
개발자로 후회없는 삶 살기
CV PART.객체탐지 개요 본문
서론
※ 이 포스트는 다음 강의의 학습이 목표임을 밝힙니다.
https://www.youtube.com/playlist?list=PLpkj8RKr48wZAx6jXEcpOQca5A1yCoNJr
[개정판] 딥러닝 컴퓨터 비전 완벽 가이드
www.youtube.com
본론
- Localization, Detection, Segmentation

1. Localization : 단 하나의 object 위치를 bbox로 지정하여 찾음
2. Detection : 여러개의 Obejct들에 대한 위치를 bbox로 찾음
3. Segmentation : Detection 보다 더 발전된 형태로 Pixel 레벨 Detection 수행
> 이들과 분류의 차이는 위치를 아냐 아니냐입니다. 로칼, 객체 탐지 둘 다 bbox regression과 classification 두 개의 문제가 합쳐져있습니다. 근데 객체 탐지는 여러개이고 로칼은 하나입니다.
- 객체탐지의 주요 구성 요소
1. 영역 추정
bbox를 예측하고 그 안에 객체가 뭔지 분류도 해야하는데 어떤 영역에 있을 것 같다고 말을 해줘야 bbox를 잘 예측합니다. 객체가 있을 것 같은 곳을 힌트를 줘야합니다.
2. 객체탐지 모델

1) 백본 : 특징 추출,
2) 넥,
3) 헤드 : 분류 회귀
FPN이 나오면서 넥 개념이 생겼습니다. 객체탐지의 문제가 작은 객체를 잘 못 찾는 것인데 작은 객체의 정보에 대해 분류를 체계화 한 것입니다. 헤드에서 분류와 회귀를 합니다.
- 어려운 이유

1. 분류와 회귀를 동시에 해야합니다. 두 개의 loss가 있는데 이 설정이 만만치 않습니다. 이 두개가 다 좋은 성능을 보여야 하기에 식이 복잡해집니다.
2. 다양한 크기와 유형의 객체가 섞여있고 이들을 탐지해야합니다.
3. 실시간 객체 탐지가 요구되고 있습니다.
4. 객체 이미지가 명확하지 않은 경우가 많고 배경이 대부분을 차지합니다.
5. 데이터 세트의 부족합니다. 에너테이션을 만들어야하므로 훈련 데이터 셋을 생성하기가 상대적으로 어렵습니다.
- Localization 개요
이것은 이미지에 무조건 객체가 하나만 있다는 전제하에 하는 것으로 객체 탐지보다 훨씬 쉽습니다.

어노테이션이 있고 bbox의 좌표 값을 가지고 있습니다. feature map까지는 똑같은데 regression layer가 따로 있습니다. 근데 살짝 다른게 이 feature가 있으면 요 bbox라고 예측을 하는 것입니다. "그냥 car면 car이다" 느낌입니다.

사진을 보면 처음 예측한 bbox에서 학습을 해나가면서 점점 탐지를 잘 해나갑니다. 빨간색 feature가 있으면 저 bbox라고 예측을 하는 것입니다.

+평가 점수 분류 confidence score : 일반적인 confidence score는 분류 점수입니다. 뜻은 "이 bbox를 친 객체가 차일 확률이 0.9이다"는 뜻입니다. 근데 Localization은 일반적인 분류 모델에 bbox하나만 붙이면 되는데 이런 로직은 객체 탐지에 바로 쓸 수 없습니다.

안되는 이유 : 사람도 bbox가 있고 car에도 있을텐데 여러개의 객체가 있으니 feature map에 객체가 여러개 있습니다. 근데 local로 하면 bbox 예측을 이상하게 하더라 즉, bbox만 모델에 넣으면 추론 자체가 어렵습니다. 이 이미지만 봐도 객체가 하나만 있는게 아니고 여러 개이니 차 feature가 있고 저 차 feature가 있지만!!("이런 feature 일 땐 bbox가 여기일 거다!"가 local의 원리이므로) 여러개이니 두 차의 가운데를 찍게 됩니다.
> 그래서 학습을 시킨 이후에도 어디에 있을 거라는 것을 알려주고 탐지를 하는 것이 필요합니다. Resion Proposal을 하는 것이 추론에도 일어납니다. 그렇게 하지 않으면 예측을 난사합니다.
- Object Detection

