
개발자로 후회없는 삶 살기
[22.05.01]딥러닝 PART.순환 신경망 본문
서론
cs231n 10강 강의 내용을 정리합니다.
Stanford University CS231n: Deep Learning for Computer Vision
Course Description Computer Vision has become ubiquitous in our society, with applications in search, image understanding, apps, mapping, medicine, drones, and self-driving cars. Core to many of these applications are visual recognition tasks such as image
cs231n.stanford.edu
본론
- RNN이란?
=> 구조 및 동작방법

1. 히든 state의 재귀적인 반복
2. 출력 y를 가지려면 끝단에 FC 레이어 존재
3. 매 스탭에서 동일한 가중치 행렬 W가 사용됩니다.
4. 재귀적으로 피드백하는 것으로 h0는 초기 상태로 0으로 초기화
5. 입력 -> ht-1, xt 2개/ 출력 -> 다음 상태 ht
- 학습
-> cost함수 구하는 법

1. y는 h를 이용하여 만듭니다.
2. gradient도 동일합니다.
=> loss함수

1. 매 타임 step의 셀마다 y 값이 출력됩니다.
2. 따라서 매 step마다 loss가 생성됩니다.
3. 데이터 입력 1개를 넣으면 loss가 하나가 나오고 모든 데이터를 거치면 나온 데이터 수만큼의 loss를 평균 내어 최종 loss를 구하는데
-> 여기서는 하나의 입력을 넣었는데 여러 개의 loss가 나온 것입니다.
+ 최종 loss를 구하는 이유는 t, x, y의 W는 매 타임마다 공유되는 하나의 행렬이므로 하나의 loss로 하나의 행렬을 갱신하는 것입니다.
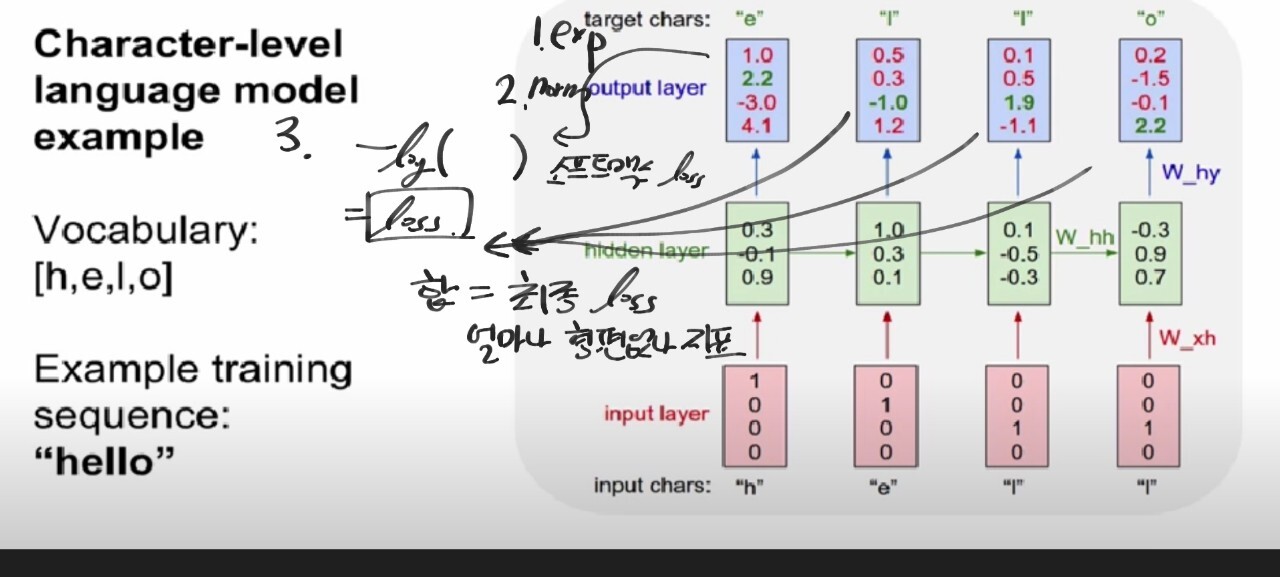
=> 최종 loss 구하기
1. 모든 타임 step마다 loss가 생성
2. softmax를 거치니 softmax cross entropy loss를 계산합니다.
3. 모든 셀의 loss를 더해서 최종 loss를 생성
4. gradient도 동일한 방식으로 최종 gradient를 구합니다.
※ 순전파 : loss를 구하는 과정/ 역전파 : gradient를 구하는 과정
- 자연어 처리
-> test data를 사용

