
개발자로 후회없는 삶 살기
CV PART.데이터셋 구성, opencv 본문
서론
※ 이 포스트는 다음 강의의 학습이 목표임을 밝힙니다.
https://www.youtube.com/playlist?list=PLpkj8RKr48wZAx6jXEcpOQca5A1yCoNJr
[개정판] 딥러닝 컴퓨터 비전 완벽 가이드
www.youtube.com
본론
- 주요 데이터 셋

1. 파스칼
20개의 카테고리에 대해 객체 탐지하는 대회에서 사용된 데이터 셋입니다. 어노테이션이 XML로 되어있습니다.
2. 코코
80개의 카테고리입니다. json format을 가집니다.
3. 구글 오픈 이미지s
600개의 카테고리이고 csv format을 가집니다.
- 파스칼 데이터 세트 탐색
구조를 보면 어노테이션과 jpeg가 1 대 1로 맵핑됩니다. a.jpeg 이미지면 a.xml로 1대 1 맵핑입니다.
파스칼 데이터셋을 다운 받고 탐색해보겠습니다. Annotaions와 JPEGImages dir안에 xml와 jpg이 1대 1로 맵핑됩니다. Imagesets의 train.txt를 보면 이런 데이터를 train으로 쓰겠다는 의미입니다.
이미지와 xml이 맵핑이 되고


elementTree 라이브러리를 사용하여 파싱합니다. xml은 tree 구조라서 tree를 잡고 root 노드를 잡습니다.(xml은 각 태그를 노드라고 표현하고 태그 안에 내용물을 text라고 함) 여기서는 annotation이 루트입니다.
# !pip install lxml
import os
import xml.etree.ElementTree as ET
xml_file = os.path.join(ANNO_DIR, '2007_000032.xml')
# XML 파일을 Parsing 하여 Element 생성
tree = ET.parse(xml_file)
root = tree.getroot()
# image 관련 정보는 root의 자식으로 존재
image_name = root.find('filename').text # root인 annotation 밑에 filename이라는 자식을 찾음
full_image_name = os.path.join(IMAGE_DIR, image_name)
image_size = root.find('size') # root인 annotation 밑에 size를 찾음
image_width = int(image_size.find('width').text) # size 태그의 width를 찾음
image_height = int(image_size.find('height').text)annotation 루트의 밑에 filename 자식과 size 자식을 찾고 size의 자식 중 width를 찾습니다.
# 파일내에 있는 모든 object Element를 찾음.
objects_list = []
for obj in root.findall('object'):
# object element의 자식 element에서 bndbox를 찾음.
xmlbox = obj.find('bndbox')
# bndbox element의 자식 element에서 xmin,ymin,xmax,ymax를 찾고 이의 값(text)를 추출
x1 = int(xmlbox.find('xmin').text)
y1 = int(xmlbox.find('ymin').text)
x2 = int(xmlbox.find('xmax').text)
y2 = int(xmlbox.find('ymax').text)
bndbox_pos = (x1, y1, x2, y2)
class_name=obj.find('name').text
object_dict={'class_name': class_name, 'bndbox_pos':bndbox_pos}
objects_list.append(object_dict)
print('full_image_name:', full_image_name,'\n', 'image_size:', (image_width, image_height))
for object in objects_list:
print(object)> 이번엔 object 자식을 모두 찾고 loop를 돕니다. 하나의 이미지에 비행기 객체가 여러개 있고 xml에도 여러개의 object가 담겨있는데 그걸 다 찾아서 개별 object마다 find해서 x, y 최대 최소 노드를 찾습니다. 찾은 것을 dic으로 만들고 object_list에 append합니다.
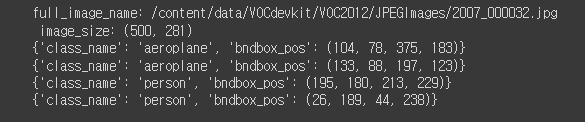
결과적으로 xml에서 데이터를 노드에 맞는 텍스트를 파싱했습니다.
- ms coco 데이터 셋
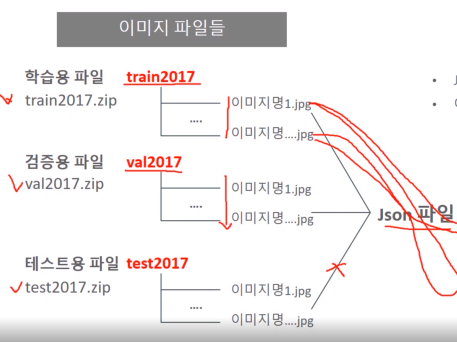

