
개발자로 후회없는 삶 살기
[22.10.11] 딥러닝 PART.교과목 CNN, 고급 신경망 활용 본문
서론
교과목 5주차 고급 신경망 활용에 관한 내용을 정리합니다.
목적 : feature extraction의 재발견!
본론
- Shallow Learning vs Deep Learning

1. SL : feature 추출은 전문가(사람)이 하고, 분류만 모델이 하는 방법
2. DL : feature 추출부터 분류까지 모델이 하는 방법
=> 핵심
1. SL은 분류기만 학습합니다.
2. DL은 추출기부터 분류기까지 전부 학습합니다. ※ 빨간색 부분이 분류기/ 파란색 부분이 분류기
> 결론 : 과거와 현재의 차이는 feature 추출을 사람이 하는가, 기계가 하는가의 차이입니다.
- CNN
=> FNN의 문제점
1. 뉴런이 완전 연결되어 학습시켜야 하는 파라미터의 개수가 폭발적으로 증가
2. 입력을 1차원으로 바꾸는 과정에서 정보 손실
=> cnn 핵심
1. 특정 영역에 대해서만 입력을 받겠다는 것입니다.(= 일부 데이터만 정보를 받습니다. = 지역성) -> 뉴런 하나하나가 그 지역이 어떤지 지역만의 특징을 익힙니다.
2. 하나의 영역을 하나의 value로 바꿔주는 뉴런들의 집합입니다.
=> 데이터의 복잡성
ex) cifar 10 -> 32 32 3의 컬러 영상 : 28x28x1에서 32x32x3으로 어마어마한 벡터가 모델로 들어갑니다. + 이미지 넷 : 224 x 224 x 3의 1000개의 클래스
=> 데이터 증강
정의 : 확보된 데이터를 인위적으로 증가시키는 방법(ex) 위험한 영상 등 더 찍는 게 최고지만 차선으로 더 찍을 수 없는 경우 데이터를 조작해서 같은 비행기 카테고리에 속한 다른 영상을 만듭니다.
-> 케라스 API
import ImageDataGenerator -> 증강된 데이터로 모델 학습을 시킬 때는 fit_generator 함수 사용(keras api 참고), flow로 조작된 데이터를 학습에 사용합니다.
=> resnet
핵심 : 영상 인식의 모든 feature 추출은 다 이 모델로 합니다. = resnet에서 dense를 빼서 feature 추출만 하고 위에 내가 원하는 모양으로 쌓은 후 새로 학습을 시켜 분류, detection을 합니다.
+ resnet을 백본으로 사용한다고 합니다.
-> residual block
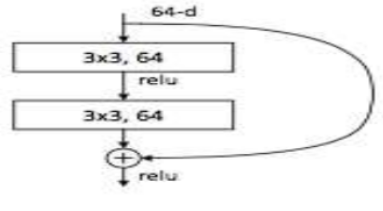
마지막 층의 분류기가 최고층의 출력만 입력으로 받으면 밑의 정보는 못 봐서 기억력 손실이 일어납니다.
∴ 분류기가 너무 추상화된 이미지만 봐서 세세한 걸 보려면 웃는 얼굴, 스미스 톰을 구분해야 하니 아래층의 feature 정보가 필요합니다.
-> 대다수의 모델이 순차적으로 데이터의 흐림이 일어나서 밑의 출력은 보지 않습니다. = 밑에가 무시됩니다. ∴ skip pass를 사용하여 아래 저수준의 정보와 위의 고수준의 정보를 결합합니다.
예제 1)
# include_top을 하면 vgg 분류기까지 가져온다는 얘기
model = VGG16(weights='imagenet', include_top=True)
model.compile(optimizer='sgd', loss='categorical_crossentropy')
# resize into VGG16 trained images' format
im = cv2.resize(cv2.imread('/content/cat.jpg'), (224, 224))
im = np.expand_dims(im, axis=0) # 1, 224, 224, 3이 됨
im.astype(np.float32)
# predict
out = model.predict(im)
index = np.argmax(out)
print(index) > vgg를 이미지 넷으로 학습하고 feature extraction 하는 부분에서부터 분류기까지 include_top으로 다 가져옵니다.
