
개발자로 후회없는 삶 살기
NLP PART.BERT, GPT 본문
서론
※ 이 포스트는 다음 강의의 학습이 목표임을 밝힙니다.
https://www.youtube.com/@mcodeM/playlists
메타코드M
메타코드에서 SKY출신 / AI기업 현직자에게 무료로 코딩을 배우세요 서울대 , 카이스트, 고려대 + 현업 개발자들의 핵심 코딩/데이터 강의 [비지니스 협업은 메일로 연락주세요 : support@mcode.co.kr] -
www.youtube.com
본론
BERT(bidirectional encoder rep transformer= 양방향성을 가지고 있습니다. 트랜스포머의 인코딩 부분을 사용합니다.) & GPT(Generative pretrained transformer = 이름대로 만들어내는 구조입니다.)
- bert
transformer의 인코더 부분을 사용합니다.
-> 트포의 인코더 구조
인풋이 들어오면 > 임베딩 > rnn 대신에 position encoding > self attention > feed forward를 하는 모델입니다.
=> BERT의 특징

1. ★대용량 corpus data로 일단 모델을 학습시킵니다.★ > w2v을 하는 것은 종류기 굉장히 많았는데 그 중에서 bert를 사용하는 것입니다. > w2v 하는 bert 모델을 학습하는 것입니다. > ★그 후에 task에 알맞게 전이 학습을 합니다.★
2. 양방향 언어 모델입니다. > 추론하고자 하는 단어는 앞에서부터도 참조할 수 있고 뒤에서부터도 참조할 수 있습니다.

> bert도 워드 임베딩 방법입니다. 근데 굳이 glove, cbow 등을 놔두고 bert를 사용하나요? glove나 다른 w2v는 학습을 시키고 task를 하려면 lstm, seq2seq 등의 모델을 차용을 했었어야 했습니다. > 근데 BERT는 lstm이나 1d cnn등을 테스크에 사용할 필요 없이 bert 위에다가 ann만 얹어서 task를 수행할 수 있고 성능이 잘 나옵니다. 이게 BERT를 쓰는 이유 중 하나입니다.
=> BERT의 구조
대용량 corpus로 학습을 한 다음에 학습한 모델을 가져와서 task에 알맞게 fine tuning을 합니다. 보통 fine tuning를 할 때 사전학습한 대용량 신경망 뒤에 fcn을 하나 붙이는 게 fine tuning을 하는 방식입니다. fine tuning이 전이 학습의 한 방법이기도 합니다. fine tuning을 할 때 사전학습한 모델에 tcn을 하나 붙이고 재학습을 할 때는 사전 학습 모델은 freezing을 시키고 fcn만 학습을 시킵니다. bert를 fine tuning할 때 사전 학습을 해서 BERT의 가중치를 다 맞춘 다음에 freezing을 시키고 나중에 task에 맞춰서 fine tuning를 합니다.
-> 내부 구조

문장 A, B가 들어갑니다. ( 물론이 A, B는 기본적인 텍스트 전처리 + 임베딩은 되어있습니다. ) > A랑 B를 기본적으로 한 번에 넣습니다. 그것들이 인코딩을 거쳐서 나오는데 NSP와 MLM이 나오고 이 두 가지가 BERT에서 사전 훈련을 하는 대상입니다. > 두 개의 문장이 인풋으로 들어가서 두 개의 목표(따라서 loss도 두 개), 두개의 목적함수를 기울기 하강으로 학습시키게 됩니다.
> 위 과정으로 내부 bert의 가중치들을 다 학습시킨 다음에 나중에 fine tuning에서는 위에 layer를 쌓거나 BERT의 윗단를 남겨뒀다가 fine tuning 시에 남겨둔 w들만 학습시킵니다.
=> 학습

1) mlm(masked language model) : 마스킹은 가리는 것입니다. > 가려서 학습을 하겠다는 것입니다.(비지도 학습!) > 단어 레벨에서 학습입니다.
2) nsp(next sentence prediction) : 문장 2개 A, B이 서로 연결되어 있느냐를 묻습니다. 두 문장을 넣었을 때 두 문장이 어색함이 없느냐를 보는 것입니다. (레이블링을 해서 지도학습을 합니다.) > 문장 단위로 학습합니다.
> 두 가지가 동시에 학습이 됩니다.
1. mlm