학습용 파일 train2017.zip에 이미지들이 다 들어가있고 검증용, 테스트용이 다 들어가 있습니다. 그런데 annotation 파일은 딱 하나입니다. json 포맷은 한 개의 파일로 한 라인으로 구성됩니다.

json을 까보면 5개의 대분류로 구성이 되고 info, license는 헤더 정보라 중요하지 않고 images에 모든 이미지의 id, 파일명, 이미지 너비 높이 정보가 들어있습니다. annotations에는 zip 파일에 들어있는 대상 image 및 object의 id, segm, bbox, 픽셀 영역을 가지고 있고 이걸 한개의 파일에 가지고 있습니다.
- openCV
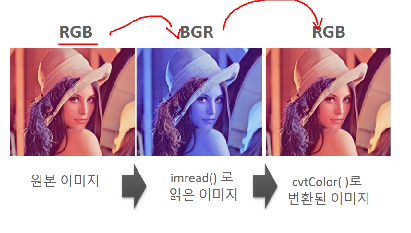
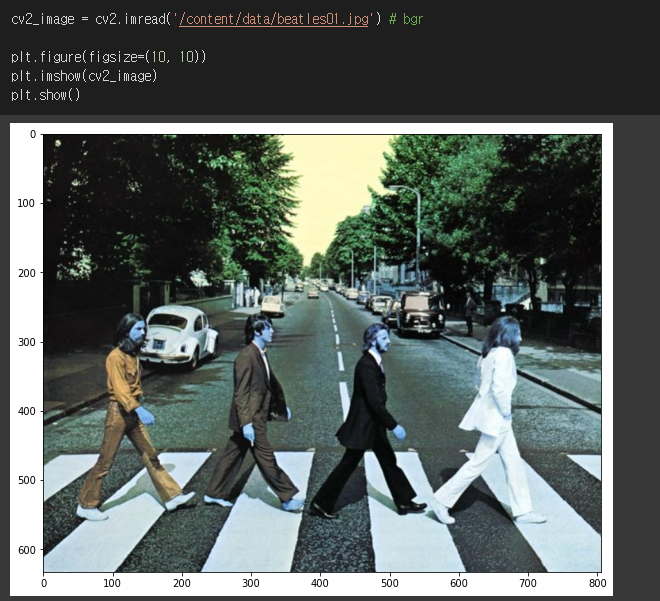
주의할 게 있는 rgb, bgr 변환하는데 문제가 있습니다. imread로 이미지를 읽어 오면 이미지 파일을 넘파이로 읽고 오는데 rgb형태가 아닌 bgr 형태로 로딩하기 때문에 색감이 원본이미지와 다르게 나타납니다. 따라서 R 계열이 높은 이미지에서 B 계열이 높은 이미지로 변환이 됩니다. 이거를 다시 rgb로 바꾸려면 cvtColor(convert color)를 써야합니다.
> imwrite도 인자로 bgr형태의 이미지 배열을 받야하고 결과는 rgb로 바꿔줍니다.
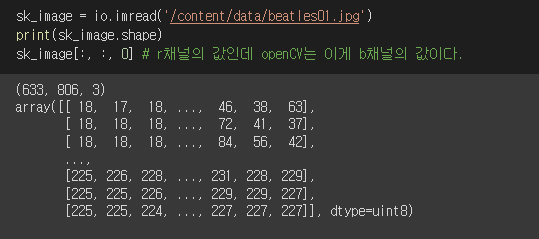
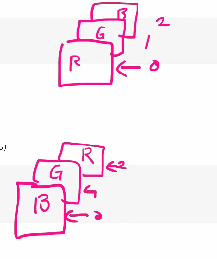
이것을 보면 이미지의 np 형식을 제대로 알 수 있습니다. 1개의 이미지의 경우 값이 3개라 3차원이다. 나는 처음에 0을 보고 여러개의 이미지 중에서 첫번째 이미지의 값인 줄 알았는데 한개의 이미지였고 한개의 이미지의 bgr 중에서 첫번째인 b를 나타내는 것입니다.
=> 영상처리
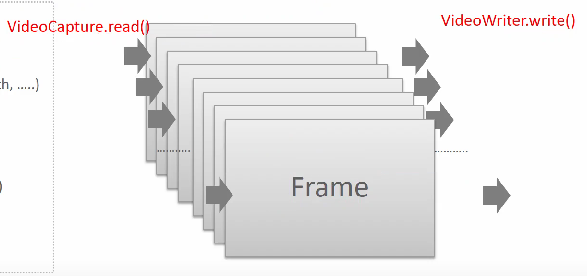
cv의 영상처리 라이브러리로 VideoCapture가 있습니다. 인자로 비디오 경로 mp4를 넣어주면 영상의 프레임을 하나씩 읽습니다. VideoCapture.read로 읽어서 프레임을 반환합니다. 두개가 반환되는데 하나는 개별 이미지(img_frame)이고 다른 하나는 hasFrame으로 프레임이 있냐 없냐입니다. 마지막 프레임까지 읽으면 다음 프레임이 없어서 hasFrame이 0이 됩니다.

