
개발자로 후회없는 삶 살기
NLP PART.RNN, Seq2Seq 구조 본문
서론
※ 이 포스트는 다음 강의의 학습이 목표임을 밝힙니다.
https://www.youtube.com/@mcodeM/playlists
메타코드M
메타코드에서 SKY출신 / AI기업 현직자에게 무료로 코딩을 배우세요 서울대 , 카이스트, 고려대 + 현업 개발자들의 핵심 코딩/데이터 강의 [비지니스 협업은 메일로 연락주세요 : support@mcode.co.kr] -
www.youtube.com
본론
- rnn
시간에 따라 변화하는 데이터를 처리하기에 좋은 NN 구조입니다. > 예시 : 음성인식, 음악 생성기, DNA 염기 서열 분석, 번역기, 감정 분석
> state space model입니다. 입력, 상태, 출력을 다루는 모델입니다. history를 가져가는 모델입니다. 세 개의 w를 공유합니다.
rnn의 활용(seq2seq)
영어에서 프랑스어로 번역을 할 것입니다. 문장이 들어오고 문장이 나옵니다. 내부 구조를 어떻게 꾸며야 이런 식으로 나올까요? > rnn으로 단어 하나씩 들여보낸 다음에 바로 입력과 출력으로 내보내는 구조일까요?
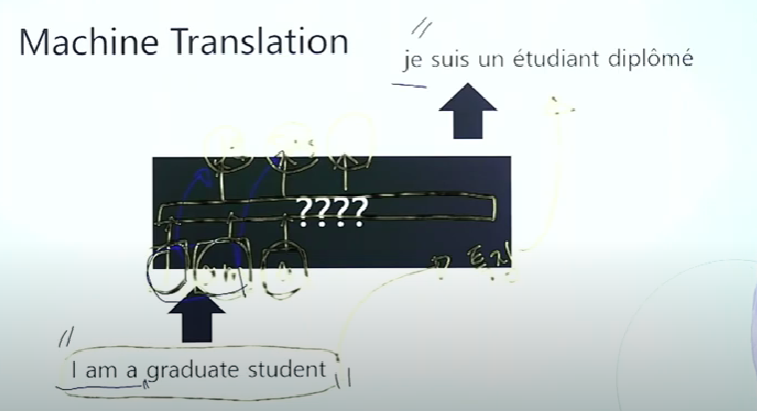
이 구조의 단점은 들어가는 건 영어고 나오는 건 불어입니다. 인코더 디코더 구조로 해석이 불가능합니다. (rnn으로 감정 분석을 할 때 입력을 다 받아서 마지막 rnn 블럭까지 history를 모은 것이 인코더이고 마지막 블럭의 출력을 받아서 dense를 거친 것이 디코더입니다. 입력을 인코더로 인코딩하고 디코더로 해석하는 것입니다.)
=> 단점
1. 인코더 - 디코더 구조를 사용하지 못하는 거 자체
2. 번역을 못 하는 것
> 우리는 전체 문장을 하나의 어떤 특징으로 추출해서 특징으로 번역을 해야 하는 게 번역의 원리입니다. (번역은 인코더가 있어야 합니다.)
-> 예제
i am a boy 에서 번역은 앞에서 바로 i면 i만 보고 번역을 하는 게 아닙니다. 번역할 때 앞에서 부터 봐서 번역하는 게 아니고 전체 문장을 보고 전체 문장의 맥락을 파악한 다음에 한 번에 번역을 하는 것입니다. 단어 단위가 아니고 문장 전체 단위입니다. (여기서 알 수 있는 것은 단어 단위로 봐도 되는 것은 특징 히스토리를 추출할 필요가 없는 것입니다. 근데 전체 단위로 전체를 봐야 한다면 특징 히스토리를 추출해야 합니다.)
> 그래서 전체의 특징을 파악한 후 파악한 특징으로부터 전체 번역된 문장을 생성해야 하는 것입니다. 그래서 이런 식으로 하나의 rnn 구조로 하면 i만 보고 단어를 생성해야 하고 i am만 보고 단어를 생성해야 하고 이러면 문제가 발생할 수 있습니다. 그래서 나온 게 seq2seq 모델입니다.
- seq2seq

ngram 언어 모델이 뭐였나요? n이 3이면 i am a graduate student이면 i am a 때문에 graduate가 나왔었습니다. 통계기반이라고 했지만 앞의 단어로 뒤의 단어를 만드는 것이라고 n-gram이 그런 거라고 했습니다. 앞의 몇 개의 단어들만 보고 다음 단어를 예측하는 것이었습니다. > 문제가 뭐였냐면 정보 불충분 문제와 이후 student라는 정보도 보이지 않는다는 것이 문제였습니다.
-> seq2seq는 어떤 구조로 접근하냐면

