게 파헤쳐 주는 책! (책**아 님)★★★★★ GAN의 발전사를 알맹이만 쏙쏙 빼먹을 수 있어 유익했다. (아***인 님)★★★★★ GAN 입문을 위한 좋은 책 (spaci*** 님)★★★★★
tensorflow.blog
본론
- GAN 이란?
하나는 가짜 데이터를 생성하도록 훈련되고 다른 하나는 실제 샘플과 가짜 샘플을 구분하도록 훈련되는 두 개의 모델을 훈련하는 머신러닝의 한 종류입니다. (첫걸음 2일차 참고!)
> 레오나르도 다빈치의 작품처럼 보이는 이미지를 생성하고 싶다면 다빈치의 작품을 훈련 데이터 셋으로 사용해야 합니다. (판별기에는 실제 이미지를 넣어줘야 하는 거 알죠?)
=> 생성자와 판별자의 목표
1. 생성자의 목표 : 훈련 데이터 셋에 있는 실제 데이터와 구분이 안될 정도로 유사한 샘플을 만드는 것(다빈치의 그림처럼 보이는 그림을 생성)
2. 판별자의 목표 : 생성자가 만든 가짜 데이터를 실제 데이터와 구별(훈련 데이터를 진짜 데이터라고 한다) 인지 가짜인지 구별하는 미술품 감정사 역할입니다.
- GAN의 동작 방식
위조범이 더 그럴듯하게 만들수록 감정사가 진품을 판별하는 능력 또한 더 뛰어나야 합니다. 반대 상황으로 감정사가 위작을 찾는 능력이 뛰어날수록 위조범 역시 잡히지 않기 위해 더 감쪽같은 위작을 만들어내야 합니다.
+ 더 직관적으로
-> 판별자가 가짜 이미지에 속아 가짜를 진짜로 분류할 때마다 생성자는 자신이 임무를 잘 수행하고 있다는 것을 알게 되고(가짜 이미지를 판별자가 1이라고 할 테니 생성자의 오차가 적어질 것이니 오차가 적은 게 임무를 잘 수행하고 있는 것입니다.) 반대로 생성자가 만든 이미지가 가짜라는 걸 판별자가 포착할 때마다 생성자는 더 그럴듯한 결과물을 생성해야 한다는 피드백을 받습니다.(가짜 이미지를 판별자가 0이라고 하는데 생성자는 1이라고 하니 오차가 크다 오차가 피드백입니다.)
-> 판별자는 여타 분류기처럼 자신의 예측과 실제 레이블 간의 차이(오차)를 통해 학습하고 따라서 생성자가 더 그럴듯한 데이터를 만들수록 판별자도 진짜와 가짜를 더 구별하게 되어 두 네트워크 모두 동시에 지속해서 성능이 향상됩니다.
- GAN 시스템
1. 훈련 데이터 셋(실제 데이터 x) : 생성자가 이것을 모방하려고 하는 것이고 판별자의 입력으로 들어갑니다.
2. z : 랜덤 숫자 벡터로 가짜 샘플(x) 합성의 시작점으로 사용됩니다.
3. 생성자 네트워크 : 생성자는 z를 입력으로 받아서 가짜 샘플(x)을 출력 = 생성자의 목표 -> 훈련 데이터 셋의 진짜 샘플과 구별이 안 되는 가짜 샘플을 생성하는 것입니다.
4. 판별자 네트워크 : 판별자는 x와 x*을 입력으로 받는다, 판별자는 각 샘플이 진짜일 확률을 계산하는 일반적인 분류기입니다.
반복 훈련 : 일반적으로 분류기를 평가하는 것과 마찬가지로 판별자의 예측의 오차가 얼마인지 계산해서 이 결과를 사용해 역전파로 판별자와 생성자 네트워크를 반복해서 훈련합니다,
-> 판별자의 가중치와 편향은 x를 진짜로 판단하고 x*을 가짜로 판단하도록 올바른 예측의 확률을 최대화하여 분류 정확도를 높이도록 업데이트됩니다.
-> 생성자의 가중치와 편향은 판별자가 x*을 잘못 분류할 확률을 최대화하도록 업데이트됩니다.