그니깐 이전에는 차로 학습을 시키면 차의 feature map 결과로 학습을 시키니 다른 이미지로 추론을 할 때 차가 하나밖에 없었으니 feature map을 구했는데 "이 feature는 학습시킨 차의 feature와 같으니 지금 추론하는 객체는 차겠고 bbox는 여기겠구나!"가 됐었습니다.
> 근데 이제는 여러개가 있으니 각각의 비슷한 객체에 대해서 bbox reg을 학습을 시켜놨더니 추론할 이미지를 넣으면 비슷한 객체지만 다른 곳에 있을 것이라서 엉뚱한 곳을 추론합니다. 따라서 그림에서 탐지하려는 객체가 어디에 있는지를 찾는게 객체탐지에서 첫번째 넘어야할 알고리즘입니다.(지금 여러개의 객체를 Localization으로 탐지를 하려고 하니 난사를 하는 것이다. 그러니 위치를 알려주고 Localizaion을 하자!
윈도우를 이동시키며 객체를 탐지하는 것입니다. 윈도우 하나만 있고 현재 윈도우 위치에서만 객체가 있는지 찾습니다. 그러다가 학습한 햇번과 비슷한 feature가 새로운 이미지의 현재 윈도우의 feature에서 느껴지면 현재 이 윈도우의 위치에 bbox를 치고 햇번이라고 분류를 합니다.
근데 이런 방법은 슬라이딩 윈도우 크기, 시작 위치 등에 따라 추론 결과가 달라지는 case by case입니다. 따라서 다양한 형태의 윈도우를 돌려야합니다. 너무 오래 걸리고 검출 성능이 낮습니다.(이게 나중에 앵커 박스에 녹아 들어갑니다.)
2. Selective Search 방식

윈도우 방식은 추정이라고 보기는 좀 그렇습니다. 모든 곳을 다 보는 완전 탐색이라 추정은 아닙니다. 그래서 나온게 SS입니다. 픽셀의 색깔과 edge를 봐서 유사한 영역을 Segmentation을 하여 객체가 있을 것 같은 곳을 찾아내는 방식입니다. 세그멘테이션이 픽셀 영역이라서 픽셀을 봐서 영역을 나눕니다. 그렇게 점점 유사도가 비슷한 세그멘트들을 모아서 bbox를 만들고 그것을 region proposal을 하는 방식입니다.


SS 라이브러리를 사용하면 region bbox를 구할 수 있고 openCV rectangle 라이브러리로 원본 이미지에 사각형을 그릴 수 있습니다.
=> IoU

합집합 분에 교집합으로 모델이 예측한 결과와 실제 GT의 bbox가 겹친 부분이 얼마나 정확하게 겹치는가 를 나타내는 지표입니다.
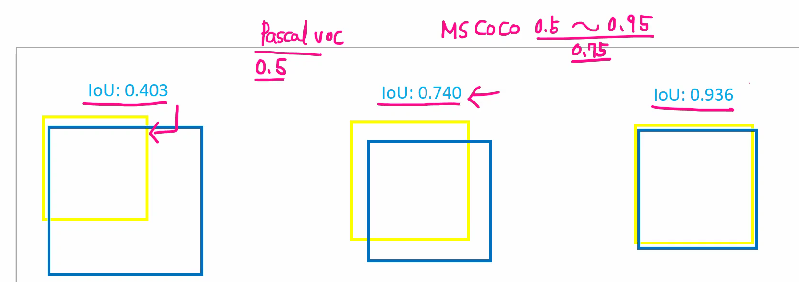
-> IoU에 따른 객체 탐지 성능 :
1) 0.403이면 잘 못했다. 0.4정도 겹쳤다는 뜻입니다. MS COCO에서 0.5보다 낮다고 하면 제대로 못했다고 평가를 한다고 합니다.
2) 0.740이면 잘 했다. 0.7 정도 겹쳤다.는 뜻입니다.
IoU의 잘했다의 기준을 0.5 ~ 0.95로 바꿔가면서 평가를 하는데 IoU가 0.74인데 기준이 0.5면 잘한 거고 0.95가 기준이면 못한겁니다.
def IoU(box1, box2):
# box = (x1, y1, x2, y2)
box1_area = (box1[2] - box1[0] + 1) * (box1[3] - box1[1] + 1)
box2_area = (box2[2] - box2[0] + 1) * (box2[3] - box2[1] + 1)
# obtain x1, y1, x2, y2 of the intersection
x1 = max(box1[0], box2[0])
y1 = max(box1[1], box2[1])
x2 = min(box1[2], box2[2])
y2 = min(box1[3], box2[3])
# compute the width and height of the intersection
w = max(0, x2 - x1 + 1)
h = max(0, y2 - y1 + 1)
inter = w * h
iou = inter / (box1_area + box2_area - inter)
return iou교집합(inter)과 합집합(둘의 합 - 교집합)으로 iou를 구합니다.


