
개발자로 후회없는 삶 살기
데이터 청년 캠퍼스 PART.6, 7일차 머신러닝 기반 분석 실습 본문
서론
본론
6일차
실습
※ R이나 파이썬이 좋은 이유 : 웨카나 spss는 정적 라이브러리라서 헤비하다 근데 파이썬, R은 라이브러리를 가져오는 거라서 가볍다 -> 웨카나 spss를 동적으로 라이브러리 쓰는게 r과 파이썬이다/
- 개요
1.2 설명 모형 vs 예측 모형의 구축
① 설명 모형 : 전체를 설명할 경우 전체 데이터를 사용하지만
② 예측 : 5년치 데이터를 사용하는 것보다 1년치 데이터를 사용하는 것이 예측을 더 잘 한다/
③ 결론 : 데이터는 쪼개서 써야한다/
1.3 최적화 알고리즘과 휴리스틱
-> 회귀 분석의 가정(최적화 모델의 문제는 가정이 많다는 건데 현실의 데이터는 가정에 맞지 않다 > 그래서 휴리스틱 모델인 딥러닝 모델로 하는 게 정확도가 더 높다)
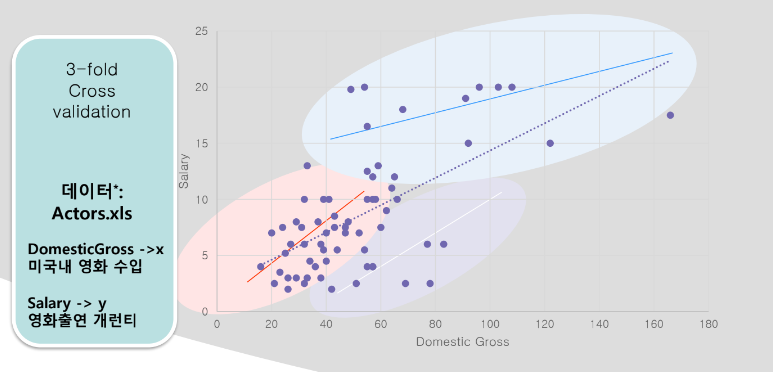
가정 1 : 이것부터 현실에서는 맞지 않다 -> 오차그래프에서 어느정도 정규분포를 띄는 오차를 가진다 > 현실은 정교분포를 따르지 않으니 벌써 가정에 맞지 않는다/
=> kfold 실습
도요타 크롤라 중고차 가격 예측

★어떤게 나한테 중요한지, 어떤 변수를 타겟으로 잡을지, 정상 정량 변수는 뭔지 확인을 시작으로하고, 피봇, 통계적 전처리를 한다, color를 그냥 다 라벨인코딩할까 아니면 몇가지로 묶을 거냐(흰색이냐 아니냐로 할까, 흰색, 회색, 나머지로 이런 걸 피봇으로 영향이 있나 없나를 보고 하면 된다 = 아 전처리 전 후를 둘 다 피봇으로 보면 되겠네)하고 난 후라고 가정 -> 왜? k폴드랑 예측 실습이니깐/
=> 데이터 보기
1. 기초 통계로 최대, 최소, 평균, 편차 등등 확인 하자
2. m_color를 보면 뉴메릭이 아니고 카테고리였으니 봐꿔야한다
3. 6, 8을 nominal
4. 데이터 4대6 스플릿
5. plain으로 하면 test입력시 예측 결과를 글자로 보여준다 -> on test split인 40의 test set에 대하여 실제값, 예측값, 오차값을 보여줌/
6. target을 price로 한다(임의로)
7. start 결과 : 표편은 작아야 안정적이고, 크면 위험한거다 w랑 같은 느낌이지/
2.2 분류 모형의 성과 평가지표
- 정확도(오분류 오차의 확률) : 분류 모형의 성과를 판단하는 기본적인 기준/
- 성과 평가

