
개발자로 후회없는 삶 살기
CV PART.RCNN의 발전 본문
서론
※ 이 포스트는 다음 강의의 학습이 목표임을 밝힙니다.
https://www.youtube.com/playlist?list=PLpkj8RKr48wZAx6jXEcpOQca5A1yCoNJr
[개정판] 딥러닝 컴퓨터 비전 완벽 가이드
www.youtube.com
본론
- 객체 탐지 네트워크 개요

객체 탐지는 이렇게 구성되어 있습니다.
1. feature extraction 네트웤
2. object detection 네트웤
3. region porposal 영역( 있을 수도 있고 없을 수도 있음 )

1은 이미지 분류를 위해 feature map을 만드는 것으로 백본이라고 부르고 원본이미지에서 점점더 사이즈는 작고 깊이는 깊은 map을 만드는 것입니다. 그리고 만들어진 feature map을 가지고 클래스 분류를 위해 FC 레이어와 연결되었습니다. 1번은 딱 FC와 연결되기 전까지만 말합니다. 보통 이미지넷 데이터 셋으로 사전학습 되어있는 것을 가져옵니다. 이렇게 뽑은 map을 가지고 객체 탐지를 할 것입니다.
> 객체 탐지 네트워크는 별도의 네트워크로 되어있습니다. 사진을 보면 햇번과 그레고리페의 객체 크기가 크기 때문에 큰 객체들을 어떻게 할것인가, bbox, cls를 어떻게 계산할 것인가에 대한 것들이 객체 탐지 모델에 들어있습니다. 앞으로 이런 것들에 대해서 배울 것입니다. RP는 객체가 있을 만한 위치를 계산을 해주는 것으로 네트워크로 존재할 수도 있습니다.
-> 선명도, FPS와 탐지의 성능 상관 관계

Image Resolution(이미지 선명도)는 이미지 사이즈로 가정을 할 것이고 높은 선명도면 탐지 성능이 좋습니다. 선명도가 높아지면 FPS(1초에 탐지할 수 있는 이미지 개수)가 적어집니다. 왜냐하면 선명도가 높아지려면 배열의 크기가 커지기 때문입니다. 예를 들어서 욜로 288 x 288로 하면 FPS가 91이고 mAP가 69입니다. 반대로 544 x 544는 FPS가 40이고 mAP가 78.6입니다. 따라서 FPS가 빨라야하는 요구사항이면 객체탐지 성능이 떨어집니다. 즉 우리는 두마리 토끼를 다 잡기를 원하는데 그런게 어렵습니다. 이 강의를 통해 '이런 상황에서는 이런 탐지 모델', '저런 상황에서는 저런 탐지 모델'을 선택할 수 있는 가이드를 줄 것입니다.
- RCNN의 이해

RCNN은 SS를 적극적으로 도입하는 것과 동시에 RP에서 예측이 된 객체들을 어디에 짚어 넣냐면 CNN 모델에 넣게 됩니다. 처음에 예측은 SS를 통해서 2000개의 객체가 있을 만한 위치를 제안합니다.(하나의 이미지에 2000) 2000개의 mini 이미지를 다시 사이즈를 동일하게 맞춘 다음에 CNN 네트워크에 짚어넣어서 학습을 시킵니다.
> 2000개가 모델에 들어갈 때 이미지 사이즈가 동일해야합니다. 그 이유는 1D FC 레이어에서 사이즈가 얼마인지가 명시가 되어있어야합니다. 512 X 7 x 7의 feature map을 사이즈가 정해진 1D로 만들 것이기 때문에 2000개의 이미지로 만들어진 feature map의 사이즈가 동일해야했습니다. faeture map의 사이즈가 동일하려면 입력 이미지의 사이즈가 동일해야합니다. (아니 애초에 cnn은 크기가 동일해야합니다.) 근데 2000개는 이미지 사이즈가 다 다르니 다 찌그러트려줘야합니다.
> 보통 CNN에서 마지막에 소맥을 해서 분류를 하는데 RCNN에서는 소맥을 안쓰고 SVM 분류기를 붙였습니다. 이게 무슨 말이냐면 딥러닝은 FC 레이어에서 끝이고 나는 딥러닝 모델의 출력을 받아서 다시 SVM을 적용을 하겠다는 것입니다. 따라서 특징 추출부분에서만 딥러닝을 썼고 이후에는 SVM을 썼습니다. SVM도 따로 SS도 또 따로 있었습니다.
-> RCNN 특징 정리