각 RP마다 iou를 구해서 print 합니다. IoU가 0.5 이상인 bbox만 시각화합니다.
=> NMS

객체 탐지의 경우 SS를 하면 정확하게 그 객체를 찾아서 반환하는게 아니고 객체가 있을 만한 곳을 여러개를 반환을 합니다. Max가 아닌 bbox는 제거하는 것입니다.
-> 구하는 방법
1. bbox별로 confidence score를 봄
2. iou를 봄
confidence score 0.5이하인 RP는 제거하고 높은 점수 순으로 내림차순 정렬을 하고(0.9 0.8 0.7 ,,,,, ) 가장 높은 iOu를 가지는 RP와 다른 RP와의 겹치는 정도를 봐서 특정 threshold 이상인 bbox를 모두 제거합니다. GT와 겹치는게 아니라 가장 높은 iou와 얼마나 겹치나를 보는 것입니다. 그래야 같은 객체를 보는 다른 Max가 아닌 bbox를 제거 할 수 있습니다. 그래서 GT와의 iOu가 작은데 살아 남은게 있을 수 있습니다. Max만 남기는게 아닙니다.
=> mAP
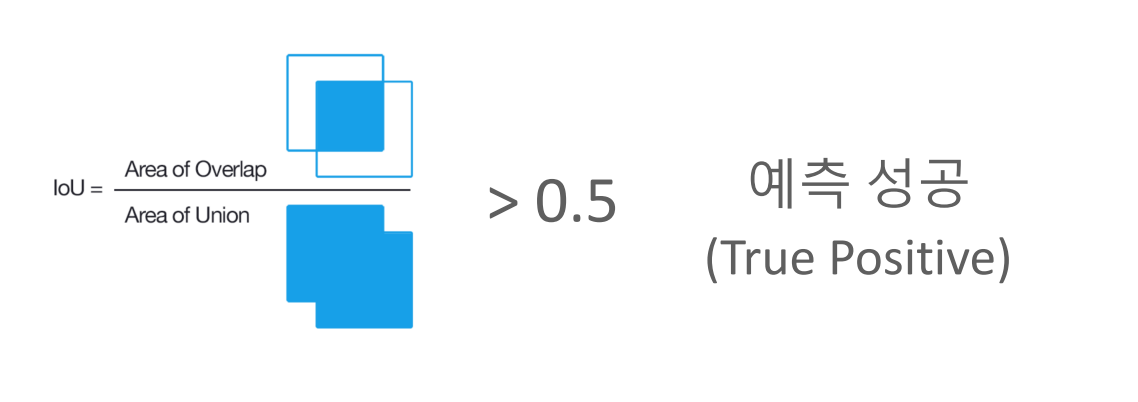

정밀도와 재현률은 이진 분류의 평가 척도로 예측을 성공했나를 알아야 합니다. 객체탐지에서 어떤 것을 예측 성공으로 볼 것이냐면 IoU로 합니다. ( ex) IoU가 0.5보다 높으면 예측 성공이라고 인정합니다. ) 이것으로 성공, 실패를 정의해서 precision recall을 구합니다.
> recall을 x축으로 두고 precision을 y축으로 둬서 recall 값의 변화에 따른 precision의 변화를 AP라고 하고 PR curve로 곡선으로 나타냅니다.


recall이 0.2부터 시작해서 1.0으로 증가하면서 precision의 변화를 보여주고 PR 곡선은 지그재그 형태로 만들어집니다. 이것을 오른쪽 최대값을 연결을 하기로 약속했고 결론적으로 밑에 넓이가 AP입니다. AP는 한 개의 객체에 대한 성능 수치이고 여러개의 객체의 AP의 평균이 mAP입니다.
> 하나의 사진에 원숭이 고양이 토끼가 있을 때 각각의 AP를 구하고 그 평균이 mAP이며 어떤 객체는 AP가 크고 어떤 객체는 작다면 mAP가 중화됩니다.
-> COCO에서 mAP


AP@[.50:.05:.95]라고 하면 IoU 기준을 0.5에서 시작하여 0.05씩 증가를 시켜서 0.95까지 기준을 잡겠다는 뜻입니다. IoU를 0.5인 최하로 하면 기준이 낮아지니 mAP가 커지고 0.95로 높이면 기준이 높아져 mAP가 작아집니다. > 논문으로 보면 AP50은 IoU가 0.5일때 라는 얘기이고 밑에 숫자 55.7은 그때의 mAP입니다. 75에서 굉장히 많이 떨어집니다.
'[AI] > [네이버 BoostCamp | 학습기록]' 카테고리의 다른 글
| CV PART.RCNN의 발전 (0) | 2023.03.18 |
|---|---|
| CV PART.데이터셋 구성, opencv (0) | 2023.03.18 |
| [22.09.26] GAN PART.CGAN, CycleGAN (0) | 2022.12.27 |
| [22.09.23] GAN PART.최신 GAN 기술 (0) | 2022.12.27 |
| [22.09.15] GAN PART.훈련과정 (0) | 2022.12.27 |



