
개발자로 후회없는 삶 살기
JPA PART.엔터티 매핑 본문
서론
※ 이 포스트는 다음 강의의 학습이 목표임을 밝힙니다.
https://www.inflearn.com/roadmaps/149
https://www.inflearn.com/roadmaps/149
www.inflearn.com
본론
jpa에서 제일 중요하게 볼 것은 내부 동작 구조 매커니즘과 객체와 DB를 어떻게 매핑해서 사용하는 지로 이번에는 매핑에 대해 알아보겠습니다.
-> 엔터터 매핑 소개

객체와 테이블을 매핑하고 필드와 컬럼, 기본키, 연관관계를 매핑하면 됩니다. 회원과 팀처럼 서로 관계가 있을 때( ex 1대다) JPA에서는 어떻게 매핑해야 하는 지에 관한 내용입니다.
- 객체와 테이블 매핑 @Entity
@Entity가 붙은 클래스는 JPA가 관리하는 엔터티로 @Entity가 붙지 않으면 JPA와 전혀 관계없는 클래스입니다.
-> 주의점
1. 기본 생성자
2. final, enum, interface, inner 클래스는 @Entity 불가
3. 저장할 필드에 final 사용 X
JPA가 관리하는 엔터티는 기본 생성자가 꼭 있어야 합니다. JPA 리플랙션 같은 내부적인 기능을 하기 위해서 필요합니다. 또한 DB에 저장할 필드에는 final을 사용하면 안 됩니다.
@Entity
public class Member {
@Id
private Long id;
private String name;
protected Member() {
}
public Member(Long id, String name) {
this.id = id;
this.name = name;
}Member 클래스를 보면 @Entity가 있습니다. 이러면 JPA가 관리하는 객체고 이걸 DB 테이블과 매핑해서 사용하는 것입니다.
@Entity
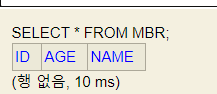
@Table(name = "MBR")@Table은 매핑할 때 테이블 명을 바꾸고 싶을 때 사용하는 것입니다. 명시하지 않으면 클래스 이름과 같은 테이블과 자동 매칭되는데 DB 테이블 name을 명시하면 'name'에 적힌 테이블과 매핑이 되어

select 쿼리를 날리면 위처럼 from MBR이 됩니다.
- 데이터 베이스 스키마 자동 생성
JPA는 매핑 정보를 보면 어떤 쿼리를 만들어야 하는지 다 알 수 있는데, 따라서 어플 로딩 시점에 DB 테이블도 생성할 수 있습니다. 따라서 이 기능을 사용하면 어플 실행 시점에 테이블이 생성되게 합니다.
이렇게 하면 확실한 장점이 있습니다. ✅
보통 개발을 할 때 설계를 다 마치고 구현 단계에서 테이블을 다 create 쿼리를 직접 사용하여 만들어 놓고 어플을 개발하는데 JPA는 그렇게 할 필요가 없습니다.
객체에 매핑을 다 해놓으면 어플이 뜰 때 테이블을 다 만들어 줍니다. 또한 DB 방언 덕분에 DB마다 적절한 DDL 생성이 가능합니다. 이렇게 생성된 DDL을 적절히 다듬어서 사용하면 됩니다.
-> 자동 생성 속성

위와 같이 ddl auto의 value 속성이 있습니다.

create를 하고 실행해보면 멤버라는 테이블이 있다면 지우고 create table을 하고 로직이 돕니다. 이렇게 어플 로딩 시점에 매핑된 엔터티들을 다 보고 테이블을 만들어 냅니다.

필드를 하나 더 추가해보면 추가한 필드를 포함해서 새로 테이블을 만듭니다. 이렇게 alter 쿼리도 직접 할 필요 없습니다. 보통은 DB 설계를 다 하고 create table sql 혹은 워크밴치 sync로 테이블을 다 만들어 두고 개발을 하는데 JPA는 이런 과정이 없어도 됩니다.
-> 속성 종류
create : 기존 테이블 삭제 후 생성
create-drop : create와 동일한데 어플 종료 시점에 테이블을 drop
update : 변경분만 반영
validate : 엔터티와 테이블이 정상 매핑되었는지만 확인
none : 자동 생성 속성 적용 X
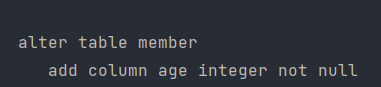
update는 변경 전에 만든 쿼리와 변경 후 만든 쿼리를 보면 alter table를 합니다.

