
개발자로 후회없는 삶 살기
NLP PART.언어 모델 본문
서론
※ 이 포스트는 다음 교재의 학습이 목적임을 밝힙니다.
https://wikidocs.net/book/2155
딥 러닝을 이용한 자연어 처리 입문
많은 분들의 피드백으로 수년간 보완된 입문자를 위한 딥 러닝 자연어 처리 교재 E-book입니다. 오프라인 출판물 기준으로 코드 포함 **약 1,000 페이지 이상의 분량*…
wikidocs.net
이번 장에서는 통계 기반 전통 언어 모델을 배웁니다.
-> 전체 코드
GitHub - SangBeom-Hahn/NLP
Contribute to SangBeom-Hahn/NLP development by creating an account on GitHub.
github.com
본론
- 언어 모델이란?
단어 시퀀스(문장)에 확률을 할당하는 모델입니다. 어떤 문장이 있을 때 이 문장은 적절해, 이 문장은 말이 "안 돼"라고 모델이 사람처럼 정확히 판단할 수 있다면 기계의 자연어 처리의 성능이 뛰어나다 할 수 있습니다. 이번 장에서는 통계 기반 전통 언어 모델을 배웁니다.
통계 기반 언어 모델은 실제 사용하기에는 한계가 있고 요즘 들어 인공 신경망이 그러한 한계를 많이 해결해주면서 통계 기반 언어 모델은 많이 사용 용도가 줄었습니다. 하지만 그럼에도 통계 기반 방법론에 대한 이해는 언어 모델에 대한 전체적인 시야를 갖는 일에 도움이 됩니다.
1. 언어 모델이란?
언어 모델(Language Model, LM)은 언어라는 현상을 모델링하고자 단어 시퀀스(문장)에 확률을 할당(assign)하는 모델 > 언어 모델을 만드는 방법은 2가지로 1. 통계, 2. 인공 신경망입니다. 최근 핫한 자연어 처리의 기술인 GPT나 BERT 또한 인공 신경망 언어 모델의 개념을 사용하여 만들어졌습니다.
> 언어모델은 단어 시퀀스에 확률을 할당한다고 했는데 이를 쉽게 말하면 ★가장 자연스러운 단어 시퀀스를 찾아내는 모델입니다.★ 언어 모델이 이전 단어들이 주어졌을 때 다음 단어를 예측하도록 하는 것입니다. (좁은 의미에서의 언어 모델로 가장 기본이자 반드시 갖춰야 하는 기능입니다.)/
> 언어 모델링은 주어진 단어들로부터 아직 모르는 단어를 예측하는 작업을 말합니다. 즉, 이전 단어로 다음 단어를 예측하는 일입니다.
2. 단어 시퀀스의 확률 할당
단어 시퀀스에 확률을 할당하는 일이 왜 필요할까요?
ex) 기계번역 : 언어 모델은 두 문장을 비교하여 좌측의 문장의 확률이 더 높다고 판단합니다.

ex) 오타 교정 : 언어 모델은 두 문장을 비교하여 좌측의 문장의 확률이 더 높다고 판단합니다.

ex) 음성 인식 : 언어 모델은 두 문장을 비교하여 우측의 문장의 확률이 더 높다고 판단합니다.

3. 이전 단어로 다음 단어 예측하기
이를 조건부 확률로 표현하면 n-1개의 단어가 나열된 상태에서 n번째 단어의 확률입니다.
ex) 비행기를 타려고 공항에 갔는데 지각을 하는 바람에 비행기를 [?]이라는 문장이 있을 때 사람은 "놓쳤다"라고 예상할 수 있습니다.
> ★ 이게 매우 중요한 게 이것의 원리는 사람의 지식에 기반하여 나올 수 있는 여러 단어들을 후보에 놓고 놓쳤다는 단어가 나올 확률이 가장 높다고 판단하였기 때문입니다. 기계도 비슷합니다.
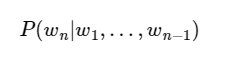
★"앞에 어떤 단어들이 나왔는지 고려"하여 "후보가 될 수 있는 여러 단어들에 대해서 확률을 예측해보고 가장 높은 확률을 가진 단어"★를 선택합니다.(그러면 앞에 단어들을 봐서 나올 수 있는 단어들을 추리고, 그 추린 단어들의 확률을 예측해서 가장 높은 확률의 단어를 뽑는 건가?)
+ 검색 엔진이 입력된 단어들의 나열에 대해서 다음 단어를 예측하는 언어 모델을 사용합니다.

