
개발자로 후회없는 삶 살기
JPA PART.연관관계 매핑 기초 본문
서론
※ 이 포스트는 다음 강의의 학습이 목표임을 밝힙니다.
https://www.inflearn.com/roadmaps/149
본론
- 연관관계 매핑 기초
테이블에 맞춰서 fk를 그대로 가져와서 설계하는 것이 아닌 연관관계를 갖춘 객체지향 설계를 배웁니다. 객체와 DB의 패러다임의 차이를 극복해 보겠습니다.
객체는 레퍼런스로 쭉 따라갈 수 있는데 테이블은 외래키를 이용합니다. 객체의 참조와 테이블의 외래키를 매핑하는 법을 배워야 합니다.
-> 예제 시나리오
구체적인 예제로 알아봅니다.
회원과 팀이 있다.
회원은 하나의 팀에만 소속될 수 있다.
회원과 팀은 다대일 관계다.(회원이 N)
-> 테이블에 맞춘 설계
@Id @GeneratedValue(strategy = GenerationType.AUTO)
@Column(name = "MEMBER_ID")
private Long id;
@Column(name = "USERNAME")
private String name;
@Column(name = "TEAM_ID")
private Long teamId;회원이 N측이라서 다측의 pk를 가져야 하는데 팀 참조가 아닌 팀 id 외래키를 그대로 가집니다.
1. 저장시 문제
Team team = new Team();
team.setName("TeamA");
em.persist(team);
Member member = new Member();
member.setName("member1");
member.setTeamId(team.getId());
em.persist(member);회원을 저장하려면 팀을 만들고 팀을 저장하고 회원을 저장할 때 영속 상태에 들어간 팀의 id를 가져와서 회원을 저장합니다. 이게 객체 지향스럽지 않습니다. setTeam이라고 해야할 것 같은데 연관 관계 매핑을 안해서 ID를 그대로 받습니다.

정말 자바를 쓰는 매리트가 없어집니다. 자체 테스트, 자체 검증을 못 하게 됩니다.

팀과 회원을 한 번에 가져오려면 join 문법을 사용해야 합니다.
2. 조회시 문제
Member findMember = em.find(Member.class, member.getId());
Long findTeamId = findMember.getTeamId();
Team findTeam = em.find(Team.class, findTeamId);회원을 조회할 때 회원을 조회한 후 회원이 어떤 팀 소속인지 알고 싶으면 회원의 teamid로 팀을 find한 후 team을 꺼내야합니다. 뭔가 하나 할 때마다 jpa에게 계속 물어보게 됩니다. 연관관계가 없기 때문입니다.

객체를 테이블에 맞추어 데이터 중심으로 모델링하면, 협력 관계를 만들 수 없습니다. 테이블은 외래키로 조인을 해서 연관된 테이블을 찾는데, 객체는 참조를 사용해서 연관된 객체를 찾습니다. 이러한 패러다임의 차이가 있습니다.
- 단방향 연관관계
가장 기본이 되는 연관관계를 알아봅니다.
-> 객체 지향 모델링

