
개발자로 후회없는 삶 살기
데이터 청년 캠퍼스 PART.18일차 MongoDB 본문
서론
빅데이터 수집을 배우자
본론
- 센트럴 저장소 : one single machine - one db server

=> 대표 : 관계형 데이터 베이스
-> 왜 빅데이터 저장에는 효율적이지 않니 4가지 이유?? :
1) 구조가 있지 않는 데이터를 저장하기에 유연하지 않음(데이터를 가져와서 테이블 구조로 저장하면 정형데이터, 테이블 구조로 저장하지 않으면 비정형 = 처음 가져왔을 때 기준이다 json은 처음 가져오면 테이블로 저장되지도 않고 텍스트나 이미지도 아니니 반정형이다)/
2) 관계형 데이터는 저장되는 속도가 느리다
3) sql을 써야한다?/
- 디센트럴 저장소

데이터를 하나의 서버에 관리하는게 아니고 여러 서버에 관리 -> 클라우드를 생각하면 처음 시작할때 지역을 선택하더라/
=> 장점 = 센트럴의 단점
db 서버가 하나 죽어도 다른 서버를 쓰면 된다 -> 클라우드는 "내가 너의 데이터를 99.9999999% 보장하겠다"라는 말을 하더라/
=> 대표 : nosql
non relational(table) = nontable : 데이터를 저장하는데 테이블로 저장하지 않겟다(-> sql을 안쓴다는게 아님 sql도 쓴다)/
-> nosql의 특징
1) 유연성 : 테이블이 아닌 다양한 형식으로 저장한다
2) scalabilty : 규모 변경이 쉽다(관계형에서 안되는게 아님 쉽게 안됨)

-> scale up : 공간이 적으면 ram을 더주고 공간을 더 주고 이런게 된다(예를 들어 영화를 저장하는데 내 hdd가 부족하면 hdd를 추가하는 거를 생각하면 됨)
+ scale out : 데이터를 나눠서 저장함 -> 이것도 공간이 적은 경우인데 같은 서버를 크기를 키우지 말고 여러 서버에 저장하자/
- pg 23
-> 노는 테이블 말고 다른 구조로 저장하기 때문에 빅데이터를 좀 더 쉽게 관리할수있다/
1. 데이터를 테이블이 아닌 컬럼형으로 저장 -> 컬럼이 테이블이 아니다/
2. 데이터를 그래프 형식으로 저장/
3. 트리구조로 저장하고/
4. 키벨류로 저장하고 그렇다/
- 키벨류 저장소

- 문서 저장소(json, xml)

결국 키벨류 형식을 가지고 있다 -> 하나의 차이점 : 키 벨류만 있는게 아니고 키 : 배열이 있고 또 그 안에 v가 있다 = 그냥 kv가 아니고 좀 더 복잡한 구조/
- 컬럼 저장소

사용자 정보를 저장하기 위해서 밥이라는 사람의 이메일, 성별, 나이가 있다 근데 브리니니느 나이가 없고 톨리는 나라랑 머리색이 있다 -> 이 데이터를 그대로 가져와서 테이블로 저장하면 컬럼이 5개가 나온다 = 희소 테이블이 나온다 이럴 경우 컬럼 저장소를 만든다/
-> 하나의 컬럼 패밀리라고 하고 가족 구성원의 길이가 다르다/
-> 요소 : 키가 있고 키에 해당하는 컬럼을 만듬/
- 그래프 저장소

자료 2 몽고디비 미리보기
- 구조를 이해해보자

문서를 문들고 커넉션에 넣고 커넥션을 묶어서 db에 넣는다 = 커넥션안에는 문서가 있고 db안에는 커넥션이 있다 >
=> 문서 구조
에레이 안에 벨류, 에레이 안에 또 문서/

- 몽고 요소
=> 1. 데이터 베이스
따라서 db 생성해야한다 use 명령어가 새로운 db를 만든거다 > 근데 show dbs를 해도 생성이 되지 않는다?? 아직 데이터를 넣지 않아서 그렇다 = 데이터를 넣어줘야한다(이걸 컴패스에서 해도 적어도 하나의 컬렉션이 무조건 있어야 한다고 나온다)
① insert 넣어줌

② drop 전부 삭제

=> 2. 콜렉션
콜렉션을 만들어보자 -> 역시 안 생긴다 왜? 문서가 없으므로
=> 3. 문서
문서를 만들어 보자 > db.이 문서를 넣을 컬렉션.insert()/

