
개발자로 후회없는 삶 살기
NLP PART.텍스트 전처리 본문
서론
※ 이 포스트는 다음 교재의 학습이 목적임을 밝힙니다.
https://wikidocs.net/book/2155
딥 러닝을 이용한 자연어 처리 입문
많은 분들의 피드백으로 수년간 보완된 입문자를 위한 딥 러닝 자연어 처리 교재 E-book입니다. 오프라인 출판물 기준으로 코드 포함 **약 1,000 페이지 이상의 분량*…
wikidocs.net
-> 전체 코드
https://github.com/SangBeom-Hahn/NLP/blob/main/nlp_book/1_nlp_%EC%A4%80%EB%B9%84.ipynb
GitHub - SangBeom-Hahn/NLP
Contribute to SangBeom-Hahn/NLP development by creating an account on GitHub.
github.com
- 다룰 내용
1. 토큰화
2. 토큰화에서 개발자의 직관
3. 어간 추출과 표제어 추출
4. 불용어 처리
5. 정규표현식
본론
- 텍스트 전처리
풀고자 하는 용도에 맞게 텍스트를 사전에 처리하는 작업입니다. task에 맞게 전처리하지 않으면 제대로 동작하지 않습니다.
1. 토큰화
1) 단어 토큰화
토큰의 기준을 단어로 하는 경우로 단어 단위 외에도 의미를 갖는 문자열로 간주되기도 합니다.( ex] 한국어의 어간, 문장 등)

Time is a illusion.을 토큰화 해보면 "Time", "is", "an", "illustion" 결과가 나옵니다. 이 경우는 토큰화 작업이 굉장히 간단합니다. 구두점을 지우고 띄어쓰기를 기준으로 잘라냅니다.
※ 구두점 : 마침표, 컴마, 물음표 등
하지만 보통 토큰화 작업은 단순히 구두점이나 특수 문자를 전부 제거하는 정제 작업을 수행하는 것만으로 해결되지 않습니다. 구두점이나 특수문자를 전부 제거하면 토큰이 의미를 잃어버리는 경우가 발생하기도 합니다.
2) 토큰화 중 생기는 선택의 순간
토큰화를 하다보면 토큰화의 기준을 생각해봐야 하는 경우가 발생합니다. (개발자의 직관이 필요한 부분!)

ex) 영어권 언어의 '(어포스트로피)가 들어가 있는 단어는 어떻게 토큰으로 분류해야 하는지에 대한 선택의 문제!
-> Don't be fooled by the dark sounding name, Mr. Jone's Orphanage is as cheery as cheery goes for a pastry shop.
다음 문장에서 Don't와 Jone's는 어떻게 토큰화할까요?
# 코드
print("word_tokenizer : ", word_tokenize("Don't be fooled by the dark sounding name, Mr. Jone's Orphanage is as cheery as cheery goes for a pastry shop"))
# 결과
word_tokenizer : ['Do', "n't", 'be', 'fooled', 'by', 'the', 'dark', 'sounding', 'name', ',', 'Mr.', 'Jone', "'s", 'Orphanage', 'is', 'as', 'cheery', 'as', 'cheery', 'goes', 'for', 'a', 'pastry', 'shop']
> tokenizer마다 다르게 토큰화하더라 word_tokenize는 'Do', "n't"로 분리하였습니다. 반면 'Jone', "'s" 존은 이렇게 분리했습니다.
WordPunctTokenizer는 구두점을 별도로 분류하는 특징을 갖고 있기 때문에 앞의 tokenizer와 달리 Don, ', t로 분리하였습니다.
#코드
print("wordpunc_tokenizer : ", WordPunctTokenizer().tokenize("Don't be fooled by the dark sounding name, Mr. Jone's Orphanage is as cheery as cheery goes for a pastry shop"))
# 결과
wordpunc_tokenizer : ['Don', "'", 't', 'be', 'fooled', 'by', 'the', 'dark', 'sounding', 'name', ',', 'Mr', '.', 'Jone', "'", 's', 'Orphanage', 'is', 'as', 'cheery', 'as', 'cheery', 'goes', 'for', 'a', 'pastry', 'shop']
-> WordPunctTokenizer 구두점을 별도로 분리