회원에 팀 참조를 넣습니다.
@ManyToOne
@JoinColumn(name = "TEAM_ID")
private Team team;그러면 jpa에게 이 둘의 관계가 무엇인지 알려줘야 합니다. 회원이 N이고 팀이 1입니다. 그래서 회원이 N이라고 ManyToOne 어노테이션을 붙입니다. 그리고 member 테이블의 fk와 회원 엔터티의 team을 매핑해야 하는 것입니다.
그니깐 team_Id와 team을 매핑하는 것인데 둘 다 참조한다고 보면 이해하기 쉽습니다. JoinColumn하고 회원 테이블의 fk 이름을 줍니다. 회원 엔터티를 설계할 때 team 엔터티와 team 테이블은 볼 것이 없습니다. 다 회원 테이블에 나와있는대로 매핑하는 것입니다. 그래서 테이블 설계가 중요합니다.
> 이렇게 하면 매핑이 끝난 것입니다. 테이블을 설계하고 테이블 설계를 보며 엔터티 설계를 하면 됩니다. 이렇게 하면 마음껏 사용할 수 있습니다.
-> 해결
1. 저장
// 이전
Team team = new Team();
team.setName("TeamA");
em.persist(team);
Member member = new Member();
member.setName("member1");
member.setTeamId(team.getId());
em.persist(member);
// 이후
Team team = new Team();
team.setName("TeamA");
em.persist(team);
Member member = new Member();
member.setName("member1");
member.setTeam(team);그냥 팀을 만들고 회원에 set하면 jpa가 알아서 pk 값을 꺼내서 insert할 때 회원 테이블에 fk로 넣어줍니다. 근데 이때도 팀을 저장해야 합니다. jpa는 insert를 할 때 pk를 가져오는데 지금 팀의 pk를 회원의 fk로 하기 때문에 팀의 pk가 반드시 필요합니다.
2. 조회
// 이전
Member findMember = em.find(Member.class, member.getId());
Long findTeamId = findMember.getTeamId();
Team findTeam = em.find(Team.class, findTeamId);
// 이후
Member findMember = em.find(Member.class, member.getId());
Team findTeam = findMember.getTeam();조회도 그냥 getTeam하면 바로 팀이 나옵니다. 이전 코드와 비교를 해보면 id를 직접 fk로 사용했을 때와 번거로움이 사라지고 객체 지향적으로 레퍼런스를 가져오는 것을 확인할 수 있습니다.

jpa가 회원과 팀을 조인해서 한 번에 가져오는 것입니다. 여기서 핵심은 "jpa를 활용하면 객체의 참조와 DB의 외래키를 매핑할 수 있구나"입니다.
3. 수정
member.setTeam(teamB);팀을 B로 바꾸고 싶으면 setTeam으로 팀을 넣으면 update 쿼리가 날라가서 team 참조에 매핑된 테이블의 fk가 변경됩니다.
- 양방향 연관관계와 연관관계의 주인
참조와 외래키의 차이를 이해해야 주인의 개념을 알 수 있습니다. 이는 JPA의 기능이라기 보단 DB 테이블의 개념이고 이걸 잘 이해해야 JPA라는 도구를 잘 쓸 수 있습니다.
=> 양방향 매핑
지금 봤던 것은 단방향 매핑으로 멤버에서 member.getTeam()으로 팀으로 갈 수 있는데 팀에서는 멤버를 참조하고 있지 않아서 팀에서 멤버로는 당연히 못갑니다.
@OneToMany(mappedBy = "team")
private List<Member> members = new ArrayList<>();근데 사실 이 둘을 레퍼런스로 넣어두면 양쪽으로 갈 수 있고 양쪽으로 참조하게 만들면 양방향 연관관계라고 합니다. (한 쪽에 참조를 넣으면 단방향, 양쪽에 넣으면 양방향 연관관계입니다.)
-> 테이블 모양

테이블의 모양을 보면 단방향 예제와 똑같이 회원에 외래키로 팀의 id를 넣어둡니다. 양방향으로 할 때도 테이블은 전혀 변화가 없습니다. 왜냐하면 테이블은 외래키로 조인하면 팀에서 회원으로 갈 수 있고 회원에서도 팀으로 갈 수 있습니다. 테이블은 외래키 하나로 양방향이 다 있는 것입니다. 테이블의 연관관계는 방향이라는 관계가 없고 fk가 넣어두면 양쪽이 다 알 수 있습니다. 하지만 문제는 객체입니다.
-> 엔터티 모양