1. 입력으로 'h'하나를 학습된 모델에 넣습니다.
2. 출력 'e'가 다음 타임 step의 입력으로 들어갑니다,
3. 따라서 'h'를 아는 'e'로 'l'의 출력을 합니다,
4. 따라서 'h'를 아는 'e'를 아는 'l'로 'l'의 출력을 합니다.
5. 학습에서는 'h' 'e' 'l' 'l'을 넣고 ht의 ht+1의 입력으로 sequence한 학습을 하고 테스트에서는 학습된 히든 state들과 이전 출력의 다음 입력으로 sequence한 예측을 할 수 있습니다.
- loss, 역전파

=> 역전파 Through time
1. 시퀀스 step마다 출력값이 존재하여 loss를 더하여 최종 loss를 구하고 gradient도 마찬가지입니다.
2. 근데 이럴 경우 seq가 긴 경우 문제가 될 소지가 있습니다. -> 법전으로 하면 학습이 느립니다.

-> batch backprop
1. train step을 100으로 자릅니다.
2. 100 step만 순전파하고 sub seq의 loss를 계산하고 gradient step을 진행합니다.
3. 순전파시 이전 batch에서 계산한 hidden state는 유지합니다. -> 다음 batch에서 순전파를 계산할 때 이전 hidden을 사용합니다.
4. 그라디언트 스탭(역전파)은 현재 batch에서만 진행됩니다.
※ 확률적 경사하강의 seq 데이터 버전입니다.
- 다이어그램
=> RNN