rnn구조를 쓰는데 인코더 rnn구조, 디코더 rnn구조 2개를 가져다 씁니다. (인코더 디코더 하나하나는 rnn 구조입니다.) > rnn 네트워크 2개를 가로로 쌓고 영어 문장이 뭉터기로 들어오면 하나하나 잘라서 인코더에 인풋으로 씁니다.
> 인코더에서 출력이 되나요? 인코드의 출력은 확인하지 않고 마지막 y도 아닌 마지막 hidden을 끌고 와서 디코더의 초기 상태로 씁니다.
> x0(초기 상태지 초기 입력이 아님!) > 인코더의 초기 상태는 랜덤입니다. (random initailize) 디코더의 처음 입력은 "번역을 시작할게요"라는 <시작> 태그를 입력합니다. > 그러면 초기 상태(context vector=특징)와 <시작>과 만나서 첫 번째 번역 단어를 내보냅니다. > 그다음 첫 번역 단어를 두 번째 입력으로 사용하여 두번째 단어를 번역합니다. 또 그걸 세 번째 입력으로 씁니다. 이게 seq2seq의 구조입니다.
> 인코더의 학습이 다 됐다고 가정을 하고 입력 시계열을 쭉 넣으면 입력의 특징인 context vector를 디코더로 넘겨주고 > 디코더에서 <시작>이라고 하면 특징을 받아서 번역(=생성)을 합니다. 마지막 끝 단어가 들어오면 디코더에서 y로 <끝>이라고 출력을 합니다. 끝이라고 조건문으로 확인하여 문장 생성(번역)을 마칩니다.
※ 머신러닝 교과목에서 배운 거 보면 진짜 <끝>이라고
-> 학습방법
인코더에서는 문장이 입력, 문장이 출력으로 지도학습 데이터 셋을 만들고 데이터 셋마다 인코더에 인풋을 넣습니다.

> 그러면 인코더에서는 아웃풋은 안 내보내고 state만 내보내서 마지막 state를 디코더로 보내고 <시작>이라고 하면 시작해서 아까 첫 번째 단어를 생성한다고 했고 그걸 받아서 두 번째 단어를 내보내고 쭉죽쭉 진행하다가 마지막 단어는 <끝>을 내보낸다고 했습니다.
> 지도학습입니다. 인코더에서 문장을 집어넣어서 hidden state를 만들고 hidden state이 디코더의 초기 상태로 들어간 후 디코더에서는 1대1 대응으로 지도학습을 합니다. (라벨과 예측 벡터의 차이가 손실입니다.)
> 결론 : 데이터는 지도 학습 데이터인데 디코더에서 조정을 합니다. 입력 데이터 앞에 <시작>을 붙이고 실제 입력을 하나씩 <시작> 뒤에 붙입니다. 아웃 풋은 맨 뒤에 <끝>이라고 직접 붙입니다. 한 칸씩 뒤로 밀어서 입력과 출력이 어긋나 있습니다.
+ seq2seq를 학습하는 방법 정리
= 인코더에 인풋 집어넣고 인코더 아웃풋은 보지 않고 디코더에서는 시작이라는 단어를 넣고 아웃풋에서는 출력을 해서 학습을 합니다. 인코더는 그냥 입력을 넣고 디코더에서는 밀어서 <시작>을 붙이고 뒤에 <끝>을 붙입니다.
-> 궁금증

시작을 넣으면 말이 안 되는 단어가 나오고 그걸 입력으로 넣으면 두 번째 단어도 말이 안 되는 단어가 나오는 거 아닌가요? > 이건 학습을 잘 맞혔을 때 test에는 좋습니다. 그런데 말이 안 되는 단어는 rnn 학습에 좋지 않은 영향을 미치겠죠? 인풋이 틀린 상태로 들어갑니다. (질문 : 인코더의 입력은 무시하나? 디코더의 입력이 별로라고 하신다.) > 그래서 뒤의 단어가 다 망가집니다. 그래서 우리는 seq2seq를 학습시킬 때는 teacher-force training을 합니다.
-> teacher

트레이닝을 할 때에 있어서는 정답을 미리 다 알려주는 것입니다. 디코더의 입력을 원래는 디코더의 출력으로 썼는데 학습에 있어서는 실제 정답을 미리 알려주자!
> 디코더의 출력을 입력으로 쓰지 말자! 디코더의 출력을 쓰는 것은 test 때만 씁니다. > 마찬가지로 <시작> + 실제 정답 붙여서 디코더의 입력을 만들고 출력은 <끝>을 붙여서 학습을 합니다. 이게 teacher forse training입니다. 다만 테스팅할 때는 원래대로 씁니다. 그래서 seq2seq의 단점이 나옵니다.
-> 단점
학습이 제대로 되지 않았을 때 첫 출력이 잘못되면 뒤의 결과는 다 잘못된 결과를 내놓습니다! 연쇄적으로 진행되기 때문에 다 틀립니다. 그래서 attention 메커니즘이 나왔습니다. 그래도 전체 뭉터기로 들어온 것을 하나하나하나 단어 단위로 하나씩 해석하지 않고 context vector를 통해서 주기 때문에 기본 lstm보다 좋은 성능을 보입니다.
- seq2seq 전체 구조(번역, 단어 생성)
tokenizer + 인코딩(word2vec) > 학습(입력과 라벨을 주어서 + teacher force로 학습한다.) > 검증+테스팅
- 1D-CNN
cnn은 이미지 처리를 할 때 사용합니다. 필터를 이미지에 입혀서 피쳐를 추출하여 feature map을 추출합니다. 이 cnn을 자연어 처리에 사용할 수 없을까요? 고민해서 만든 것이 1d cnn입니다.