이전 예제에서는 회원이 팀을 가져서 팀으로 가는 것은 되는 데 팀은 회원을 가지지 않아서 회원으로 못 갑니다. 따라서 팀 쪽에 List로 다측의 참조를 넣어야 합니다. 둘 다 셋팅해야 하는 것입니다. 이게 객체와 테이블의 가장 큰 패러다임 차이입니다.
-> 팀 엔터티
@OneToMany(mappedBy = "team")
private List<Member> members = new ArrayList<>();팀에 리스트를 넣고 new로 초기화 해두는 것이 관례입니다. 이전 멤버는 다대일이니 팀은 일대다로 어노테이션을 잡고 mappedBy = team을 적는데 이것은 "1대 다 관계에서 뭐랑 연결되어 있지?" 라는 것으로 멤버에 있는 team 참조입니다. 다대일은 테이블과 JoinColumn을 하는데 일대다는 다측과 mappedBy를 합니다.
Member findMember = em.find(Member.class, member.getId());
List<Member> members = findMember.getTeam().getMembers();
for (Member m : members) {
System.out.println("m = " + m.getName());
}이렇게 하면 반대로 탐색을 할 수 있습니다. 팀에서 getMembers 호출이 됩니다. 이렇게 보면 회원에서 팀으로 팀에서 다시 회원으로 가는 것을 양방향 연관관계라고 하고 반대 방향으로 객체 그래프 탐색이 가능합니다.
=> mappedBy는 뭐죠?
이 포인트가 진짜 중요합니다. 이는 객체와 테이블간의 연관관계를 맺는 차이를 이해해야 합니다.
-> 차이

1. 객체
객체의 연관관계는 2가지가 있습니다.
팀 > 회원
회원 > 팀
객체는 팀에서도 가고 회원에서도 가는 것으로 단방향이 2개가 있어서 양방향이 됩니다. 참조가 양쪽에 있어야 합니다.
2. 테이블
테이블은 다측에 fk를 하나 두는 것으로 연관관계를 가지고 1가지입니다. 이 1개만으로 회원도 팀을 알 수 있고 팀도 회원을 알 수 있습니다. fk로 연관관계가 끝이 납니다.
테이블은 사실 방향이 없는 것으로 보면 되고 객체는 단방향이 두개가 있는 것으로 봐야하며 이 두 차이가 시작입니다.
-> 객체의 양방향
객체의 양방향은 단방향 2개로 억지로 양방향으로 부르는 것이고 객체의 양방향은 참조를 각각 2개 만들어야 합니다.
-> 테이블의 양방향
테이블은 fk 하나로 두 테이블의 관계를 관리합니다. 따라서 fk 하나만 있으면 양쪽을 알 수 있습니다. 따라서 joincolumn이 테이블의 컬럼을 엔터티에 적는 것이었는데 팀에는 없어서 joincolumn을 할 수 없습니다.
+ 딜레마

여기서 딜레마가 옵니다. 객체는 2개를 만들어 뒀는데 멤버의 팀 참조를 바꿨을 때 외래키가 업데이트 되어야할까? 팀의 멤버를 업데이트했을 때 외래키를 업데이트 해야할까? 딜레마가 옵니다.
그니깐 멤버의 외래키, 즉 멤버 테이블이 보고 있는 다른 테이블의 값을 바꾸고 싶을 때 멤버 엔터티의 team은 실제 회원의 team_id이니 이 team을 바꿨을 때 바뀌게 할까? 아니면 팀 객체의 members가 멤버의 외래키인 참조를 매핑하고 있으니 여기서 멤버를 바꿔야할까? 이게 고민인 것입니다.
단방향일 때는 회원만 고려하면 되는데 양방향이 되면서 양쪽의 데이터를 어떻게 업데이트를 할 지 고려해야 하는 것입니다.
- 연관관계의 주인
그래서 둘 중 하나로 외래키를 관리하자는 룰이 나온 것이고 둘 중 하나가 주인이 되어야 합니다. 객체의 두 참조 중 하나를 주인으로 잡아야 합니다. 주인만이 외래키를 변경할 수 있고 주인이 아닌 쪽은 읽기만 가능합니다. 주인이 아니면 mappedBy 속성으로 내가 주인이 아니고 '~에 의해서 매핑됐다.'고 주인을 지정을 해야합니다.
-> 누가 주인이 좋나요?

