
개발자로 후회없는 삶 살기
논문 리뷰 PART.Transformer: Attention Is All You Need 본문
서론
Attention Is All You Need는 기존 Seq2Seq의 문제점이었던 시간 의존도를 해결하는 아이디어를 제안합니다.
본 포스팅에서 주요 내용 위주로 논문을 번역/ 요약하였습니다.
> 논문에서는 Context Vector에 의한 시간 의존성으로 이해 입력 단어들 사이의 연관성이 사라지는 문제가 단어의 표현력을 저해함을 언급합니다. trasformer는 과거의 의미를 압축하는 Context Vector가 아닌 attention 기법을 활용하여 새로운 모델을 제안합니다. 틀린 내용이 있으면 피드백 부탁드립니다.
- 논문 제목 : Attention Is All You Need
- 저자 : Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser
본론
- 논문
[논문 1회독]
- Abstract
기존 sequence transduction model들은 인코더와 디코더를 포함한 복잡한 recurrent 나 cnn에 기반하였고 가장 성능이 좋은 모델 또한 attention mechanism으로 인코더와 디코더를 연결한 구조입니다. 이것은 Seq2Seq 모델에 attention 기법을 적용한 것입니다.
Transformer : 온전히 attention mechanism에만 기반한 구조이고 (recurrence 나 convolution은 사용하지 않습니다.) 병렬적으로 문서를 처리하고, 따라서 훨씬 적은 학습 시간이 걸립니다.
- 본론 Figure 미리 보기
=> Fig 1
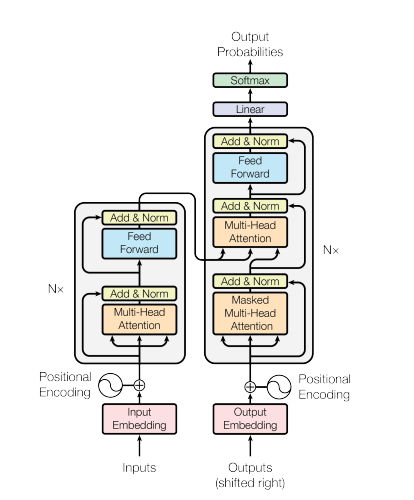
그림 1 : 트랜스포머 구조
=> Fig 3

그림 3 : attention을 시각화하여 보여준다. self 어텐션은 문장에서 attention 할 단어를 해당 문장에서 찾는다. making의 경우 해당 문장에서의 다른 단어에 각각 다른 영향을 받고 벡터로 임베딩 되어진다.
7. Conclusion
어텐션에 기반한 최초의 시퀀스 변환 모델인 Transformer를 제시하여 인코더-디코더 아키텍처의 recurrent 층을 멀티 헤드 셀프 어텐션으로 대체했습니다. 변환 작업의 경우 Transformer는 recurrent 계층을 기반으로 하는 아키텍처보다 훨씬 빠르게 학습할 수 있습니다.
[논문 2회독 (수식 + method experiment 위주)]
1. Introduction
Recurrent model은 parallelization이 불가능해 longer sequence length에서 치명적이다. Attention mechanism은 다양한 분야의 sequence modeling과 transduction model에서 주요하게 다뤄집니다. Attention mechanism은 input과 output sequence 간 길이를 신경 쓰지 않아도 됩니다.
Transformer는 input과 output간 global dependency를 뽑아내기 위해 recurrence를 사용하지 않고, attention mechanism만을 사용합니다.
2. Background
기존의 연구들은 모두 CNN을 basic building block으로 사용하였고 따라서 input output 거리에서 dependency를 학습하기 어려웠습니다.
-> Self-attenion(=intra-attention) : reading comprehension, abstractive summarization, textual entailment, learning task, independent sentence representations를 포함한 다양한 task에서 성공적으로 사용됩니다.
3. Model Architecture
3.1 Encoder and Decoder Stack
Encoder

=> 특징
1. Encoder는 6개의 identical layer로 이루어집니다.
2. 각 layer는 두 개의 sub-layer가 있습니다.
> 첫 번째 sub-layer는 multi-head self-attention mechanism이고, 두 번째 sub-layer는 간단한 position-wise fully connected feed-forward network입니다. 인코더 내부의 6개의 층 중 하나를 거치면 2 개의 sub-layer를 통과해야 합니다.
3. 각 two sub-layers 마다 layer normalization 후에 residual connection을 사용합니다. 즉 각 sub-layer의 결과는 LayerNorm(x+Sublayer(x)) 입니다.

