
개발자로 후회없는 삶 살기
[22.01.19] 딥러닝 PART.CS231n 2강 본문
서론
※ 이 포스트는 다음 강의의 학습이 목적임을 밝힙니다.
http://cs231n.stanford.edu/
Stanford University CS231n: Deep Learning for Computer Vision
Course Description Computer Vision has become ubiquitous in our society, with applications in search, image understanding, apps, mapping, medicine, drones, and self-driving cars. Core to many of these applications are visual recognition tasks such as image
cs231n.stanford.edu
본론
- 이미지 분류란?
입력 이미지를 미리 정해진 카테고리 중 하나인 라벨로 분류하는 문제입니다.
-> 이미지 : 숫자로 구성된 3D arrays로 0 ~ 255 사이의 숫자들이 height × width × colors의 3차원으로 배치

고양이 이미지는 가로, 세로, 색상 채널로 구성 -> 입력으로 들어온 arrays 보고 고양이라고 판단하는 것
=> 문제점 : 컴퓨터가 보는 이미지는 숫자 배열일 뿐, 이미지의 밝기나 형태에 따라 달라지는 픽셀 데이터를 보고 분류
① 시점 변화 : 카메라에 의해 시점이 상이 > 보는 시각에 따라 이미지 변화
② 조명 상태 : 조명의 영향으로 픽셀 값 변형 > 밝기에 따라 음영과 그림자 등
③ Occulusion(폐색) : 객체의 전체가 보이지 않는 경우 > 은폐, 은닉에 따라 기계의 판단력 저하
④ class의 다양성 : 분류의 범위가 큰 것들이 많다. > 고양이 중에서도 페르시안인지, 샴인지?
+크기, 변형, 배경 등등
- 함수 표현식
이미지를 인자로 받아 고양이의 레이블을 class_label 반환하는 개념
-> 주의점 : 이미지를 입력으로 받아 고양이라는 클래스로 인식하는 명백한 알고리즘 존재 ❌
-> 시도 : 이미지의 특징적인 Edge, Shape를 찾아 명시적 규칙 집합 정의 ex) 고양이는 두 개의 귀와 하나의 코 등 하지만 모든 객체마다 다르게 적용되어 확장성, 유연성 ❌
- Data-driven approach
데이터 수집 > 모델학습 > 평가
1) 이미지와 레이블로 구성된 데이터 수집
2) 데이터 셋에 대하여 Classifier 학습
3) 테스트 이미지 셋에 대하여 Classifier를 평가
=> 함수식
1) train
IN ➜ 이미지, 레이블/ OUT ➜ 메모리 모델 구축
2) predict
IN ➜ 모델, 입력 테스트 이미지/ OUT ➜ 테스트 이미지 레이블 반환
- Nearest Neighbor Classifier
=> 데이터 기반 접근을 사용한 학습 모델
1. 모든 학습용 이미지와 레이블 메모리 적재
2. 예측 단계에서 테스트 이미지와 메모리 데이터 순차 비교
3. 유사성이 가장 높은 이미지 레이블 적용
=> CIFAR - 10 데이터 셋 예제
1. Train 50000, Test 10000
2. 하나의 이미지 32×32 픽셀
3. 0~9중 하나인 10개의 클래스로 라벨링

비행기부터 트럭 클래스 10개로 구성 + 이미지 입력 시 정확도 순으로 나열
=> 동작 원리
Test 이미지와 Train 이미지의 픽셀 값 비교
1) L1 distance
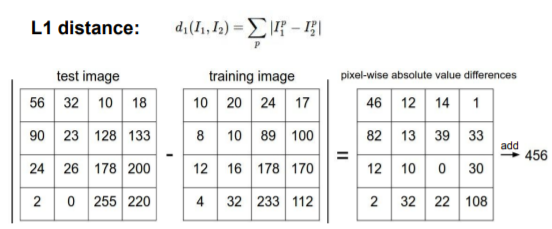
두 이미지 벡터의 각 성분의 차이 계산합니다. 차를 전부 더하여 결과를 도출합니다. -> ※ 결괏값이 작을수록 높은 유사성을 띱니다.
2) L2 distance