케라스의 text_to_word_sequence는 기본적으로 모든 알파벳을 소문자로 바꾸면서 구두점을 제거합니다. 하지만 dont의 '인 아포스트로피는 보전하는 것을 알 수 있습니다. (Don't의 대문자를 소문자로 바꿉니다.)
# 코드
print("text_to_word_sequence : ", text_to_word_sequence("Don't be fooled by the dark sounding name, Mr. Jone's Orphanage is as cheery as cheery goes for a pastry shop"))
# 결과
text_to_word_sequence : ["don't", 'be', 'fooled', 'by', 'the', 'dark', 'sounding', 'name', 'mr', "jone's", 'orphanage', 'is', 'as', 'cheery', 'as', 'cheery', 'goes', 'for', 'a', 'pastry', 'shop']
-> keras의 구두점 제거

3) 토큰화에서 고려해야 할 사항
토큰화 작업을 단순히 코퍼스에서 구두점을 제외하고 공백 기준으로 잘라내는 작업이라고 간주할 수 없습니다. 이보다 섬세한 알고리즘이 필요합니다.
① 구두점이나 특수 문자를 단순 제외해서는 안 된다.
코퍼스에서 정제 작업을 진행하다보면 구두점조차도 하나의 토큰으로 분류하기도 합니다. 가장 기본적인 예로 마침표 같은 경우는 문장의 경계를 알 수 있으므로 제외하지 않을 수 있습니다.
또한 단어 자체에 구두점을 갖고 있는 경우도 있는데 AT&T, Ph.D 등과 $45.55, 2022/10 등을 봐도 구두점이나 특수 문자를 단순 제외해서는 안됩니다.
② 줄임말과 단어 내에 띄어쓰기가 있는 경우
줄임말은 i'm은 i am으로 인식할 수 있어야 하고, 단어 내 띄어쓰기는 rock 'n' roll을 보면 띄어쓰기가 있는 경우도 하나의 토큰으로 인식할 수 있어야 합니다.
③ 표준 토큰화 예제 표준으로 쓰이는 treebank의 규칙을 보자
# 트리뱅크 표준
from nltk.tokenize import TreebankWordTokenizer
tokenizer = TreebankWordTokenizer()
text = "Starting a home-based restaurant may be an ideal. it doesn't have a food chain or restaurant of their own."
print(tokenizer.tokenize(text))
# 결과
['Starting', 'a', 'home-based', 'restaurant', 'may', 'be', 'an', 'ideal.', 'it', 'does', "n't", 'have', 'a', 'food', 'chain', 'or', 'restaurant', 'of', 'their', 'own', '.']
규칙1 : -로 구성된 단어는 하나로 유지
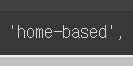
규칙2 : doens't와 같이 '로 접어(i'm 이런 거)가 함께하는 단어는 분리

4) 문장 토큰화
토큰의 단위가 문장일 경우입니다.