여기는 답이 있습니다. 다측이 주인이어야합니다. 그렇게 해서 주인은 외래키를 수정, 삭제할 수 있고 team의 members는 조회만 할 수 있습니다. 주인이 아니면 조회만 가능하고 db에 외래키에 값을 업뎃하거나 넣을 때는 다측의 주인만 참조합니다.
결론적으로 외캐키가 있는 곳을 주인으로 정합니다. 테이블 개념에서는 다측이 자식인데 엔터티 개념에서는 다측이 주인입니다. 외래키가 있는 곳이 주인으로 테이블 개념은 다측에 fk가 있는데 따라서 엔터티 개념에서는 다측이 주인이 됩니다. 주인이면 진짜 매핑을 하는 것으로 진짜 매핑은 외래키의 값을 바꿀 수 있다는 것이고 1측은 가짜 매핑으로 가짜 매핑은 외래키를 조회만 할 수 있다는 것입니다.
이렇게 하여 아예 양쪽을 고려해야하는 헷갈림을 방지하는 것입니다. 다쪽에 ManyToOne을 걸고 JoinColumn을 달면 됩니다.
- 주의점 정리
실수할 만한 것을 정리합니다.
=> 주인에 값을 입력하지 않음
Member member = new Member();
member.setName("member1");
em.persist(member);
Team team = new Team();
team.setName("TeamA");
team.getMembers().add(member);
em.persist(team);현재 팀 하나, 멤버 하나가 있습니다. 팀에 멤버를 넣고 진짜 주인인 멤버에는 외래키를 넣지 않고 이름만 셋팅합니다.
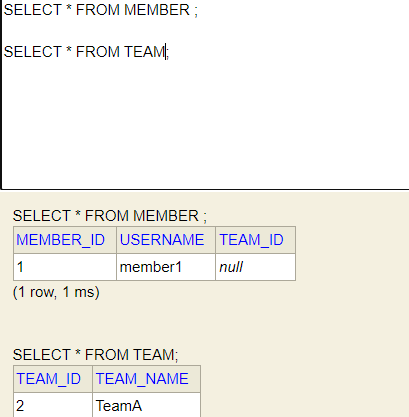
이렇게 실행해보면 insert는 2번이 나오는데 멤버의 team_id가 null입니다. 이게 아까 말한 가짜 매핑에 값을 넣어서 값이 안 들어가는데 진짜 매핑에 값을 안 넣어서 그렇습니다. jpa에서 mappedBy가 있는 곳은 변경을 할 때는 애초에 안 보는 읽기 전용입니다.
Team team = new Team();
team.setName("TeamA");
// team.getMembers().add(member);
em.persist(team);
Member member = new Member();
member.setName("member1");
member.setTeam(team);
em.persist(member);주인에 값을 넣어야 값이 들어갑니다.

둘 다 넣으면 주인의 값만 들어가서 주인에만 넣었을 때와 동일하게 동작합니다.
그래서 사실 양방향에서는 양쪽에 다 값을 넣는게 맞는 코드입니다. ✅
Team team = new Team();
team.setName("TeamA");
// team.getMembers().add(member);
em.persist(team);
Member member = new Member();
member.setName("member1");
member.setTeam(team);
em.persist(member);
em.flush();
em.clear();
Team findTeam = em.find(Team.class, team.getId());
List<Member> members = findTeam.getMembers();
for (Member m : members) {
System.out.println("m = " + m.getName());
}객체 지향적으로 생각을 하면 양쪽에 값을 넣어야 합니다. 1측에 값을 안 넣어줘도 다측에서 1측을 찾을 수는 있긴 합니다.주인에 값을 넣고 find로 팀을 가져오고 출력하면 팀의 members를 잘 찾아온 것을 볼 수 있습니다. 지연로딩이라고 하는데 jpa에서 실제 findTeam.getMembers()로 실제 데이터를 로딩했을 때

