
개발자로 후회없는 삶 살기
JPA PART.영속성 관리 본문
서론
※ 이 포스트는 다음 강의의 학습이 목표임을 밝힙니다.
https://www.inflearn.com/roadmaps/149
김영한의 스프링 부트와 JPA 실무 완전 정복 로드맵 - 인프런 | 로드맵
Java, JPA 스킬을 학습할 수 있는 개발 · 프로그래밍 로드맵을 인프런에서 만나보세요.
www.inflearn.com:443
본론
jpa의 내부 구조가 어떻게 동작하는지 알아보겠습니다.
- 영속성 컨텍스트
jpa를 이해하려면 영속성 컨텍스트를 이해해야 합니다. jpa에서 가장 중요한 2가지는 엔터티와 DB 테이블 매핑과 영속성 컨텍스트입니다. 매핑은 설계와 관련된 정적인 것인데 영속성은 실제 jpa 내부 동작입니다.
-> 그림

jpa를 쓰게 되면 공장과 매니저를 씁니다. 예를들어 웹 어플을 개발하면 공장을 통해서 고객 요청이 올 때마다 매니저 1, 2를 생성하고 매니저가 내부적으로 커낵션을 써서 db를 쓰게 됩니다.
-> 영속성 컨텍스트란?
jpa를 이해하는데 가장 중요한 용어로 엔터티로 영구 저장하는 환경이라는 뜻으로 em.persist를 보면 객체를 DB에 저장하는 것으로 배웠습니다. 이거는 사실 DB에 저장하는게 아니라 영속성 컨텍스트를 이용하여 엔터티를 영속화한다는 뜻이고 사실 DB에 저장하는 게 아니고 엔터티를 영속성 컨텍스트에 저장하는 것 입니다. 영속성 컨텍스트는 논리적인 개념으로 눈에 보이지 않습니다. 매니저를 통해 컨텍스트에 접근합니다.
-> 컨텍스트 환경

매니저를 만들면 1대1로 컨텍스트가 생성이 됩니다. 매니저 안에 컨텍스트라는 공간이 생기는 것이라고 볼 수 있습니다.
- 엔터티의 생명주기
엔터티는 생명주기가 있습니다.
1) 비영속

최초에 객체를 new로 만든 컨텍스트와 전혀 관계가 없는 새로운 상태입니다. 그림을 보면 회원을 생성하고 컨텍스트에 아무것도 하지 않고 jpa와 전혀 관계없는 상태입니다.
2) 영속

em.persist()를 하면 영속 상태로 컨텍스트에 관리되는 상태입니다. 맴버 객체를 생성을 하고 매니저를 생성한 후 트랜잭션 환경에서 persist에 멤버를 넣으면 매니저 안에 컨텍스트에 멤버 객체가 들어가면서 영속 상태가 됩니다.
try {
Member member = new Member();
member.setId(100L);
member.setName("HelloJPA");
System.out.println("=====");
em.persist(member);
System.out.println("=====");
tx.commit();
} catch (Exception e) {
tx.rollback();
} finally {
em.close();
}코드를 보면 setName까지는 jpa와 아무 관계가 없는 상태인 비영속 상태로 "멤버 엔터티가 비영속 상태다"라고 합니다. 당연히 DB에 아무 데이터도 들어가지 않습니다. persist에 멤버 객체를 넣으면 영속 상태가 되고 매니저 안에 있는 컨텍스트을 통해서 멤버가 관리가 됩니다.
이전엔 이렇게 하면 db에 저장되는 것으로 알았는데 사실 Db에 저장이 되지 않습니다. db에 저장이 되는 거라면 이때 쿼리가 나가야할 것입니다.