- k-Nearest Neighbor
=> NN과 차이점
1. 가장 가까운 이미지( = 거리가 가장 짧은 ) 가까운 이미지를 찾되 '개수' 지정
2. k개의 후보 중 다수결로 투표, 유사성 판단
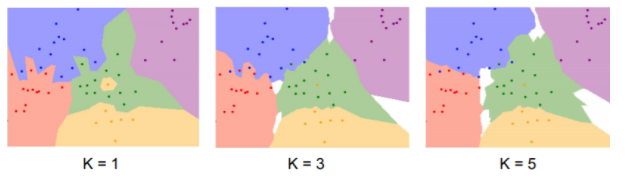
3. 가장 가까운 train 데이터 외에도 접근
4. 더 많은 이웃들이 투표에 참여하면 각종 잡음들에 강인해 집니다.
=> 하이퍼 파라미터
어떤 distance를, K값을 몇으로 해야 좋을지 고민 > 주어진 환경에서 실험 후 최적의 값 설정
> 반복적인 실험
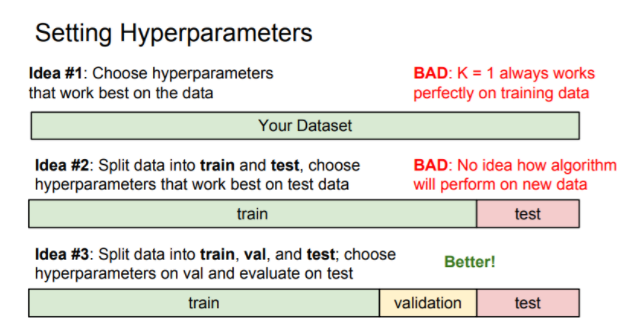
1) 100% 훈련 셋
2) 훈련 셋 + 실험 셋
3) 훈련 셋 + 검증 셋 + 실험 셋
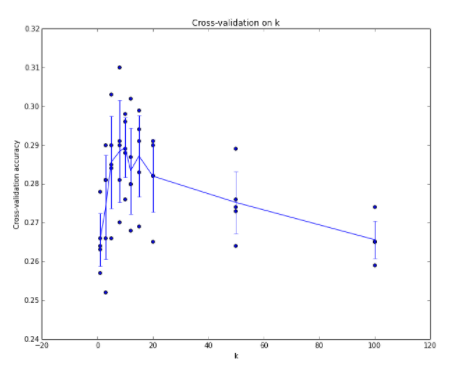
> Cross-validation
1) 훈련 셋의 양이 적을 경우
2) 하이퍼 파라미터 추가
=> NN 문제점
1) 학습 시간에 비해 테스트 시간이 매우 큼 + 비교, 거리 측정 등, 이미지 데이터에 성능 부적합
2) 거리 예측의 난이도