select from member가 한 번 더 나가는데 jpa에서 DB에서 find로 가져오면 db에는 멤버에 외래키가 있으니 팀과 멤버의 연결 정보를 jpa가 확인을 한 상태여서 팀의 members를 실제 사용하는 시점에 가져올 수 있습니다. 그래서 굳이 값을 team에 멤버를 안 넣어줘도 괜찮긴 합니다.
-> 문제 발생
Team team = new Team();
team.setName("TeamA");
// team.getMembers().add(member);
em.persist(team);
Member member = new Member();
member.setName("member1");
member.setTeam(team);
em.persist(member);
// em.flush();
// em.clear();
Team findTeam = em.find(Team.class, team.getId());
List<Member> members = findTeam.getMembers();
for (Member m : members) {
System.out.println("m = " + m.getName());
}이것을 완전히 플러쉬 클리어를 하면 문제가 없습니다. 플러쉬를 하면 1차 캐시를 다 비워서 두번쨰 find할 때 DB에서 가져와서 그렇습니다.
그런데 플러시를 안하고 find로 팀을 가져오면 영속성 컨텍스트의 1차 캐시에 있는 팀을 가져오는 것이고 em.persist(team)한 시점의 team의 상태 그대로를 가져오는 것입니다. 팀의 연결 정보를 jpa가 모르고 따라서 지연로딩 select가 안 나갑니다.

플러쉬도 안하고 가짜 매핑인 list에 add도 안하면 persist를 하는 insert 외에 아무값도 안 나옵니다. 영속성 컨텍스트에 setName만 한 상태의 팀을 find해서 그런 것인데 그러면 순수한 객체 그 자체라서 지연로딩이 안 일어납니다. 1차 캐시에 넣은 그 상태는 그냥 순수 객체라서 jpa도 fk를 모르고 지연 로딩이 안 일어납니다.
따라서 객체 지향 관점에서 진짜 매핑인 멤버에는 당연히 값을 세팅하고 팀에도 값을 세팅하는 게 맞습니다. ✅
또한 테스트를 할 때는 jpa를 사용 안 할 수도 있으니 둘 다 넣는게 맞고 결론은 진짜 수정은 진짜 매핑에서만 일어나지만 항상 순수 객체 상태를 고려해서 양쪽에 다 값을 세팅하는게 맞습니다.
※ 추천하는 방식
따라서 두 곳에 다 값을 넣기 위해서 연관관계 편의 메서드를 생성하는 것이 좋습니다.
// 진짜 매핑 쪽
public void changeTeam(Team team) {
this.team = team;
team.getMembers().add(this);
}
// 사용하는 곳
Team team = new Team();
team.setName("TeamA");
em.persist(team);
Member member = new Member();
member.setName("member1");
member.changeTeam(team);
em.persist(member);멤버에 setTeam을 할 때 팀의 list에도 멤버(this)를 넣는 방법이 있습니다. 그러면 멤버에 팀을 셋팅하는 시점에 팀에도 값이 들어가서 실수할 일이 없습니다. 따라서 팀에서 회원을 조회할 수 있습니다.

또한 연관관계 편의 메서드에는 이름을 set으로 하지 말고 changeTeam이라고 합니다. 연관관계를 생각할 때 가짜와 진짜에 둘 다 데이터를 넣기 위해 change를 고려하면 됩니다.
// 가짜 매핑 쪽
public void addMember(Member member) {
member.setTeam(this);
members.add(member);
}
// 사용하는 쪽
Team team = new Team();
team.setName("TeamA");
em.persist(team);
Member member = new Member();
member.setName("member1");
em.persist(member);
team.addMember(member);혹은 가짜 매핑에 데이터를 먼저 넣게 되는 경우는 addMember라고 합니다. 역시 주인은 member인데 값을 세팅하는 것은 내 맘대로 주인에서 하든 노예에서 하든 중요한 것은 둘 중에 한 곳에서 하는데 양쪽에 다 데이터를 넣는 게 좋습니다.
=> 양방향 시 무한 루프 조심하자
@Override
public String toString() {
return "Member{" +
"id=" + id +
", name='" + name + '\'' +
", team=" + team +
'}';
}toString과 롬복 라이브러리에서 문제가 됩니다. 롬복을 통해서 toString을 만들면 모든 필드를 다 사용하게 되는데
@Override
public String toString() {
return "Team{" +
"id=" + id +
", name='" + name + '\'' +
", members=" + members +
'}';
}멤버도 toString을 만들고 팀도 만들면 양쪽으로 toString을 무한 호출하게 됩니다. 따라서 양방향 연관관계에서 롬복 toString을 만드는 것을 지양해야 합니다.
- 양방향 매핑 정리
1. 단방향 매핑만으로 설계를 끝내고 양방향을 만들면 안 됩니다.
사실 단 방향 매핑으로 설계가 다 끝난 것입니다. 실무에 테이블보면 2 - 30개 나올 텐데 일단 단방향 매핑으로 설계를 완료해야 합니다.
테이블 설계에서 fk가 나올테니 다쪽에 manyToOne이나 OneToOne으로 단방향 매핑이 들어갈 텐데 이때 양방향 매핑을 하지 말아야 합니다. 처음에는 단방향 매핑으로 설계를 끝내야합니다.
2. 양방향 매핑을 언제할까?
단방향으로 설계를 끝낸 후 양방향 매핑은 반대 방향으로 조회 기능 추가가 필요할 때만 추가해야 합니다. JPQL에서 역방향 참조할 일이 많은데 단방향 매핑을 잘 하고 양방향은 필요할 때 추가하면 됩니다. 양방향은 테이블에 fk를 추가할 필요가 없다고 했는데 그러니 그냥 필요할 때 엔터티에만 추가하면 됩니다.
- 실전 예제
이전에 연관관계을 안하고 단순하게 테이블에 맞춰서 설계한 예제 1을 객체스럽게 연관관 매핑을 씌어보겠습니다.