근데 persist에 앞뒤로 sql이 나가는지 확인해보면 나가지 않습니다. ====가 끝나고 insert가 날라갑니다.
그러면 persist는 뭐를 하는 것일까요? ✅
결론부터 말하면 영속 상태가 된다고 해서 바로 db에 쿼리가 날라가는 게 아니고 트랜잭션 커밋이 되는 시점에 매니저가 컨텍스트에 있는 애를 보고 엔터티 분석을 해서 DB에 쿼리가 날라갑니다.
3) 준영속 + 삭제

매니저에서 detach(member)를 하면 컨텍스트에서 다시 그 엔터티를 지워서 jpa와 관계를 없애는 것입니다.
- 영속성 컨텍스트의 이점
어플과 db 사이에 중간 계층을 둬서 얻어내는 것이 있습니다.
1차 캐시
동일성 보장
쓰기지연, 변경감지, 지연로딩
등 중간에 뭔가 있으면 캐시를 하거나, 버퍼링을 할 수도 있습니다. 이러한 이점을 자세히 알아봅니다.
-> 1차 캐시

컨텍스트은 내부에 1차 캐시라는 것이 있습니다. 멤버를 비영속 상태로 만들고 persist를 하면 어떤 일이 일어나나 알아봅니다. 매니저의 컨텍스트의 내부에 1차 캐시라는 게 있는데 키-벨류 형태입니다. @Id가 DB pk고 값이 Entity 객체 자체로 지금은 id가 pk인 member1, 값이 멤버 엔터티 객체 자체입니다.

이렇게 하면 조회할 때 이점이 있습니다. 멤버를 영속하고 find로 조회하면 먼저 DB가 아닌 1차 캐시를 뒤져서 DB 값이 아닌 캐시에 있는 값을 조회합니다. 세션과 같은 개념입니다.

회원 2는 Db에는 있고 1차 캐시에는 없다는 가정을 하고 조회하면 find에서 회원 2를 찾는데 1차 캐시에 없어서 DB에서 조회를 하고 DB에서 조회한 회원을 1차 캐시에 저장하고 멤버 2를 반환합니다. 이후에 멤버 2를 또 조회하면 1차 캐시의 멤버 2를 반환하고 Db를 조회하지 않습니다.
근데 이건 그렇게 큰 이점은 아닙니다. 트랜잭션 단위로 동작하는 매니저는 고객의 요청이 끝나면 지워버려서 1차 캐시도 날라갑니다. 여러명의 고객이 공유하는 2차 캐시가 아니고 한 트랜잭션에서만 효과가 있어서 성능 이점을 얻을 수 있는 장점은 없습니다.
System.out.println("====");
em.persist(member);
System.out.println("====");
Member findMember = em.find(Member.class, 101L);
System.out.println("findMemeber.id = " + findMember.getId());
System.out.println("findMemeber.name = " + findMember.getName());find로 가져와서 출력을 해서 조회용 sql이 나가는지 확인해보면

sout문 이전에 persist와 find를 했는데 insert는 sout문 다음에 나오고 find는 select 쿼리가 나오지도 않습니다. insert는 지금 고려할 게 아닌데 select는 나가지도 않았습니다. 그 이유는 persist를 하면 DB가 아닌 1차 캐시에 저장을 하고 find를 하면 DB에서 가져오는게 아니고 1차 캐시에서 가져와서 그렇습니다.
try {
Member findMember = em.find(Member.class, 101L);
Member findMember1 = em.find(Member.class, 101L);
tx.commit();
}이번에는 DB에는 저장한 상태에서 어플리케이션을 새로 돌려서 매니저를 새로 만들어 컨텍스트을 새로 만들고 2번 조회해보겠습니다.

