
개발자로 후회없는 삶 살기
데이터 청년 캠퍼스 PART.8, 17일차 시공간 분석 본문
서론
본론
시공간 분석(시간 + 공간 분석이다)을 배워보자

시계열 분석
- 시계열 분석 목적
1. 추세파악(= 경향파악) : 잡음을 제거하여 큰 흐름 파악
2. 원인 예측 및 대응 : 패턴을 보고 이를 극복하기 위한 예측, 방안 마련
3. 향후 전망 = 추이 전망/
- 시계열의 요인

=> 시계열 분해법 : 여러가지 요인으로 결과가 나기 때문에 하나하나 쪼개서 분석하여 요인이 뭐가 있나 봐야한다/
1) 추세요인 : 지속적인 경향을 보이는 경우의 요인 -> 어떠한 추세를 가진다의 요인
2) 계절요인 : 올라갔다 내려갔다하는 요인인데 왜 올라가고 내려가는지 이유을 아는 경우 ex) 계절도 순환임(=1년 단위의 짧은 기간 동안의 요인 주기발생)
3) 순환요인 : 순환인데 왜 그러는지 모를 때 + 긴 기간 동안의 요인을 순환 요인으로 뺌/
4) 불규칙요인 : 추세를 읽기도 애매하고 정말 많은 요인들을 하나씩 벗겨내야 분석할 수 있는 경우의 요인
-> 루트를 씌운다던가 로그를 취한다던가 여러가지 일을 해서 위의 3개의 요인으로 바꾸려고 전처리를 해야한다.
- 시계열의 데이터의 특징
1. 시간 순차성 : 시간 순차적이다/
2. 지연 값 : 관측되는 텀으로 오늘은 1시0분에 쟀는데 내일은 1시1분에 잼/
3. 주기성 : 계절처럼 주기적 변동을 의미/
1) 계절성 : 기온, 강수량, 낮의 길이 = 주기적인 변동을 의미하여 LA는 항상 봄 날씨를 유지하는데 거기도 계절마다 특정 현상이 있을 수 있다 따라서 일, 주단위 월단위 년단위로 주기가 있을 수 있고 + 3년 이상은 측정을 해봐야 알수있다/
2) 푸리에 : 파동의 모양을 뛰는 경우(ㅋㅋㅋㅋㅋ아니 다 파동아님?) > 근데 이게 상위가 주기성이니 다 비슷비슷하겠네 -> 주기적인 규칙적인 현상은 삼각함수다!!라고 말한 수학자가 푸리에래/
- 시계열 전처리 pg16

데이터가 주기적 성질을 가지는 경우 : 사인 코사인 삼각함수의 합으로 표현하여 원모양이 나오면 왼그림으로 바꿀수있고 이런 전처리를 한대(실습에서 생각)/
=> 분석 정리
①어떠한 요인인지 파악/ ②어떠한 특징인지 파악한다/ ③분석기법(단순이동, 가중이동, 지수평활)
+ 공간 분석 : 시계열은 스케터 바로 찍어보고 공간은 요소 분포 맵바로 찍어봐라 히스토그램 찍는 거랑 완전 똑같/
=> 전처리 정리
① 불규칙 요인을 추세, 계절, 순환 요인으로 바꾸려는 전처리/ ②년, 월, 일 전처리/ ③주기적 성질에 맞게 삼각함수의 합으로 표현한다/
- 시계열의 형태
해석하기 힘든 형태가 80퍼 이상이다 > ★ x축을 시간으로 y축을 다양한 요소로 두고 점 그래프를 다 찍어봐라 = 어떤 특성이 있을 수 있겠구나 파악가능 -> 기초분석에서 히스토, 파이차트 찍는 거랑 같은 거임/
=> 나타나는 변동
1) 체계적 : 실험 설계가 잘 된 데이터에서 나타나는 형태
2) 불규칙 : 우연적으로 발생(80퍼 이상) -> 요인도 80퍼 변동도 80퍼/
=> 불규칙 변동 형태

