
개발자로 후회없는 삶 살기
데이터 청년 캠퍼스 PART.교육 1, 2일차 start! 본문
서론

20일 뒤에는 위 기업의 데이터 부서와 실제 데이터를 가지고 프로젝트를 하게된다. 민폐끼치지 않기 위해
최선을 다해서 교육을 듣자
본론
1일차
- 실무에 대한 관점
1. 실무에 가면 데이터가 잘 있을 거라고 생각하지 마라

-> 투입된 회사나 기관에 데이터가 있는지 보는 것부터 데이터 분석, 컨설턴트의 임무이다 > 상사가 요구하는 것은 데이터를 전문적으로, 상식적으로 상용화 가능한가 불가능한가이므로 그러한 데이터가 존재하는 가 알아보는 것부터 데이터 분석가의 일이다/
+ 프로젝트에 맞는 데이터를 구할 수 있는지 얼마 만에 데이터를 구할 수 있는지 판단 하는 것부터 일이다 -> 공공기관이나 카드, 통신 업체에 데이터를 부탁할 수도 있기에 데이터를 구하는데도 시간이 걸린다./
+ 우리 회사가 어떤 데이터를 가지고 있는지 분석가님이 알아봐주셔야 하는거 아니에요?? 라는 질문부터 받는다 > 우리회사 데이터 뭐 있는지 모르겠는데 그거부터 알아봐 주시겠어요?/
2. 실무는 내가 데이터를 처음부터 가공하고 예측까지 다 하는게 아니고 데이터 분석 파이프라인 단계 중에서 분업된 업무 중 하나를 담당하게 될거다./
3. 무조건 sql, 리눅스는 알아야한다. 기업이 희망하는 전문 데이터 분석가가 되기 위해서는 윈도우가 아닌 리눅스를 할 줄 알아야하고 다소 간단한 일은 파이썬이 아닌 sql로 처리할 수 있어야한다.
4. 데이터는 돈이다.

기획 능력이(경영, 경제학과) 우수한 팀이 장관상을 받더라 = 데이터를 분석만 하는게 아니라 돈으로 볼 줄 아는 사람이 있어야 한다는 것이다.
> 강사님이 면접 때 원하는 대답 : 데이터를 어떻게 생각하느냐 -> 데이터는 돈이라고 생각해야 한다 데이터를 보관, 사오는거 구하는 거에도 다 돈이 들어간다 > 실무의 역량은 데이터의 적당한 가격을 메기는 것도 필요하다. ★ 결론 : 실무에 나가면 데이터는 없다는 생각을 가져라/
5. human in the loop : 실무는 논리적인, 과학적인 완결성을 볼 필요가 없다 > 정확도가 50이여도 실무에 쓸만하기만 하면 된다. 99.9로 정확도를 올릴 필요가 없다 -> 50의 정확도로 업무가 개선되면 기업의 금전적 가치가 생기는 거다. > 혹시 여기 계시는 분 중에 내 앞으로 지나가는 동물을 100퍼 맞추는 분 계시나요? ㄴㄴ 사람도 잘 모른다. > 일반인 보다만 잘 하면 된다./
= ★ 없는 것보다 나은 이득을 가져다 주면 된다. 주식 투자를 예로 들면 없으면 마이너스 수익을 띄는데 있으면 0.004 퍼센트의 수익을 준다는 얘기다.
6. 빅데이터의 정의