그러면 첫번째 조회할 때는 1차 캐시에 없어서 DB에서 가져와 쿼리가 나가야하고 2번째 조회할 때는 1차 캐시에서 가져와 쿼리가 나가면 안 됩니다. 조회를 할 때 먼저 1차 캐시를 보고 없으면 DB를 보고 DB에서 가져온 것을 1차 캐시에 올리도록 동작해서 그렇습니다.
-> 영속 엔터티의 동일성 보장
try {
Member findMember = em.find(Member.class, 101L);
Member findMember1 = em.find(Member.class, 101L);
System.out.println("result = " + (findMember1 == findMember));
tx.commit();
}컬랙션에서 == 비교하면 똑같은데 jpa도 똑같습니다.
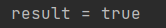
결과를 보면 T가 나옵니다. jpa는 마치 컬랙션에서 가져온 것이 주소가 같아서 같은 것처럼 영속 엔터티에 같은 트랜잭션 안에서 일어나는 것은 동일성을 보장해서 == 비교를 보장해줍니다. 이게 가능한 것이 1차 캐시가 있어서 그렇습니다.
-> 쓰기 지연
엔터티를 등록할 때 쓰기 지연이 가능합니다. 트랜을 실행하고 em.persist로 회원 A, B를 넣어두면 여기까지 insert sql을 보내지 않고 jpa가 쭉쭉 쌓고 있고 커밋되는 순간에 insert sql을 db에 보냅니다. 그래서 아까부터 "==="가 다 끝나고 커밋할 때 insert 쿼리가 나간 것입니다.
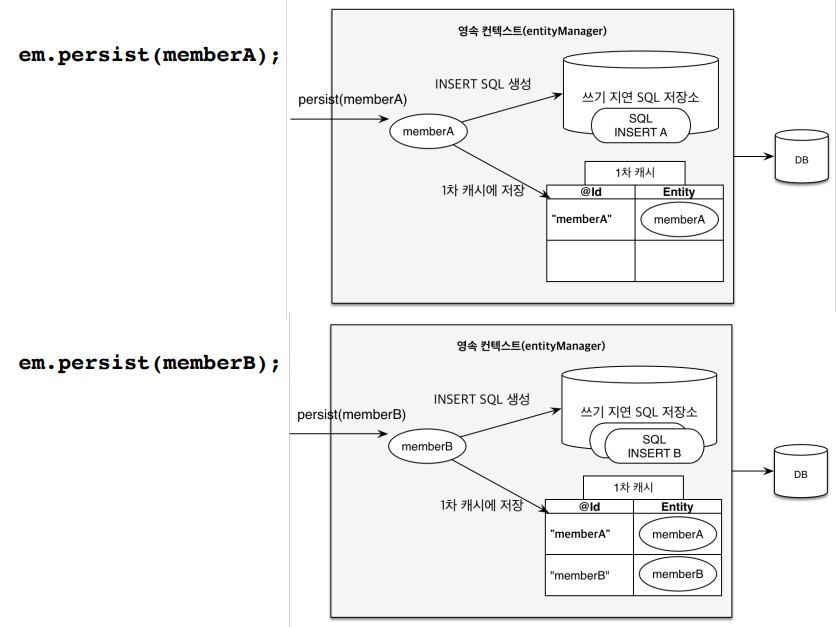
그림을 보면 A와 B를 컨텍스트에 순차적으로 넣습니다. 컨텍스트에는 1차 캐시도 있지만 쓰기 지연 SQL 저장소라는 것도 있습니다. A를 딱 저장을 하면 A는 일단 1차 캐시에 들어갑니다. 그리고 동시에 jpa가 엔터티를 분석을 해서 insert 쿼리를 만들어서 저장소에 쌓아둡니다. 이때까지 DB에 들어가는 것이 없습니다. B도 저장하면 똑같이 캐시에 넣고 쿼리도 저장소에 쌓습니다. 역시 이때까지 DB에 들어가는 것이 없습니다.
얘가 언제 쿼리가 DB에 날라가냐면 커밋을 하는 시점에 저장소에 있던 애들이 flush가 되면서 DB에 날라가고 커밋됩니다. 역시 트랜잭션이 끝나면서 매니저도 없어져서 다음에 다른 persist를 한다고 해도 이전에 캐시에 넣어둔 데이터들은 없습니다. 이 그림을 머리에 그리는 것이 정말 중요하고 그러면 jpa 동작 방식이 이해됩니다.