확률적으로 발생하여 언제 발생할지 알수없다 = 어디로 튈지 모른다 예측 불가/
ex) 전쟁으로 인해 기름값이 올라간다 = 그래프에 나타나지 않는 요인 때문에 확 튄다 = 세계 경제 그래프를 보면 갑자기 뚝 떨어지는 것이 발생/ 사실 산불이랑 홍수도 다 우리 기억에는 이맘때면 내리겠지하는 체계적인 주기성을 보이는 것 같지만 그래프 상으로는 다 다르다
-> 일, 월, 년 별로 봐서 남들이 생각하지 못하는 규칙성을 찾아내는게 빅데이터의 매력이다 = 지난 10년간 돌이 안 굴러 떨어졌다는 보도! 아니 이런걸 왜 찾지? 이런게 그래프상 빅데이터 분석이다/
=> 체계적 변동
추세 : 장기적으로 유지되는 추세가 일어나는 현상
순환 : 긴 순환은 반복
계절 : 계절은 특정 주기를 두어 반복(짧은 순환)/
1) 추세 : 장기간으로 짧은 기간에서는 모름 -> 지구의 평균온도=아니 겨울에 너무 추워서 온난화 맞아?? 이러는데 길게 보면 진짜 오르더라/ ★ 이런 변동이 일어나면 그 요인을 분석하는게 데이터 분석가가 할 일/

2) 순환 : 시간을 따라서 오르거나 내림을 반복 -> 경기변동(불황, 호황, 경기후퇴 등등에 따라서 순환변동이 일어난대) -> 떨어졌다가 다시 회복하는게 순환이 일어난대/

3) 계절

1년 주기로 나타나는 거 = 설등 명절을 봤을 때 주기로 볼 만한게 뭐가 있을까? 쌀값? 밀가루값? 배추값? 서울에서 부산으로 자동차로 걸리는 시간? 현금인출량?/ 그래서 이런 걸 하려면 데이터 복사본을 여러개 만들어서 이것 저것 하고 조금씩 여러번 모델을 돌려서 좋은 것만 모아야한다, 내가 무슨 분석을 한지 알 수 있어야한다/
+ 순환변동을 년 단위로 끊으면 계절성을 띔/
-> 시계열은 실생활로 좀 상식적인게 많네(그래서 재밌어) : 경제가 성장하면 백화점 판매액이 증가 = 실생활/
- 퀴즈
=> pg27

1) 추세 : 지속적인 유지 = 데이터에 별로 매력은 없음
2) 순환 : 경기가 대표인다 > 순환은 순환인데 파동의 폭, 높이 등이 다 다를 수 있다/
3) 계절 : 짧은 순환
4) 불규칙 : 모든 데이터가 이거다 그래서 잘 가공하여 1,2,3)으로 만드는게 실력이다/
=> pg28

y값이 시간에 따라서 올라가는 선형(추세) -> 반드시 3년이상 되어야 우연인지 아닌지 확인 가능, 년단위로 3번의 증가가 반복(계절)이니 이런걸 분해법으로 분해해서 봐야한다/
=> pg29

점점 지수적으로 커지고, 년따라 다르네?/
=> pg30

99년까지는 완만한 추세하다가 이후 확 증가하면 이때 무슨일이 있었구나 -> 그러면 이걸로 뭘 알 수 있을까? 99년에 그런 것처럼 나중에 이 일이 또 일어나면 나중에 어떤 결과를 낼거다 예측가능
ex) 환률이라면 99년이랑 아주 비슷한 현상이네!! 과거의 경험에서 나타난 것이기 때문에 오호라 그때 환률이 올랐으니 이제 또 오르겠네!!를 알 수 있다/
- 시계열 모형(곱해서 모형만들면 뭐하는 건데??)