이것은 어텐션을 거친 데이터와 거치지 않은 데이터의 결합을 의미합니다.
4. residual connection을 구현하기 위해, embedding layer를 포함한 모든 sub-layer들의 output은 512 차원입니다.
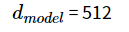
Decoder

=> 특징
ecoder도 마찬가지로 6개의 identical layer로 이루어집니다. 각 Encoder layer의 두 sub-layer에, decoder는 세 번째 sub-layer를 추가합니다. encoder stack의 결과에 해당 layer가 multi-head attention을 수행하고 마찬가지로 residual connection 적용합니다.
3.2 Attention
Attention function은 쿼리와 key-value쌍을 output에 매핑합니다. query,key,value,output은 모두 입력 단어를 vector에 매핑한 것입니다. output은 value들의 weighted sum으로 계산됩니다.
3.2.1 Scaled Dot-Product Attention

=> 특징
1. 입력 : 문서를 구성하는 단어들의 query, key의 dimension dk, value의 dimension dv
2. 모든 query와 key에 대해

dot product를 key를 전치하고 계산하고, √dk로 나눠주고, 각 단어 별로 가중치를 적용하기 위해 문서 내 단어의 value에 softmas를 적용합니다.
3.2.2 Multi-Head Attention

Single attention을 keys, values, queries에 적용하는 것보다 queries, keys, values를 h번 서로 다른, 학습된 linear projection으로 와dv차원에 linear 하게 project 하는 게 더 효과적이라는 사실을 알아냈습니다. 즉 Scaled Dot-Product Attention을 서로 다른 행렬로 linear projection을 하여 value에 대해 다른 연산 결과를 구하는 의도입니다.

project 된 각 값들은 병렬적으로 attention function을 거쳐 dv-dimensional output value를 만들어 냅니다. 이 value들을 합쳐서 최종 value를 만들어 내고 이것을 하나의 Multi-Head Attention의 임베딩으로 출력합니다.
3.3 Position-wise Feed-Forward Networks
인코더 디코더의 각 layer는 fully connected feed-forward network를 가집니다. 이는 각 position에 따로따로, 동일하게 적용되고 ReLu 활성화 함수를 포함한 두 개의 선형 변환이 이루어집니다.

3.5 Positional Encoding
Transformer는 recurrene와 달리 입력의 병렬 입력으로 위치를 알 수 없기 때문에 sequence의 순서를 사용하기 위해 sequence의 상대적, 절대적 position에 대한 정보를 주입해줘야 합니다. 이를 위해 transformer는 다른 주기의 sine, cosine function을 사용합니다.
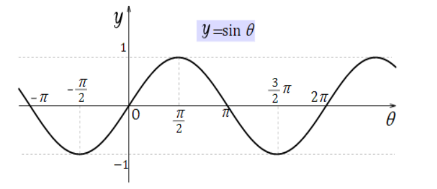

sin, cos과 같은 주기함수를 이용해 각 단어의 상대적인 위치정보를 입력으로 넣습니다. 또는 주기 함수를 사용하지 않고 임베딩 값을 학습하도록 바로 네트워크에 넣을 수도 있습니다. 두 방법에 성능 차이는 거의 없으며 Transformer 이후 모델은 임베딩 값을 바로 학습하도록 하는 방법을 많이 사용합니다.
5. Training
5.1 Training Data and Batching : WMT 2014 English-German 데이터셋을 사용하였습니다. 4.5백만 sentence pair로 문장들은 byte-pair 인코딩으로 인코딩 되어있습니다.
5.2 Hardware and Schedule : 8개의 NVIDIA P100 GPU로 학습하였고 base model은 12시간 동안 (100,000 step) 학습시켰으며, large model 은 3.5일 동안 (300,000 step) 학습시켰습니다.
5.3 Opimizer : Adam optimizer 사용하였습니다.
5.4 Regularization : 3가지 정규화를 하여 과대 적합을 막았습니다.
1) 각 sub-layer마다 dropout, 임베딩의 합과 positional 인코딩에 dropout, Label smooting 0.1을 적용하였습니다.