입력 이미지가 있습니다. 이걸 RP로 2000개를 쪼갭니다. CNN에 들어가는 입력 사이즈는 동일해야합니다. 그래서 2000개를 다 찌그러뜨립니다. 따라서 이미지가 깨집니다.(warp) 그렇게 구한 feature map을 SVM에 넣는습니다. 또한 2000개를 각각 CNN을 해야하고 SS를 해야해서 느립니다. 이걸 추론할 때도 2000개를 구하기에 느립니다.
- 학습 방법
=> 분류

1. 원본 이미지의 GT 어노테이션이 있습니다. 원본 이미지에 SS를 하면 GT가 있는 반면에 SS의 예측도 있을 것이고 이게 정확히 겹치는 것도 있고 아닌 것도 있습니다.
2. 이미지 넷으로 학습된 alexnet을 준비하고 내가 준비한 이미지 데이터로 튜닝을 할 것입니다. 근데 그냥 GT로만 학습하면 안 되고 SS가 예측한 객체가 있을 만한 위치를 함께 Alexnet 튜닝하는데 넣어 학습을 해야합니다.
> 그렇게 하기 이해 GT와 SS 중에 IoU가 0.5 이상인 경우만 GT 라벨로하고 이하는 background로 하여 학습을 합니다. back도 학습에 사용합니다. SS가 2000개 나오는데 그중 back과 GT라벨로 라벨링을 해서 튜닝을 합니다.
3. 특징 맵을 1차원으로 만들고 이걸로 SVM을 학습시킵니다. SVM의 클래스 개수를 내가 준비한 데이터의 클래스 개수로 잡고 학습합니다. 그니깐 SVM은 객체 탐지 딥러닝 부분과는 또 따로 학습을 시킨 것입니다. 객체 탐지부와 SVM을 따로 다른 데이터로 학습을 한 것입니다. CNN은 2000개 전체로 학습하고 SVM은 GT로만 학습하여 각각 따로 학습하고 나중에 연결한 개념입니다.
=> reg

빨간색이 GT고 검은색이 ss로 예측된 것인데 가운데에 px, py, 너비 높이 pw, ph가 있습니다. 이 모델이 목표로 하는게 뭐냐면 예측된 p xy하고 GT x,y하고 거리가 최소가 될 수 있도록 RPN 모델이 만들어져야 합니다. 거리뿐만 아니라 pw와 GT w와의 차이도 최소가 되야했습니다.
> 모델의 예측값을 이렇게 기준을 잡습니다. 우리가 예측할 bbox의 센터 x(g햇x), y(g햇y)를 찾는다고 한다면 ss가 제안한 px, py에 대하여 pw만큼 가중치를 곱하고 dx(P)를 곱해서 예측값을 만듭니다. 이런식을 세워서 로스값을 최소화 시킬 수 있는 것을 구하는 것이고 우리가 결국 구하고 싶은 것은 dx(P)가 얼마가 되어야 실제 GT x인 gx와 얼마나 가까워질까를 구하는 것이고 px는 고정값이니 dx(P)가 얼마가 되어야할까가 모델이 찾아줘야하는 값입니다. dx(P)를 갱신하는 것이다. gx와 g햇x의 차가 최소가 될 수 있도록 dx(P)를 구하는 것입니다.
> 너비 높이는 pw에 exp로 dw(p)를 곱합니다. 역시 dx(p)를 구해서 g햇w와 gw가 가깝도록 학습을 합니다. 결국은 gt와 예측하는 값의 차이가 0에 가깝도록 합니다. 이를 reg에서 target을 이렇게 나와줘야한다고 별도로 정했습니다. t는 어떤 목표를 하냐면 gx - px가 0이 되면 좋고 w단위로 정규화를 시켜 안정적인 학습을 하고자 했습니다. 이렇게 식을 정하고 손실함수를 정해서 bbox reg를 정의를 했습니다.
> ★ 손실함수를 보면 정의한 target - 갱신할 d(p)의 차이가 0이 되도록 학습합니다.
- SPP Net
fast rcnn이 이 모델을 채용 하기에 미리 알아두면 좋습니다.
-> RCNN의 문제점
느리다. 하나의 이미지에서 2000개를 뽑는게 진짜 너무 느립니다. 학습도 오래걸리고 추론도 느립니다.