예를들면 i love ㅁ(빈칸) for always에서 "ㅁ을 컴퓨터에게 맞춰봐라"라고 하는 것입니다. 입력이 두 개라고 했으니 i love ㅁ for always + its so ㅁ today를 넣고 ㅁ가 하나씩 마스킹이 되어있는 것입니다. bert는 입력이 그대로 병렬로 z임베딩 결과로 나오는데 MASKING이 안 된 건 그대로 임베딩 되어서 나오는데 ㅁ은 맞춰봐라라는 것입니다. ㅁ에 들어갈 단어가 무엇인지 맞춰봐라! 하고 정답을 알려줍니다. 이렇게 비지도 학습을 합니다.
> 그래서 단어를 임의로 15퍼 MASKING하고 이걸 맞춰봐라고 인공신경망에게 요구하는 것입니다. > 전체 단어가 아니고 두 개의 문장에서 15퍼를 MASKING하고 맞춰봐라고 하는 것입니다.
ex) 어제 정말 재미있게 놀았어

재미있게가 MASK인 경우입니다. 인풋이 "어제 정말 MASK 놀았어" 이렇게 됩니다. > 그러면 트랜스포머 인코더에서는 self-attention이 일어납니다. > 4개의 단어가 서로를 참조를 해서 입력 단어가 Q가 되면 4개의 문장 내(self) 단어에게 참조를 해서 인코더를 다 거치고 fcn을 거쳐서 정답을 내놓습니다. (역시 분류이니 vocab_size의 출력 사이즈의 fcn 이겠습니다)
> 여기는 무엇일 거야!라고 BERT가 예측하면 '재미있게'(실제 정답)와 얼마나 차이가 나는지 로스를 계산해서 기울기 하강을 하고 역전파 시키는 게 mlm의 전체 학습 방법입니다. > MASK가 Q고 k가 단어 전체입니다. > v는 똑같이 단어 전체입니다.
> 여기서 양방향성이란? BERT는 인코딩이 들어가면 self-attention을 하니 모든 단어를 참조합니다. 그래서 아래로도 위로도 갈 수 있습니다. 재미있게를 파악할 때 어제 정말도 참고하지만 놀았어도 참조합니다.
-> 강화

아까 입력 단어의 15퍼를 MASKING 한다고 했는데 15퍼 중에 80을 MASKING하고 남은 10은 MASKING 하지 않고 다른 임의의 단어로 바꿉니다. ex) 수행한다를 맑다로 대신 넣습니다. > 10퍼는 그냥 원래 단어를 그래도 두고 원래 단어를 한 번 추론해 봐! 이런 것입니다.
2. nsp

두 개의 문장이 주어졌을 때 두 문장이 서로 이어지느냐?를 물어서 학습을 합니다.
A : i studied hard today, B : it is hard to predict stock, Label : NO > 이렇게 지도 학습으로 인간이 라벨을 합니다. 이 문장을 BERT에 두 문장을 짚어 넣고 nsp를 풉니다. > 그러면 지도학습 2진 분류 문제가 됩니다.
=> bert 구조
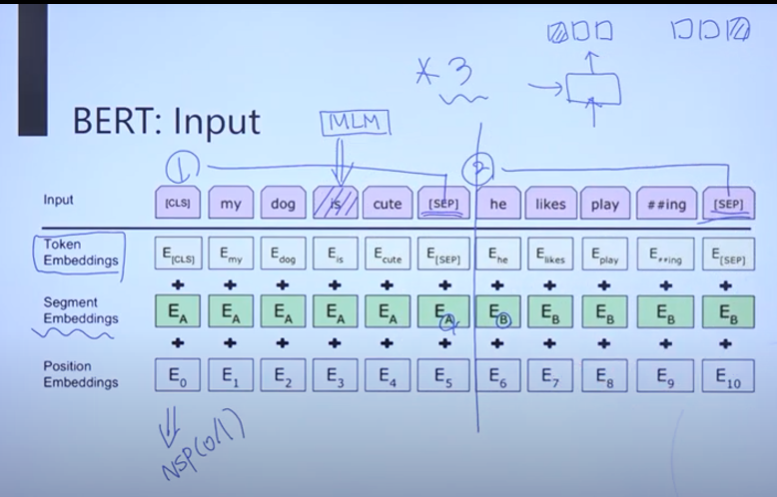
1) 입력 : BERT에는 문장 2개 전체가 입력으로 들어갑니다. > 문장이 두 개 들어간다고 했으니 sep로 문장을 구분해 줍니다. > 입력이 들어가면 임베딩 layer를 거쳐야 하는데 (여느 모델처럼 인코딩에 넣기 전에 임베딩을 한다) 3개의 임베딩을 시킵니다. > 3개의 합으로 최종 임베딩 결정합니다.
① token 임베딩 : 그냥 토큰화하는 것입니다.
② segment 임베딩 : 문장 경계로 라벨이 (A, B) 바뀝니다. 문장 단위로 임베딩을 하는 것입니다.
③ position 임베딩 : 앞쪽에는 앞에 단어에 가중치를 많이 두고 뒷쪽에는 뒤에 단어에 가중치를 많이 두어 단어의 pos을 결정을 해주는 것입니다.
> 3개의 임베딩 결과를 합쳐서 BERT의 최종 임베딩 인풋이 됩니다. 이 인풋을 가지고 트랜스포머 인코더에 넣습니다.(★ 입력에 마스킹을 하고 3개의 임베딩을 해서 인코더에 넣어서 인코더의 출력 결과가 마스킹 한 단어를 맞추도록 하면서 학습이 됩니다. ★) > nsp는 인코더 다 끝나고 합니다.
=> fine tuning