1. 민감도(=재현률) : 실제 반응할 사람을 반응할 거라고 하는 것 = 정확하게 분류할 확률 -> 사고가 난 것을 진짜 났다고 맞춘게 몇 개냐 > 리콜을 안하고 정확도를 하면 뭐가 문제임?? 일주일에 20군데에 사건이 하나도 발생안했을 때 하나도 발생안했다고 예측하면 엄청 좋은 거지? 정확도가 엄청 좋을 거야 하나가 나도 정확도는 엄청 좋을 거야 근데 리콜로 하면 실제 사고가 안난걸 안났다고 한건 안 보겠다 사고가 난 하나를 잘 봤냐를 보는거야 ★ 그 하나 발생한 그걸 봤냐 못봤냐를 평가할 수 있다는 거지/
2. 가짜양성률 : 1이라고 예측한 결과들 중에서 잘못 예측한 거 = 1이라고 예측한 결과들 중에서 0을 1로 에측한 것/ 가짜 음성률 : 0이라고 예측한 결과들 중에서 1을 0으로 예측한 것/
3. 정밀도 : 10cm로 자르는 도구를 사용했는데 그 도구가 진짜로 10cm로 자르냐 = 머신러닝 모델이 True라고 한 게 실제 True인 비율로 너네 모델이 진짜 정확히 일을 하냐/
=> cutoff(임계값으로 분류를 하는 기준 값)

분류 기분값은 기본값이 0.5이다 > 집단 1에 속할 확률을 추정한다(이걸 모델이 한다) > 그러면 0.25로 하면 집단 1에 속한다고 말할 확률이 늘어나서 오분류율이 늘어나는 거 아닐까?ㅋㅋㅋㅋ 상범아 뭐해? > 집단 1이 더 중요하므로 집단 1은 다 맞추는 게 좋으니 걍 cutoff를 낮춰서 다 집단1이라고 말하게 하는게 좋다??/
ex) pg28 0.25로 하면 음성을 양성이라고 하는 가짜양성률이 증가한다 이렇게 하는게 더 좋대 언제?? 양성을 더 잘 예측하는게 더 중요하면/

2.3 리프트
도표

cut을 0.5라고 하면 13번 이상은 예측 집단이 다 0 > 예측과 실제를 비교하여 같은 경우만 누적이 쌓임 > 7, 11 등에서 누적이 안됨 > 이 그림을 pg30에 그려놓고 맞춘 12개를 맨앞에 모아두면 좋을 거다 > 근데 확률이 높은 거부터 낮은 순서로 나열을 해놓은거기 때문에 계단형으로 나올 거고 그러면 안 좋은 모델이다 > 그래프의 양 끝 점을 연결했을때 면적이 넓어야 좋은 모델이다 > 두 모델의 그래프를 그려놓고 어떤 모델은 면적이 넓고 어떤 모델은 면적이 적으면 적은 모델이 안 좋은 거다/ -> 결론 f1이나 정밀도처럼 평가지표의 하나라고 보면 될 듯 하다/
2.4 ROC

써먹는 곳 : gs가 누구한테 광고 메일을 보내야하지? 누구한테 보내야 호갱일까 3000짜리 찌라시를 보내는데 확률로 따져서 상위 50퍼만 보내라 > 틀리기 시작하는 부분 전까지 = 상위 확률을 가지는 사람들까지는 보내라 이럴 때 쓴대(흐음 깊게 보지 않아도 될듯하다 진짜 데이터 분석으로 마케팅 팀이 분석할 때 쓰는 거잖아 근데 써먹는 곳 정도는 알아두자) > 그냥 모델이 면적이 크면 정확도가 높은 모델이다라고 볼 때 정도 쓸 듯)/
2.6

※ 오분류비용 : 오분류했을때 드는 비용으로 가짜양성으로 오분류 했을때 드는 비용이 적다면 양성이 더 중요한 비대칭성을 띄는 것 아닐까?/
-> 실제 데이터가 2% 였는데 50%로 뻥뛰기한 경우 과대표본 추출로 그래도 사용하면 안된다ㅋㅋㅋ 써봐야 알아/
2.7 예측모형 평가지표(분류와 회귀의 평가 지표가 다른다는 것)
MAPE : 예측결과가 평균적으로 얼마나 실제치에서 벗어나 있는지를 백분율/
- KNN

