
개발자로 후회없는 삶 살기
논문 리뷰 PART.Word2Vec: Efficient Estimation of Word Representations in Vector Space 본문
논문 리뷰 PART.Word2Vec: Efficient Estimation of Word Representations in Vector Space
몽이장쥰 2022. 12. 25. 22:08서론
Word2Vec는 단어를 모델이 이해할 수 있도록 수치 표현으로 변환하는 모델로 단어를 표현하는 방법을 설명합니다. 본 포스팅에서 주요 내용 위주로 논문을 번역/ 요약하였습니다.
> 논문에서는 Word2Vec 방식 2가지를 설명합니다. 두 방식의 모양은 서로 다르지만 결과적으로는 같은 목적을 이룹니다.
저자들은 이전 NLP 모델과 저자들의 모델을 비교하며 과거의 문제점을 위 논문으로 해결한 것을 중점으로 다룹니다. 틀린 내용이 있으면 피드백 부탁드립니다.
- 논문 제목 : Efficient Estimation of Word Representations in Vector Space
- 저자 : Tomas Mikolov, Kai Chen, Greg Corrado, Jeffrey Dean
본론
- 논문
[논문 1회독]
- Abstract
기존에 Neural NET Language Model과 Recuurnct Neural Net Languege Model 기반의 Word Representations의 시간복잡도를 분석하고 보다 더 효과적인 Word Representation 방법인 CBoW와 Skip-Gram을 제안하고 있습니다.
- 본론 Figure 미리 보기
=> Fig1
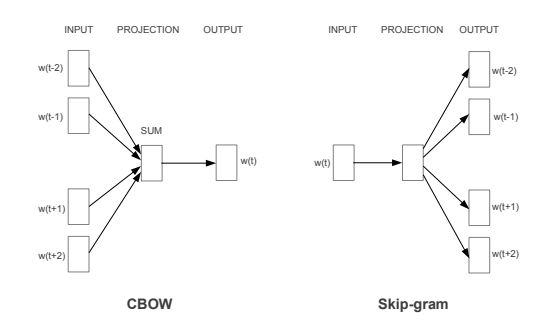
그림 1 : 두 개의 모델을 제시한다. CBOW는 주변 단어들을 통해서 현재 단어를 예측하고 Skip-gram은 현재 단어를 통해서 주변 단어를 예측합니다.
6. Conclusion
-> w2v의 장점 나열
1) 벡터 표현에 대한 성능을 다양한 모델을 이용해서 다양한 task에 대해서 측정했습니다.
2) 단순한 구조로도 뛰어난 성능의 word vector를 학습할 수 있다는 것을 알 수 있습니다.
3) 연산 비용이 매우 작기 때문에, 큰 차원의 큰 데이터셋에 대한 학습도 가능합니다.
[논문 2 회독 (수식 + method + experiment 위주)]
1. Introduction
현재(논문 발표 당시 2013년) NLP 시스템에서 사용되는 단어표현 방법들은 단어를 atomic unit으로 다루었고, 개별적인 단어를 표현할 뿐 단어 간의 유사성을 표현하지 못하였습니다. 대표적으로 통계적인 언어 모델링을 이용한 N-gram을 생각해 볼 수 있습니다.
> 하지만 이러한 단순한 기술은 많은 task에 한계를 가지고 있습니다. 많은 언어들은 충분하지 못 한 크기의 말뭉치를 가지고 있습니다. 이러한 상황에서 단순한 모델은 단어의 표현에 개선을 가져오지 못합니다. 따라서 우리는 보다 더 advecned techniques을 필요로 합니다.
2. Model Architectures

다른 모델들과 비교하여, 본 논문에서 훈련에 필요한 parameter의 수에 따른 계산복잡도를 정의합니다. 그다음 계산복잡도를 최소화하면서 정확도를 최대화하기 위한 방법을 모색합니다. 모든 모델에서 훈련의 시간 복잡도는 다음과 같은 요소에 비례합니다.
3. New Log-linear Models
연산량을 최소화하면서 단어의 분산 표현을 학습할 수 있는 새로운 두 모델의 구조를 제안한다. 이전 섹션에서 주요한 점은 연산의 복잡성이 non-linear hidden layer 때문입니다.
3.1 Continuous Bag-of-Words Model

CBoW model은 hidden layer가 제거되고 모든 단어가 projection layer를 공유하고 있는 형태의 feedforward NNLM과 유사합니다. 모든 단어는 같은 position으로 projection 됩니다. 훈련 복잡도는 다음과 같은 수식으로 표현될 수 있습니다.

그림을 보면 주변에 있는 단어들을 가지고 중간에 있는 단어를 예측하는 방법임을 알 수 있습니다.
3.2 Continuous Skip-gram Model

Skip-gram Model은 문맥을 기반으로 현재의 단어를 예측하는 대신에 같은 문장 안에서 다른 단어들을 기반으로 단어의 분류를 최대화합니다. 각각의 단어를 input으로 사용하여 정해진 범위들의 단어를 예측합니다. 범위를 증가시킬수록 word vector의 결과가 향상됨을 찾아냈습니다. 하지만 이는 역시 계산 복잡성을 증가시킵니다. Skip-gram의 훈련 복잡도는 다음과 같습니다.

C는 단어 간 거리의 최댓값입이다. 또한 본 논문에서는 C를 5로 선택하였습니다. 각각의 training word에 대하여 1~C 사이의 임의의 수 R을 선택하였고 R개의 과거단어와 미래단어를 현재 단어의 정답 label로 설정하였습니다.
4. Results
X = vector(”biggest”)−vector(”big”) + vector(”small”)
small에 대하여 big-biggest와 같은 유사성을 갖은 단어를 찾기 위해서는 X = vector(biggest) - vector(big) + vector(small)을 연산하고 벡터 공간에서 X와 cosine 거리가 가장 가까운 단어를 찾으면 vector(smallest)를 구할 수 있습니다.
본 논문에서는 많은 데이터를 가지고 훈련한 고차원의 word vector의 결과는 단어 사이의 매우 미묘한 의미적인 표현에 사용할 수 있음을 밝혔습니다. 이러한 의미를 표현할 수 있는 word vector는 NLP application의 성능을 향상할 수 있을 것입니다.
'[AI] > [논문 리뷰, 분석]' 카테고리의 다른 글
| 논문 리뷰 PART.Transformer: Attention Is All You Need (0) | 2022.12.28 |
|---|---|
| 논문 리뷰 PART.FastText: Enriching Word Vectors with Subword Information (0) | 2022.12.26 |
| 논문 리뷰 PART.Sketch2Fashion: Generating clothing visualization from sketches (0) | 2022.11.22 |
| 논문 분석 PART.Tensorflow로 GAN 구현하고 학습하기 (0) | 2022.10.20 |
| 논문 리뷰 PART.Generative Visual Manipulationon the Natural Image Manifold (0) | 2022.10.19 |



