
개발자로 후회없는 삶 살기
논문 리뷰 PART.FastText: Enriching Word Vectors with Subword Information 본문
논문 리뷰 PART.FastText: Enriching Word Vectors with Subword Information
몽이장쥰 2022. 12. 26. 11:47서론
FastText는 train 데이터에 등장하지 않은 단어들도 표현가능한 단어 표현 모델입니다. 본 포스팅에서는 주요 내용 위주로 논문을 번역/ 요약하였습니다.
> 논문에서는 Word2Vec의 문제점을 다루면서 시작합니다. 저자들은 그 문제점의 중요성을 말하고 극복하기 위한 새로운 모델을 제시합니다. 결과적으로 Word2Vec와 동일하게 단어를 표현하는 모델을 제안합니다. 틀린 내용이 있으면 피드백 부탁드립니다.
- 논문 제목 : Enriching Word Vectors with Subword Information
- 저자 : Piotr Bojanowski, Edouard Grave, Armand Joulin, Tomas Mikolov
본론
- 논문
[논문 1회독]
- Abstrack
Word2Vec에는 한계점이 있습니다. training data로 등장하지 않은 rare word의 경우 정확한 vector embedding이 어렵습니다. 이를 OOV(Out of Vocabulary) 문제라고 합니다.
> 또한 단어의 형태학적 특징을 반영하지 못합니다. 유사한 의미의 개별적 단어가 문맥 정보를 기반으로 unique 하게 학습이 되는 문제가 발생합니다.
본 논문에서는 skipgram을 기반으로 각 단어가 문자 n-grams 벡터의 조합으로 표현하여 위의 문제를 해결합니다. 벡터 표현은 각 문자 n-gram과 연관되어 있으며, 단어들은 이러한 표현의 합을 표현합니다. 이 방법은 큰 말뭉치에서도 속도가 빠르고 train 데이터에 등장하지 않은 단어들도 표현 가능합니다.
- 본론 Figure 미리 보기
=> Fig1

훈련 데이터의 크기가 성능에 미치는 영향을 보여줍니다. 증가하는 크기의 데이터 세트를 사용하여 제안된 모델에 따라 단어 벡터를 계산합니다.
7. Conclusion
본 논문에선 subword 정보를 통해 단어 표현을 학습하는 방법에 대해 알아보았습니다. 기존 skip-gram 기반의 단어 표현에 character n-gram의 subword 정보를 고려한 모델입니다. 이 모델은 단순하기 때문에 빠르게 훈련하며 사전 처리나 감독이 필요하지 않습니다. 결론적으로, 성능이 좋고 형태적 분석에 의존한 방법입니다.
[논문 2회독 (수식 + method + experiment 위주)]
3. Model
3.1 General model
word2vec model은 총 W개의 단어가 있을 때, 각 단어들에 대해 벡터를 할당해주고 주변에 어떤 단어가 올 지 잘 예측할 수 있는 방향으로 학습을 진행했습니다.

총 T개의 단어들이 있고 w_t(하나의 단어)가 주어졌을 때 w_c(주변의 문맥단어)에 어떤 단어가 와야 확률값이 가장 높은 지를 최적화하였습니다.
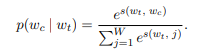
위의 두 벡터를 가지고 확률값을 가지는 방법은 softmax를 사용합니다. 그러나 softmax 함수는 w_t에 대해 w_c 하나에 대해서는 잘 맞출 수 있지만 주위 다른 단어들은 잘 예측하지 못합니다. 그래서 word2vec에서는 softmax 대신 negative sampling을 사용합니다.

softmax는 다중분류에 반에 이것은 이진분류입니다. 전체 단어 집합이 아닌, 일부 단어에만 집중합니다. 여기서 주변 단어를 positive로 하고 랜덤으로 샘플링된 단어를 negative로 놓습니다.
3.2 Subword model
Word2Vec은 쪼갤 수 있는 최소 단위가 단어입니다. Subword model은 하나의 단어 안에도 여러 단어들이 존재하다록 합니다. 따라서 글자 단위 n-gram을 구성합니다.
Ex) where
→ <wh ,whe, her, ere, re> 그리고 < where>3-grams라면 2개의 subword만 다룹니다. 단어를 n-gram 벡터의 합으로 나타냅니다.