> 자연어는 i am a student 면 각 단어마다 이것은 w2v이 선행이 되어야 합니다. 하면 인코딩 벡터가 있을 것입니다. > 여기다가 커널을 입히자는 것입니다. 그렇게 feature를 만들어 내자!
> 이미지 처리에서 커널을 입히면 하나의 feature map이 그 이미지 전체의 특징을 담고 있습니다. 그걸 임베딩 벡터에 해서 여러 단어를 포괄하는 커널을 만들자는 것입니다.
> 단어 2개짜리를 덮는 커널이 있다고 치면 이 노란색 필터가 한 칸씩 밑으로 내려가는 것입니다. > 커널의 w와 임베딩 값을 cnn을 돌립니다. 그러면 단어가 5개인데 2개짜리 필터로 cnn 연산을 하면 크기가 줄어듭니다. 이런 식으로 가다 보면 feature가 나옵니다. 이 문장(시계열 데이터)을 잘 나타내는 특징이 나올 것입니다. 이때 필터들의 w를 학습하면 시계열이니 시간 사이의 상관관계를 학습합니다.
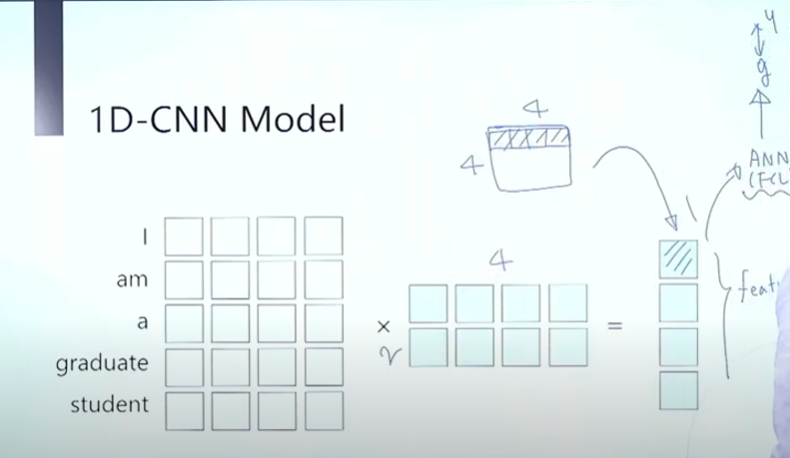
> 이 feature를 dense에 넣어서 실제 y와 비교를 하여 오차로 학습을 합니다. > rnn을 사용하지 않고 cnn만 사용하여 시계열 처리를 하는 강력한 모델입니다.
=> 전체 structrure

1, 2, 3 필터가 있으면 여러 feature map을 만듭니다. > max-poolig을 거치고 > 그 결과들을 모아서 concat 합니다. > 얘네를 ann에 넣어서 오차로 학습하면 되는 cnn과 같은 모습입니다.
- bi lstm(컴퓨터가 안 좋으면 gru 쓰고 아니면 이것을 쓴다!)

bi는 방향이 앞 뒤인 lstm을 합쳐놨다고 해서 bi lstm입니다. > rnn 모델은 시간 방향이 과거에서 미래로 이동하는 방식이었습니다. > 이러면 과거만 봐서 추론을 해야 합니다. 근데 번역이라는 것이 가운데 단어를 해석을 할 때 앞의 단어도 중요하지만 뒤의 단어도 중요합니다. > 반대로 가는 lstm도 있으면 좋겠다고 해서 나온 것입니다. > ★ 뒤에 데이터를 참조해도 될 때만 > bi를 사용할 수 있습니다!
-> lstm과 비교

lstm은 입력이 들어오면 화살표가 오른쪽으로 흘러갈 수밖에 없습니다. 이게 lstm의 규칙이었습니다. > ★bi는 w가 추가됩니다.★ 왼쪽에서 오는 거 오른쪽으로 가는 거로 전체 w가 추가됩니다. > self 피드백을 주는 Wy와 wh가 아닌 Wx만 두배로 늘어납니다.
> 주의점 : casualty를 무시해도 될 때 사용합니다. 테스트할 때 오른쪽에서 오는 데이터를 사용 못 할 때는 bi를 사용하면 안 됩니다. 미래 데이터가 영향을 못 미칠 때는 사용하면 안 됩니다.
'[AI] > [네이버 BoostCamp | 학습기록]' 카테고리의 다른 글
| NLP PART.BERT, GPT (0) | 2022.12.09 |
|---|---|
| NLP PART.Attention 메커니즘 (0) | 2022.12.06 |
| NLP PART.텍스트 마이닝 이론 (0) | 2022.12.01 |
| NLP PART.텍스트 전처리 이론 (0) | 2022.12.01 |
| [22.05.01]딥러닝 PART.순환 신경망 (0) | 2022.11.08 |