try {
Member member1 = new Member(150L, "A");
Member member2 = new Member(160L, "B");
em.persist(member1);
em.persist(member2);
System.out.println("===================");
tx.commit();
}
====을 긋고 보면 로그에 선을 긋고 나서 쿼리가 나갑니다. persist를 할 때는 객체도 캐시에 저장하고 쿼리도 저장소에 저장해서 아무런 일이 로그에 남지 않고 커밋을 할 때 쿼리가 나갑니다. 단순하게 생각하면 무조건 커밋이 트랜잭션의 마지막에 있으니 맨 마지막에 쿼리가 나갈 것입니다.
왜 굳이 이렇게 하까요? ✅
버퍼링이라는 기능을 쓸 수 있습니다. 이렇게 하면 쿼리를 1번만 날립니다. 쿼리는 1번만 날리는 게 어플리케이션 성능에 좋습니다.
<property name="hibernate.jdbc.batch_size" value="10"/>배치 사이즈를 주면 이 사이즈만큼 쿼리를 모아서 한 번에 DB에 보냅니다. 이것을 탬플릿을 쓰면 버퍼링을 모아서 날리도록 코드를 짜야하는데 jpa가 필요한 기능을 제공하는 것입니다.
-> 엔터티 수정 변경감지
try {
Member member = em.find(Member.class, 150L);
member.setName("ZZZZ");
System.out.println("===================");
tx.commit();
}멤버를 찾고 A를 ZZZZ로 바꿉니다. 정말 단순하게 set으로만 컬랙션처럼 데이터를 수정합니다. select 쿼리는 어플리케이션에 지금 당장 필요한 것이라서 커밋 전에 나갑니다. 근데 컬랙션처럼 값만 바꿨는데 update 쿼리도 나갑니다. update 메서드 같은 게 필요할 거 같은데 수정이 됩니다.
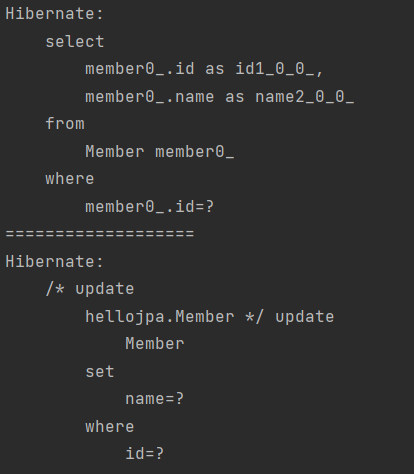
이게 왜 이렇게 되냐면 jpa는 변경 감지라는 기능이 제공이 됩니다. 제 생각엔 update 코드를 해야하는데 그런 코드 없이 DB에 변경이 일어납니다. 탬플릿에서도 update 쿼리를 string으로 작성하고 DB에 직접 날렸는데 여기는 그런게 없어보입니다.
+ 그림

