
개발자로 후회없는 삶 살기
[구현] 팀 프로젝트 추론 서버 배포 주의점 본문
🚨 서론 (문제 상황)
웹 어플리케이션 서버는 클라우드에서 JAR 파일 실행 혹은 Docker로 프로세스화하여 운영하게 됩니다. 만약, 웹 어플리케이션 외에 다른 추가적인 서버를 배포하고 이를 분산 환경에서 운영해야 한다면 어떻게 해야 할지 고민이 됩니다.
1) 서버 간 통신은 어떻게 유지할까
2) 네트워크 통신에서 시스템 에러로 인한 문제 관리법
3) 추론 서버는 단일 스레드인데, 다수의 동시 요청 처리법
위와 같은 고민 외에도 다양한 문제가 발생할 수 있을 거라고 예상됩니다.

특히 3번이 핵심 문제입니다. 스프링 서버는 개발자가 단일 스레드 상황을 고려하고 코드를 작성해도 WAS가 멀티 스레드로 동작하게 해주지만, AI 모델은 그렇지 않습니다.
1) 사용자 요청이 누락되는 문제
2) 무한정 대기로 사용자 이탈
그로 인한 부작용은 위와 같으며, 반드시 해결해야 했습니다. 이제부터 제가 해결한 방법을 작성해보겠습니다.
본론
- 추론 서버 배포 방식
현재 추론 서버는 GPU 메시지 큐를 사용하여 GPU Utilization을 높이는 방식으로 배포되어 있습니다.
https://hsb422.tistory.com/entry/ML-PARTGPU-%ED%92%80-%EA%B5%AC%ED%98%84%EA%B8%B0-2
최적화 PART.GPU 풀 구현기 2
서론 사설망에서 서버 간 통신으로 GPU 풀을 이용하는 과정을 기록합니다. 본론 -> 깃허브 https://github.com/boostcampaitech6/level2-objectdetection-cv-05/pull/20 feat: gpu pool 기능 구현 by SangBeom-Hahn · Pull Request #20
hsb422.tistory.com
웹 서버에서 3D 재구성 요청을 큐에 넣으면 가용 가능한 추론 Worker에서 추론을 수행하고 결과 PLY 파일을 클라우드 스토리지에 저장합니다. 이를 통해 큐에 있는 작업을 가져가는 시간을 최소화할 수 있고 작업이 들어온 순서대로 GPU 사용성을 극대화할 수 있습니다.
- 서버 통신 규격
웹 서버와 추론 서버 간 통신을 하기 위한 규격을 정의하였습니다. 웹 서버는 Queue에 유저 업로드 파일 경로만 적재하면 되고 Consumer인 Worker 또한 Queue와 통신하여 메시지가 있는지 체크하고 메시지에서 파일 경로를 가져와 추론을 수행합니다.
컨슈머를 실행하면 메세지가 들어올 때까지 대기하고

while문을 통해 메세지가 들어오는지 반복적으로 모니터링합니다.
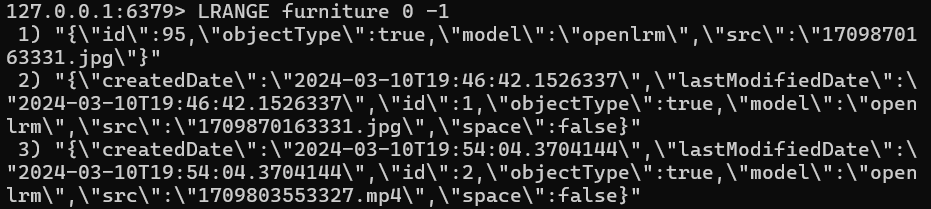
웹 서버에서 이미지나 영상을 업로드하면 레디스에 모델 규격에 맞는 메시지를 입력합니다.
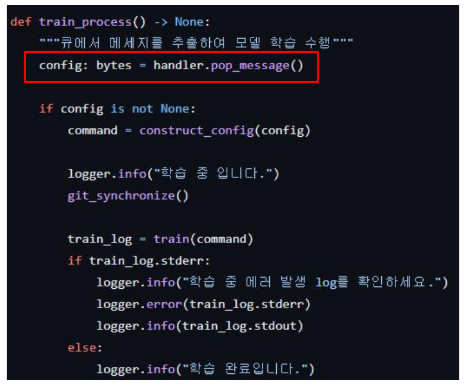
메시지가 들어오면 레디스에서 데이터를 추출하고
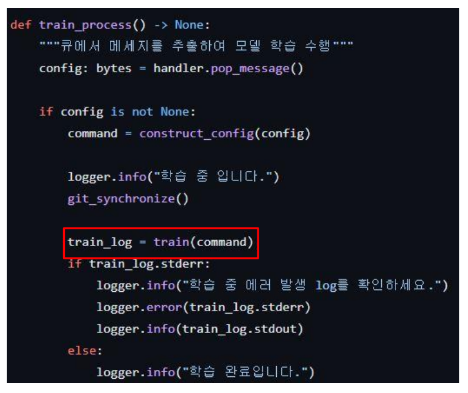
추출한 데이터를 통해 학습을 진행한 후 학습이 끝나면 ply 파일을 클라우드에 저장하고 다시 while문으로 큐를 모니터링하는 상태로 돌아갑니다.