+ 모델을 가져오더라도 compile을 해야 하고 새로운 데이터를 넣으려면 resize, reshape 등의 전처리를 무조건 해야 합니다.
예제 2)
# prebuild model with pre-trained weights on imagenet
base_model = VGG16(weights='imagenet', include_top=True)
print (base_model)
for i, layer in enumerate(base_model.layers):
print (i, layer.name, layer.output_shape)
# extract features from block4_pool block
model = models.Model(inputs=base_model.input,
outputs=base_model.get_layer('block4_pool').output)
img_path = 'cat.jpg'
img = image.load_img(img_path, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
# get the features from this block
features = model.predict(x)
print(features)-> 사전 학습된 모델을 feature 추출한 부분까지만 쓰기 위해 output을 중간 계층으로 잡았습니다. > 이랬을 경우 더 일반화된 예측이 가능합니다.
- 고급 합성곱 신경망
=> Classification & Localization
-> 내용
1. 영상 안에 물체가 있고 반드시 하나만 있다는 전제하에 물체가 어디 있고 그 물체의 종류가 무엇인지 맞추는 문제
2. 분류에서는 feature extraction 하고 feature map을 이용하여 완전 연결망으로 분류를 했는데 여기서는 두 가지를 합니다.
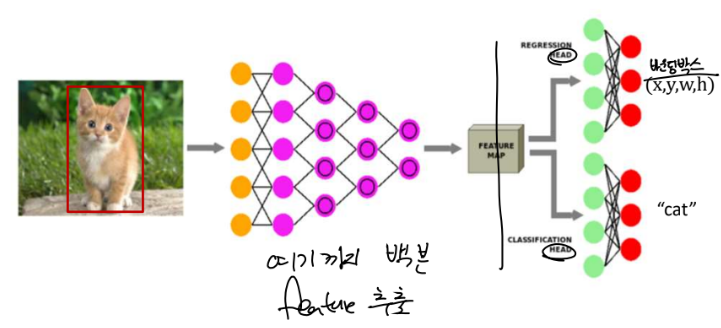
1) 분류 : 사진 안의 물체가 어떤 클래스인지 알아내는 문제
2) 회귀 : 위치 추적 -> 숫자 4개를 알아내는 문제
-> 분류와 회귀를 동시에 하는 문제로 바뀝니다.
+ 학습 방법 : 목표가 2개로 분류와 위치 추적(실수의 4차원 벡터를 예측합니다.)을 합니다.
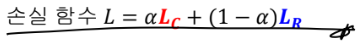
-> 이것을 하려면 손실 함수를 2개 씁니다.(손실이 곧 목표!)
사진을 보면 :
1) 정답 박스와 예측 박스의 차가 LR
2) 분류가 LC > 둘 중에 뭘 더 중요하게 볼지가 α > ★ feature 추출과 분류망, 회귀망이 같이 학습됩니다.(SL이 아닌 DL!) ★
=> Object Detection
※ 갤럭시 카메라의 박스가 실제 바운딩 박스입니다., 이제 실생활의 상식처럼 되어버렸습니다. 매우 중요한 부분!
+ 내용 : 이제는 물체가 몇 개인지, 위치도 모르는 상황입니다.
