
개발자로 후회없는 삶 살기
논문 분석 PART.Tensorflow로 GAN 구현하고 학습하기 본문
서론
이번 포스팅에서는 Tensorflow로 구현한 GAN을 MNIST dataset으로 학습한 후, 학습된 generator이 생성한 가짜 이미지를 확인하는 것을 목표로 한다. 작업 환경은 Google Colab에서 진행합니다.
-> 전체 코드
https://github.com/SangBeom-Hahn/AI_Paper_Review_Analysis/tree/main/Vanila_Gan
GitHub - SangBeom-Hahn/AI_Paper_Review_Analysis
Contribute to SangBeom-Hahn/AI_Paper_Review_Analysis development by creating an account on GitHub.
github.com
본론
- 목차
1. 학습에 필요한 util 함수들 정의
2. GPU 셋팅
3. 모델 구축
4. 학습
5. generator이 생성한 가짜 이미지 확인하기
- 참고한 코드 :
https://github.com/eriklindernoren/PyTorch-GAN/blob/master/implementations/gan/gan.py
GitHub - eriklindernoren/PyTorch-GAN: PyTorch implementations of Generative Adversarial Networks.
PyTorch implementations of Generative Adversarial Networks. - GitHub - eriklindernoren/PyTorch-GAN: PyTorch implementations of Generative Adversarial Networks.
github.com
official GAN 논문의 모델 구현 부분만 참고했습니다.
- 라이브러리 정의
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow.keras.datasets import mnist
from tensorflow.keras.layers import Dense, Flatten, Reshape
from tensorflow.keras.layers import LeakyReLU
from tensorflow.keras.models import Sequential
from tensorflow.keras.optimizers import Adam
import os
from keras.models import model_from_json
import time
1. 학습에 필요한 util 함수들 정의
# 가중치 저장 함수
def save_weight_to_json(model):
cur_dir = os.getcwd()
ckpt_dir = "checkpoints"
file_name = "gan_weights.ckpt"
dir = os.path.join(cur_dir, ckpt_dir)
os.makedirs(dir, exist_ok = True)
file_path = os.path.join(dir, file_name)
model.save_weights(file_path)
model_json = model.to_json()
with open("model.json", "w") as json_file :
json_file.write(model_json)
# 가중치 로드 함수
def load_weight_to_json():
json_file = open("model.json", "r")
loaded_model_json = json_file.read()
json_file.close()
loaded_model = model_from_json(loaded_model_json)
# 그래프를 생성하는 함수
def plotLoss(G_loss, D_loss, epoch):
cur_dir = os.getcwd()
loss_dir = "loss_graph"
file_name = 'gan_loss_epoch_%d.png' % epoch
dir = os.path.join(cur_dir, loss_dir)
os.makedirs(dir, exist_ok = True)
file_path = os.path.join(dir, file_name)
plt.figure(figsize=(10, 8))
plt.plot(D_loss, label='Discriminitive loss')
plt.plot(G_loss, label='Generative loss')
plt.xlabel('BatchCount')
plt.ylabel('Loss')
plt.legend()
plt.savefig(file_path)
# 이미지를 저장하는 함수
def sample_images(epoch, latent_dim = 128):
cur_dir = os.getcwd()
image_dir = "images"
file_name = '%d.png' % epoch
dir = os.path.join(cur_dir, image_dir)
os.makedirs(dir, exist_ok = True)
file_path = os.path.join(dir, file_name)
r, c = 5, 5
noise = np.random.normal(0, 1, (r * c, latent_dim))
gen_imgs = generator.predict(noise)
# Rescale images 0 - 1
gen_imgs = 0.5 * gen_imgs + 0.5
fig, axs = plt.subplots(r, c)
cnt = 0
for i in range(r):
for j in range(c):
axs[i,j].imshow(gen_imgs[cnt, :,:,0], cmap='gray')
axs[i,j].axis('off')
cnt += 1
fig.savefig(file_path)
plt.close()
# 모델을 로드하는 함수
def load_model(model, model_path='saved_model/model.h5'):
print('\nload model : \"{}\"'.format(model_path))
model = tf.keras.models.load_model(model_path)
# 모델을 저장하는 함수
def save_model(model, model_path='saved_model/model.h5'):
print('\nsave model : \"{}\"'.format(model_path))
model.save(model_path)학습에 필요한 유틸리티 함수들을 선언합니다. 학습 시 생기는 산출물들을 저장하고 불러오는 함수들입니다.
2. GPU 셋팅
1) 가능한 GPU 리스트 보기
tf.config.list_physical_devices('GPU')
# 결과
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
2) GPU 사용이 가능한지 확인
tf.test.is_gpu_available()
# 결과
True
3) GPU 사용하기
tf.device('/device:GPU:0')
# 결과
<tensorflow.python.eager.context._EagerDeviceContext at 0x7fb700087e10>위에서 사용 가능하다고 나온 GPU:0을 사용합니다.
3. 모델 구축
1) generator
def build_generator(img_shape, z_dim):
model = Sequential()
model.add(Dense(n_hidden, input_dim = z_dim)) # 인풋은 100 다음은 128개의 노드
model.add(LeakyReLU(alpha = 0.01))
model.add(Dense(28 * 28 * 1, activation="tanh")) # 128개의 노드 다음은 784개의 노드
model.add(Reshape(img_shape))
return model데이터의 복잡도가 낮기에 모델의 용량을 작게 하였습니다.
