
개발자로 후회없는 삶 살기
논문 리뷰 PART.Generative Visual Manipulationon the Natural Image Manifold 본문
논문 리뷰 PART.Generative Visual Manipulationon the Natural Image Manifold
몽이장쥰 2022. 10. 19. 00:36서론
Generative Visual Manipulationon the Natural Image Manifold은 제목 그대로 이미지의 자연 상태에서 시각적인 조작을 하는 방법을 설명합니다. 본 포스팅에서 주요 내용 위주로 논문을 번역/ 요약하였습니다.
> 논문에서는 이미지 조작을 실시간으로 대화형(interactive)으로 하는 것을 목표로 하기 때문에 IGAN이라고 부릅니다. official pix2pix의 저자분들께서 제안하셨으며 GAN을 대화형으로 사용할 수 있다는 것을 보여줌과 동시에 사용자를 위한 인터페이스까지 제공합니다. 틀린 내용이 있으면 피드백 부탁드립니다.
- 논문 제목 : Generative Visual Manipulation on the Natural Image Manifold
- 저자 : Jun-Yan Zhu , Philipp Kr¨ahenb¨uhl , Eli Shechtman , and Alexei A. Efros
본론
- 논문
- 깃허브
https://github.com/junyanz/iGAN
GitHub - junyanz/iGAN: Interactive Image Generation via Generative Adversarial Networks
Interactive Image Generation via Generative Adversarial Networks - GitHub - junyanz/iGAN: Interactive Image Generation via Generative Adversarial Networks
github.com
[깃허브나 유튜브]
- Overview
Interactive Image Generation via Generative Adversarial Networks가 README 제목으로 GAN을 활용한 대화형 이미지 생성입니다. 논문 저자가 인터페이스 또한 제공합니다.
- Getting start
① Download the model > model.sh에 들어가보면 outdoor_64 모델이 있습니다.
② Run the python script > run main.py 명령어를 실행하면 됩니다.
- Requirements
Python3의 경우 PyQt랑 OpenCV는 버전에 맞게 따로 다운 받아야 합니다.
- Model Zoo
theano 프레임워크 버전의 dcgan을 다운 받으면 됩니다.
=> 실행
1. git clone
2. requirements
-> 위에서 말한 opencv와 pyqt는 python2가 아닌 3일 경우 다르게 하라고 저자가 유도하였습니다.
1) opencv
python-opencv를 설치하라고 나와있지만 python3의 경우 설치 방법이 바뀌었다고 확인되어 시도 중에 있습니다.(참고 1)
∴ pip3로 대체하였습니다.
pip install opencv-python
2) pyqt4 : (참고 2)
위 주소를 참고 하려고 했으나 실제 코드에 적혀있는 pyQt4를 전부 5로 바꿔서 해결하였습니다.
3) cuda 버전 이슈
저자는 CUDA 7.5, cuDNN 5 사용을 권장한다. 하지만 현재 실행하는 컴퓨터의 GPU와 CUDA 버전을 맞춰놓은 상태라 변경하지 못했습니다.
3. model 다운로드


-> 이제 라이브러리 설치, 모델 다운로드까지 완료하였으니 환경구성만 하면 실행할 수 있습니다. 하지만 CUDA 버전을 바꿀 수 없었습니다. 이를 위해서 도커로 환경 구성을 하는 법을 공부해야 합니다. 도커를 사용한다면 CUDA를 한 컴퓨터에 여러 개 설치하고 바꿔가며 사용할 수 있습니다.
※ Command Line Argument(= 명령행 인자) : java 메인을 실행할 때 받는 것처럼 새로운 프로세스를 실행하면서 전달하는 인자를 "명령행 인자"라고 부릅니다.
[논문 1회독]
- Abstract
제시된 방법은 거의 실시간으로 사용자의 낙서를 기반으로 처음부터 새로운 이미지를 생성할 뿐만 아니라 한 이미지를 다른 이미지처럼 변경하는 데에도 사용할 수 있습니다.
- 본론 Figure 미리 보기
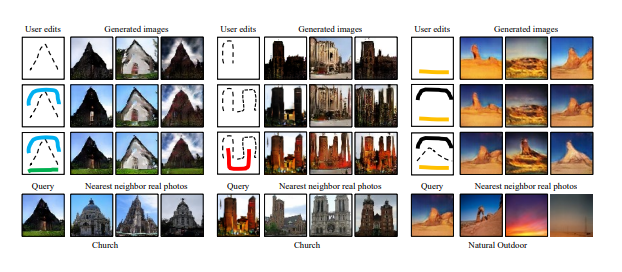
=> Fig1 : 원본 사진을 실제 자연 manifold 차원으로 영사하고 그것을 UI로 편집하고 편집한 것을 부드럽게 전환합니다.