이를 개선하면 원본 이미지에 SS로 추출한 2000개를 CNN에 넣어 feature map을 뽑을텐데 바로 CNN에 넣지 말고 원본 이미지를 CNN에 넣어서 feature map을 만듭니다. 그 후 SS에서 찾은 추천되는 영역을 feature map에 맵핑하면 이미지 한번 만 넣으면 되니 2000번 CNN에 입력 시키는 것보다 좋습니다.
> 근데 이것이 당시에는 안됩니다. 분류를 하려면 Dense를 해야하는데 feature map이 3차원인데 마지막 FC 레이어가 정해져있습니다. 예를 들어 13 * 13 * 512의 feature map이라면 13 * 13 * 512 크기의 dense로 받아야 한다는 것입니다. 이렇게 하려면 dense의 뉴런 수를 고정을 해야하는 것인데 이러면 feature map도 dense 크기에 맞게 고정을 해야합니다. 근데 feature map에서 SS 영역을 맵핑하면 각 맵핑 사이즈가 달라서 고정이 안됩니다.
> 결국 학습을 시키려면 아까 RCNN에서 본 것처럼 GT와 back과 해당 레이블의 SS 제안 영역을 CNN에 넣어서 feature map을 뽑고 학습을 시켜야하는데 맵핑 사이즈가 다르니 학습을 할 수가 없습니다. 그래서 rcnn 방법을 쓴 것이었습니다.(pooling이 필요합니다.)
=> SPP Net

이것을 하게 한 것이 spp 넷으로 각각 다른 사이즈를 맵핑할 수 있는 별도의 레이어를 만들자라는 것입니다. 먼저 인풋이미지 사이즈를 고정하지 말고 다양하게 들어오되 fc와 맵핑할 수 있는 별도의 레이어를 두면 사이즈가 바뀌어도 아무문제가 없다는 것입니다.
1. spatial pyramid matching에서 출발

bag of visual words라고 해서 이미지 분류를 해야한다면 이미지를 짤라서 가방에 넣고 예를들어 여성 사진이라면 귀, 눈, 코 등 특징들을 짤라서 가방에 넣고 거기서 bow가 가방에서 빈도수가 많은 것을 결론으로 내는 것처럼 귀가 많으면 여성이라고 결론을 내는 개념입니다. 이렇게 분류를 하는 방식입니다.
-> bovw의 문제점
귀만 많이 나온다고 여성이라고 볼 수는 없습니다. spatial라는 위치라는 개념이 들어가야합니다. 이 위치에 어떤 특성이 있는지를 나타내야합니다.
2. spatial pyramid matching