2) discriminator
def build_discriminator(img_shape):
model = Sequential()
model.add(Flatten(input_shape = img_shape)) # 이미지 모양대로 입력받아서 flat
model.add(Dense(n_hidden))
model.add(LeakyReLU(alpha=0.01))
model.add(Dense(1, activation="sigmoid"))
return model
4. 학습
1) GAN 모델 선언
def build_gan(generator, discriminator):
model = Sequential()
# 생성자 -> 판별자로 연결된 모델
model.add(generator)
model.add(discriminator)
return modeldiscriminator = build_discriminator(img_shape)
discriminator.compile(loss="binary_crossentropy", # 판별자의 이진 분류
optimizer=Adam(),
metrics=['accuracy'])
generator = build_generator(img_shape, z_dim)
discriminator.trainable = False # 생성자를 훈련하는 동안 판별자가 훈련되지 않도록 동결
gan = build_gan(generator, discriminator)
gan.compile(loss='binary_crossentropy', optimizer=Adam())
2) train 코드
def train(total_epoch, batch_size, sample_interval):
# MNIST 데이터셋 로드
(X_train, _), (_, _) = mnist.load_data()
# [0, 255] 흑백 픽셀 값을 [-1, 1] 사이로 스케일 조정 ∵ 생성자의 끝이 tanh라서 판별자의 모든 입력 범위를 맞춰야함
X_train = X_train / 127.5 - 1.0 # -> 0 / 127.5 = 0 > 0-1 = '-1'/ 255 / 127.5 = 2 > 2-1 = '1'
X_train = np.expand_dims(X_train, axis=3) #60000, 28, 28, 1
# 진짜 이미지 레이블: 모두 1
real = np.ones((batch_size, 1))
# 가짜 이미지 레이블: 모두 0
fake = np.zeros((batch_size, 1))
D_loss_list = [] # 오차 그래프를 그리기 위한 손실이 저장될 배열
G_loss_list = []for iteration in range(total_epoch):
# 판별자 훈련
# real 이미지에서 랜덤 배치 가져오기 -> 랜덤한 정수 추출
idx = np.random.randint(0, X_train.shape[0], batch_size) # 0 ~ 60000 사이의 수에서 128개의 수를 뽑음
imgs = X_train[idx] # 그것을 fancy 인덱싱하면 랜덤으로 뽑은 수(행)에 해당하는 mnist 이미지가 생김
# fake 이미지 배치 생성
z = np.random.normal(0, 1, (batch_size, z_dim)) # z로 0 ~ 1의 수 128행 100열을 만듬
gen_imgs = generator.predict(z)
# 판별자 훈련
d_loss_real = discriminator.train_on_batch(imgs, real)
d_loss_fake = discriminator.train_on_batch(gen_imgs, fake)
d_loss, accuracy = 0.5 * np.add(d_loss_real, d_loss_fake)
# 생성자 훈련
# fake 이미지 배치 생성
z = np.random.normal(0, 1, (batch_size, z_dim)) # fake 이미지에 넣을 크기 100(z_dim = 100차원)의 벡터를 생성
gen_imgs = generator.predict(z)
# 생성자 훈련
g_loss = gan.train_on_batch(z, real) # 가짜가 1이라고 말함
G_loss_list.append(g_loss)
D_loss_list.append(d_loss)
print ("%d [D loss: %lf, acc.: %.2lf%%] [G loss: %lf]" % (iteration, d_loss, 100*d_loss, g_loss))
if total_epoch % sample_interval == 0: # 인터벌마다 생성자가 이미지 생성
sample_images(total_epoch)
plotLoss(G_loss_list, D_loss_list, total_epoch)
3) 손실 그래프 출력
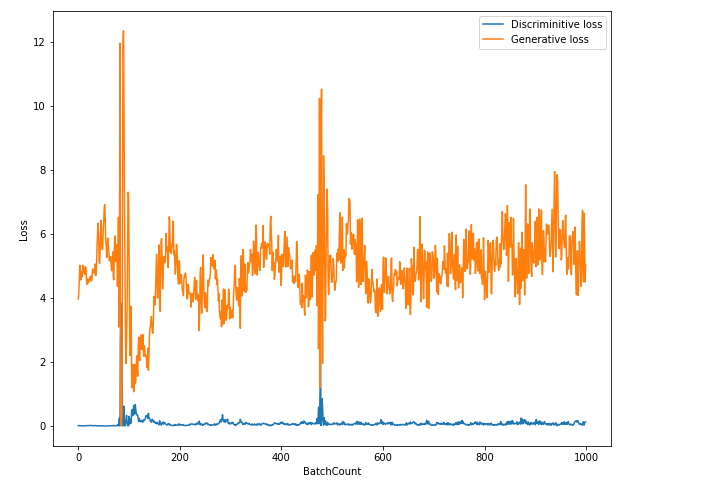
400 에폭까지는 생성자 손실이 갈피를 잡지 못하다가 500 에폭 이후 내시 균형을 이루는 모습을 보입니다.
5. generator이 생성한 가짜 이미지 확인하기

1000 에폭을 하였지만 좀 더 많은 학습이 필요해 보입니다. 모델의 깊이가 낮아서 그럴 수도 있습니다.