1) 가법 모형 : 모형을 만들어서 분해해보니 4가지 요인이 다 보이더라 > 이 요인들이 연관이 많으면 단순 가법 모형 불가, 독립인 애들끼기 가법 모형 실시/
2) 승법 : 다 곱한거 -> 독립이면 각각의 단위를 쓰면 되는데 곱한 경우에는 단위를 비율로 한다 = 통일화지/
- 시계열 분석의 기법
이동 평균법 : 앞의 몇가지를 알고있으면 이후를 알수있는 1, 2를 알면 k를 아는 그거(귀납법)네 > 123개월의 평균을 가지고 4월의 값을 예측 > 아니 이거 야매아니야? 여러번 반복하여 오차범위를 줄이는게 필요하대/
-> n값을 잡는게 가장 중요한 이슈로 작년 데이터로 평균을 내고 올해 1월을 예측해보면 올해 1월은 이미 데이터가 있으니 그 오차를 확인하고 그걸 줄이는 방향으로 n을 잡고 쭉쭉쭉 하다보면 올해 9월(아직 데이터가 없는 것)을 예측할수있겠네/
-> 가중이동평균법 : 단순이동 평균이 3개를 묶어서 3으로 나눠 n빵하는 평균임 > 단순이 n빵하는 문제를 해결하여 작년에 1월과 3월의 값이 엄청 달라 근데 4월을 예측할 건데 1월과 4월이 비슷해 그러면 1월에 좀 더 포커싱하여 가중치를 주면 좋겠다는 기법/
※ 가중치의 합은 1이 되어야한다/
지수평활 : 앞으로 일어날 사회는 과거보다는 최근과 유사할 거라는 가정 -> 예측 오차를 비교하여 오차가 적게 만들어야하고 과거에 가중치를 작게하고 최근에 가중치를 크게 잡는다/
-> 단점 : 불규칙의 영향을 약화시키는 효과가 있지만, 계절변동, 장기추세에 안좋아 왜? 일직선으로 간단하게 만들어버리기 때문(불규칙 영향 약화)/
- 시계열 예측
과거의 패턴을 이용하여 예상한다 -> 위의 분석 기법으로 과거 관찰 기록을 연구하고 예측하는 것이므로 잘 분석해야한다/
ex) 날씨 : 근데 기상청만 봐도 아직 정확하게 예측하긴 어렵다는 걸 알수있다 -> 그날 비오는 대략적인건 맞추지만 정확히 몇시에 비오는 지는 못맞춘다/(실습을 봐야 이해가 될거같다)
- 예측방법
1. 정성 : 꼭 짚어서 오늘의 값이 내일의 값을 결정하니 내일 정확히 이럴겁니다!! ex주가 예측 > 단기예측을 할 때 정성적 방법을 한다, ex는 주가 예측이고 방법은 설문조사등으로 소비자 수요를 식별한다/
2. 정량적 : 실제 수치를 가지고 값, 장기적인 추세를 예측/ ex) 실업률 예측 : 고용노동부에 등록된 접수를 전수조사하면 된다/
- 시계열 예측 메커니즘
어떤식으로 예측을 할지 :
① 분해하는거/
② 평탄화하게만드는거/
③ 추세(경향성)을 보는 모델 -> 여기서 모델이 agent가 아니고 분석모델, 분석방법이라고 보면 될 듯/
1. 분해모델 : 3가지로 분해
추세나 계절성 분석 + 두개에 속하지 않는 노이즈를 더 잘 쪼개어 두개에 속하도록(불규칙을 속하도록하는게 분석, 전처리네)/
2. 평활화 : 너무 틔는 데이터를 위에서처럼 평탄화 작업 > 의미있는 이상치인지, 파악을 해야한다 항상 이런 건 있을 수 밖에 없네 > 주기성을 띄는 이상치는 이상치가 아니다 특출난걸 제거해야한다/
3. 회귀기반 : 서로의 인과관계, 상관관계를 보고 어떤 요소를 알면 영향있는 요소의 값을 알수있는 모델(상관임) > ex) 미술을 잘하는 애가 음악도 잘?/
※ 회귀분석 : 원인과 결과를 파악하는 분석, 상관분석 : 관계 분석 > 그래서 관계를 알고 그 관계가 결과에 영향을 미치나를 보는 것이다 = 상관분석을 하고 인과관계를 따져야한다/
- 상관관계

0.8이면 80퍼의 확률로 x를 알면 y를 알 수 있다는 의미 -> 다중공선성 : 독립변수가 3개 이상일때 변수들간에 선형 상관관계가 있는 경우로ABC가 D에 영향을 미치나를 보고 싶은데 AB랑 선형 상관이면 예측을 불안정하게 한다 ex) ABC가 사실은 하나랑 같은 결과 > 다중 공선성이 있다면 한 변수를 제거하는게 좋다(아 그래서 corr를 다른 변수들끼리도 봐야하는거구나)/
★ 등분산성, 정규성을 띄는 것을 가정한 상태에서 상관관계를 다뤄야한다/
=> TLCC