고객이 1000명이 있을 때 내 정보와 가장 가까운 고객의 정보로 내 데이터에 예측한다 > 모든 차원의 인풋데이터의 거리를 계산하여 가장 가까운 데이터 선택 -> 아마존이 내 정보와 가장 유사한 정보의 사용자를 찾을 때 썼대 > 이슈 : 1. 데이터가 정량이면 유사도를 찾는데 문제가 없다 근데 정성이면?? 문제가 됨/ 2. 계산 오래걸림 = 대표를 정한다고 하셨지/
=> 해결
1.데이터가 정성이면?
고객 신상 정보 > 구매한 제품 정보 > 클릭한 정보 -> 영화 어때요??를 평점을 남겨주세요~로 정성을 정량으로 달라고하거나 최근에는 클릭 정보를 데이터로 남기더라 > 어떤 제품을 클릭해서 장바구니에 넣는지, 장바구니에 넣었다 빼는지를 1점, 2점, -1점으로 바꿔서 바꿔서 정성데이터를 구하자 -> 이런 걸 다 정성데이터 다루기에 쓰면 좋겠다는 거야/ => 유사도 측정법(추천시스템에 사용됨) ★진짜 이런게 실제 기업에서 수집하는 데이터겠지..?/
=> 예제3
3개의 변수로 소유여부를 보자/
※ 타겟이 정량이면 distance weight를 줌, 정성이면 안 줌/
재현율 : 실제 오너중에 맞춘애
정밀도 : 오너라고 예측한 애중에 실제 오너/ 타겟이 정성이라서 커브가 나온다(threshholdcurve = roc, cost/benefit = 리프트도표)/ 혼돈 행렬도 나옴/
7일차
- 예제2
=> 변수
출발시간 : 18개 구간으로 나눔 -> 이건 내가 더 개선될 방향으로 나누면 됨/
=> 조건부확률
이런 x의 조건이 주어졌을때 c에 연착할 확률과 c2에 연착할 확률중 더 큰 걸 선택하는 것

=> 컨티 비행기가 dca에서 출발하여 ewr에 도착한 건 지연은 26 정각은 68일때 확률은 26/94, 68/94라서 더 큰 정각에 도착할 거란 것을 새로운 비행기에 대해서도 적용하겠다(구글의 다른 사용자의 입력) > 근데 컨티 비행기가 도착과 출발이 dca, ewr밖에 없네?? > 만약 8개의 항공사에서 도착 공항이 3개, 출발 공항이 3개 다 있다면 조건부 확률로 하기 좋다 아주아주 굉장히 정확한 방법이다/
-> pg75
조건부 확률로 추정하면 예측변수가 적더라도 경우의 수가 너무 많이 필요해서 어렵다 > 따라서 해결방안 = 나이브 베이즈
>
결합됐던 확률이 풀리면서 단순해진다 > 7개의 요일마다, 8개의 항공사마다의 3개의, 3개 마다의 경우의 수로 바뀐 거다 7*8*3*3이 마다마다로 독립된다 -> 하나하나 변수의 하나씩으로 다 떨어뜨려서 종속변수와 하나의 변수사이로 나눠버림 ∴ 데이터가 적더라도 변수별로 하나하나 존재하기만 하면 충족된다/
-> pg76