- 이슈 사항
1. 웹 서버와 추론 서버 사이의 알림
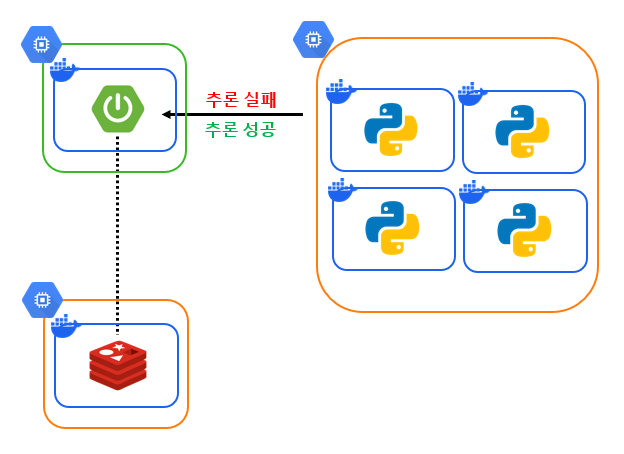
1) OOM
2) 입력 데이터 포멧 오류로 인한 학습 실패
3) 디스크 용량 부족으로 출력물 생성이 안되는 문제
학습 과정에서는 위와 같이 다양한 오류가 발생할 수 있습니다. 처음에는 추론 서버가 PLY만 생성하면 OK 사인이라고 생각했지만, 요청을 받으면 응답도 하는 것이 통상적으로 올바르다고 생각되기에 OK 사인도 따로 보내야 한다고 생각되었습니다.
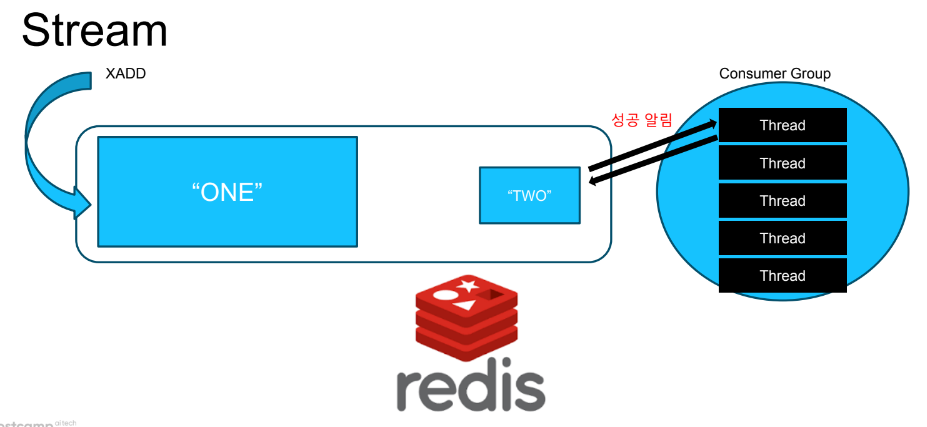
이를 레디스 stream은 기본 기능으로 제공합니다. 컨슈머가 메시지 처리를 완료하여 acknowledge 신호를 레디스에게 보내면 레디스가 메시지를 삭제합니다.
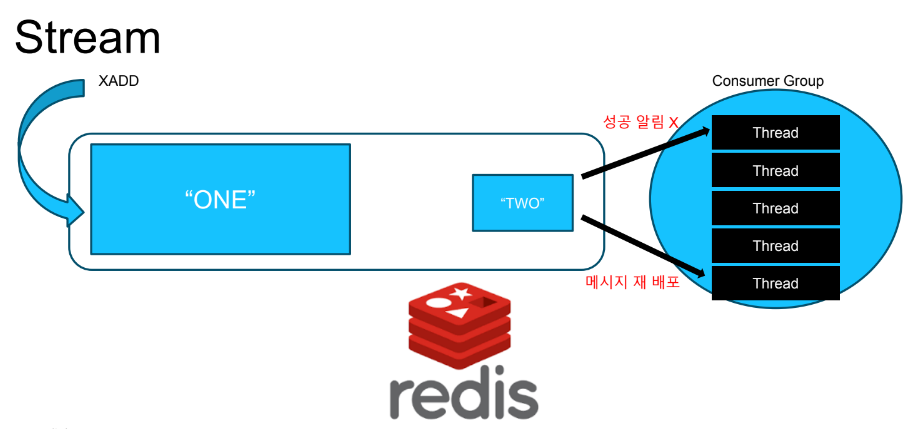
만약 일정 시간 안에 완료 메시지가 오지 않으면 처리 실패라고 인지하여 다른 컨슈머에게 메시지를 재 배포할 수 있습니다. 저는 추론 서버 환경이 stream과 맞지 않아 레디스 List를 사용하여 실패 상황에 맞는 메일 알림을 주는 것으로 이를 대체하였지만 이 또한, 메일 리소스를 유발하기 때문에 Stream을 사용하는 것이 성능을 개선할 수 있을 거라고 예상됩니다.
https://hsb422.tistory.com/entry/2
Stream을 사용한 추론 방법은 위 블로그를 참고하길 바랍니다.
