
개발자로 후회없는 삶 살기
CV PART.OpenCV로 객체탐지 구현하기 본문
서론
※ 이 포스트는 다음 강의의 학습이 목표임을 밝힙니다.
https://www.youtube.com/playlist?list=PLpkj8RKr48wZAx6jXEcpOQca5A1yCoNJr
[개정판] 딥러닝 컴퓨터 비전 완벽 가이드
www.youtube.com
본론
아직 객체탐지 설명을 상세하지 않았습니다. 근데 미리 구현해보는게 쉽게 이해할 수 있어서 해보자 OpenCV의 DDN 모듈로 객체탐지를 구현해보겠습니다.
- 개요
1. 기존 프레임워크와의 연동

타 프레임워크의 모델을 readNetFromTensorflow('가중치 모델 파일', '환경 파일') 이렇게 쉽게 할 수 있습니다.
2. OpenCV에서 사용 가능한 Tensorflow 모델이 있다.

정확성 위주, 성능 위주의 모델이 있습니다.
- 수행 절차
1. 가중치와 환경 설정 파일 로드

read로 모델을 로드합니다.
2. 입력 이미지 전처리


blob으로 이미지 전처리를 하고 cvNet.setInput으로 네트워크에 입력함 blob은 이미지 스케일링, BGR RGB 변경 등 이미지 처리를 제공합니다.
3. inference
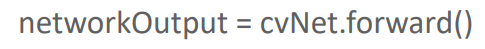
cvNet.forward()를 하면 모델 결과가 출력됩니다. 감지된 정보가 반환됩니다.
- 실습 1
1. 이미지 다운로드

비틀즈 이미지를 탐지해보겠습니다.
2. 가중치와 환결 설정 파일 로드

tf 모델은 1.x를 가장 많이 지원합니다. 가중치 파일을 다운로드하고 환경 파일을 다운받아서
> 우리가 할 건 faster rcnn resnet 50입니다. config 파일을 보고 이것을 OpenCV가 해석을 해서 OpenCV 모델로 받아들이는 것입니다.
cv_net = cv2.dnn.readNetFromTensorflow('./pretrained/faster_rcnn_resnet50_coco_2018_01_28/frozen_inference_graph.pb',
'./pretrained/config_graph.pbtxt')> 모델을 read로 읽는데 pbtxt를 보고 읽는 것이고 반환은 객체 탐지 모델이 됩니다.
3. coco 데이터셋의 클래스 id 별 클래스 명 지정

coco는 80개의 클래스인데 id는 91까지 있습니다. 중간에 없는 11개의 클래스가 있어서 그렇습니다.
# OpenCV Tensorflow Faster-RCNN용
labels_to_names_0 = {0:'person',1:'bicycle',2:'car',3:'motorcycle',4:'airplane',5:'bus',6:'train',7:'truck',8:'boat',9:'traffic light',
10:'fire hydrant',11:'street sign',12:'stop sign',13:'parking meter',14:'bench',15:'bird',16:'cat',17:'dog',18:'horse',19:'sheep',
20:'cow',21:'elephant',22:'bear',23:'zebra',24:'giraffe',25:'hat',26:'backpack',27:'umbrella',28:'shoe',29:'eye glasses',
30:'handbag',31:'tie',32:'suitcase',33:'frisbee',34:'skis',35:'snowboard',36:'sports ball',37:'kite',38:'baseball bat',39:'baseball glove',
40:'skateboard',41:'surfboard',42:'tennis racket',43:'bottle',44:'plate',45:'wine glass',46:'cup',47:'fork',48:'knife',49:'spoon',
50:'bowl',51:'banana',52:'apple',53:'sandwich',54:'orange',55:'broccoli',56:'carrot',57:'hot dog',58:'pizza',59:'donut',
60:'cake',61:'chair',62:'couch',63:'potted plant',64:'bed',65:'mirror',66:'dining table',67:'window',68:'desk',69:'toilet',
70:'door',71:'tv',72:'laptop',73:'mouse',74:'remote',75:'keyboard',76:'cell phone',77:'microwave',78:'oven',79:'toaster',
80:'sink',81:'refrigerator',82:'blender',83:'book',84:'clock',85:'vase',86:'scissors',87:'teddy bear',88:'hair drier',89:'toothbrush',
90:'hair brush'}
Opencv 구현을 할 때 Tensorflwo Faster RCNN은 0 ~ 90까지 클래스를 써야하는 유의점이 있습니다. 우리는 Labesl_to_names_0을 쓸 것입니다.
- inference 코드 구현