비밀은 다 컨텍스트에 있습니다. jpa는 커밋을 하는 순간에 엔터티와 스냅샷을 비교합니다. 1차 캐시에 원래 엔터티가 저장된다고 했는데 스냅샷이라는 것도 있습니다. 스냅샷은 엔터티를 읽어온 최초 시점에 컨텍스트에 들어온 상태의 엔터티를 스냅샷을 해놓습니다. 그 상태에서 엔터티 값을 변경하면 jpa가 커밋하는 시점에 실제 엔터티와 스냅샷을 비교를 해서 엔터티가 바뀌었으면 update 쿼리를 저장소에 만들어서 넣고 DB에 보내서 커밋합니다.
※ 엔터티 삭제는 커밋 시점에 delete 쿼리가 나갑니다.
- 플러시
플러시는 컨텍스트의 변경 내용을 db에 반영하는 것입니다. 보통 커밋할 때 플러시가 일어납니다. 저장소에 쌓아둔 쿼리를 db에 날리는 것으로 컨텍스트의 변경 사항과 db의 상태를 쿼리를 날리는 것을 통해 맞추는 것입니다.

커밋 직전에 플러시가 자동으로 발생하며 이때 변경 감지를 해서 수정된 엔터티를 쓰기 지연 sql 저장소에 등록하고 저장소에 쌓여있는 모든 쿼리를 db에 전송합니다. db에 날라간 sql들이 반영된 후에 커밋을 합니다.
-> 컨텍스트을 플러시하는 방법

이를 실제로 할 일은 거의 없지만 테스트를 위해서 알아는 둬야합니다.
try {
Member member = new Member(200L, "member200");
em.persist(member);
em.flush();
System.out.println("===================");
tx.commit();
}persist를 해도 커밋할 때 까지 쿼리를 볼 수 없는데 그 전에 미리 보고 싶으면 flush()를 하면 되고 그 즉시 플러시를 했을 때 일어나는(변경감지, 수정 쿼리 sql 저장소에 작성, 저장소 쿼리 db에 전송) 동작들이 일어납니다.

보면 === 선 전에 insert 쿼리가 호출됩니다. persist를 하면 컨텍스트에 담기고 flush로 바로 쿼리가 날라갑니다. 플러시를 하면 1차 캐시가 다 지워지는 건 아니고 오직 앞에서 본 동작들만 일어나 db에 반영만 됩니다.

jpql 쿼리를 실행시 플러시가 자동으로 호출되는 이유는 jpql은 조회 쿼리를 할 텐데 그러면 db에 저장이 되어있어야 합니다. 만약 플러시가 되지 않으면 persist는 커밋 시점에 쿼리가 날라가 조회 결과가 없을 것 입니다. 그래서 jpql 실행 전에 무조건 플러시를 날려서 jpql 쿼리가 개발자 의도대로 동작하게 합니다.

근데 커밋을 할 때만 플러시가 되고 쿼리를 실행할 때는 플러시가 안 되게 해야할 때가 있습니다. persist는 회원을 저장하는데 jpql은 상품을 가져오는 경우는 쿼리를 실행한다고 플러시로 얻을 수 있는 이점이 없습니다. 그때 플러시 속성값을 커밋할 때만 되게 변경하면 됩니다.
- 준영속 상태
영속 상태에서 준 영속 상태로 바꿀 수 있습니다. persist를 하거나 find를 하면 컨텍스트이 엔터티를 관리하는 영속상태입니다. 준영속은 영속상태의 엔터티를 다 컨텍스트에서 분리하는 것으로 이렇게 되면 컨텍스트이 관리를 안해서 변경감지나 동기화가 불가합니다.
-> 준영속 상태로 만드는 방법
1. detach()
try {
Member member = em.find(Member.class, 200L);
member.setName("AAAA");
em.detach(member);
System.out.println("===================");
tx.commit();
}멤버를 find로 가져오면 영속 상태입니다. 컨텍스트이 관리하기 싫어서 detach()를 하면 이제 jpa에서 관리를 안 하는 것이고 컨텍스트에서 다 빠져버려서 커밋을 할 때 아무 일도 일어나지 않습니다.

실행해보면 조회 쿼리는 나가는데 수정 쿼리는 안 일어납니다. 커밋 시점에 수정 쿼리가 나가는데 detach로 이것과 관련된 것을 다 빠져버립니다. 이것도 직접 쓸 일은 거의 없는데 웹 어플에서 사용하는 경우가 있습니다.
try {
Member member = em.find(Member.class, 200L);
member.setName("AAAA");
em.clear();
Member member2 = em.find(Member.class, 200L);
System.out.println("===================");
tx.commit();
}em.clear나 close를 해도 준 영속 상태로 만들 수 있는데 매니저의 컨텍스트을 통째로 다 지우는 것입니다.

clear를 하고 find를 또 하면 컨텍스트에 없어서 1차 캐시에서 가져오지 않고 DB에서 가져와서 조회 쿼리가 2번 나갑니다. close는 컨텍스트을 종료하는 것이라서 아예 매니저가 없어지는 것입니다.
'[백엔드] > [JPA | 학습기록]' 카테고리의 다른 글
| JPA PART.고급 매핑 (0) | 2023.08.20 |
|---|---|
| JPA PART.다양한 연관관계 매핑 (0) | 2023.08.17 |
| JPA PART.연관관계 매핑 기초 (0) | 2023.08.12 |
| JPA PART.엔터티 매핑 (0) | 2023.08.01 |
| JPA PART.JPA 환경 구축 및 실습 (0) | 2023.06.07 |