위치를 봐서 어떤 특성이 있는지 보는 것으로 이 특징들이 해당위치에서 어떻게 표현되는지 정보화하게 되는 것이고 이 정보를 기반으로 분류를 합니다. 왼쪽은 위치 정보를 보지 않은 쪼개지 않은 경우이고 오른쪽은 위치를 봐서 이 위치별 특성 정보를 봐서 분류를 한 것입니다.
> 이런 이미지의 위치 정보를 유지하면서 새로운 특징 정보를 추출해서 분류를 하는 것이 spm입니다. 중요한 것은 뭐냐면 이것과 feature map 맵핑되는 객체들의 크기가 달라지는 것과 무슨 상관이 있냐면
-> 객체의 크기에 대입하자면

클래스가 3개라면 맨 위 이미지는 한개의 영역에서 3개를 고르니 3개의 히스토그램을 얻게됩니다. 가운데는 4개의 영역에서 3개의 히스토그램이 나옵니다. 이런식으로 해서 3 + 12 + 48 = 63개의 원소의 벡터로 표현할 수 있습니다. 지금 원본이 8 * 8로 들어왔다고 해도 다른 크기로 들어와도 다 1개의 영역 4개, 16개로 나눌 것이라서 입력 크기가 어떻든 63개의 vector로 표현되는 것은 똑같습니다. ★ 이미지를 63개의 벡터로 만들 수 있습니다!
3. spatial pyramid pooling

분면을 나눈다는 것이 cnn에서는 풀링개념과 유사합니다. 풀링을 한다는 것은 원본 feature map에서 가장 큰값을 뽑아내는 것입니다. 아까는 영역을 나누고 히스토그램을 구한건데 이제는 진짜 max pooling을 해서 원본 이미지를 21개의 벡터로 만듭니다. 이렇게 하면 입력 이미지의 크기가 달라져도 21개의 벡터로 표현가능합니다.
4. spatial pooling net(spp net)

서로 다른 사이즈의 feature map이 입력으로 들어와도 16, 4, 1로 21개의 벡터로 만듭니다. 그 어떤 사이즈의 feature map이 들어와도 출력은 달라지지 않습니다. 근데 이렇게 까지 가공해도 정보 손실이 없을까요? 근데 테스트 결과 손실대비 이미지 사이즈가 고정되면서 warp보다 훨씬더 성능이 좋습니다!
-> 이를 객체 탐지에 적용

원본 이미지를 cnn에 넣어 뽑은 feature에서 ss에서 가져온 영역을 맵핑한 결과 크기가 저 핑크색으로 다양할 수 있습니다. 그럼에도 저렇게 분면을 16 4 1로 나눠서 가면 출력 사이즈는 변하지 않습니다. 이제 이상태에서 FC로 넣으면 되지 않느냐! 라는 것입니다.
- fast rcnn
rcnn을 해결하여 원본 이미지의 feature map에 매칭된 2000개의 사이즈가 다른 ss를 spp layer로 크기를 통일시켜 속도를 향상시켰습니다.(fast)

spp와 비슷하게 roi pooling을 합니다. spp 대신에 풀링하는 것과 svm이 아닌 소맥을 쓰는 것, 그리고 multi loss 함수로 cls와 reg를 함께 최적화하여 end to end network learning을 합니다. 즉 분류를 딥러닝 안으로 들어오게 만들었습니다. (이제 남은 것은 SS를 딥러닝 안으로 들어오게 만드는 것뿐입니다.)원래는 svm이 밖에서 학습을 하고 reg만 딥러닝 안에 있었는데 둘이 합쳐서 total loss로 만들었습니다.
=> roi pooling