실행을 보면 Faster RCNN이라서 속도는 느립니다. 특히 영상처리에 적합하지는 않습니다. 근데 결과를 돌려보면 차와 사람을 잘 찾았습니다. 정확성이 높습니다.
-> 코드 분석
1. 이미지 전처리 및 모델에 이미지 입력
cv_net.setInput(cv2.dnn.blobFromImage(img, swapRB=True, crop=False))blob으로 전처리하고 setInput으로 입력합니다.
2. inference
forward로 inference를 하고 결과를 cvout으로 출력합니다.
# Object Detection 수행하여 결과를 cvOut으로 반환
cv_out = cv_net.forward()
# 결과
(1, 1, 100, 7)
# 객체 탐지 하나 결과
[0.00000000e+00, 0.00000000e+00, 9.99780715e-01,
2.80248195e-01, 4.11070466e-01, 4.66062039e-01,
8.59829783e-01]cvout을 보면 (1, 1, 100, 7)이고 100은 탐지한 객체의 개수입니다. 이걸 나중에 if score가 0.5보다 큰 것들로 filter 할 것입니다.
> 7은 100개의 객체 탐지 결과마다 7개의 값이 의미가 있습니다. 첫번째는 다 0으로 의미가 없습니다. 두번째는 클래스 id입니다. 세번째는 클래스 confidence입니다. 뒤에 4개가 좌표입니다.
# bounding box의 테두리와 caption 글자색 지정
green_color=(0, 255, 0)
red_color=(0, 0, 255)
# detected 된 object들을 iteration 하면서 정보 추출
for detection in cv_out[0,0,:,:]:
score = float(detection[2]) # 세번째 자신감
class_id = int(detection[1]) # 두번째 클래스
# detected된 object들의 score가 0.5 이상만 추출
if score > 0.5:
# detected된 object들은 scale된 기준으로 예측되었으므로 다시 원본 이미지 비율로 계산
left = detection[3] * cols # 네, 다섯, 여섯, 일곱 번째 좌표
top = detection[4] * rows
right = detection[5] * cols
bottom = detection[6] * rows
# labels_to_names_seq 딕셔너리로 class_id값을 클래스명으로 변경.
caption = "{}: {:.4f}".format(labels_to_names_0[class_id], score)
print(caption)
#cv2.rectangle()은 인자로 들어온 draw_img에 사각형을 그림. 위치 인자는 반드시 정수형.
cv2.rectangle(draw_img, (int(left), int(top)), (int(right), int(bottom)), color=green_color, thickness=2)
cv2.putText(draw_img, caption, (int(left), int(top - 5)), cv2.FONT_HERSHEY_SIMPLEX, 0.4, red_color, 1)
img_rgb = cv2.cvtColor(draw_img, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(12, 12))
plt.imshow(img_rgb)클래스 id가 0으로 99퍼 확신하는 것입니다. 근데 4개의 좌표가 0 ~ 1로 스케일링이 되어있습니다. 이것을 다시 좌표값으로 바꾸려면 원본 이미지의 w, h를 곱해줘야합니다.
- 비디오 inference
1. 비디오 캡쳐
video_input_path = '/content/data/Jonh_Wick_small.mp4'
cap = cv2.VideoCapture(video_input_path)
frame_cnt = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
print('총 Frame 갯수:', frame_cnt)프레임을 다 뽑습니다.
2. 비디오 라이터
video_input_path = '/content/data/Jonh_Wick_small.mp4'
video_output_path = './data/John_Wick_small_cv01.mp4'
cap = cv2.VideoCapture(video_input_path)
codec = cv2.VideoWriter_fourcc(*'XVID')
vid_size = (round(cap.get(cv2.CAP_PROP_FRAME_WIDTH)),round(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)))
vid_fps = cap.get(cv2.CAP_PROP_FPS )
vid_writer = cv2.VideoWriter(video_output_path, codec, vid_fps, vid_size)
frame_cnt = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
print('총 Frame 갯수:', frame_cnt)객체 탐지 후 그려서 출력할 준비를 합니다.
3. inference
def do_detected_video(cv_net, input_path, output_path, score_threshold, is_print):
cap = cv2.VideoCapture(input_path)
codec = cv2.VideoWriter_fourcc(*'XVID')
vid_size = (round(cap.get(cv2.CAP_PROP_FRAME_WIDTH)),round(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)))
vid_fps = cap.get(cv2.CAP_PROP_FPS)
vid_writer = cv2.VideoWriter(output_path, codec, vid_fps, vid_size)
frame_cnt = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
print('총 Frame 갯수:', frame_cnt)
green_color=(0, 255, 0)
red_color=(0, 0, 255)
while True:
hasFrame, img_frame = cap.read()
if not hasFrame:
print('더 이상 처리할 frame이 없습니다.')
break
img_frame = get_detected_img(cv_net, img_frame, score_threshold=score_threshold, use_copied_array=False, is_print=is_print)
vid_writer.write(img_frame)
# end of while loop
vid_writer.release()
cap.release()위에서 이미지 처리한 코드를 쓰고 그냥 vid_writer.write해주면 됩니다.
- 모던 객체탐지 모델 구조