=> Fig4 : 잠재 벡터가 사용자 편집으로 인해 변합니다.

=> Fig 5 : 사용자의 색깔 편집

- 결론 Figure 미리 보기
저자가 보여준 3가지 실제 같은 이미지 조작 결과를 보여줍니다.
1. 첫 번째 image manipulation 원본 이미지에 색깔을 살짝 칠하면 대화형으로 이미지 조작이 되는 것을 확인합니다.
=> Fig 6 : 이미지 조작 ex)원본 이미지에 사용자가 색을 칠하면 연속적으로 이미지의 색깔이 변합니다.

2. 두 번째 generative image transformation 원본 이미지를 아예 새로운 모양으로 바꿉니다. > 모양과 색깔을 바꿉니다.
=> Fig 7 : 원본 이미지의 모양과 색깔이 순차적으로 변하는 것을 보입니다.

3. 세 번째 interactive image generation 아무것도 없는 상태에서 이미지를 생성합니다. (= no image to begin)
=> Fig 8 : 사용자는 스케치 툴을 사용하여 이미지를 생성하고 refine 합니다.
8. Discussion and Limitations
생성된 결과의 품질(저해상도, 누락된 텍스처 및 세부 정보)과 DCGAN이 적용되는 데이터 유형(제품 이미지와 같은 구조화된 데이터 세트에서는 잘 작동하고 보다 일반적인 이미지에서는 더 나빠짐)은 기대할 수 있는 결과의 범위를 제한합니다. 한정된 조건이니 한정된 결과가 나옵니다.
[논문 2회독 (수식 + method + experiment 위주)]
3. Learning the Natural Image Manifold
모든 자연 이미지가 이상적인 저차원 manifold M에 있다고 가정합니다.
이 이상적인 manifold M을 직접 모델링하는 것은 고도로 구조화되고 복잡한 백만 차원 공간(복잡도가 높은 이미지의 차원은 매우 클 수 있기 때문)에서 생성 모델을 훈련하는 것과 관련되기 때문에 매우 어렵습니다.
자연스러워 보이는 이미지를 생성하는 deep generative 네트워크의 최근 성공에 따라 대규모 이미지에서(복잡도가 매우 높은 이미지) GAN(Generative Adversarial Network)을 사용하는 모델을 학습하여 이미지 매니폴드를 근사화합니다.
GAN에는 이러한 작업을 위한 주의점이 있습니다.
1) GAN : 하나는 GAN의 특성을 이해해야 하는 것입니다. 생성자와 판별자가 대조적으로 학습을 하는 구조이입니다. 생성자와 판별자는 min-max 손실을 통해서 훈련됩니다.

2) GAN as a manifold approximation : GAN을 사용하여 manifold로 근사화하는 데는 두 가지 이유가 있습니다.
① 고품질 이미지를 생성합니다.

② 잠재 공간의 유클리드 거리는 종종 지각적으로 의미 있는 시각적 유사성에 영향을 그대로 나타냅니다.

