
개발자로 후회없는 삶 살기
데이터 청년 캠퍼스 PART. 11, 12일차 신경망 기반 알고리즘 본문
서론
본론
- 인공신경망

데이터의 입력 > 어떠한 출력 -> 과거의 사람들은 이걸 컴터로 구현할수있겠는데?라고 생각했다 그래서 10^11의 뉴런을 연결한 거야(그렇게 치면 진짜 인간은 어떻게 만들어진 걸까?)/
- 용어
머신러닝 : 통계적 가정을 만족하지 않더라도 컴퓨터가 스스로 패턴을 학습하는 방법/
딥러닝 : 인공신경망 알고리즘으로 머신러닝을 하는 것 -> 머신러닝과의 차이점 : 특징추출을 안한다? 기계가 알아서 하도록 한다 ★아까는 전처리 안한다고 했는데 기본적인 건 해줘야한다 이미지의 경우 28*28을 784이런거/
=> 데이콘 1등
앙상블(xgboost), 딥러닝 모델이다/ 데이콘에서 제공하는 데이터가 앙상블에 초점을 맞춰서 그렇대/ -> 프로젝트를 할 때 정확도가 중요한 것 vs 남에게 설명을 하기 위한 것이 있다 기업체와 프젝을 하면 정확도를 중요시하는 요구사항이면 앙상블과 딥러닝 모델을 적용해 보는 생각을 해보고 설명을 요하면 선형회귀 모델로 해보자/
- 퍼셉트론

인공신경망의 시작 : 이런식으로 발전이 되었구나 이해해보자 > 생물학적 신경망을 공학적 구조로 변경 ★1개의 뉴런이 퍼셉트론이야! 활성함수를 계단을 쓴게 퍼셉이 아니고 초기에 그냥 퍼셉트론의 활성화함수를 계단을 쓴 것일 뿐이지 1개의 뉴런이면 다 퍼셉트론이다.
-> 이게 비선형적인 문제를 해결하지 못하니 나온 것이 다층 퍼셉트론!
xor문제를 해결하기 위해 다양한 비선형 알고리즘을 생각하게 되었다 > 그래서 나온 것 : 다층 퍼셉트론
> 단순 선형 이진 분류기!! 이진 분류기이다 -> 결론 : 퍼셉트론은 활성화함수로 계단을 쓴 뉴런(y=wx+b)이다/ > wx+b가 0보다 작으면 0으로 크면 1로 바꿔줌/
-> xor문제를 해결하기 위해 다양한 비선형 알고리즘을 생각하게 되었다 > 그래서 나온
> 다층 퍼셉트론 : 다층은 은닉이 1층이래 > 딥러닝이 은닉이 여러개이다/
- 오차역전파(에폭에서 진행됨)

포워드 : y뽑기
백워드 : 최적화/
질문 : 역전파는 로스를 구하고 그 로스만큼 뉴런을 조정하는거일거아냐 > 김인철교수님 강의 드라를 보고 이걸 맨 앞의 노드라고 생각하면 > 시작은 글로벌이 1로 나중에는 영향역을 알게 될거야 그러면 여기에 포워드에서 구한 로스는 어디에 쓰여서 언제 갱신이 되니??/
-> 답 : 손실함수로 오차 계산, 오차가 나오면 최적화함수로 오차의 변화가 아닌 변화율을 확인, 만약 변화율이 0이라면 최적화됐다고 판단 > 그러면 그대로 오차 역전파 알고리즘을 활용하여 가중치 갱신 > 이게 한 에폭 > 갱신된 가중치에 손실함수써서 오차계산 > 또 최적화함수로 ... 이걸 반복/ ★ 오차는 그냥 보는 거다 오차만큼 변하는 거지 오차가 갱신을 계산하는 식에 들어가는 건 아니다/
- 활성화함수