- GAN 훈련하기

1. 판별자 훈련
-> 훈련 데이터 셋에서 랜덤 하게 진짜 x를 선택(첫걸음 2주차 11의 첫 번째!) > z를 얻어서 생성자에 넣어 x* 생성(11의 두 번째!) > 판별자 네트워크를 이용해 x와 x*을 분류(첫 번째, 두 번째!) > 오차로 판별기 파라미터 업데이트하고 분류 오차를 최소화합니다.★
-> 처음 안 사실!(매우 중요 ★ x 100) : 판별자도 비지도 학습입니다. 진짜로 데이터가 x 뿐이지 x, y가 아니었습니다. mnist 데이터에서 어떤 숫자 벡터를 넣던지 y는 안 넣고 그저 실제다(1), 가짜다(0)만 넣어줬습니다.★
2. 생성기 훈련
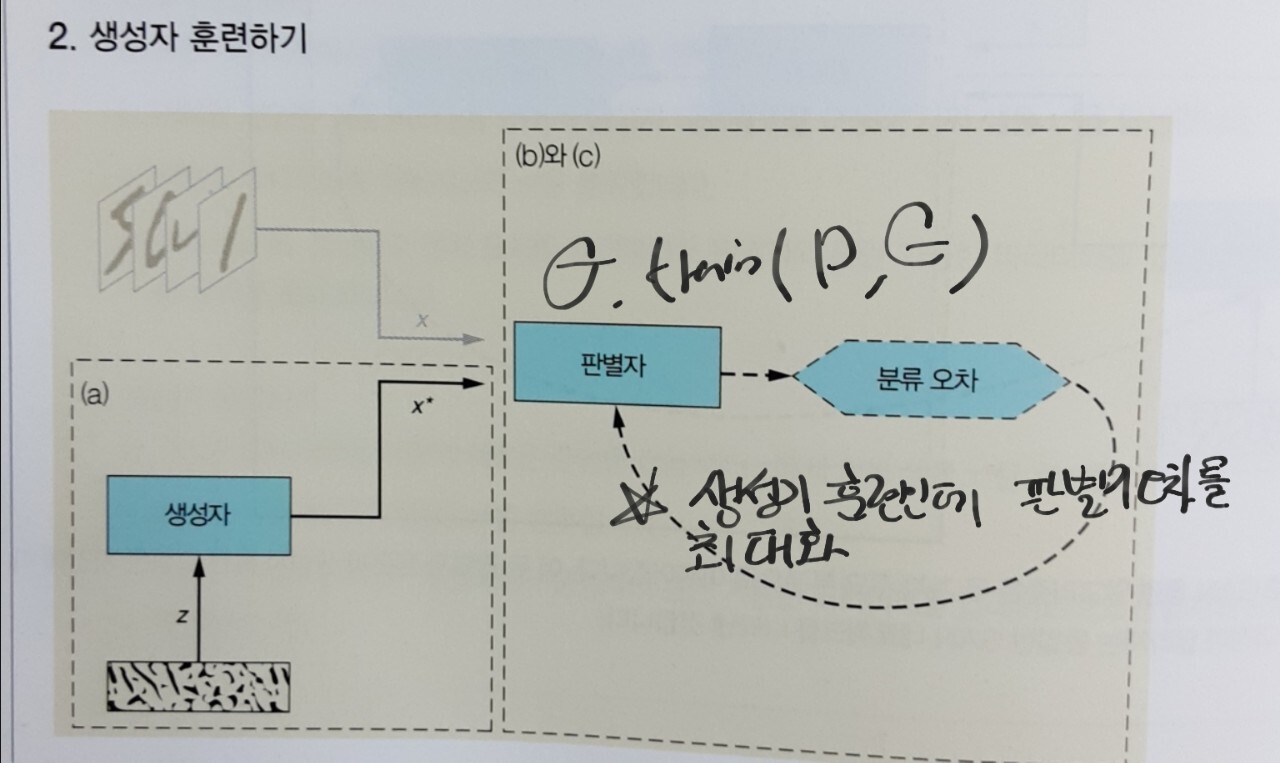
-> z를 생성자에 넣어서 x* 합성 > 판별자 네트워크를 이용해 x분류(11의 세 번째!) > 이 오차로 판별기의 오차를 최대화합니다. (D(x)에 대한 판별자의 손실을 역전파 하여 분류 오차가 최대화되도록 훈련합니다.)★ -> 어떻게 할까요? 생성자가 만든 이미지를 1로 라벨링 합니다.
- 균형이란?
1. 일반적인 신경망 학습은 명확한 목표가 있습니다. ex) 훈련 중에 훈련과 검증 셋의 분류 오차를 보다가 검증 오류가 나빠지면 과대적합이라고 판단하여 훈련 중단합니다.
2. GAN의 훈련
두 네트워크는 목표가 서로 다릅니다, 하나가 좋아질 때 다른 하나는 나빠집니다. 언제 훈련을 종료할까요?