위 사진을 보면 잠재 공간이 가깝다면 유클리드 거리가 짧고 이미지가 시각적으로 유사한 결과를 보입니다.
3) Traversing the manifold : manifold M에 두 개의 이미지가 주어졌을 때 G(z0), G(z1), . . . G(zN)로의 부드러운 전환의 시퀀스가 가능합니다.

여기서 S는 거리 함수입니다. 그래서 간단한 선형 보간이 이뤄집니다. 그림 2는 잠재 공간의 두 점 사이를 보간하여 생성된 매끄럽고 의미 있는 이미지 시퀀스를 보입니다. 그림 2는 잠재 공간의 두 지점 사이를 보간하여 생성된 매끄럽고 의미 있는 이미지 시퀀스를 보여줍니다. 이것을 실시간의 사진 편집을 위한 자연 이미지의 근사치로 사용할 수 있습니다.
4. Approach

그림 1은 접근 방식의 개요를 보입니다. 실제 사진이 주어지면 먼저 원본 이미지에 가장 가까운 GAN의 잠재 특징 벡터 z를 찾아 이미지 매니폴드에 투영합니다. 그런 다음 잠재 벡터 z를 연속적이고 자연스럽게 업데이트하는 실시간 방법을 제시하여 사용자의 편집(예: 낙서 등)을 모두 적용하고 자연 이미지에 가까운 원하는 이미지를 생성합니다.
하지만 이 변환에서 생성 모델은 일반적으로 입력 이미지의 중요한 세부 정보 중 일부를 잃습니다. 따라서 저자는 생성 모델에 적용된 편집에서 픽셀당 색상과 모양 변화를 모두 추정하는 밀집 대응 방법을 사용했습니다. 그 후 가장자리 인식 보간 기술(edge-aware interpolation)을 사용하여 변경된 부분을 최종 결과로 생성합니다.
4.1 Projecting an Image onto the Manifold
논문의 목표는 실제 이미지인 x와 가까운 x'를 찾는 것으로

재구성 오차를 최소화하여 생성 모델 G를 사용하여 원본 사진 x를 x'로 재구성하는 것입니다. 이 오차를 줄이는 manifold로의 projection을 보겠습니다.
1) Projection via optimization(= 최적화를 통한 projection)
재구성 품질은 z의 초기화에 크게 의존합니다. 여러 번의 랜덤 초기화에서 시작하여 최소 비용으로 결과물을 출력할 수 있어야 합니다. 그러나 안정적인 재구성 손실을 얻기 위해 필요한 무작위 초기화 횟수가 엄청나게 많아(100회 이상) 실시간 처리가 불가능합니다.
∴ projection을 보다 효율적으로 하기 위해 심층 신경망을 훈련합니다.
2) Projection via a feedforward network(= 신경망을 통한 projection)

모델 P의 아키텍처는 적대적 네트워크의 판별자와 동일하며 최종 네트워크 출력 수만 다릅니다. 유사한 이미지의 프로젝션은 유사한 네트워크 매개변수를 공유하고 유사한 결과를 생성합니다. 따라서 초기에 잠재공간을 결과물과 유사하게 설정한다면 원하는 결과를 얻을 수 있습니다.