예를들어서 age라는 필드를 추가하고 싶은데 drop을 하기 싫고 alter를 하고 싶다면 update를 사용합니다. 근데 update 속성이 필드를 지우는 것은 안 됩니다. 잘 못해서 테이블 컬럼이 날아가면 큰일나서 막아놨습니다.

validate는 db에 없는 컬럼을 필드에 추가하면 오류가 발생합니다. 정상 매핑되었는지만 확인할 때 사용합니다.
-> 자동 생성 주의점
운영 장비에는 절대로 create, create-drop, update를 사용하면 안 됩니다.

개발초기 단계는 create 또는 update를 사용해서 로컬에서 하면 됩니다. 개발이 좀 진행되고 여러 명이 함께 쓰는 테스트 서버는 update 또는 validate를 쓰며 create를 쓰면 절대로 안됩니다. create는 이미 있는 테이블을 제거하기 때문에 누군가가 넣어둔 데이터가 다 날라갑니다. 스테이징과 운영 서버는 validate 또는 none을 사용합니다. 절대로 create를 사용하면 안 됩니다.
결론은 자동 생성을 로컬 PC에서만 사용하고 여러명이 함께 쓰는 서버나 운영서버에서는 사용하지 않습니다. 또한 운영 서버에 반영할 때는 반영할 sql 스크립트 직접 일일히 쿼리를 잘 따져서 만들어야 합니다.
-> DDL 생성기능 추가
@Column(unique = true, length = 10)
private String name;@Column이라는 속성과 필드를 매핑하는 어노테이션이 있습니다.

여기에 unique와 length를 주면 unique 제약조건에 생기고 name의 길이가 생깁니다.
- 필드와 컬럼 매핑
jpa에서 필드와 컬럼 매핑은 enum 타입도 있어서 다양합니다.
-> 요구사항 추가
1. 회원은 일반과 관리자로 구분
2. 회원 가입일과 수정일이 있다.
3. 회원을 설명할 수 있는 필드가 있어야하고 이 필드에는 길이 제한이 없다.
이 요구사항을 만족하도록 필드와 컬럼을 매핑해보겠습니다.
-> 설명
@Entity
public class Member {
@Id
private Long id;
@Column(name = "name")
private String username;
private Integer age;
@Enumerated(EnumType.STRING)
private RoleType roleType;
@Temporal(TemporalType.TIMESTAMP)
private Date createdDate;
@Temporal(TemporalType.TIMESTAMP)
private Date lastModifiedDate;
@Lob
private String description;
//Getter, Setter…
}1. 객체는 username인데 DB는 그냥 name으로 서로 다르다면 name 속성을 원하는 대로("name")하면 됩니다.
2. @Enumerated는 객체에서 enum을 쓰고 싶을 때 사용하면 됩니다.
3. 날짜 타입을 쓰고 싶으면 Temporal을 쓰면 되고 날짜, 시간, 날짜+시간 속성을 명시합니다.
4. Lob은 DB에 varchar를 넘어서는 큰 용량의 내용을 넣고 싶을 때 사용합니다.

생성된 것을 보면 age는 integer로 생성됐는데 이는 int나 integer나 JPA가 dialect에 맞게 최적의 타입을 정해서 쿼리를 날려주기 때문입니다. desc는 clob, roleType은 varchar로 enum은 varchar로 매핑됩니다.
-> 매핑 어노테이션 정리

1. Transient
@Transient
private int temp;필드에는 있는데 DB와 매핑하기 싫고 메모리에서만 쓰고 싶을 때가 있습니다. 메모리에서만 임시로 사용할 때 사용합니다.

실행해보면 쿼리에 temp가 안 나옵니다.
2. Column : 컬럼매핑

제일 많이 쓰는 매핑입니다.
1) insertable
@Column(name = "name", insertable = false, updatable = false)
private String username;이 필드의 내용을 저장할 때 그 내용을 DB에 반영을 할 건지 말건지를 나타냅니다.

이름만 false로 하고 영속시켜보면


이름에 null이 들어갑니다.
2) updatable
동일하게 update할 때 DB에 반영을 할지 말지로 false로 하면 DB에 절대로 반영이 변경이 되지 않습니다.