갖고 있는 코퍼스 내에서 문장단위로 구분하는 작업으로 갖고 있는 코퍼스가 정제되지 않은 상태라면 문장 단위로 구분이 필요합니다. 어떻게 할 수 있을까요?
직관적으로는 마침표나 물음표로 문장을 자르면 되지 않을까?라고 생각할수 있지만 꼭 그런 건 아닙니다. '!' 나 '?'는 문장의 구분을 위한 명확한 구분자이지만. 온점은 그렇지 않습니다.
"IP 111.111.111.111 서버에 들어가서 로그 파일을 저장해서 aaa@gmail.com으로 보내줘"라고 하면 이때 마침표를 기준으로 문장 토큰화를 하면 예상한 결과가 나오지 않을 수 있습니다.
★ 사용하는 코퍼스가 어떤 국적의 언어인지, 또는 해당 코퍼스 내에서 특수문자들이 어떻게 사용되고 있는지에 따라서 직접 규칙들을 정의해 볼 수 있겠습니다. -> 갖고 있는 코퍼스에 오타나 문장의 구성이 엉망이라면 정해 놓은 규칙이 소용없을 수 있기 때문입니다.
-> 중간 중간 온점이 등장하는 경우 -> nltk는 단순히 마침표를 구분자로 사용하지 않기 때문에 Ph.D. 를 잘 인식합니다.
# 중간 중간 온점이 등장하는 경우 -> nltk는 단순히 마침표를 구분자로 사용하지 않기 때문에 Ph.D.를 잘 인식한다.
text = "I am actively looking for Ph.D. students. and you are a Ph.D student."
print('문장 토큰화2 :',sent_tokenize(text))
# 결과
문장 토큰화2 : ['I am actively looking for Ph.D. students.', 'and you are a Ph.D student.']
한국어의 경우 문장 토큰화 도구가 따로 존재합니다.( kss(korean sentence splitter) )
-> 결과
import kss
text = '딥 러닝 자연어 처리가 재미있기는 합니다. 그런데 문제는 영어보다 한국어로 할 때 너무 어렵습니다. 이제 해보면 알걸요?'
print('한국어 문장 토큰화 :',kss.split_sentences(text))
# 결과
한국어 문장 토큰화 : ['딥 러닝 자연어 처리가 재미있기는 합니다.', '그런데 문제는 영어보다 한국어로 할 때 너무 어렵습니다.', '이제 해보면 알걸요?']
입력 : '딥 러닝 자연어 처리가 재미있기는 합니다. 그런데 문제는 영어보다 한국어로 할 때 너무 어렵습니다. 이제 해보면 알걸요?'
출력 : ['딥 러닝 자연어 처리가 재미있기는 합니다.', '그런데 문제는 영어보다 한국어로 할 때 너무 어렵습니다.', '이제 해보면 알걸요?']
5) 한국어 토큰화의 어려움
영어는 New York 같은 합성어나 he's같은 준말에 대한 예외 처리만 한다면, 띄어쓰기를 기준으로 토큰화를 수행해도 됩니다. 거의 대부분 단어 단위로 띄어쓰기가 이루어지기 때문에 띄어쓰기 토큰화와 단어 토큰화가 같습니다.
> 하지만 한국어는 영어와 달리 띄어쓰기만으로 하면 안됩니다. 한국어의 경우에는 띄어쓰기 단위가 되는 단위를 어절이라고 하는데 어절 토큰화는 지양됩니다.
> 그 이유는 한국어가 교착어이기 때문입니다. 교착어란 조사, 어미 등을 붙여서 말을 만드는 언어입니다.
① 교착어의 특성
한국어는 영어와 달리 조사가 존재합니다. '그'라는 단어 하나만 봐도 그가, 그에게, 그를 등 '그'라는 글자 뒤에 띄어쓰기 없이 바로 붙게 됩니다.
> 같은 단어임에도 서로 다른 조사가 붙어서 다른 단어로 인식이 되면 자연어 처리가 힘들고 번거로워지는 경우가 많습니다.
∴ 대부분의 한국어 NLP에서 조사는 분리해줘야합니다.
= 한국어는 어절이 독립적인 단어로 구성되는 것이 아니라 조사 등의 무언가가 붙어있는 경우가 많아서 이를 전부 분리해줘야 합니다.
★ 형태소 ★
한국어 토큰화에서는 형태소란 개념을 반드시 이해해야 합니다.!!
형태소란?
뜻을 가지는 가장 작은 말의 단위입니다. + 2가지 종류가 있습니다.
1) 자립 형태소 : 접사, 어미, 조사와 상관없이 자립하여 사용할 수 있는 형태소, 그 자체로 단어가 다.
2) 의존 형태소 : 다른 형태소와 결합하여 사용되는 형태소. 접사, 어미, 조사, 어간을 말한다.
ex) 에디가 책을 읽었다.