굳이 모던이라고 붙였는데 백분 > 넥 > 헤드라는 주요 구성 요소가 확립이 된게 3년밖에 안됐습니다.
1. 백본
feature map 만듭니다.
2. 넥

FPN 때문에 나왔다. feature pyramid로 피쳐맵이 원본 이미지 대비 점점 사이즈가 줄어드는데 두께는 계속 두꺼워집니다. 위로 올라갈 수록 좀더 추상화된 map이 생기게 됩니다. 밑에 층에 map에서 상세한 정보(원본이미지 일수록 상세하고 끝으로 갈수록 추상적)를 가지고 있습니다.
> Neck이 생기면서 마지막 추상화된 map이 아니라 중간 중간 다양한 map에서 정보를 뽑아내서 객체 탐지를 하기 위한 정보를 정화를 시켜줍니다.
> 원래는 마지막 map만 활용하였었는데 그러지 말고 중간 중간 map도 활용을 해보자는 것으로 왜 그러냐면 원본 이미지에 있는 작은 객체를 탐지해야하는데 마지막에서는 잘 안되니 다양한 feature map에서 뽑아서 해보자는 것입니다.
3. 헤드
cls, reg를 합니다.
-> 정리
결국 FPN의 목표는 작은 개체를 잘 감지하기 위해 만들어진 것으로 다양한 Map을 활용하자는 것입니다. 바텀업이 백본이고 top다운이 넥이 하는 방식입니다. 마지막 map 포함에서 각 map의 정보를 neck에 전달을 해줍니다.
예를 들어서 2를 전달하고 전달 받은 것을 2배를(업 샘플링) 해서 4로 만들고 이전 4와 합치고 그런 식으로 맵핑을 하면서 작업을 합니다. 상위의 정보를 2배해서 받아들이고 하위 feature map을 전달받아서 더합니다.
- faster rcnn에 FPN 활용

RPN을 FPN으로 합니다. 최종 feature map이 있습니다.여기가 백본이고

오른쪽이 RPN 넥입니다.

각 계층에 RPN을 하여 cls와 bbox reg를 하고 전체 RoI 풀링을 하여 최종 cls와 reg를 합니다.
'[AI] > [네이버 BoostCamp | 학습기록]' 카테고리의 다른 글
| CV PART.Faster RCNN (0) | 2023.03.28 |
|---|---|
| CV PART.RCNN의 발전 (0) | 2023.03.18 |
| CV PART.데이터셋 구성, opencv (0) | 2023.03.18 |
| CV PART.객체탐지 개요 (0) | 2023.03.16 |
| [22.09.26] GAN PART.CGAN, CycleGAN (0) | 2022.12.27 |