2. 추론 서버 상태 체크
1) 가용 공간
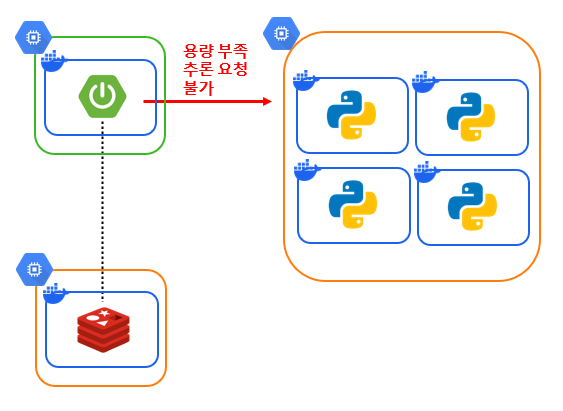
가용 공간이 부족한데 모델이 추론을 하면, 서버에 장애가 발생할 수도 있습니다. 따라서 학습 전에 추론 서버의 남은 공간을 체크하고 용량이 충분할 때만 추론하도록 하는 과정이 필요해 보입니다.
2) 네트워크 상태
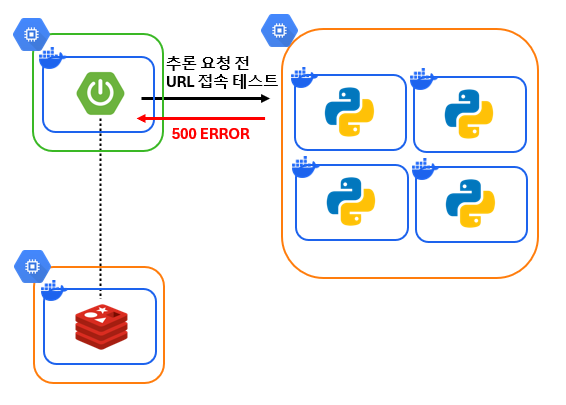
분산 환경에서는 데이터를 원격으로 주고받기 때문에 네트워크 연결 상태에 따라서 메시지가 유실될 확률이 있습니다. 따라서 추론 요청을 보내기 전에 커낵션 연결 상태를 확인하고 연결이 불가할 경우 유저에게 오류 메시지를 전달해야 합니다.
✅ 발생할 수 있는 문제
1) 웹 서버에 업로드는 성공했어도 추론에 실패했을 때 실패 알림을 주지 않아서 사용자는 무한정 대기
2) 메시지를 pop하는 것 조차 실패하여 메세지 유실
분산 환경에서 데이터를 주고받을 때 위와 같은 문제가 발생할 수 있으며 따라서 연결 테스트를 해주어야 합니다.
private void validateUrlS(final String url) {
try {
final URL dest = new URL(url);
final HttpURLConnection connection = (HttpURLConnection) dest.openConnection();
connection.setUseCaches(false);
connection.setConnectTimeout(1000);
connection.setReadTimeout(1000);
if (canNotConnect(connection.getResponseCode())) {
throw new HealthCheckException();
}
} catch (IOException e) {
throw new HealthCheckException();
}
}예를 들어 원격 서버 간에 현재 접속 가능한 상태인지 테스트한다면 위와 같은 문제를 막을 수 있으며, 저는 HttpURLConnection 추상 클래스를 사용하여 200 OK인 경우에만 추론 요청을 보낼 수 있도록 했습니다.
결론
실시간 스트림 방식의 추론 서버를 운영한 경험담을 작성해 보았습니다. 실서비스에서 고려할 점이 굉장히 많음을 깨달았고 분산 추론 서버를 다뤄보는 값 진 내용이었습니다.
'[대외활동] > [네이버 BoostCamp]' 카테고리의 다른 글
| [운영] 유저 트랜잭션 분석을 위한 로깅 전략 (0) | 2024.04.04 |
|---|---|
| [최적화] 팀 프로젝트 대용량 파일 업로드 속도 및 리소스 최적화 (0) | 2024.02.10 |
| [설계] 팀 프로젝트 9, 10주차(가구 모델 리서치, 슈가 뷰어, UXR 모델 확정) (0) | 2024.02.08 |
| [설계] 팀 프로젝트 8주차(모델 세미나, 평가 지표) (0) | 2024.01.29 |
| [설계] 팀 프로젝트 6, 7주차(프로젝트 진행 방식, 주제 구체화, 타당성 분석) (0) | 2024.01.12 |