멤버의 이름을 변경했는데도
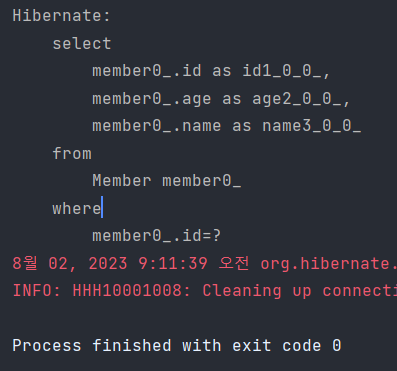
update 쿼리가 나가지 않는 것을 볼 수 있습니다.
4. Enumerated : enum 타입

enum은 기본이 ORDINAL로 enum의 순서를 DB에 저장하고 STRING은 enum의 이름을 DB에 저장합니다.


ID를 넣고 실행하면 기본(ORDINAL)이 순서를 저장해서 Integer 타입으로 쿼리가 나옵니다.


DB 결과를 보면 1번으로 두 번째 인스턴스를 나타냅니다.

STRING으로 하면 인스턴스가 들어갑니다. 근데 ORD를 쓰면 안됩니다. 순서는 enum에 인스턴스를 추가하면 변화가 일어나므로 기존 데이터에 오류가 생깁니다. 따라서 enum 타입은 무조건 STRING을 써야합니다.
3. Temporal : 날짜 타입
@Temporal(TemporalType.TIMESTAMP)
private Date createdDate;
// 이걸 사용
private LocalDate createdDate;옛날에는 필요했는데 지금은 자바 8에 LocalDateTime이 생겨서 사용할 필요가 없습니다. 현재는 @Temporal 대신에 LocalDate를 쓰면 됩니다. LocalDateTime은 DB에 timestamp로 들어가고 LocalDate는 DB에 date 타입으로 들어갑니다.
- 기본 키 맵핑
@ID와 @GenerativeValue를 알아야합니다.
-> 직접 할당
내가 ID를 직접 할당해야 하는 경우는 위처럼 @Id만 사용하면 됩니다.
-> 자동 할당
자동 생성을 하고 싶으면 @GenerativeValue를 사용해야하고 여러 전략이 있습니다. DB가 자동으로 값을 생성해줍니다.
-> 전략
1. AUTO
DB 방언에 맞게 알아서 자동 생성 됩니다.
2. Identity
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
Member member = new Member();
em.persist(member);기본 키 생성을 DB에 위임하는 것으로 setID를 안 했으면 ID 값은 NOTNULL이라서 무조건 들어가야 하는 값이라서 객체에 값이 안 들어가있으면 DB에 저장이 안됩니다.


근데 persist로 영속화 시켜보면 저장됩니다. DB가 자동으로 생성해줘서 그렇습니다. 값을 안 넣으면 null이 들어가는데 DB가 null을 데이터로 바꿔줍니다. 한 번 더 실행하면 자동으로 2가 들어갑니다.
3. sequence
주로 오라클 DB에서 사용하며 DB의 시퀀스 객체를 이용하는 것입니다.
4. Table 전략
키 생성 전용 테이블을 하나 만들어서 키만 뽑는 방법입니다.
@Entity
@TableGenerator(
name = "MEMBER_SEQ_GENERATOR",
table = "MY_SEQUENCES",
pkColumnValue = "MEMBER_SEQ", allocationSize = 1)
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.TABLE,
generator = "MEMBER_SEQ_GENERATOR")
private Long id;
}id에 매핑 전략을 Table로 잡고 generator를 @TableGenerator의 name으로 잡고 @TableGenerator에 PK 컬럼명을 잡아주면 table이 하나 생성이 되고 실행해보면


MY_SEQUENCES 라는 테이블이 실제로 하나 만들어지고 거기에 key 값이 생깁니다. member 테이블에는 MY_SEQUENCES에서 따온 pk가 자동으로 들어갑니다. 하지만 DB에서 IDENTITY로 만든 값을 사용하는 것이 좋고 이걸 많이 사용하지는 않습니다.
-> IDENTITY 전략 특징
Member member = new Member();
em.persist(member);
System.out.println(member.getId());
System.out.println("=====");IDENTITY는 애매한 게 있습니다. 바로 내가 이 ID에 값을 넣으면 안 되고 insert 할 때 값을 DB가 셋팅해줘서 insert 전에 pk값을 알 수가 없습니다.
근데 JPA의 영속성 컨텍스트를 생각해보면 컨에 1차 캐시에 무조건 PK가 있어야 합니다. 따라서 IDENTITY 케이스만 커밋 전 persist가 일어나는 즉시 insert 쿼리를 먼저 날려서 pk값을 얻어냅니다. (원래 persist는 commit 할 때 insert 쿼리가 나갑니다.)