원본 이미지를 cnn에 넣어서 14 x 14 feature map을 구하고 여기에 SS로 8 x 4 roi를 구했습니다.( 이 영역이 SS가 말해주기를 객체가 있을 것이라고 해주는 곳입니다.) 8 x 4에서 4등분해서 max를 뽑아냅니다.
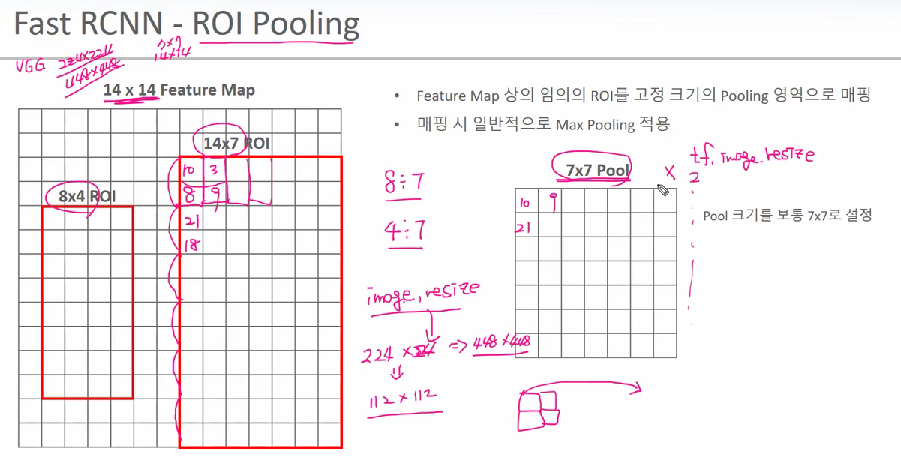
> 이게 max pool과 다른게 뭔지 싶을 텐데 fast rcnn에서는 roi pooling을 조금 다르게 했습니다. 무조건 pooling 결과를 7 x 7로 맞춥니다. 14 * 7에서 2행 1열짜리 filter로 7 x 7짜리 pooling을 합니다. 8 x 4라면 보간법을 적용합니다. 이미지 resize를보면 늘리는 건 보간법을 적용하여 원래 픽셀의 근처에있는 값으로 유추를 해서 늘립니다. 이와 유사하게 8행을 7행으로 만들기 위해 마지막 두개의 행을 더해서 2로 나눈다거나 4열을 7열로 만들기 위해서 보간법으로 resize 메서드로 키웁니다. 이것을 실제로 코드에서는 tf.image.resize를 써서 7 x 7로 만들어버립니다.(꾸겨 넣어버리는 것입니다.)
> 이렇게 해서 고정된 7 x 7 pooling이 발생합니다. 결과적으로 SS가 2000개라서 7 x 7이 2000의 dep를 가지는 feature map이 되고 이것을 98000 뉴런 개수의 dense로 넣을 수 있게 됩니다.
=> 전체 fast rcnn
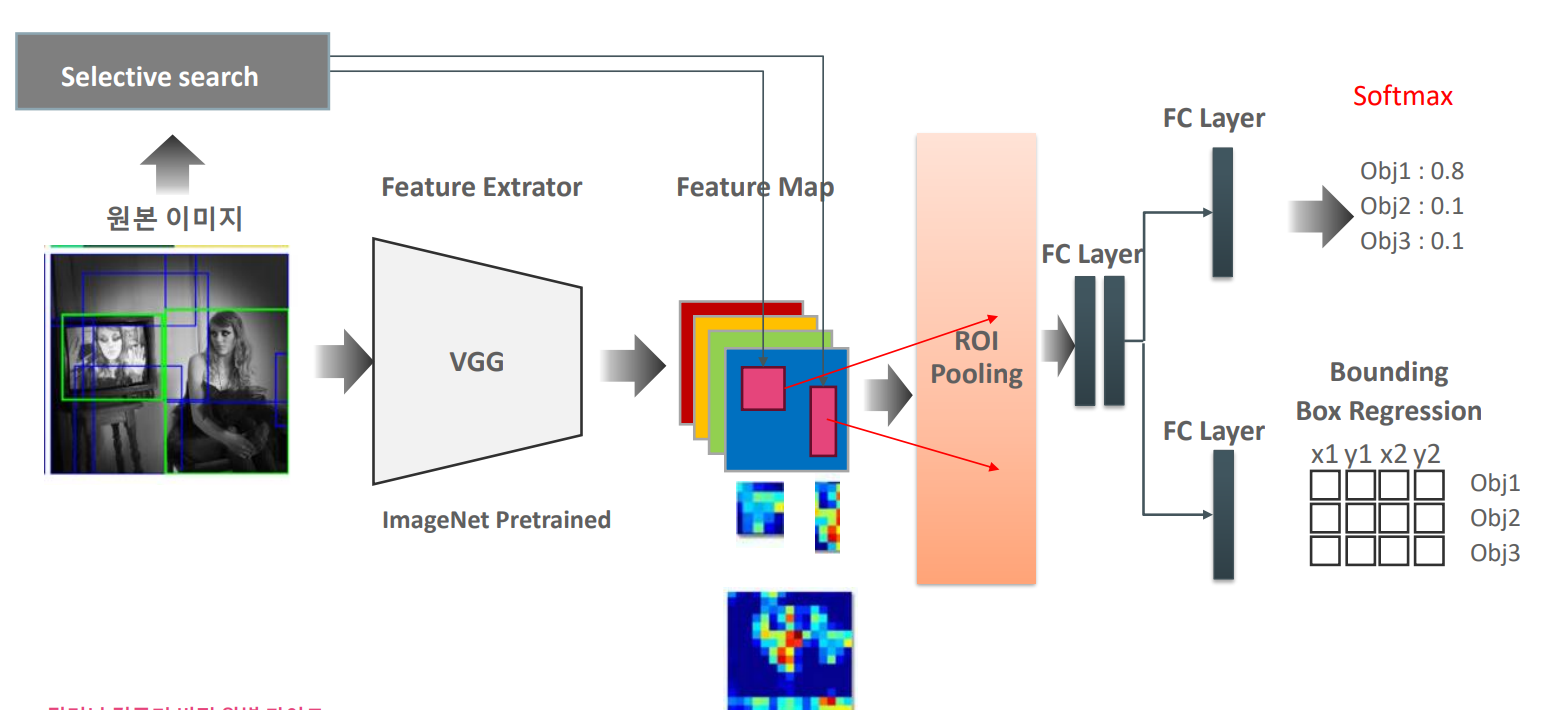