기존과 테이블 구조는 동일하고 회원과 주문이 1대다, 주문과 아이템의 다대다를 1대다 2개로 풀어낸 매핑 테이블이 있습니다.
=> 객체 구조
객체를 참조를 사용하도록 바꿔봅니다. 다측에 무조건 단방향 연관관게를 만드는 것이 중요합니다.
1. 주문

회원과 주문을 보면 주문이 다측이니 주문에만 회원을 두고 ManyToOne과 JoinColumn(member_id)을 하면 됩니다. 이렇게 주문 테이블과 주문 엔터티를 매칭합니다.
2. 주문_아이템 매핑 테이블

이건 주문과 아이템의 동시에 다측인 매핑 테이블이니 order와 item의 참조를 둘 다 가지고 ManyToOne과 JoinColumn을 둘 다 합니다. 이렇게 다측에 참조를 두면 됩니다.
3. item
아이템 입장에서는 아무것도 안해도 됩니다. 주문 입장에서는 상품이 중요한데, 상품 입장에서는 주문을 볼 일이 잘 없습니다. 이는 설계 단계에서는 당연히 단방향만 보니 필요가 없는데 어플 개발 단계에서도 상품에서 주문을 볼 일이 잘 없다는 것입니다.
4. 회원
양방향 경우를 만들어 봅니다. 개발 단계에서 회원에 orders list가 필요하다고 가정합니다. (예제라서 가정만 하는 것이지 양방향은 필요할 때만 합니다.)

1측인 회원에 주문을 LIST로 두면 되고 관례상 new하고 OneToMany mappedBy(member)를 합니다. 하지만 상품처럼 어플리케이션 단계에서 주문에서 회원을 fk를 통해서 접근하지 회원에서 주문을 보는 일은 거의 없습니다. 항상 DB 설계할 때 배웠지만 시스템 입장에서 봐야지 사람 입장에서는 보면 안 됩니다. (사람 입장에서는 주문을 볼 수 있습니다. 하지만 시스템 입장에서 생각해야 합니다. DB 개념입니다.)
@OneToMany(mappedBy = "team")
private List<Member> members = new ArrayList<>();
public void addMember(Member member) {
member.setTeam(this);
members.add(member);
}
그리고 연관관계 편의 메서드를 노예에 만들어 보자면 add(노예)로 할 수 있을 것입니다.
'[백엔드] > [JPA | 학습기록]' 카테고리의 다른 글
| JPA PART.고급 매핑 (0) | 2023.08.20 |
|---|---|
| JPA PART.다양한 연관관계 매핑 (0) | 2023.08.17 |
| JPA PART.엔터티 매핑 (0) | 2023.08.01 |
| JPA PART.영속성 관리 (0) | 2023.06.11 |
| JPA PART.JPA 환경 구축 및 실습 (0) | 2023.06.07 |