이 문장을 띄어쓰기 단위 토큰화를 한다면 ['에디가', '책을', '읽었다']의 결과입니다.
형태소 단위로 분해하면 자립 형태소 : 에디, 책/ 의존 형태소 : -가, -을, 읽-, -었, -다 > ★한국어에서는 어절 토큰화가 아니라 형태소 토큰화를 수행해야 합니다.★
② 한국어는 띄어쓰기가 영어보다 잘 지켜지지 않습니다.

사용하는 한국어 코퍼스가 뉴스 기사와 같이 띄어쓰기를 철저하게 지키려고 노력하는 글이라면 좋겠지만, 많은 경우에 띄어쓰기가 틀렸거나 지켜지지 않는 코퍼스가 많습니다. 영어권 언어와 비교하여 띄어쓰기가 어렵고 잘 지켜지지 않는 경향이 있습니다.
> 이유 : 한국어의 경우 띄어쓰기가 지켜지지 않아도 글을 쉽게 이해할 수 있는 언어입니다. 영어의 경우 띄어쓰기를 하지 않으면 알아보기 어려운 문장들이 생깁니다. 이는 언어적 특성의 차이입니다.
6) 품사 태깅
단어는 표기는 같지만 품사에 따라서 단어의 의미가 달라지기도 합니다. fly는 동사로는 날다지만 명사로는 파리입니다. 한국어에서도 못은 명사로는 고정하는 물건을 의미하지만 부사로서는 할 수 없다는 의미로 쓰입니다.
결국 단어의 의미를 제대로 파악하기 위해서는 해당 단어가 어떤 품사로 쓰였는지 보는 것이 주요 지표가 될 수도 있습니다.
# nltk에서는 treebank pos_tag라는 기준을 사용하여 품사를 태깅한다.
from nltk.tokenize import word_tokenize
from nltk.tag import pos_tag
text = "I am actively looking for Ph.D. students. and you are a Ph.D. student."
tokenized_sentence = word_tokenize(text)
# 결과
단어 토큰화 : ['I', 'am', 'actively', 'looking', 'for', 'Ph.D.', 'students', '.', 'and', 'you', 'are', 'a', 'Ph.D.', 'student', '.']
품사 태깅 : [('I', 'PRP'), ('am', 'VBP'), ('actively', 'RB'), ('looking', 'VBG'), ('for', 'IN'), ('Ph.D.', 'NNP'), ('students', 'NNS'), ('.', '.'), ('and', 'CC'), ('you', 'PRP'), ('are', 'VBP'), ('a', 'DT'), ('Ph.D.', 'NNP'), ('student', 'NN'), ('.', '.')]
영어 문장에 대해서 토큰화를 수행한 결과를 입력으로 품사 태깅을 수행했습니다.
PRP는 인칭 대명사, VBP는 동사, RB는 부사, VBG는 현재부사, IN은 전치사, NNP는 고유 명사, NNS는 복수형 명사, CC는 접속사, DT는 관사를 의미!
> 한국어 자연어 처리를 위해서는 KoNLPy라는 파이썬 패키지를 사용할 수 있습니다.
konlpy가 한국어 자연어 처리 패키지이고 여기서 다양한 기능을 제공합니다. 그중 형태소 분석기를 제공하는데 okt와 꼬꼬마를 해보겠습니다.

okt 형태소 분석기로 토큰화를 시도해본 예제입니다. 각각은 다음의 기능을 가지고 있습니다.