1. R-CNN : region cnn
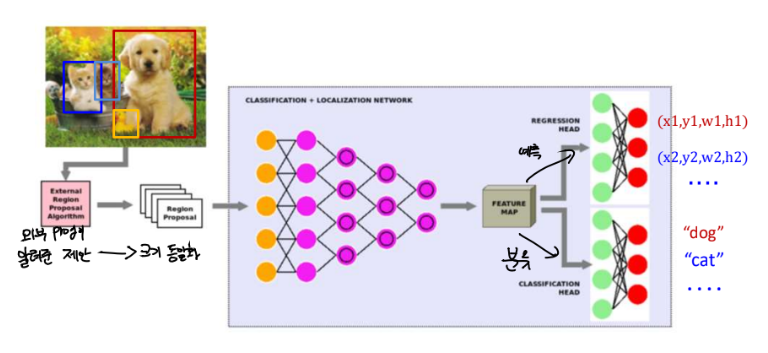
=> 방법
1) 물체가 어디에 있을 거 같다는 것을 제시해 주는 프로그램을 써서 있을 거 같아 보이는 영역을 추천받았습니다. (실제 있다는 게 아니고, 최소한 있을 수 있다는 후보만 보여주었습니다. = extract region proposal)
2) 추천받은 patch를 하나의 전체 영상으로 봐서(사실은 patch인데) CNN을 통과시켜서 feature map을 만들고 feature map을 완전 신경망을 통과해서 분류를 하는 것입니다. (= 추천받은 후보 박스에 대한 분류 및 위치 추정)
3) 이 과정에서 추천받은 영역이 크기가 다 다른데 cnn의 입력 크기는 동일하니 크기를 동일하게 만들어 주는 작업이 필요합니다.
★ cnn으로 patch 각각 feature 추출하고 분류하는 건 똑같습니다.
=> 문제점
1) 영역 추천기의 도움을 너무 많이 받습니다.
2) 각 patch를 cnn 다 돌리는 게 무리입니다. (feature map이 추천 patch 개수랑 똑같은 개수로 생김)
2. fast R-cnn : R-cnn 개선
방법 : patch 전부를 다 cnn 돌리는 건 무리니 한 번에 하자! > 아까는 추천받은 박스마다 cnn을 돌렸습니다(= feature map을 따로따로 구했습니다.)
1) 영상 통째로 cnn을 거쳐서 feature map을 구하고 그 feature map을 나눕니다.
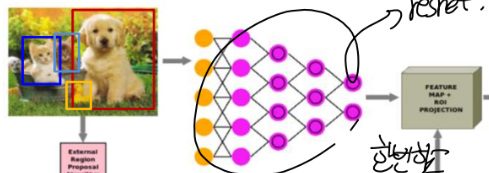
2) feature map을 나눌 때는 추천 프로그램을 쓰고 이러면 feature map 안에서 추천합니다.
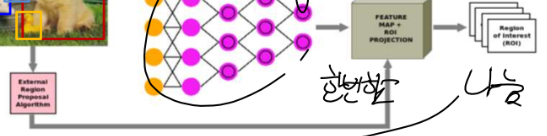
3) 이것을 분류층에 넣기 위해 모양을 통일해야 하므로 roi(region of interest = 관심 영역) pooling을 거칩니다. = 물체가 있어 보이는 곳의 크기를 통일시킵니다.
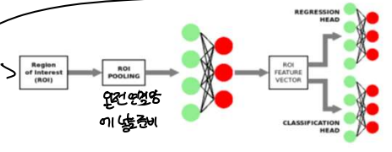
4) roi 원리
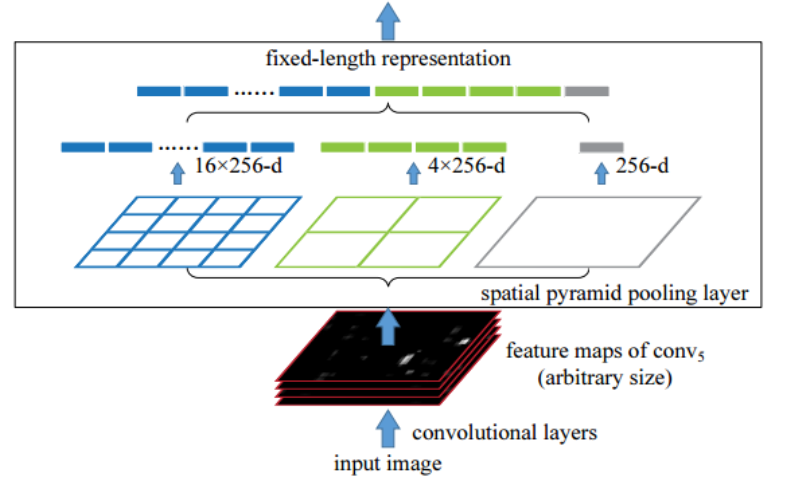
① 입력이 feature map을 추천받은 크기로 쪼갠 것입니다.