1) 시그모이드
-> 정의 : 0과 1 사이로 출력하게 만드는 함수
-> 기울기 소실문제 : 백프로파할때 미분값인 기울기가 앞으로 전달이 안된다/
2) 렐루
-> 기울기 소실을 막지만 미분의 원리상 소실이 일어나기 때문에 깊은 층에서는 렐루를 써도 기울기 소실이 일어난다/
3) 소맥
-> 출력층을 여러개로 늘리고 확률처럼 만들어주는 함수/
- 배치사이즈
한번에 계산시킬 데이터 개수 > 하나씩 넣으면 느려서 빠르게 하기 위함이다 > 원래는 학습에 영향을 주지 않는데 너무 크게 하면(전체데이터개수의 절반 이상) 학습에 악영향을 준다/
- 실습
1. 이미지 분류
2. 수치데이터 셋에서 딥러닝 적용
- CNN
컴퓨터 비전 실습을 미치도록 할거다!!/
=> ann과의 차이
처음에 flatten해서 평탄화할거냐 그냥 할거냐/
=> 층
1) conv 층
이미지에서 특징을 추출하는 역할 > 이걸 필터가 한다 > 왼쪽상단에서 우측 하단으로 이동하면서 필터가 특징을 추출한다 > 커널의 크기 : 얼마나 큰 면적에서 데이터를 뽑을 거냐 피쳐가 크면 많은 면적에서 다양한 특징을 압축할 수 있지만 너무 크면 좋지 않고 여느 하퍼처럼 돌리면서 찾아야한다/
-> 이때 줄어드는 걸 좋아하지 않음 : 패딩/ 스트라이드 : 계산량을 줄이기 위해서 키운다! 하지만 일반적으로는 1로 준다 = 특징을 추출하는 면에도 크면 넘어가 버리니깐 좋지 않을거같고, 크기가 크게 줄어드는 것도 싫으니깐/
-> 필터는 여러개로 feature map이 두꺼워지고 여러개의 필터를 넣어서 특징을 다르게 추출하고 압축하는 것이다/
2) 풀링 층
conv에서 특징을 추출했다면 그걸 압축하는 거다 > 그래서 conv때 줄어들지 않게 패딩을 줘야한다/
=> cnn 실습 -> ann으로 한 거랑 정확도 차이 비교
필터개수 늘리고, conv 층 늘리니 정확도 확 뛴다!! -> 확인 완료, 또 역시 2, 3층이 제일 성능이 좋은거 같다 -> 역시 특징을 다양하게 추출하고 깊게 하니 정확도가 높아진다/
12일차
- cifar 10 실습
-> 데이터 설명 : 데이터 모양이 3이 추가됨 > rgb값을 의미하며 4차원으로 구성/
=> cnn 구조
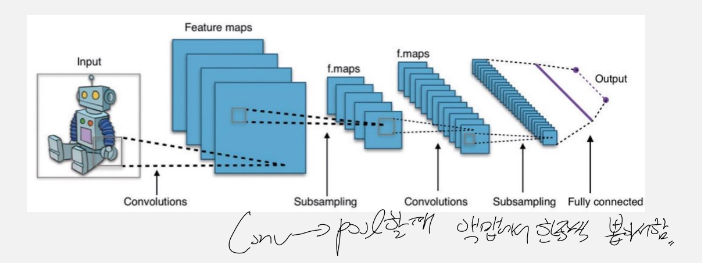
-> ★ 정리 : pooling을 거치면 크기가 작아지니 필터개수는 점점 키워준다/ Dense는 압축을 하는 거니 점점 줄여준다/ 필터개수 늘리고, conv 층 늘리니 정확도 확 뛴다!!/
-> 드랍아웃
모든 층을 연결하는게 아니라 모델이 렌덤으로 학습할 때마다 사진한장 넣을 때마다 랜덤으로 연결을 제거해서 과적합을 방지함 -> 이게 은근 아직도 도움이 된대/
=> 인코딩
레이블 인코딩 = sparse/ 원핫 = 그냥/
- 사전 훈련 모델(=전이학습) -> ㅜㅠㅜㅠ 내가 정말 알고싶었던 것/
학습한 애들을 가져와서 dense층, 분류기쪽만 연결해서 사용가능!/
ex) vgg16
순서 : 사전학습 모델의 끝을 불러와서 내가 원하는 모양과 연결하고 마지막에 모델의 시작을 알려주고 끝을 알려주면 됨/
- 객체 탐지
=> 분류와 탐지의 차이