예제에서 형태소 추출과 품사 태깅 메서드의 결과를 보면 조사를 기본적으로 분리하고 있음을 확인할 수 있습니다.
> 각 형태소 분석기는 성능과 결과가 다르게 나오기 때문에, 형태소 분석기의 선택은 사용하고자 하는 필요 용도에 어떤 형태소 분석기가 가장 적절한지를 판단하고 사용해야 합니다.
2. 정제 및 정규화
토큰화 작업 전, 후에는 텍스트 데이터를 용도에 맞게 정제(cleaning) 및 정규화(normalization)하는 일이 항상 함께 합니다.
=> 목적
정제(cleaning) : 갖고 있는 코퍼스로부터 노이즈 데이터를 제거합니다.
정규화(normalization) : 표현 방법이 다른 단어들을 통합시켜서 같은 단어로 만들어줍니다.
> 정제 작업은 토큰화 작업에 방해가 되는 부분들을 배제시키고 토큰화 작업을 수행하기 위해서 토큰화 작업보다 앞서 이루어지기도 하지만, 토큰화 작업 이후에도 여전히 남아있는 노이즈들을 제거하기 위해 지속적으로 이루어지기도 합니다.
※ 사실 완벽한 정제 작업은 어려운 편이라서, 대부분의 경우 이 정도면 됐다.라는 일종의 합의점을 찾습니다.
1) 규칙 기반 표기가 다른 단어 통합
같은 의미를 갖고 있음에도, 표기가 다른 단어들을 하나의 단어로 정규화하는 방법을 사용합니다.
USA와 US는 같은 의미를 가지므로 하나의 단어로 정규화해볼 수 있습니다. uh-huh와 uhhuh는 형태는 다르지만 여전히 같은 의미를 갖고 있습니다. 이에 어간추출, 표제어추출을 사용합니다.
2) 대, 소문자 통합
영어권 언어에서 대, 소문자를 통합하는 것은 단어의 개수를 줄일 수 있는 또 다른 정규화 방법입니다.
-> 소문자 변환이 왜 유용한가?
페라리를 검색해본다고 하면, 엄밀히 말해서 사실 사용자가 검색을 통해 찾고자 하는 결과는 a Ferrari car라고 봐야 합니다. 하지만 검색 엔진은 소문자 변환을 적용했을 것이기 때문에 ferrari만 쳐도 원하는 결과를 얻을 수 있습니다.
> 물론 무작정 전부 다 소문자로 바꾸면 안 됩니다. ∴ 이런 규칙이 필요합니다. 문장의 맨 앞에서 나오는 단어의 대문자만 소문자로 바꾸고, 다른 단어들은 전부 대문자인 상태로 유지
3) 불필요한 단어 제거
노이즈 데이터(noise data)는 자연어가 아니면서 아무 의미도 갖지 않는 글자들(특수 문자 등)을 의미하기도 하지만, 분석하고자 하는 목적에 맞지 않는 불필요 단어들을 노이즈 데이터라고 합니다.
1. 불용어 제거
2. 등장 빈도가 적은 단어
-> 때로는 텍스트 데이터에서 너무 적게 등장해서 자연어 처리에 도움이 되지 않는 단어들이 존재합니다.
ex) 100000개의 메일을 가지고 정상 메일에서는 어떤 단어들이 주로 등장하고, 스팸 메일에서는 어떤 단어들이 주로 등장하는지 봐서 분류기를 만드려고 합니다.
> 근데 100000개의 메일에서 총 5번밖에 등장하지 않는 단어가 있다면 이 단어는 직관적으로 분류에 거의 도움이 되지 않은 것입니다.
3. 길이가 짧은 단어