측정시간과 실제시간 사이에 발생하는 TL를 고려하여 상관계수를 계산
=> DTW

공간분석과 결합에서 쓰임 -> 최소 직선 경로를 찾는 방식으로 상관관계를 찾는 법 > 유클거리 : 직선거리 구하는 법으로 최단 직선이 아닐수있음(데이터셋끼리 1대1 비교) > DTW : 잘 모르는 데이터에서는 이게 좋다
-> 잘 모르는 데이터에서 어떤 점이 저 데이터와 거리가 짧은 가를 볼수있음/
> 유클리디안 : 일일로 측정 날짜가 같은 경우 > DTW : A데이터는 하루에 한번측정한 데이터이고 B데이터는 3일에 한번 측정한 경우에 사용/
※터빈데이터 : 일정한 주기로 주기적으로 수집할 수 있는 데이터/
- 예측 방법론
예측 방법 중에 가장 예측하기 좋은게 시계열 분석이고 정량적 방법론에 속한다/
<시간 데이터 시각화>
1. 막대 그래프 : 좋은 점 x, y를 몰라도 가운데가 제일 좋은 추세네~ 그 이유가 뭘까? 3월에 보너스를 주는 회사가 많고 학교 개강도 하네 > 그러니 3월에 신제품을 출시해야겠다!! 갤럭시 스쿨/

2. 누적 막대

누적된게 중요한 경우로 : 각각을 보면 막대 그래프 3개를 그릴텐데 > 전체 총 매출액, 전체중 의류의 중요성을 파악가능/
3. 묶음 막대
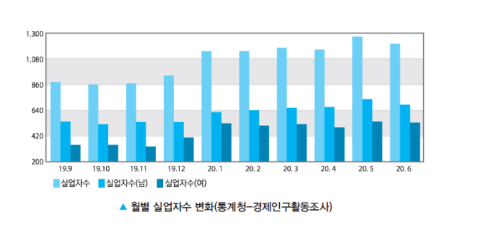
누적을 옆으로 줄줄이 연결/
4. 점 그래프

시계열 데이터는 이걸 가장먼저 찍어봐라 > 그리고 점의 색을 보자 > 처음에 데이터가 어떤 모양인지 점검하기 위해 쓴대/
5. 꺾은선

점과 점사이에 선으로 연결한 거임 > 시계열에서는 이게 제일 보기 좋다/
6. 계단 그래프

변화가 생기기 전까지 기다리다가 변화가 생기면 급격하게 변화하는 표현
<공간데이터 분석>
- 공간데이터란 뭐가 있을까?

유동인구? 시간에 따라서 어떤 지역의 유동인구가 시간 분석이었다면 공간에 따라 그 시간에 유동인구가 어떠한가? -> ★ 이런게 시공간의 완벽한 결합/
-> 누가 어디에 왜 있는지에 대한 데이터의 분석이다/
-> 비즈니스 환경에서 흔히 접하는 대부분의 데이터는 국,지,우,주같은 공간적인 요소들을 포함하고 있다 왜냐면 이제 다양한 지역의 사람들이 돌아다니기 편하고 온라인으로 많은 공간에 접근할 수 있기 때문에 수집하기 쉽다./
=> 공간 데이터를 분석하여 생활밀착형ㆍㆍㆍㆍ 활용가능 = 복합데이터임(이런 모든 데이터가 공간데이터이다) -> 그니깐 시간에 따른 데이터라도 공간데이터도 될 수 있는 데이터가 대부분이다/
=> 데이터 종류

1) 벡터
2) 레스터 : 픽셀 격자로 표현하면 더 이해가 좋대 당연한게 cnn이 다 레스터 데이터가 잘 먹겠지/
- ★ 공간데이터 분석
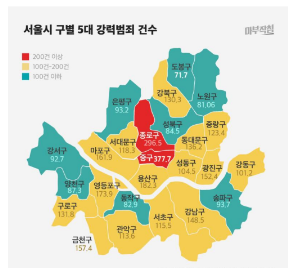
편의점 점장의 입장에서는 손님이 비싼거 사서 빨리 나갔으면 좋겠다, 겨울에는 부피가 큰 옷을 입기 떄문에 빨리 나가야 좋다 -> 이런게 시공간 분석이래 > 이거로 어디에 편의시설을 두면 좋을까? 입장로를 어디에 두면 좋을까? 등을 예측한대 > 이런 걸 실습에서 느껴보자/
+ 왜 특정 주가 아이폰을 더 많이 쓸까? 시각화 패턴을 분석하고 추세를 분석하는게 필요 > 종로구가 왜 이럴까? 등등 = 이건 데이터 분석이면 다 똑같지/
- 공간 데이터 베이스
빅데이터에 시간과 공간은 그냥 기본 옵션이 되었다 > 명목형에 시간, 공간, 구분이 있잖아 그냥 이런게 다 시공간이야 = 우리가 생활하고 데이터를 생성해내는 곳이라서 그러하다 = ★지역별 분석, ★시간대별로 분석/
=> 공간 데이터
비공간 유형 : 위도,경도, 빌딩 호수, A동, B동 등으로/
공간 유형 : 레스터 -> 실세계에 존재하는 객체의 이미지로서 항공 사진, 인공위성 사진 등의 데이터 타입/ 벡터 -> 래스터 타입으로부터 유도될 수 있으며, 점, 선, 면 등의 요소/
<공간데이터 시각화>
비례식 기호 맵 : 빈도에 따라 원과 투명도 다르게