-> 분류 : 고양이인가 아니면 무언가
-> localization : 고양이인 건 아는 상태에서 단 하나의 객체가 어디에 있나
-> 객체 탐지 : 여러개의 객체를 분류하고 위치를 찾음 -> ★ 고양이를 맞추더라도 바운딩 박스를 제대로 잡아야함/
=> 어려운 이유

1. 분류와 위치를 동시에 찾아야 한다 = 일반적인 분류보다 훨씬 어려움
2. 주로 '실시간' 영상에서 지속적으로 객체를 탐지하는 것을 함(무겁고 복잡한 모델은 실시간이 불가능하여 모바일넷같은 성능은 떨어지지만 실시간성 가능)
3. 사람이 수작업으로 네모박스를 쳐주어 라벨링 작업을 해줘야 됨 등등/
=> 흐름

자동차 사진 수집 > 한장한장에 위치를 다 잡아줌 = 다 바운딩 박스를 만듬(이게 정답임 라벨링으로) annotation 프로그램으로 좌표를 y값으로 잡음(바운딩박스 4개의 숫자 regression) > 학습 -> 분류 + 위치를 찾는 단계로 학습이 된다/
-> 객체를 찾는 법
요즘은 영역 추정(region proposal)을 씀/
-> 평가 방법
1. IOU : intersection over union -> 모델이 예측한 결과와 실측 박스가 얼마나 겹치는가
> 고양이인가 강아지인가는 중요하지 않고 면적만 본다 = 객체를 잘 탐지했나만 보는 거임 + 분류도 잘했나를 봐야하는데 얘는 (면적을 담당함)

-> iou가 0.5보다 크면 제대로 검출했다고 판단/

2. 혼돈행렬 : 분류를 담당함

-> 1. 면적은 완벽한데 고양이라고, 2. 새로 잘했는데 면적이 50퍼 비초과야, 3. 애초에 면적이 안맞아/
=> 객체 탐지의 혼돈행렬 적용

정밀도가 몇이거나 재현율이 몇 이냐에 따라서 탐지 결과가 달라짐 따라서 둘의 중간 단계를 잘 찾아 정해야 원하는 결과를 얻을 수 있을 것이다.
-> 정밀도와 재현율의 변화

신뢰도를 높여서 엄격하게 예측함 = 한개만 예측함 > 예측한 것중 1개가 진짜 새다 > 이걸 신뢰도를 낮춰가며 계속 해나감 > 0.7에서 보면 예측을 3개로 봤는데 새가 아닌게 포함되어서 정밀도가 낮아짐 > 이걸 보면 재현율과 정밀도의 트레이드 오프가 보임/ -> 이런 방식으로 객체 탐지의 성능 평가를 하며 confidence를 사이값으로 잡고 그때의 정밀도와 재현율은 보여야 성능이 좋다라고 생각하겠지/
3. mAP
=> AP(Average Precision)
클래스 하나의 AP를 구함 > 어떤 객체는 정밀도가 높을 수도 있고 어떤 건 낮을 수도 있으니 그거의 평균이 mAP/
- 오토인코더