VideoCapture.get으로 VideoCapture로 가져온 프레임의 속성을 알 수 있습니다. 원본 프레임의 너비, 높이, fps 속성을 알 수 있다. FPS가 높으면 성능은 좋지만 컴퓨팅 파워를 많이 먹습니다.
> VideoWriter는 읽은 프레임을 다시 비디오로 만들어주는 것인데 VideoWriter_fourcc(*'MP4')를 인자로 주면이 포멧으로 write한다는 것입니다. 따라서 VideoWriter의 인자는 VideoCapture로 읽은 경로, VideoWriter_fourcc, 속성을 줄 수 있습니다. get으로 가져온 원본 프레임의 fps, 너비, 높이 그대로 write한다는 의미입니다.
원본 영상을 불러 준비합니다.
import cv2
video_input_path = '/content/data/Night_Day_Chase.mp4'
# linux에서 video output의 확장자는 반드시 avi 로 설정 필요.
video_output_path = '/content/data/Night_Day_Chase_out.mp4'
cap = cv2.VideoCapture(video_input_path)
# Codec은 *'XVID'로 설정.
codec = cv2.VideoWriter_fourcc(*'XVID')
vid_size = (round(cap.get(cv2.CAP_PROP_FRAME_WIDTH)),round(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))) #(200, 400)
vid_fps = cap.get(cv2.CAP_PROP_FPS )
vid_writer = cv2.VideoWriter(video_output_path, codec, vid_fps, vid_size)
frame_cnt = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
print('총 Frame 갯수:', frame_cnt, 'FPS:', round(vid_fps), 'Frame 크기:', vid_size)
# 결과
총 Frame 갯수: 1383 FPS: 28 Frame 크기: (1216, 516)cap을 만들고 원본 이미지의 size와 fps를 구할 수 있습니다.
import time
green_color=(0, 255, 0)
red_color=(0, 0, 255)
start = time.time()
index=0
while True:
hasFrame, img_frame = cap.read()
if not hasFrame:
print('더 이상 처리할 frame이 없습니다.')
break
index += 1
print('frame :', index, '처리 완료')
cv2.rectangle(img_frame, (300, 100, 800, 400), color=green_color, thickness=2)
caption = "frame:{}".format(index)
cv2.putText(img_frame, caption, (300, 95), cv2.FONT_HERSHEY_SIMPLEX, 0.7, red_color, 1)
vid_writer.write(img_frame)
print('write 완료 시간:', round(time.time()-start,4))
vid_writer.release()
cap.release()cap으로 영상을 한 프레임씩 읽어와서 img_frame에 할당하고 프레임 이미지마다 사각형과 text를 넣고 writer로 위해서 생성할 때 넣은 속성값 그대로 영상을 다시 write합니다.


보면 VideoCapture 클래스를 객체로 생성하고 get으로 속성을 뽑고 VideoWriter 클래스를 생성할 때 get으로 뽑은 속성을 인자로 주면 여기까지가 읽기와 쓰기 객체를 생성한 것이고 이제 while을 돌면서 프레임을 read()하고 cv로 프레임에 그림을 그리고 write로 작성하면 while이 끝나고 ouput이 생기는게 아니고 첫 프레임에 작성할 때마다 바로 output.mp4가 생깁니다. 하지만 while이 끝나기 전 mp4는 미완성이라 볼 수 없습니다.
'[AI] > [네이버 BoostCamp | 학습기록]' 카테고리의 다른 글
| CV PART.Faster RCNN (0) | 2023.03.28 |
|---|---|
| CV PART.RCNN의 발전 (0) | 2023.03.18 |
| CV PART.객체탐지 개요 (0) | 2023.03.16 |
| [22.09.26] GAN PART.CGAN, CycleGAN (0) | 2022.12.27 |
| [22.09.23] GAN PART.최신 GAN 기술 (0) | 2022.12.27 |