② 그것을 각각 사이즈에 맞게 4 by 4, 2 by 2로 쪼갭니다.
③ 각 픽셀에서 풀링 기법을 써서 하나의 값을 구합니다.
-> 이러면 총 입력 모양이 어떻든 21개가 생기고 이것을 dense 하여 분류기에 넣을 준비를 마쳤습니다.
★내가 착각한 부분★
1) 처음에 feature map을 만들 때는 영상 원본(아무것도 하지 않은)을 넣는 것입니다.
2) 그 후에 만들어진 feature map을 영역 제안 프로그램을 돌리는 것이라고 보면 됩니다.
3) 그러면 feature map이 제안 영역에 맞게 쪼개지고 당연스럽게 feature를 구했으면 그것으로 분류와 회귀를 하는 것입니다.
3. faster R-cnn : fast R-cnn 개선
개념 : 아직까지 region proposal을 추천기를 통해서 받습니다. 이것을 혼자 해보겠습니다.
방법
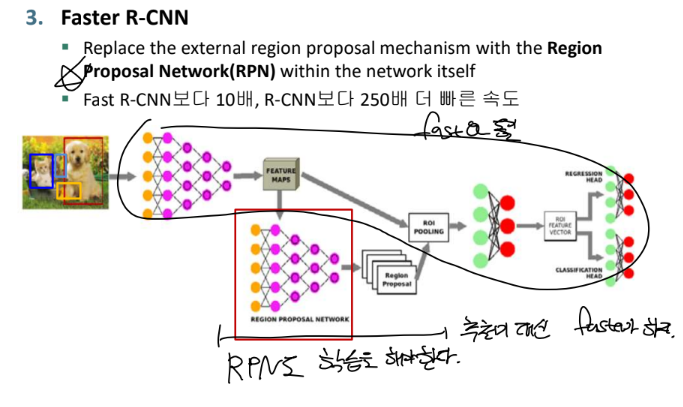
1) feature map으로 영상 통째 뽑습니다.(fast와 동일)
2) 뽑은 feature를 RPN(feature 안 어디에 물체가 있을 것 같은지 제안해 주는 네트워크)에 넣습니다.(이게 대박인 게 네트워크를 훈련하려면 입력이 필요했었습니다. 여기서는 입력이 뽑은 feature map이고 출력이 region proposal입니다.)
3) RPN이 알려주는 proposal대로 처음에 뽑은 feature map을 쪼갭니다.(★FASTRCNN에서도 feature map을 분류기에 넣기 전에 추천기에게 받은 제안대로 쪼겠습니다.★)
=> RPN 강화
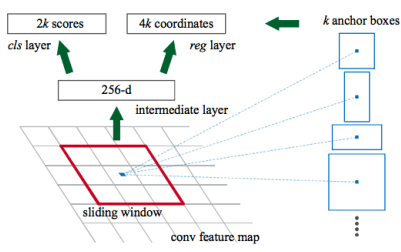
-> 순서
1. 입력은 맨 처음에 원본 영상을 cnn 거쳐서 추출한 feature map!
2. RPN은 지역을 제안해 주는 목적이니 이 feature map 중에서 어디에 있을지를 알 수 있어야 합니다. -> 하지만 어디에 있을까요? 길까 작을까 어디 있지? 아무것도 모르고 있는지 없는지도 모르는 상황입니다.