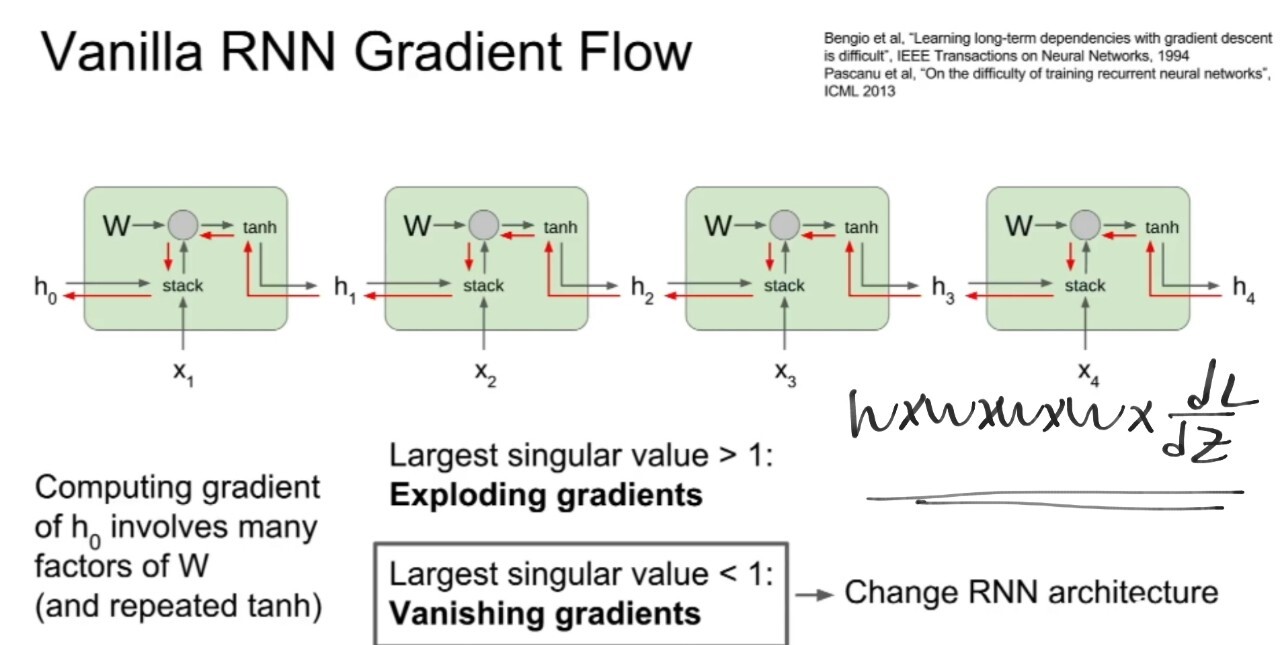
=> 문제점
★ 경사 소멸 문제
뒤에서 발생한 손실이 앞까지 도달한다면 앞으로 갈수록 값이 거의 0이 됩니다.
> 왜 도달해야 하나요?? 앞 타임에 만든 hiddem이 뒤에도 영향을 미치니 뒤에서 발생한 오차가 앞의 파라미터 갱신에도 쓰입니다.) = 가까운 노드는 오차를 받지만 먼 노드는 오차가 없어져서 경사 소실이 발생하여 갱신을 못합니다. -> 0에 가까우면 학습이 안됩니다. (가진 파라미터를 얼마나 바꾸라는 말이(지표가) 없다는 것입니다!)
∴ 결과 : 현재 벌어진 일과 앞에 벌어진 일의 연관성이 없어집니다.
=> LSTM
-> long term dependency를 해결합니다.(hidden state가 두 개로 cell state라는 게 생김) cell state는 lstm 내부에만 존재하며 밖에 노출되지 않는 변수 +hidden은 출력으로 나가서 y를 생성하고 cell이 다음 상태로 전달되는 내부 상태 정보입니다.

-> 게이트의 역할 : "너 가지 마", "못 가", "가더라도 50프로만 가" 이런 것입니다.
1. forget gate : 앞의 t-1의 c를 현재 c에 얼마나 반영할까!
2. input gate : 새로운 입력인 xt를 내부의 ct나 ht를 결정하는데 쓸 것인가 말 것인가!

3. output gate : ct가 ht를 만들 때 얼마나 영향을 미칠 것인가!

=> 다이어그램

ct-1과 ht-1, 현재 xt를 받습니다. > h, x를 쌓습니다. > 큰 W를 곱해서 게이트 처리합니다. > f 랑 ct-1 하고 , i랑 g 하고 더해서 ct를 만들고 > ct를 tanh하고 o랑 곱해서 ht 만듭니다.



역전파에서 게이트 덕분에 W가 계속 곱해지지 않고 가중치 영향 없이 gradient가 전달됩니다. + rnn은 매 step마다 tanh를 거쳤는데 얘는 첫 t에 단 한 번 tanh를 거치고 0까지 back propagation을 할 때까지 tanh를 안 거칩니다.★ 이로 인해 loss가 모델 종단부터 가장 처음까지 흘러가면서 방해를 덜 받습니다.
'[AI] > [네이버 BoostCamp | 학습기록]' 카테고리의 다른 글
| NLP PART.BERT, GPT (0) | 2022.12.09 |
|---|---|
| NLP PART.Attention 메커니즘 (0) | 2022.12.06 |
| NLP PART.RNN, Seq2Seq 구조 (0) | 2022.12.03 |
| NLP PART.텍스트 마이닝 이론 (0) | 2022.12.01 |
| NLP PART.텍스트 전처리 이론 (0) | 2022.12.01 |