1) 인풋이 문장 두 개 sep 되어습니다. > MASKING하고 임베딩하고 트랜스포머 인코더를 통과 > 마지막 layer만 fine tuning 시켜서 task에 사용합니다. sentence pair classification task로 nsp와 동일한 task로 새로운 입력 두 문장을 줬을 때 pair니?를 맞추는 task입니다.

2) single sentence(-> 얘는 문장이 하나만 들어갑니다. 두 번째 문장은 다 MASK를 시켜줍니다.) : 입력 문장이 어떤 뉘앙스를 띠고 있느냐, 어떤 분야에 속하느냐, 어떤 감정을 담고 있느냐, ( 1), 2) bert의 분류 문제는 BERT를 학습시키고 마지막 레이어만 fine tuning 시켜서 task에 사용합니다.)

3) tagging task : 한 문장의 각 단어가 있으면 각 단어의 품사를 태깅해줍니다. > 모든 출력 층에서 다 레이블이 나옵니다. 1), 2)는 c가 cls 자리에 있었는데 얘는 각 출력 layer에서 전부 다 출력이 나오고 거기서 나온 출력과 정답 품사의 차이로 학습을 합니다.
★ 깨달음 : fine tuning 이미지를 보면 마지막 층은 cls 자리에 C라는 클래스가 있습니다. 학습할 때 여기서 모델 예측이 나온다 거기서 나온 예측과 정답의 차이로 학습합니다. + BERT는 fcn을 추가하지 않고 마지막 층을 학습하지 남겨두었다가 fine tuning에 이용한다고 합니다.
-> 정정!! : 확인이 필요한 부분입니다. 예측은 mask한 부분에서 나올 수도 있고 C는 fine tuning 할 때 새로 쌓은 층일 수도 있어서 공부가 더 필요합니다.
- GPT

양방향이 아닙니다. i love ㅁ very much가 아까는 앞에서도 보고 뒤에서도 본다고 했는데 gpt는 무조건 앞만 보고 달립니다. ㅁ을 예측을 할 때 앞만 보고 예측합니다. gpt는 트랜스포머의 디코더 구조만 사용합니다. 어떻게 앞만 보냐? masked self-attention 구조를 사용하여 뒤에를 다 가려버립니다.
=> 구조

입력을 3개의 임베딩을 하고 mask 셀프 어텐션을 거치고 feed forward 거칩니다.
'[AI] > [네이버 BoostCamp | 학습기록]' 카테고리의 다른 글
| NLP PART.텍스트 전처리2 (0) | 2022.12.19 |
|---|---|
| NLP PART.텍스트 전처리 (0) | 2022.12.14 |
| NLP PART.Attention 메커니즘 (0) | 2022.12.06 |
| NLP PART.RNN, Seq2Seq 구조 (0) | 2022.12.03 |
| NLP PART.텍스트 마이닝 이론 (0) | 2022.12.01 |