이미지 매우 고차원 물체 -> 사람의 눈 VS 픽셀 값의 거리 완전히 다른 이미지를 동일하게 분류
3) 차원의 저주
고차원으로 갈 수 록 공간을 조밀하게 메우기 위한 데이터의 기하급수적 증가 -> 불가
4) Color 영향
- Linear classifier
1. 선형? 선형적 증가?
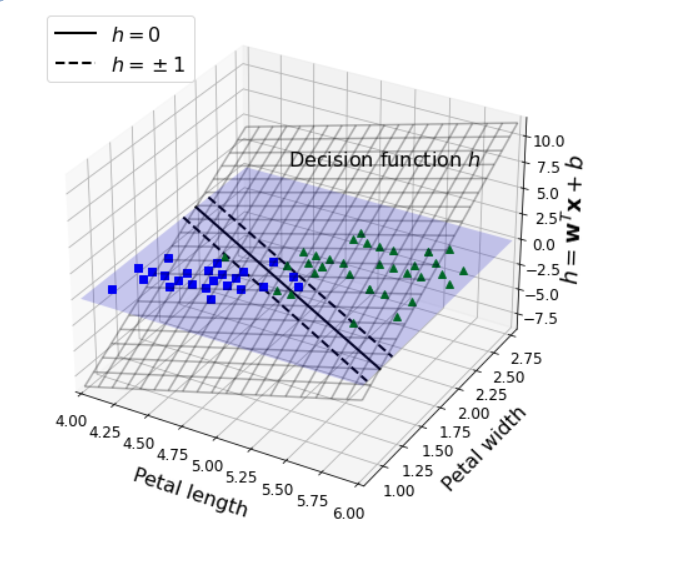
2. Parametric model
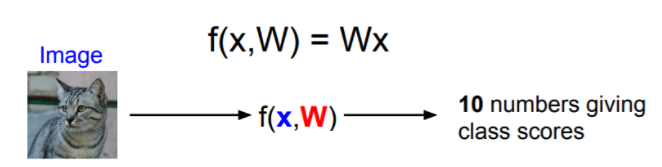
3. bias term
4. score function
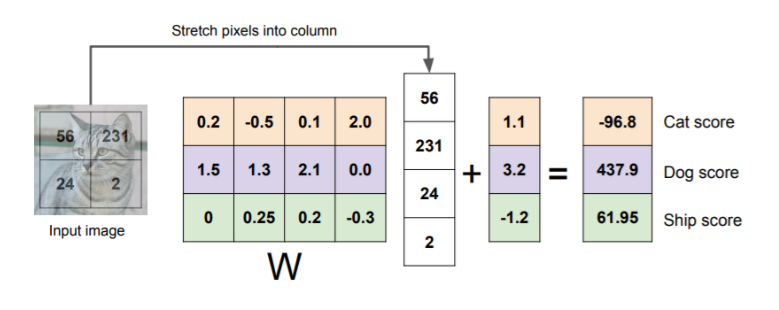
=> 문제
1) Data-driver approach에서 train 데이터의 사이즈가 평가 속도에 미치는 영향은 어떠한가?
2) 학습시킨 NN 모델에 test 셋이 아닌 train 셋을 넣고 평가하면 결과는? + 동일한 조건으로 KNN에 적용하면?
3) NN에서 이미지가 총 N개라면 계산 시간은?
- 질문 리스트
1. 고차원 공간의 좌표축은 무엇을 의미하나?
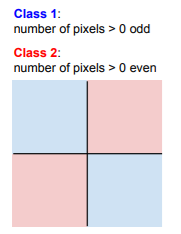
-> 강의 마무리 부분 고차원 공간 내용

-> 차원 축소 그래프
2) L1과 L2 distance에서 사람의 영향을 받음의 의미
[CS231n] 2강. L1 & L2 distance
2강 내용 중 Nearest Neighbor와 K-Nearest Neighbor 모델에서 L1, L2 distance 에 대한 내용이 나온다. 테스트데이터와 학습데이터 사이의 오차를 구하는 함수인데, 상황에 따라서 서로 다른 distance공식을 사용
bookandmed.tistory.com
-> 거리를 왜 알아야 하나 : 일종의 유사도 개념으로 거리가 가까울수록 특성들이 비슷하다는 의미
L1
p =(3, 1, -3), q = (5, 0, 7)
|3-5| + |1-0| + |-3 -7| = 2 + 1 + 10 = 13 = l1L2
p = (1, 2), q = (3, 4)
√((3-1)^2+(4-2)^2) = 2.828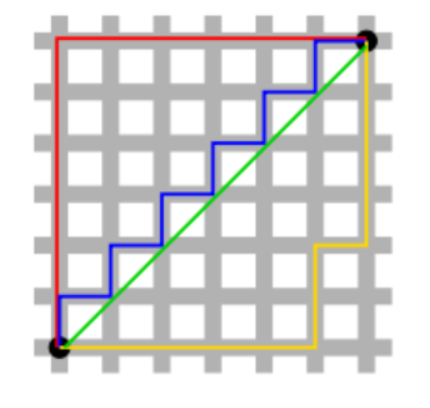
1) L1 : 좌표를 일일이 세어 일정한 거리를 구합니다.
2) L2 : 좌표를 가로질러 최단 거리를 구합니다.
'[AI] > [네이버 BoostCamp | 학습기록]' 카테고리의 다른 글
| [22.02.11] 딥러닝 PART. 밑바닥부터 시작하는 딥러닝 발제 (0) | 2022.12.27 |
|---|---|
| [22.04.27] 딥러닝 PART.CS231n 6강 (0) | 2022.12.27 |
| NLP PART.문장 유사도 (0) | 2022.12.26 |
| NLP PART.단어의 표현 (0) | 2022.12.24 |
| NLP PART.언어 모델 (0) | 2022.12.19 |