=> 위치와 강도 등 2개가 필요하여 막대 그래프로는 안되는 건데 -> 이 맵을 활용한 데이터가 뭐가 있을까?
1) 화산폭발이라면 화산의 위치, 화산의 강도, 화산의 폭발 횟수, 화산의 가스의 양 등을 진하기 정도로 표현할 수 있겠지,
2) 서울의 스타벅스라면 위치, 원의 크기와 진하기 정도는 일일 방문자 수와 매장의 크기 등을 표시하겠네/ ★ 이런 걸 보고 왜 그럴까??를 분석하는게 공간 분석/
① 단계 부분도

구역별로 차이점을 둔 지도? -> 비율이 강하면 강할수록 진한색 ★ 이런걸 보고 왜 그럴까? 번화가가 동쪽에 많고 불규칙적인 식습관인 회사들이 많다 -> 근데 이 맵은 꼭 진하기 정도 legend 등을 둬서 뭔지 세세하게 지도만으로도 읽을 수 있도록 붙여야한다 -> 그냥 시각화가 그렇다/
2) 카풀 : 중심지에서 더 많이 일어나는 이유 : 차가 많이 막히니깐 그렇겠구나~/
-> 이걸 보고 중심을 더 확대해 봐서 정확한 스토리텔링을 만들어야한다 ex) 확대해보니 진짜 중심부는 좀 연할지도 모르자나/
-> 두 지도의 차이 : 아래는 특정 지역이 모두 해당된다/ 위는 모든 지역이 전부 해당은 아니다/
② 요소 분포 맵

그냥 찍어보는 맵 = 사이즈나 그런 걸 다룬게 아니고 그냥 찍어본 시간데이터에서 꼭 바로 이거먼저 찍어보라고 한 스캐터와 같은 용도/
③ 히트 맵(밀도 맵)

추세는 이퀄 경향으로 생각하고 -> 맨해튼의 밝은 곳은 메인 도로이고 쇼핑의 밝은 곳은 카운터겠군 이거로 나오는 것 : 분석을 잘했어도 시각화를 못하면 끝이다 이 한장으로 와,,, 함성이 나오도록하도록/(인포그래픽스 사이트 : 내가 가진 데이터를 누구나 바로 알아볼수있도록 하는 시각화를 할 수 있도록 해야한다)
⑤ 흐름 맵

근데 시작과 끝이 둘 중에 뭔지 모르겠어 + 태풍이 언제 일어났는지 이동 속도는 어땠는지 모르겠어 -> 이걸 어떻게 표현할까? 속도를 언제 언제 측정할지 먼저 구함 > 하루마다라고 정했다고 치자 > 뉴스에서 나온 것처럼 시작점에서는 작은 태풍을 그려 중간에 큰 태풍을 그려/
-> ★피해 정도는 어때? : 어떻게 나타낼지 보다 뭐를 피해라고 할지를 결정을 해야한다 > 이런 걸 표현하는 방법을 생각하는게 공간 분석의 머리이다/
⑥ 스파이더 맵 :

-> 이걸 보고 만약 멀리가는 사람이 많으면 주거지가 아닌 사람들을 위한 정책을 만든다던가 + 더 자전거를 많이 둔다던가 등 분석을 활용해서 서비스를 만들 수 있을 것이다.
'[대외활동] > [데이터 청년 캠퍼스]' 카테고리의 다른 글
| 데이터 청년 캠퍼스 PART. 11, 12일차 신경망 기반 알고리즘 (0) | 2022.11.18 |
|---|---|
| 데이터 청년 캠퍼스 PART.9, 13일차 텍스트 분석 (0) | 2022.11.18 |
| 데이터 청년 캠퍼스 PART.6, 7일차 머신러닝 기반 분석 실습 (0) | 2022.11.18 |
| 데이터 청년 캠퍼스 PART.5일차 머신러닝 기반 분석 (0) | 2022.11.18 |
| 데이터 청년 캠퍼스 PART.4일차 통계 기반 분석 (0) | 2022.11.18 |