3.84는 행에 carrier 열에 flight status에 개수 + 열합계 비율에 해당(행합계 비율은 조건부 확률이다)/
=> 책임과 크기 4개에 대한 분식보고 예제
나이브는 조건부랑 베이즈랑 확률이 다른데? 아니다. 값이 필요한게 아니고 확률의 크기만 보면 되니 큰 순서는 똑같다 = 그중 가장 큰거를 보면 된다/
-> 웨카 결과(flight delay 데이터)
recall 보면 정각은 다 잘 예측하는데 지연을 정각이라고 한게 396개나 잘못하네? 왜냐? 정각에 도착한 데이터가 딜레이보다 4배 많아서 다 정각이라고 예측하려는 경향이 있다?? ★ 그러면 별로 안 좋은 거 아니야? 그래서 특정 사업에만 쓰이고, 한 데이터가 여러개 쌓이는 경우에만 쓰나?? ex) 검색 엔진에서 사과를 시과라고 친 경우가 엄청 많은 거야 그러면 사과라고 고치겠지, 근데 사과를 카과라고 치는 경우는 별로 없을 거니깐 시과라고 친 데이터가 많이 쌓일거야/
=> 장단점
1. 변수의 개수가 매우 많을 때 높은 성과/ 하지만 데이터 별로 충분한 데이터가 있어야 정확하다, 3. 법적 근거가 없다 = 신경망은 설명력이 단순 회귀보다 없으니깐/
- 의사결정나무(CART 알고르짐)
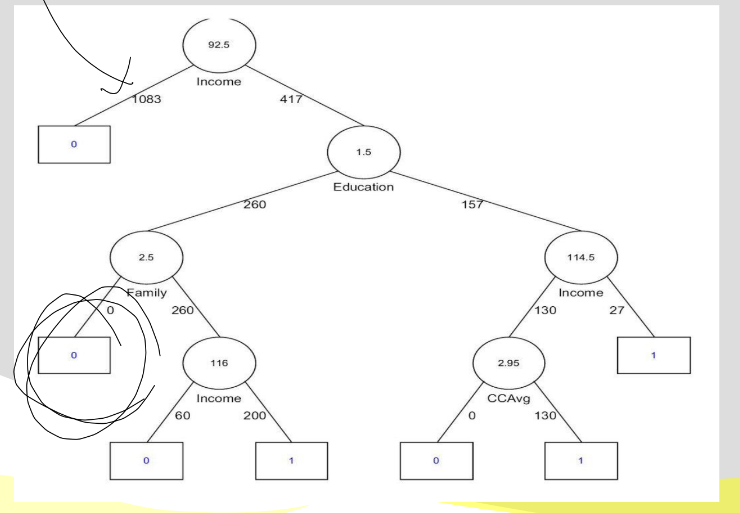
마지막 노드의 값을 구하는데 가장 중요한 변수는 루트노드겠네~라고 할 때 쓰는 모델이다/
=> 수입이 92.5보다 크고 학력이 1.5보다 작고 가족이 2.5보다 작으면 거부 당한다/
=> 핵심아이디어
1. 누구를 고를 거냐?
2. split값을 얼마로 잡을 거냐?
2. 어디까지 내려가야하지? : 깊게하면 깊게 할 수 록 정확도가 너무 올라가서 과적합됨/
=> 트리가 룰을 만드는 방법

1. professor는 무조건 y/ tant이면 6초과만 y/ 등 룰을 만듬/
2. test 데이터로 검사해봐서 이 룰을 계속 쓸거냐 말거냐를 결정/
=> 나누기 예제
pg 100)

한번에 변수 하나만 쓴다 > 소득을 한번 써보자 > 값들을 다 비교해서 사이값에 선을 그림 ex) 33과 43의 사이인 38에 하나 그림 > 24개의 데이터라 23개의 선이 생김 > 근데 제일 좋은 건 하나 그었는데 소유자 비소유자로 한번에 나눠지는 거야 -> 그걸 split값으로 쓰겠다/
- 신경망
=> bank 웨카 실습
※ more의 설명서를 봐서 모델 파라미터 조정을 해야 모델링에서의 w를 원하는대로 볼수있을 거다 -> w를 보면 얼마나 그 변수가 종속변수를 구하는데 양 또는 음의 영향을 끼치나를 알 수 있지?/
+ 파라미터 바꿔가며 모델 돌리는게 실제로 파이썬에서 모델 파라미터 바꾸는 거니 필요하면 해
=> 웨카 실습(미세먼지)
=> 신경망의 개념 및 구조
일반화 : 활용은 학습을 시키는게 아니고 이미 w를 다 구한 학습한 모델에 원하는 데이터만 넣는 것이다/
유연성 : 최적화는 안 시킨다? 역전파에의 수식과 글로벌 로컬로만 영향도를 줘서 w를 갱신만 하는 거지(에러가 글로벌로 오고) 갱신은 최적화로 일어나는게 아니다?? ㅇㅇ/
설명력 : 없다 w가 다이렉트로 구해지는게 아니라서 weka가 보여주는 w가 의미가 없고, 지니 엔트로피 등이 없다/
'[대외활동] > [데이터 청년 캠퍼스]' 카테고리의 다른 글
| 데이터 청년 캠퍼스 PART.9, 13일차 텍스트 분석 (0) | 2022.11.18 |
|---|---|
| 데이터 청년 캠퍼스 PART.8, 17일차 시공간 분석 (0) | 2022.11.18 |
| 데이터 청년 캠퍼스 PART.5일차 머신러닝 기반 분석 (0) | 2022.11.18 |
| 데이터 청년 캠퍼스 PART.4일차 통계 기반 분석 (0) | 2022.11.18 |
| 데이터 청년 캠퍼스 PART.교육 1, 2일차 start! (0) | 2022.11.09 |