대용량 데이터를 활용 분석하여 가치 있는 정보를 추출하고 생성된 지식을 바탕으로 능동적으로 대응하거나 변화를 예측하기 위한 정보화기술 -> 근데 이렇게 치면 영화 데이터에서 내가 4가지 목적을 잡은게 빅데이터의 정의다?? (데이터 > 정보 > 지식)
7. 데이터 사이언스의 요구사항 : 개발, 경험(지식), 수학적 지식 -> 다하는 사람을 찾기 어렵지만 그래서 팀을 짜서 하더라/
8. 데이터 분석 툴 : 나임, 오렌지 등 -> 실무에서 이런 류의 도구로 생성성있게 업무를 한다/
-> 사용 이유 : 파이썬으로 하기에는 시간이 너무 오래걸린다 -> 코딩으로는 못하는 분석이 있다 그래서 엑셀을 쓰는 건데 분석에 특화된 툴이 마임, 오렌지이다/
9. 주요 파일 데이터 유형
① csv, tsv 컴마랑 탭으로 데이터 구분하는 형식/
② json 자바스크립트 오브젝트 노테이션 : 데이터를 키,벨류
③ xml : HTML처럼 데이터를 보여주는 목적이 아닌, 데이터를 저장하고 전달할 목적으로만 만들어진 ML/ 또한, XML 태그는 HTML 태그처럼 미리 정의되어 있지 않고, 사용자가 직접 정의할 수 있음/
④ parguest, hdf5 등이 빅데이터에서 하둡, 모델등을 저장할 때 사용/
10. mlops
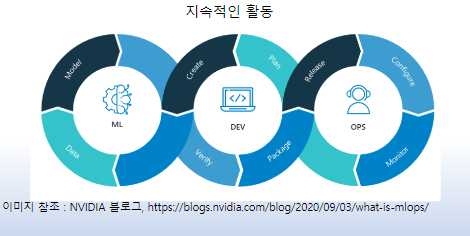
머신러닝 담당자가 개발과 운영도 함/
+ aiops : 운영에 ai의 힘을 빌리겠다는 의미 -> 우리 회사 데이터의 최고의 백업 주기는 언제니? 등을 ai로 판단/
-> 운영에 쓰는 것들
1) DVC(Data Version Control): 깃허브 같 은건데 깃허브에 올릴수있는 최대 크기가 100mb가 안된다 > 코드는 작아서 되는거지 근데 머신러닝 데이터는 어떡할까? 저장소는 따로두고 버전을 관리하게 해주는 도구가 dvc이다/
2) dagshub : 데이터의 버전관리, 모델의 관리를 클라우드 서비스에 다 맡기는 거다 -> 깃허브처럼 그래프로 버전관리 상태를 보여줌/
2일차
- no code low code

코딩이 없다 vs 클린 코드 -> + ai 실제로 코드를 짜는 것보다 nlp나 비전 도구를 활용하는 경우가 더 많다 하지만 공부는 동작의 이해를 위해 한 번은 보는게 낫다.
-> microsoft machine learning(ML) studio : 이거로 과연 노코딩을 할 수 있을까? 이걸 서비스에 넣을수 있나
> 과정 : 데이터 로드 > 분석, 전처리 > 분리 > 훈련 > 검증으로 동일한 파이프라인인데 이걸 모델 세이브가 가능하다 = 다 내부 코드로 구현되어 있나봐 -> 우와 진짜 신기하다 > 실무에서 아이리스 분포 보려고 코드를 짜는 경우는 절대 없다 방식만 알고 이런 automl 툴 쓴다(취업 박람회에서 본 컴투스가 이러한 툴을 쓰더라) > 모델 별로 하이퍼 파라미터 조정도 가능/
지금 Azure 체험 계정 만들기 | Microsoft Azure
12개월 체험 서비스, 항상 무료인 40개 이상의 서비스 및 200 USD 크레딧으로 시작하세요. Microsoft Azure에서 지금 체험 계정을 만들어 보세요.
azure.microsoft.com
- 실습
1. 기초적인 작업은 생산성을 고려했을떄 오렌지 쓰는게 좋다 -> 한번씩 파이썬으로 구현해봤다고 쳤을때 근데 이건 완전 기초 = 내가 아는 모델 학습 파이프라인은 이런거로 하는게 좋다 이거지
2. 오렌지는 협업이 안된다 + 모델 배포가 되려나?? + 내가 원하는데로 튜닝 가능?? -> 모델 배포는 가능하고 튜닝은 불가능하다 그저 적은 량의 데이터로 가능성을 보는데 사용할 것이다.
3. 이런 거로 실무에서는 파이썬이 필요없는 간단한 작업 등을 할 것이다.
※ 오렌지 문득 든 생각 : 개념 공부할 때 오렌지로 실습하면 이해는 잘 되겠다./ + 실무에서 오렌지로 먼저 작은 데이터로 학습 돌려보고 성공하면 같은 파라미터로 거대한 데이터로 파이썬으로 한다!!!
'[대외활동] > [데이터 청년 캠퍼스]' 카테고리의 다른 글
| 데이터 청년 캠퍼스 PART.9, 13일차 텍스트 분석 (0) | 2022.11.18 |
|---|---|
| 데이터 청년 캠퍼스 PART.8, 17일차 시공간 분석 (0) | 2022.11.18 |
| 데이터 청년 캠퍼스 PART.6, 7일차 머신러닝 기반 분석 실습 (0) | 2022.11.18 |
| 데이터 청년 캠퍼스 PART.5일차 머신러닝 기반 분석 (0) | 2022.11.18 |
| 데이터 청년 캠퍼스 PART.4일차 통계 기반 분석 (0) | 2022.11.18 |