영어권 언어에서는 길이가 짧은 단어를 삭제하는 것만으로도 어느 정도 자연어 처리에서 크게 의미가 없는 단어들을 제거하는 효과를 볼 수 있습니다.
> 즉, 영어권 언어에서 길이가 짧은 단어들은 대부분 불용어에 해당합니다. 하지만 한국어에서는 길이가 짧은 단어라고 삭제하는 이런 방법이 크게 유효하지 않을 수 있습니다. 영어권에서는 길이가 1인 단어를 제거하면 관사인 'a', 나 주어인 'I'가 제거됩니다.
3. 어간 추출과 표제어 추출
정규화 기법 중 코퍼스에 있는 단어의 개수를 줄일 수 있는 기법인 표제어 추출(lemmatization)과 어간 추출(stemming)
-> 서로 다른 단어들이지만, 하나의 단어로 일반화시킬 수 있다면 하나의 단어로 일반화시켜서 문서 내의 단어 수를 줄이겠다는 것!
> 이러한 방법들은 단어의 빈도수를 기반으로 문제를 풀고자 하는 BoW(Bag of Words) 표현을 사용하는 자연어 처리 문제에서 주로 사용됩니다.
> ★ 정규화의 지향점은 갖고 있는 코퍼스의 복잡성을 줄이는 일입니다.(vocab size를 줄일 수 있습니다.)
1) 표제어 추출
표제어 추출은 단어들이 다른 형태를 가지더라도, 그 뿌리 단어를 찾아가서 단어의 개수를 줄일 수 있는지 판단합니다. (역시 추출의 최종 목적은 코퍼스에서 같은 의미를 가지는 단어는 같은 단어로 만들어서 단어의 개수를 줄이는 것입니다.)
예를 들어서 am, are, is는 서로 다른 스펠링이지만 그 뿌리 단어는 be라고 볼 수 있습니다. 이때, 이 단어들의 표제어는 be라고 합니다. 형태소의 종류로 어간과 접사가 존재합니다.

표제어 추출을 하는 가장 섬세한 방법은 이 두 가지 구성 요소를 분리하는 것입니다. cats라면 어간 cat과 접사 s를 분리합니다. fox는 더 이상 분리할 수 없습니다.
표제어 추출은 어간 추출과는 달리 단어의 형태가 적절히 보존되는 양상을 보이는 특징이 있습니다.
# NLTK에서는 표제어 추출을 위한 도구인 WordNetLemmatizer를 지원한다.
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
words = ['policy', 'doing', 'organization', 'have', 'going', 'love', 'lives', 'fly', 'dies', 'watched', 'has', 'starting']
# 결과
표제어 추출 전 : ['policy', 'doing', 'organization', 'have', 'going', 'love', 'lives', 'fly', 'dies', 'watched', 'has', 'starting']
표제어 추출 후 : ['policy', 'doing', 'organization', 'have', 'going', 'love', 'life', 'fly', 'dy', 'watched', 'ha', 'starting']
하지만 결과를 보면 'dy'나 'ha'와 같이 의미를 알 수 없는 적절하지 못한 단어를 출력하고 있습니다.

> 표제어 추출기가 본래 단어의 품사 정보를 알아야만 정확한 결과를 얻을 수 있기 때문입니다.
2) 어간 추출
어간 추출은 형태학적 분석을 단순화한 버전이라고 볼 수도 있고, "정해진 규칙"만 보고 단어의 어미를 자르는 어림짐작의 작업이라고 볼 수 있습니다. 이 작업은 섬세한 작업이 아니기 때문에 어간 추출 후에 나오는 결과 단어는 사전에 존재하지 않는 단어일 수도 있습니다. 규칙 기반의 접근을 하고 있으므로 어간 추출 후의 결과에는 사전에 없는 단어들도 포함됩니다.
-> 규칙 기반의 접근

★ 이런 규칙에 기반한 알고리즘은 종종 제대로 된 일반화를 수행하지 못할 수 있습니다. ★
> organization과 organ은 완전히 다른 단어임에도 organization에 대해서 어간 추출을 했더니 organ이라는 단어가 나왔습니다. organ에 대해서 어간 추출을 한다고 하더라도 결과는 역시 organ이 되기 때문에, 두 단어에 대해서 어간 추출을 한다면 동일한 어간을 갖게 됩니다. 의미가 다른데 동일한 단어로 정규화되는 것은 정규화의 목적에 맞지 않습니다.
-> 동일한 단어의 어간, 표제어 추출 차이 비교