표를 보면 신경망 기반 projection이 재구성 오차가 낮습니다.
4.2 Manipulating the Latent Vector
방금 설명한 투영 방법을 통해 매니폴드 M에 투영된 이미지 x를 사용하여 해당 매니폴드의 이미지 수정을 시작할 수 있습니다. 원본 이미지 x에 가까운 매니폴드에 머무르면서 동시에 사용자 의도(편집)를 일치시켜 초기 투영 x를 업데이트합니다.
초기 투영 x가 주어지면, 모델은 가능한 한 많은 제약 조건을 만족시키는 x에 가까운 새 이미지 x를 찾습니다. 여기 data term은 제약 조건으로부터의 편차를 측정하고 manifold에서 이동하도록 강제합니다.
=> Gradient descent update
사용자가 이미지를 조작할 때 실시간 피드백을 제공할 수 있는 경사 하강법을 사용하여 문제를 해결합니다. 그 결과 실시간으로 결과물이 바뀝니다.
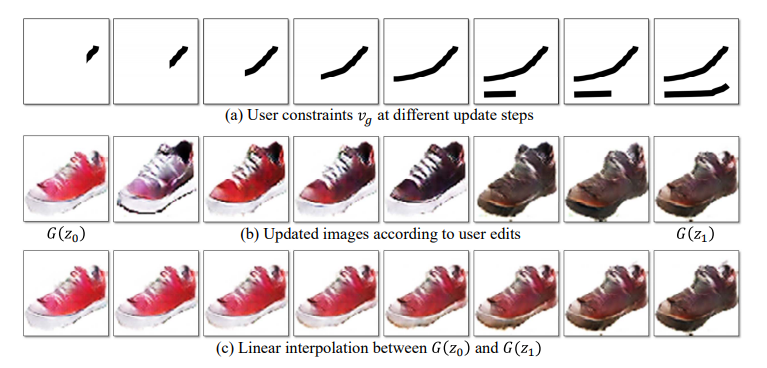
사진과 같이 초기 빨간색 신발이 주어지면 사용자는 신발 이미지에 검은색 선을 연속적으로 편집합니다. 그런 다음 업데이트 방법은 점점 더 많은 사용자 편집을 추가하여 이미지 모양을 부드럽게 변경합니다.
5. User Interface
사용자 인터페이스는 현재 편집된 사진을 표시하는 기본 창, 모든 후보 결과의 축소판을 표시하는 디스플레이, 원본 사진과 최종 결과 사이의 보간 시퀀스를 탐색하는 슬라이더 막대로 구성됩니다.
사용자 편집이 주어지면 z를 초기화하여 여러 다른 결과를 생성합니다. 사용자가 한 번의 편집을 마치면 슬라이더를 드래그하여 원본과 최종 조작된 사진 사이에 보간 된 모든 중간 결과를 볼 수 있습니다.
6. Implementation Details
1) Network architecture
DCGAN(Deep Convolutional Generative Adversarial Networks) [2]의 동일한 아키텍처를 따릅니다. DCGAN은 주로 다중 컨볼루션, 디컨볼루션 및 ReLU 레이어를 기반으로 하며 배치 정규화를 통해 최소-최대 교육을 용이하게 합니다.
100 차원 랜덤 벡터가 주어진 64 × 64 × 3 이미지를 생성하도록 생성기 G를 훈련합니다. 우리의 방법은 다른 생성 모델을 사용하여 자연 이미지 매니폴드를 근사화할 수도 있습니다.
2) Computational time
Titan X GPU에서 시스템을 실행합니다. 벡터 z의 각 업데이트(초기화)는 50~100밀리초가 걸리므로 실시간 이미지 편집 및 생성이 가능합니다. 편집이 완료되면 편집 전송 방식으로 고해상도 최종 결과를 생성하는 데 5~10초가 걸립니다.
- 새롭게 알게 된 내용
1. 매니폴드란?
실제 차원을 의미하는 것으로 지구가 3차원으로 둥근데 우리의 눈은 2차원으로 봅니다. 스위스롤도 신경망 모델의 입장에선 펼친 모양으로 알아듣겠지만 사실은 3차원 그 이상일 수 있습니다.
참고
'[AI] > [논문 리뷰, 분석]' 카테고리의 다른 글
| 논문 리뷰 PART.Transformer: Attention Is All You Need (0) | 2022.12.28 |
|---|---|
| 논문 리뷰 PART.FastText: Enriching Word Vectors with Subword Information (0) | 2022.12.26 |
| 논문 리뷰 PART.Word2Vec: Efficient Estimation of Word Representations in Vector Space (0) | 2022.12.25 |
| 논문 리뷰 PART.Sketch2Fashion: Generating clothing visualization from sketches (0) | 2022.11.22 |
| 논문 분석 PART.Tensorflow로 GAN 구현하고 학습하기 (0) | 2022.10.20 |