원본 이미지를 feature map을 만듭니다. > 원본 이미지의 SS를 2000개 구하고 SS를 feature map에 맵핑합니다. > 이것을 roi pooling을 해서 7 x 7 입력 크기를 맞추고 FC에 넣습니다. > 2000, 7, 7이 만들어지고 원본 이미지가 4개라면 4, 2000, 7, 7개가 생깁니다. 그리고 feature map의 depth가 256라면 pooling도 256으로 되어서 (4, 2000, 7, 7, 256)이 됩니다. (이게 입력값 하나하나 들이니깐 파라미터 개수가 이거 다 곱한 개수가 나올 것입니다.) > 이 상태에서 FC를 하고 softmax를 하고 bbox reg를 합니다.
- multi task loss

이제 cls와 reg를 함께 반영해서 loss를 만들 수 있습니다. 이 말은 역전파를 전체적으로 다 할 수 있다는 말이 됩니다. reg loss는 smooth l1 loss를 썼다는데 L1loss가 오차의 절대값을 손실로 하는 것인데 smooth는 x가 ti - vi인 오차로 오차가 1보다 작을 때는 L2처럼 ^2을하고 클 때는 절대값으로 합니다. 1보다 작을 때는 급격하게 오류를 줄여주는 모습을 보입니다.
'[AI] > [네이버 BoostCamp | 학습기록]' 카테고리의 다른 글
| CV PART.OpenCV로 객체탐지 구현하기 (0) | 2023.03.30 |
|---|---|
| CV PART.Faster RCNN (0) | 2023.03.28 |
| CV PART.데이터셋 구성, opencv (0) | 2023.03.18 |
| CV PART.객체탐지 개요 (0) | 2023.03.16 |
| [22.09.26] GAN PART.CGAN, CycleGAN (0) | 2022.12.27 |