3. 그러니 미리 전형적인 틀(앵커 박스)을 만들어 놓습니다. -> 대충 이렇게 생기지 않았을까? 크기도 이렇지 않을까?의 목적입니다.(많으면 많을수록 좋겠지만 트레이드오프)
4. 입력이 들어옵니다. > feature map을 몇 by 몇으로 쪼갭니다. (잘게도 되고 듬성듬성도 됩니다.)
5. 중간 포인트를 맞춰서 앵커 박스를 쌓습니다. = 이 중심을 기준으로 앵커 박스 모양대로 객체가 있을 수 있다는 생각입니다.(길고, 작고 등등)
6. 그 앵커 박스 중에서 물체가 있을 거 같은 애를 남기고 나머지는 날립니다.
+ 박스 하나당 점수를 냅니다.
1) 왼쪽 : 물체가 있을 점수, 없을 점수
2) 오른쪽 : 하나의 박스에 있다 치더라도 이 박스에서 어디에 있을까 하여 있다면 중심점, 4개의 꼭짓점이 얼마나 조정되어야 하나의 변화량 -> 이 점수가 가장 높은 앵커 박스를 남기고 다 날립니다. 남은 박스가 image patch가 됩니다. 남은 박스가 fast rcnn에서 제안기가 알려준 이미지 조각이 되어 roi로 들어가는 것입니다.
★ 메인 네트워크도 분류와 회귀를 하고 RPN도 feature를 입력으로 받아 분류와 회귀를 해서 loss로 학습합니다.(이 때문에 2 stage입니다.)
=> 정리
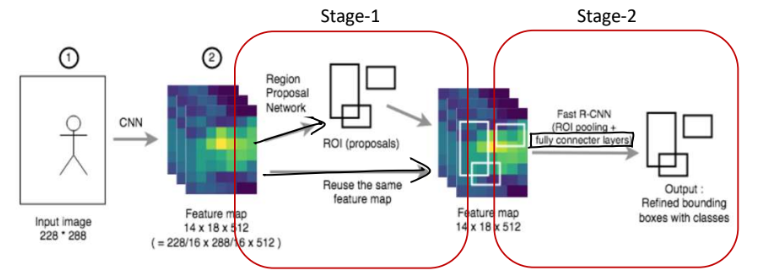
1. 영상을 cnn 거쳐서 전체 feature map을 구합니다.
2. 그 feature map을 위는 rpn, 아래는 rpn을 적용해서 분류기에 넣습니다. ∴ 아래는 rpn이 되기 전까지는 추천받는 게 별로이니 별로 되는 게 없습니다.
3. rpn의 성능이 좋아져서 resion proposal이 잘되면 뽑은 feature map에서 제안된 모양대로 쪼개고 그것을 roi pooling 해서 분류기에 넣습니다.
4. 이를 반복하여 loss를 줄이는 방향으로 모델을 학습합니다.
+ 문제점 : resion proposal이 되야만 분류기에 넣는 의미가 있습니다. resion proposal이 먼저 되어야 합니다. 즉, 속도가 느립니다. 하지만 2단계라서 정확도는 높습니다. (속도보다 정확도가 중요하면 faster R-cnn 씁니다.)
=> 전반적인 순서
1. 영상을 넣어서 feature map을 뽑음
2. feature map을 분류기에 넣으면 그냥 분류
3. feature map을 추천기가 제안한 대로 쪼개서 분류기에 넣은 것이 Fast RCNN
4. feature map을 RPN이 제안한 대로 쪼개서 분류기에 넣은 것이 Faster RCNN
'[AI] > [교과목 | 학습기록]' 카테고리의 다른 글
| [22.09.24] 딥러닝 PART.교과목(콜백, 모델 저장, tfds) (0) | 2022.12.27 |
|---|---|
| [22.09.14] 딥러닝 PART.교과목(퍼셉트론, 과적합 해소) (0) | 2022.12.27 |
| 딥러닝 PART.교과목 오토인코더(Ae) (0) | 2022.11.16 |
| 딥러닝 PART.교과목 단어 임베딩 (0) | 2022.11.08 |
| 딥러닝 PART.교과목 RNN (0) | 2022.11.08 |