딥러닝의 비지도 학습으로 압축과 압축을 해제하는 과정으로 이루어진 딥러닝 모델 > 이러한 특징으로 넣었을때 어떤애가 나오는지 -> 부족한 데이터가 있을때 가짜 데이터로 증가시켜야하는 경우 많이 사용 = 이 데이터와 비슷한 데이터를 좀 더 늘리고 싶을 때 사용/
ex) 7을 넣었을 때 다시 7을 반환할 수 있을지를 봄 > 따라서 인풋 노드와 출력 노드의 개수가 같음 -> GAN과 비슷한 결과 아님??/
=> 개념 추가
핵심은 데이터를 압축하고 다시 압축을 푸는 과정을 거치면서 압축을 했던 걸 다시 원래 것으로 돌릴 수 있나를 보는 것 > 따라서 입력, 출력노드보다 은닉층의 개수가 적어야하고 압축을 해야한다 -> dnn, cnn은 은닉층을 점점 은닉 노드 수를 늘림(32, 64, 128) 근데 얘는 줄임 압축/
=> 사용방법
차원축소 : 불필요한 특징을 제거하고 필요있는 특징을 돌려줌 > 결론 : 인코더의 압축된 출력을 분류기에 넣어라 그러면 더 좋은 분류 성능을 기대할 수 있다/
원본 이미지 복원 : 6만개의 mnist > 1의사진 784를 넣어서 784보다 줄이고 다시 784로 늘려 아웃풋을 내서 다시 1의 사진을 냄/
=> 활용
질문 : 오토인코더를 학습함 > 32개의 값을 임의로 1000개 만듬 > 디코더에 넣어서 새로 fake데이터를 만듬/
-> 모델을 3개 만드는 이유 : 오토인코더의 핵심은 재구축된 출력층의 출력이 아니라 은닉층의 출력값이라 봄/
1. 오토인코더 모델을 학습하면 인코더와 디코더도 같이 학습됨 = 별도의 모델이 아님 -> 함수형으로 연결시킨 거임/
2. 인코더에 넣으면 데이터를 압축시켜줌
3. 디코더에 넣으면 새로운 데이터를 만들어줌/
- rnn
=> 실습 -> 뉴스토픽 분류 문제/
=> 전처리
★ 중요한 부분
어떤 기사는 길고 어떤 기사는 짧고 그럼 > 개발자는 모델을 만들 때 항상 입력 구조와 출력 구조를 맞춰야함 = 독립변수의 수를 맞춰줘야한다 = 수치에서 사람 이름만 넣고 누구는 발만 넣고 누구는 발과 얼굴만 넣고 이러면 안되고 다 이름, 발, 얼굴을 넣어야한다/
-> 초과하는 애를 커트에서 뒷부분을 버리고 모자란 애들은 뒤에 0으로 패딩처리해준다/
-> 단어 개수 처리
8000개의 기사 사용한 단어 20000개 > 8000*20000의 메트릭스가 생김 > 코드로 못 돌림 > 따라서 빈도가 낮은 애들은 의미가 없다고 판단되어 빈도순 정렬로 많개는 10000개 적게는 1000개만 씀/
-> 텍스트 데이터에 pad

imdb에도 넣던데 이런게 꼭 들어가야 하나보네??
-> 백터화
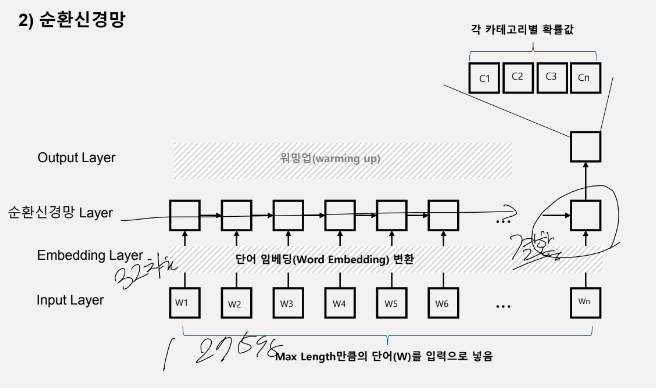
1000개의 단어를 각각 넣기는 무리가 있음 > 예를 들어 임베딩 차원이 2면 1000개의 단어를 2차원 공간에 숫자의 조합으로 뿌림 > 1000개의 단어에서 하나의 단어가 32개의 숫자 조합으로 뿌림(근데 이게 32 차원임) > 이유 : 연산량 감소, 신경망은 크기를 줄어야함 > 마지막에 dense에 넣으면 나이스/
이것만 알면 전분야에 적용가능하니 딥러닝만 알아도 최고다/
'[대외활동] > [데이터 청년 캠퍼스]' 카테고리의 다른 글
| 데이터 청년 캠퍼스 PART.19, 20일차 Clustering (0) | 2022.11.22 |
|---|---|
| 데이터 청년 캠퍼스 PART.18일차 MongoDB (0) | 2022.11.22 |
| 데이터 청년 캠퍼스 PART.9, 13일차 텍스트 분석 (0) | 2022.11.18 |
| 데이터 청년 캠퍼스 PART.8, 17일차 시공간 분석 (0) | 2022.11.18 |
| 데이터 청년 캠퍼스 PART.6, 7일차 머신러닝 기반 분석 실습 (0) | 2022.11.18 |