제로섬 게임 : 한 사람의 이득이 곧 다른 사람의 손해입니다. -> 이 경우 내시 균형에 도달하면 게임이 끝나는데 GAN은 두 가지에 내시 균형에 도달합니다.
1) 생성자가 훈련 데이터 셋의 실제 데이터와 구별이 안 되는 데이터 생성
2) 판별자가 추측을 50대 50을 할 때
-> GAN이 위 두 가지에서 생성자가 구별이 안되는 데이터를 생성하면 판별자가 이 둘을 분간할 방법이 전혀 없어서 판별자가 받는 샘플의 절반이 진짜고 나머지는 가짜니 50%의 확률로 진짜 혹은 가짜라고 분류하는 게 판별자가 할 수 있는 최선입니다.
※ 하지만 실무에서 GAN의 수렴은 불가능에 가깝습니다. 하지만 이 문제가 gan 어플리케이션 개발에 방해되지는 않습니다. 수학적으로 완벽하게 보장되지 않더라도 GAN은 실제로 놀라운 결과를 달성합니다.
- 오토인코더

단계 1: 할머니께 말씀드리기 위해 하는 것을 모두 압축(진짜 그냥 훈련된 인코더대로 차원 축소만 함) >
단계2 : 잠재 공간을 만듦 >
단계 3 : 할머니가 할머니의 살아온 인생에 맞춰서 z가 의미하는 바를 재구성합니다, (진짜 훈련된 디코더대로 차원 확장합니다.)
=> 인코더 디코더 훈련
||x-x*||이라는 손실로 훈련합니다. > 즉 이 손실을 최소화하는 인코더와 디코더의 파라미터를 경사하강법으로 업데이트합니다.
-> 오토 인코더의 활용
1. 공짜로 압축된 표현을 얻습니다. : z는 잠재 공간 차원에서 지능적으로 축소된 객체입니다. > 축소된 잠재 공간에서 아이템과 타겟 클래스의 유사도를 확인 가능합니다. = 1. 정보검색, 2. 유사도 거리 비교 분야에 적용 가능합니다.
2. 훈련 안정화 : 세계 대전 당시의 옛날 사진이나 영상에 있는 노이즈를 제거하고 흑백사진에 색을 입힐 수 있습니다.
3. 레이블 된 데이터가 필요 없습니다.
+ 오토 인코더와 딥러닝
인, 디코더 모두 딥러닝으로 하고 두 네트워크 모두 활성화 함수와 중간층을 가집니다. > 훈련은 인코더, 디코더같이 하고 내 목적이 잠재 공간을 만드는 것이면 인코더만 쓰고 생성이 목표면 디코더만 잘라서 씁니다.
결론
784 크기의 진짜 이미지가 들어가면 만약 숫자 3이라면 3 부근이 255로 되어있고 그런 모양을 판별자에게 1이라고 지도학습을 해주고 노이즈가 막 끼어있는 이미지를 판별자에게 0이라고 지도학습을 합니다. (사실 비지도 학습이지만 지도학습이라고 하면) 이때 판별자의 파라미터가 진짜가 1 가짜가 0이라고 갱신이 될 것입니다.
> 판별자가 어느 정도 학습이 되면 생성자의 노이즈 이미지를 판별자에게 주어 1이라고 지도학습합니다. 이때 역전파를 판별자의 파라미터는 고정하고 생성자에게 줍니다. 이때 생성자의 진짜 이미지를 만들어내는 파라미터들이 갱신이 될 텐데, 보면 판별자는 현재 3 부근만 255인 이미지가 1이라고 갱신이 되어있는데 노이즈가 1이라고 말하니 오차가 엄청 크겠죠? 그만큼 생성자의 파라미터를 갱신하니 생성자의 파라미터가 엄청 많이 바뀔 거고 그러면 생성자는 노이즈를 만들다가 3 부근만 255인 이미지를 만들도록 될 것입니다.
'[AI] > [네이버 BoostCamp | 학습기록]' 카테고리의 다른 글
| [22.09.23] GAN PART.최신 GAN 기술 (0) | 2022.12.27 |
|---|---|
| [22.09.15] GAN PART.훈련과정 (0) | 2022.12.27 |
| [22.08.16] 딥러닝 PART.Batch Normalization (0) | 2022.12.27 |
| [22.02.11] 딥러닝 PART. 밑바닥부터 시작하는 딥러닝 발제 (0) | 2022.12.27 |
| [22.04.27] 딥러닝 PART.CS231n 6강 (0) | 2022.12.27 |