로그를 보면 === 전에 id를 알 수 있습니다. 그래서 버퍼 라이팅으로 모아서 한 번에 보내는 것을 못 합니다. 하지만 버퍼 라이팅도 한 트랜잭션에서만 일어나니 있어도 큰 성능의 효과는 없습니다.
-> 시퀀스의 성능 문제
근데 시퀀스도 계속 시퀀스로부터 pk를 가져오니깐 네트워크를 소모하여 성능이 안 좋습니다.
@Entity
@SequenceGenerator(
name = "MEMBER_SEQ_GENERATOR",
sequenceName = "MEMBER_SEQ", //매핑할 데이터베이스 시퀀스 이름
initialValue = 1, allocationSize = 1)
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE,
generator = "MEMBER_SEQ_GENERATOR")
private Long id;따라서 allocationSize를 사용합니다. 50으로 주면 미리 pk 50개를 시퀀스로부터 가져와서 메모리 상에 저장해두고 1차 캐시에 넣습니다. 이렇게 되면 네트워크 호출이 50개의 데이터 당 한 번만 일어나게 됩니다. 테이블 전략도 마찬가지로 allocationSize를 가지고 있습니다.
- 요구사항 분석과 기본 매핑
지금까지 배운 엔터티 매핑을 복잡한 예시로 더 알아봅니다.
-> 요구사항 분석
1. 회원은 상품을 주문할 수 있다.
2. 주문 시 여러 종류의 상품을 선택할 수 있다.
-> 기능 목록
회원등록
회원조회
상품등록
상품수정
상품조회
상품주문
주문내역조회
주문취소
-> 도메인 모델 분석


1. 회원은 여러번 주문할 수 있다.(일대다)
2. 주문과 상품 (다대다)
단순한 상품 주문 도메인으로 상품과 주문 사이에 상품 목록 테이블이 있습니다.
-> 엔터티 맵핑

주문_상품을 보면 객체스럽지 않게 ID가 직접적으로 들어가 있습니다. 주문에도 회원 ID가 들어가 있는데 우선 연관관계를 배우지 않았으니 테이블처럼 설계한 것이고 이 문제점을 알아봅니다.
-> 엔터티 작성
@Entity
@Table(name = "ORDERS")
public class Order {
@Id @GeneratedValue
private Long id;
private Long memberId;
private LocalDateTime orderDate;
@Enumerated(EnumType.STRING)
private OrderStatus status;
}Order에 보면 memberId가 있습니다. 또한 테이블을 보면 ORDERS라고 되어있습니다. 이건 DB에 order by 때문에 orders로 많이 합니다. 또한 Columns에 _ID는 대문자로 되어있는데 팀 컨벤션에 맞게 하면 되고 회사 스타일대로 하면 됩니다.
@Entity
public class Item {
@Id @GeneratedValue
@Column(name = "ITEM_ID")
private Long id;
private String name;
private int price;
private int stockQuantity;db는 필드에 테이블명_을 하는 것이 관례라서 member_id, member_name으로 하고 엔터티에서는 id, name으로 한 후 Column 매핑하는 것이 좋습니다. 원래는 이름, nullable과 length 제약도 다 적는 것이 좋습니다. 인덱스도 @Table에 적는 것이 좋습니다. 그래야 이 객체를 보고 DB를 까보지 않고 jpql을 짤 수 있습니다.
-> 주의점
Order order = em.find(Order.class, 1L);
Long memberId = order.getMemberId();
Member member = em.find(Member.class, memberId);또 잘보면 이상한게 있습니다. Order를 보면 find로 찾았다고 했을 때 이 주문을 한 회원을 찾은 후에 find를 또 해야 객체를 찾을 수 있고 이는 객체 지향적이지 않습니다. 이 주문을 한 회원이 누군지를 이렇게 찾는게 아니고 order.getMember로 바로 꺼낼 수 있는 것이 객체 지향적인 코드입니다. 이런 설계가 객체를 DB에 맞춘 코드라고 합니다.
+ 문제점

객체 그래프 탐색이 불가능하고 참조가 없으므로 UML도 잘못된 것입니다. 그래서 연관 관계 매핑에 대해 배웁니다.
'[백엔드] > [JPA | 학습기록]' 카테고리의 다른 글
| JPA PART.고급 매핑 (0) | 2023.08.20 |
|---|---|
| JPA PART.다양한 연관관계 매핑 (0) | 2023.08.17 |
| JPA PART.연관관계 매핑 기초 (0) | 2023.08.12 |
| JPA PART.영속성 관리 (0) | 2023.06.11 |
| JPA PART.JPA 환경 구축 및 실습 (0) | 2023.06.07 |