- 통계적 언어 모델(statistical language model : SLM)
앞에 나온 단어가 이러할 때 뒤에 나올 확률입니다.
1. 문장에 대한 확률

문장의 확률은 각 단어들이 이전 단어가 주어졌을 때 "다음 단어로 등장할 확률의 곱"입니다. 문장의 확률을 구하기 위해서 각 단어에 대한 예측 확률들을 곱합니다.
2. 카운트 기반의 접근
문장의 확률을 구하기 위해서 다음 단어에 대한 예측 확률을 모두 곱한다는 것은 알았습니다. 그렇다면 ★SLM은 이전 단어로부터 다음 단어에 대한 확률은 어떻게 구할까요? 카운트에 기반하여 확률을 계산합니다.★
ex) An adorable little boy가 나왔을 때, is가 나올 확률은 P(is|An adorable little boy)입니다.

그 확률은 (사진과 같습니다.) 예를 들어 기계가 학습한 코퍼스 데이터에서 An adorable little boy가 100번 등장했는데 그다음에 is가 등장한 경우는 30번이라고 합시다. 이 경우 P(is|An adorable little boy)는 30%입니다. 문장에 대한 확률은 이렇게 전체 문장에 대해 앞에 단어가 나왔을 때 다음 단어로 등장할 확률의 곱이 되겠습니다.
> ★ 문장의 확률은 모르겠고 난 지금 이전 단어가 있을 때 다음 단어를 예측할 건데 아까 위에서 앞 단어들을 봐서 나올 수 있는 단어들을 추리고 그 추린 단어들의 확률을 예측해서 가장 높은 확률의 단어를 뽑는 건가?라고 했는데 이제 알 수 있는 사실은 다음 단어를 예측할 때 분모 분자의 확률을 코퍼스의 모든 단어들 대상으로 계산해서 가장 높은 단어를 선택한다는 것입니다.
3. 카운트 기반 접근의 한계
카운트 기반으로 접근하려고 한다면 갖고 있는 코퍼스(corpus). 즉, 기계가 훈련하는 데이터는 정말 방대한 양이 필요합니다.
예를 들어 위와 같이 P(is|An adorable little boy)를 구하는 경우에서 기계가 훈련한 코퍼스에 An adorable little boy is라는 단어 시퀀스가 없었다면 이 단어 시퀀스에 대한 확률은 0이 됩니다. 또는 An adorable little boy라는 단어 시퀀스가 없었다면 분모가 0이 되어 확률은 정의되지 않습니다.
> 그렇다면 코퍼스에 단어 시퀀스가 없다고 해서 이 확률을 0 또는 정의되지 않는 확률이라고 하는 것이 정확한 모델링 방법일까요? 아닙니다. 현실에선 An adorable little boy is 라는 단어 시퀀스가 존재하고 또 문법에도 적합합니다. 이와 같이 충분한 데이터를 관측하지 못하여 언어를 정확히 모델링하지 못하는 문제를 희소 문제라고 합니다.
+ 결국 이러한 한계로 인해 언어 모델의 트렌드는 통계적 언어 모델에서 인공 신경망 언어 모델로 넘어가게 됩니다.
- N-gram 언어 모델
n-gram 언어 모델은 여전히 카운트에 기반한 통계적 접근을 사용하고 있으므로 SLM의 일종입니다. 하지만, 앞서 배운 언어 모델과는 달리 이전에 등장한 모든 단어를 고려하는 것이 아니라 일부 단어만 고려하는 접근 방법을 사용합니다.
> SLM의 한계는 훈련 코퍼스에 확률을 계산하고 싶은 단어가 없을 수 있다는 점으로 확률을 계산하고 싶은 문장이 길어질수록 갖고 있는 코퍼스에서 그 문장이 존재하지 않을 가능성이 높다는 것입니다. 그런데 N-gram은 참고하는 단어들을 줄여서 카운트할 수 있을 가능성을 높이겠다는 것입니다.

> An adorable little boy가 나왔을 때 is가 나올 확률을 그냥 boy가 나왔을 때 is가 나올 확률로 생각해보는 건 어떨까?입니다. 갖고 있는 코퍼스에 An adorable little boy is가 있을 가능성보다는 boy is라는 더 짧은 단어 시퀀스가 존재할 가능성이 더 높습니다. 이제는 다음으로 나올 단어의 확률을 구하고자 기준 단어의 앞 단어를 전부 포함해서 카운트하는 것이 아니라, 앞 단어 중 임의의 개수만 포함해서 카운트하여 근사하자는 것입니다.
1) N-gram
이때 임의의 개수를 정하기 위한 기준을 위해 사용하는 것이 n-gram입니다. n-gram은 n개의 연속적인 단어 나열을 의미합니다. 갖고 있는 코퍼스에서 n개의 단어 뭉치 단위로 끊어서 이를 하나의 토큰으로 간주합니다.
ex) An adorable little boy is spreading smiles에서의 각 n에 대해서 n-gram은 그림과 같습니다.