-> 몽고 compass에서 db클릭하면 db 목록이 나오고 > 컬렉션 클릭하면 컬렉션 목록이 나오고 > document가 나온다/
- compass에서 조작
create db > 컬렉션 만들고 > 문서 만들고 쭉쭉쭉 하면 됨/
자료 3 몽고db 쿼리
find : 검색 함수
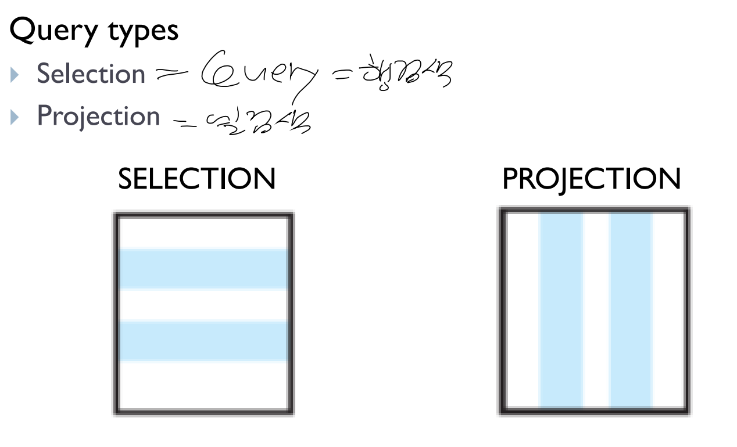
-> 파라미터 2개 : 쿼리, 프로젝션 둘 다 문서이다 = 문서라는 것은 항상 {로 시작하고 }이거로 끝난다라고 생각하자!!!/
쿼리 : 행/ 프로젝션 : 열 검색/
=> 비교함수

pg 14 equal
{ (= 하나의 다큐먼트) 필드 : {} }
인벤터리라는 컬에서 5개의 문서중 그중 qty가 25인 문서를 검색해서 보여줘 -> 파라미터인데 문서로 {}로 감싸있는 것을 봐라/ + $eq 생략 가능/
-> 대소 관계
eq말고 그냥 gt이런거로 바꾸기만 하면 된다/
-> in
status가 A거나 혹은 D인것을 보여줘라 -> 조건이 두개면 []을 써야한다/
+ nin(not in)
A가 아니거나 D가 아닌 것???/
=> logical 관계 함수
and : status가 D이면서도 qty가 75보다 작은 것을 보여줘라
or : status가 A이거나 qty가 30보다 작은 경우/
not : qty가 75보다 크지 않은거
regex : 서브스트링 매칭하는 연산자로 -> notebook에서 note만 기억날때 하는 것/
^는 앞에만 기억날 때, $는 뒤에만 기억날 때/ option을 넣을 수 있다/
- 임베드 문서 쿼리

pg37 : w를 먼저하면?? 또는 uom을 삭제하면?? 결과가 안 나온다 -> 내가 가지고 있는 데이터로 조건이 1대1 대응이 되어야 결과가 나온다/
-> 부분 검색하고 싶으면?? : dot 표기법을 쓴다 > 이걸를 쓰면 size의 하나의 벨류도 되고 두개의 벨류도 되고 그렇다 = size.h도 되고 {size.h, size.w}도 된다/
- arr of value를 다루자

tags: ["red", "blank"]인데 tags: "red" 검색하면 하나라도 포함되면 검색이 된다/
=> arr이니 인덱스 접근이 가능하다

db.inventory2.find( { "dim_cm.1": { $gt: 25 } } )이면 dim의 인덱스1의 값이 25보다 큰 애들만 검색함/ -> 그니깐 arr가 있는 경우만 이거를 쓰면 된다/
- arr of docu를 다루자

배열이 시작하고 docu가 있는지 보면된다 -> 1번은 docu가 두개, 2번은 docu가 한개 이렇다/ -> 이것도 역시 1대1 매칭이 되어야한다 {}로 감싸진 건 무조건 매칭이 되어야한다 그래서 .(dot)을 또 써야한다/
2. 드디어 파라미터 두번째 프로젝션

1이 이퀄이 아니고 그냥 보고 싶으면1 0이면 안보겠다는 거다/
'[대외활동] > [데이터 청년 캠퍼스]' 카테고리의 다른 글
| 데이터 청년 캠퍼스 PART.프젝 10, 11, 12일차(데이터 병합, EDA) (0) | 2022.12.08 |
|---|---|
| 데이터 청년 캠퍼스 PART.19, 20일차 Clustering (0) | 2022.11.22 |
| 데이터 청년 캠퍼스 PART. 11, 12일차 신경망 기반 알고리즘 (0) | 2022.11.18 |
| 데이터 청년 캠퍼스 PART.9, 13일차 텍스트 분석 (0) | 2022.11.18 |
| 데이터 청년 캠퍼스 PART.8, 17일차 시공간 분석 (0) | 2022.11.18 |