3) 한국어에서의 어간 추출

한국어는 위의 표와 같이 5언 9 품사의 구조를 가지고 있습니다. 그중 용언은 어간과 어미의 결합으로 구성됩니다.
어간 : 용언(동사, 형용사)을 활용할 때, 원칙적으로 모양이 변하지 않는 부분
어미 : 용언의 어간 뒤에 붙어서 활용하면서 변하는 부분
1.활용 : 어간이 어미를 취할 때, 어간의 모습이 일정하다면 규칙 활용, 어간이나 어미의 모습이 변하면 불규칙 활용입니다.
ex) "긋다, 긋고, 그어서, 그어라"는 불규칙 활용입니다.
2.규칙활용 : 규칙 활용은 어간이 어미를 취할 때, 어간의 모습이 일정합니다. 아래의 예제는 어간과 어미가 합쳐질 때, 어간의 형태가 바뀌지 않습니다.

규칙활용은 어간이 어미가 붙기 전의 모습과 어미가 붙은 후의 모습이 같으므로, 규칙 기반으로 어미를 단순히 분리해주면 어간 추출이 됩니다.
3.불규칙 활용 : 불규칙 활용은 어간이 어미를 취할 때 어간의 모습이 바뀌거나 취하는 어미가 특수한 어미일 경우를 말합니다.
ex) ‘듣-, 오르-, 노랗-’ 등이 어간의 형식이 달라지는 일이 있거나 이르+아/어→이르러, 푸르+아/어→푸르러’와 같이 일반적인 어미가 아닌 특수한 어미를 취하는 경우 불규칙 활용을 하는 예에 속합니다.
> 이 경우에는 어간이 어미가 붙는 과정에서 어간의 모습이 바뀌었으므로 단순한 분리만으로 어간 추출이 되지 않고 좀 더 복잡한 규칙을 필요로 합니다.
4. 불용어 제거
갖고 있는 데이터에서 유의미한 단어 토큰만을 선별하기 위해서는 큰 의미가 없는 단어 토큰을 제거하는 작업이 필요합니다.
> 여기서 큰 의미가 없다라는 것은 자주 등장하지만 분석을 하는 것에 있어서는 큰 도움이 되지 않는 단어들을 말합니다.
ex) I, my, me, over, 조사, 접미사 같은 단어들은 문장에서는 자주 등장하지만 실제 의미 분석을 하는 데는 거의 기여하는 바가 없는 경우가 있습니다. 이러한 단어들을 불용어라고 합니다.
> 179개의 불용어를 사전에 정의하고 있고 10개 확인한 결과 i, me, my 등을 불용어로 정의하고 있었습니다. 이는 문장에서 자주 등장하지만 실제 의미 분석을 하는 데는 기여하는 바가 없는 것이겠습니다.

=> 한국어에서 불용어 제거하기
사용자가 직접 불용어 사전을 만들게 되는 경우가 많습니다.
보편적인 한국어 불용어 리스트 : https://www.ranks.nl/stopwords/korean
> 불용어가 많은 경우에는 코드 내에서 직접 정의하지 않고 txt 파일이나 csv 파일로 정리해놓고 이를 불러와서 사용하기도 합니다.
5. 정규표현식
GitHub - SangBeom-Hahn/NLP
Contribute to SangBeom-Hahn/NLP development by creating an account on GitHub.
github.com
'[AI] > [네이버 BoostCamp | 학습기록]' 카테고리의 다른 글
| NLP PART.언어 모델 (0) | 2022.12.19 |
|---|---|
| NLP PART.텍스트 전처리2 (0) | 2022.12.19 |
| NLP PART.BERT, GPT (0) | 2022.12.09 |
| NLP PART.Attention 메커니즘 (0) | 2022.12.06 |
| NLP PART.RNN, Seq2Seq 구조 (0) | 2022.12.03 |