-> ngram을 이용한 언어 모델 설계

다음에 나올 단어의 예측은 오진 n-1개의 단어에만 의존합니다. ex) 4-gram에서 spreading 다음에 올 단어를 예측하는 것은 boy is spreading 3개의 단어만을 고려합니다. (3개만 써서 다음 나올 단어의 확률을 계산하는 것입니다. 그림)
> ★ 만약 갖고 있는 코퍼스에서 boy is spreading가 1000번 등장했다고 하자 그리고 boy is spreading insults 500번 등장하고 boy is spreading smiles가 200번 등장했다고 하면 boy is spreading 다음에 insults가 등장할 확률은 50%이며, smiles가 등장할 확률은 20%입니다. 확률에 따라 우리는 boy is spreading 다음에는 insults가 더 맞다고 판단합니다.
+ 강화 : 코퍼스에서 boy is spreading 뒤에 왔던 단어들의 확률을 전부 계산해서 그중 가장 높은 단어 채택!
-> 한계
1) 희소 문제가 여전히 존재합니다.
2) n을 선택하는 것은 trade-off이다. 크게 하면 희소문제가 심각해짐, 작게 하면 현실과 멀어짐 n은 최대 5를 넘게 잡아서는 안된다고 권장합니다.
- 한국어에서의 언어 모델
영어에 비해 한국어는 다음 단어를 예측하기가 훨씬 까다롭습니다. 이유를 알아보겠습니다.
1. 한국어는 어순이 중요하지 않습니다. 따라서 다음 단어를 예측할 때 어떤 단어든 등장할 수 있습니다.
ex)
1) 나는 운동을 합니다 체육관에서.
2) 나는 체육관에서 운동을 합니다.
3) 체육관에서 운동을 합니다.
4) 나는 운동을 체육관에서 합니다.
예제에서 4개의 문장은 전부 의미가 통합니다. 이렇게 단어 순서를 뒤죽박죽으로 바꾸어도 한국어는 의미가 전달되어 다음 단어를 예측하기가 어렵습니다.
2. 교착어입니다. 어절 단위로 토큰화할 경우 문장에서 발생가능한 단어의 수가 굉장히 늘어납니다. 조사가 있는데 '그녀'라는 단어 하나만 해도 그녀가, 그녀를, 그녀의, 그녀와, 그녀로, 그녀께서, 그녀처럼 등과 같이 다양한 경우가 존재합니다. 따라서 한국어에서는 토큰화를 통해 접사나 조사 등을 분리하는 것이 매우 중요합니다.
3. 한국어는 띄어쓰기가 제대로 지켜지지 않습니다. 띄어쓰기를 하지 않아도 의미가 전달되며, 제대로 지켜지지 않는 경우가 많습니다. 토큰이 제대로 분리되지 않은 채 훈련 데이터로 사용한다면 언어 모델을 제대로 동작하지 않습니다.
★ perplexity(PPL) ★
두 모델의 성능을 비교하고자, 일일이 모델들에 대해서 실제 작업을 시켜보고 정확도를 비교하는 작업은 공수가 너무 많이 드는 작업입니다. 모델이 두 개보다 그 이상의 수라면 시간이 배로 늘어납니다. 따라서 더 간단한 식이 자신의 성능을 수치화하여 결과를 내놓는 perplexity입니다.
PPL은 언어 모델을 평가하기 위한 평가 지표입니다. 수치가 낮을수록 언어 모델의 성능이 좋다는 것을 의미합니다. PPL은 이 언어 모델이 특정 시점에서 평균적으로 몇 개의 선택지를 가지고 고민하고 있는지를 의미합니다.

ex) 언어 모델에 어떤 테스트 데이터를 주고 측정했더니 PPL이 10이 나왔다고 해봅시다. 그렇다면 해당 언어 모델은 테스트 데이터에 대해서 다음 단어를 예측하는 모든 시점(time step)마다 평균 10개의 단어를 가지고 어떤 것이 정답인지 고민하고 있다고 볼 수 있습니다. PPL이 더 낮은 언어 모델이 성능이 좋습니다.
※ 부록 > 조건부 확률이란?
A = 학생이 남학생인 사건/ D = 학생이 고등학생인 사건 / P(A ∩ D) : 학생을 뽑았을 때, 고등학생이면서 남학생일 확률 / P(A|D) : 고등학생 중 한 명을 뽑았는데 남학생일 확률
'[AI] > [네이버 BoostCamp | 학습기록]' 카테고리의 다른 글
| NLP PART.문장 유사도 (0) | 2022.12.26 |
|---|---|
| NLP PART.단어의 표현 (0) | 2022.12.24 |
| NLP PART.텍스트 전처리2 (0) | 2022.12.19 |
| NLP PART.텍스트 전처리 (0) | 2022.12.14 |
| NLP PART.BERT, GPT (0) | 2022.12.09 |