| g | 모든 n-gram 딕셔너리 사이즈 |
| g_w | 단어 w에서 나올 수 있는 모든 n-gram 경우의 세트 |
| z_g | n-gram의 모든 각각의 벡터 표현 |
한 단어에서 나올 수 있는 모든 n-gram을 추출한 다음 각각의 벡터들을 다 더해서 새로운 score를 만드는 것입니다.
-> 장점
1) OOV에 대한 학습 능력이 향상됩니다.
2) 오타와 같은 빈도수가 낮은 단어에 대한 학습 능력이 향상됩니다.
5. Result
5.1 Human similarity judgement

사람의 유사도 평가와 워드 벡터의 코사인 유사도 사이의 상관계수를 측정하였습니다. 총 7개의 language dataset에 대한 sg, cbow, sisg 성능을 비교하였습니다. EN dataset을 제외한 다른 모든 언어에서 논문이 제안한 sisg 방법이 다른 방법에 비해 우수한 성능을 보입니다.
5.2 Word analogy tasks
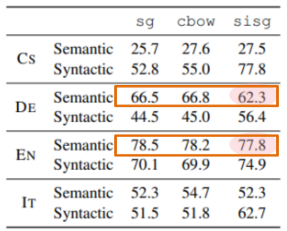
단어 간의 의미가 벡터 상에 선형적으로 잘 보존되었는지 확인합니다. ex) King-Man = Queen
> syntatic(구조적, 구문론적) task 는 baseline보다 성능이 뛰어납니다. 반대로, semantic(의미적) question에서는 뛰어나지 않고, 심지어 German과 Italian에서는 성능이 떨어짐. n-grams의 size가 적절히 선택되면 개선할 수 있습니다.
5.3 Comparison with morphological representations

단어 유사성 작업에서 subword information을 단어 벡터에 포함하는 단어 벡터에 대한 이전 연구와 본논문의 접근 방식을 비교합니다. 형태학적 분할자에 기반한 모델보다 sisg가 더 좋은 성능을 냅니다.
5.4 Effect of the size of the training data

학습 데이터의 양을 조금씩 늘려보면서 모델별로 최상의 성과가 나타나는 지점을 찾았습니다.
1) cbow는 의미상으로 좋은 성능을 보이기 때문에 데이터가 많을수록 향상됩니다.
2) sisg는 데이터가 많을수록 성능이 향상되지는 않습니다. 따라서 효과적인 사이즈의 데이터가 필요합니다. 또한 적은 데이터에도 학습이 가능합니다.
5.5 Effect of the size of n-grams

지금까진 임의적으로 3~6자 범위의 n-gram을 사용했다. n으로 어떤 숫자가 적절할지 실험해 보았습니다. 위 그림을 보면 영어와 독일어 모두 임의의 선택이었던 3~6에서 좋은 성능을 보입니다. 최적의 길이 범위 선택은 작업 및 언어에 따라 달라지며 적절하게 조정되어야 합니다. 합성어가 많은 독일어 같은 경우 larger n-grams를 사용했을 때 성능이 높은 것을 볼 수 있습니다.
5.6 Language modeling

sisg가 모든 언어에서 다른 모델(LSTM, sg)보다 좋은 성능을 보이는 것을 볼 수 있습니다. 사전 훈련된 단어 표현으로 언어 모델의 lookup table을 초기화하면 기준 LSTM에 대해 test perplexity가 개선됩니다.
∴ 언어 모델링 태스크에 subword 정보의 중요성을 보여주고 형태학적으로 풍부한 언어에 이 논문의 모델의 벡터가 유용하다는 것을 보여줍니다.



