
개발자로 후회없는 삶 살기
[최적화] 팀 프로젝트 대용량 파일 업로드 속도 및 리소스 최적화 본문
🚨 서론 (문제 상황)
저희 서비스는 영상 (mp4), 이미지 (png, jpg, jpeg, heic) 업로드로 사용자 요청을 최초로 받습니다. 보통 서비스에서 CRUD 중 R의 빈도가 가장 높은데 저희는 그만큼 업로드의 비중이 상당히 높았습니다.
1) 최소 4GB의 데이터를 업로드 하는 과정에서 디스크 IO, 메모리 IO, 네트워크 IO가 빈번하게 발생
2) 대용량 데이터를 업로드 시간이 최대 4분까지 소요
그 이유는 위와 같으며, 이를 해결한 방법을 작성합니다.
-> 전체 코드
https://github.com/bcatcv5/zzimkong-backend/pull/9
feat: file upload 기능 구현 by SangBeom-Hahn · Pull Request #9 · bcatcv5/zzimkong-backend
Overview 동영상(mp4, mov), 이미지(jpg, jpeg, png) 업로드 기능 및 테스트를 구현 동영상 업로드 최적화 Change log FileUploadApiController FileExtension RawFileData FileService FileConverter GCPFileUploader UuidHolder utils/v...
github.com
본론
- 기본 업로드 방식
private String sendFileToStorage(final RawFileData fileData) {
try (final InputStream inputStream = fileData.getContent()) {
String fileName = fileData.getStoreFileName();
BlobInfo blobInfo = BlobInfo.newBuilder(bucket, fileName)
.setContentType(fileData.getContentType())
.build();
return storage.create(blobInfo, inputStream)
.getMediaLink();
} catch (IOException e) {
throw new RuntimeException("파일 업로드에 실패했습니다.");
}
}mp4 단일 파일 전체를 업로드하는 방식입니다. 위는 Google Cloud Storage에 파일 업로드를 담당하는 sendFileToStorage() 코드입니다. 동영상 파일 하나를 storage에 업로드하고, 업로드에 성공한 파일의 storage 경로를 반환합니다.

890MB 동영상을 업로드하는데 최대 4m 16s가 소요되었고
평균 126초가 소요되었습니다. 로컬 pc에서 클라우드로 업로드 할 때 걸리는 시간이 다른 이유는 다양한데, 네트워크 상태(대역폭 등)와 로컬 컴퓨터의 CPU 사용량, 메모리 사용량 때문입니다.
✅ 방안1, 하나의 파일을 청크로 나눈 업로드 방식
대용량 단일 파일을 한번에 업로드하는 것은 패킷 누락에 대한 Retransmission과 위험 부담이 클 거라고 생각되어 적절한 청크 사이즈를 찾고 분할해서 업로드해보기로 했습니다.
https://patents.google.com/patent/KR20020053316A/ko
KR20020053316A - 대용량 데이터 전송을 위한 패킷전송방법 - Google Patents
제 1 항에 있어서, 상기 패킷정보는 수신단에서 분할 전송된 다수개의 패킷을 메시지로 조합시 원(元)데이터로 완성할 수 있도록 패킷의 순서정보를 포함하는 것을 특징으로 하는 대용량 데이터
patents.google.com
위, 조사 내용에 따르면
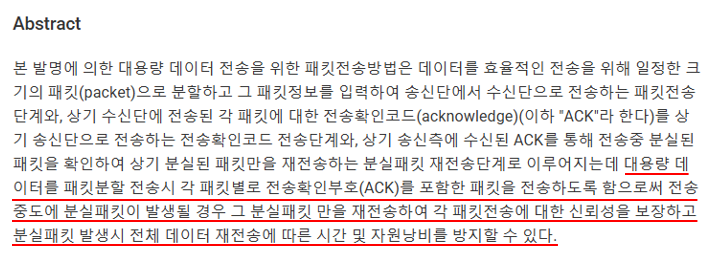
대용량 데이터를 효율적으로 전송하기 위해서 일정 크기의 패킷으로 분할하며, 이를 안전하게 관리했을 경우 시간과 리소스를 방지할 수 있다는 점을 고려했습니다.
try (final InputStream inputStream = fileData.getContent()) {
// 사전 준비
final String fileName = fileData.getStoreFileName();
final int CHUNK_SIZE = 1024 * 1024 * 400;
final BlobInfo blobInfo = BlobInfo.newBuilder(bucket, fileName)
.setContentType(fileData.getContentType())
.build();
final byte[] fileBytes = inputStream.readAllBytes();
final int numChunks = (int) Math.ceil((double) fileBytes.length / CHUNK_SIZE);
// 패킷을 청크 분할
try (final WriteChannel writer = storage.writer(blobInfo)) {
for (int i = 0; i < numChunks; i++) {
final long start2 = System.currentTimeMillis();
final int start = i * CHUNK_SIZE;
final int end = Math.min(start + CHUNK_SIZE, fileBytes.length);
final byte[] chunkBytes = new byte[end - start];
System.arraycopy(fileBytes, start, chunkBytes, 0, end - start);
// 구글 스토리지 청크 단위 업로드
writer.write(ByteBuffer.wrap(chunkBytes));
log.info("File Upload 완료");
log.info("{} 초 소요됨", (System.currentTimeMillis() - start2) / 1000);
}
}
return String.format("%s/%s/%s", "https://storage.googleapis.com", bucket, fileName);
}try 문에서 input stream을 가져와 byte 청크 단위로 쪼개고 writer로 gcs에 업로드하는 코드입니다. 적절한 청크 사이즈를 찾기 위해 여러 시도를 해보았습니다.
-> 청크 사이즈 1MB
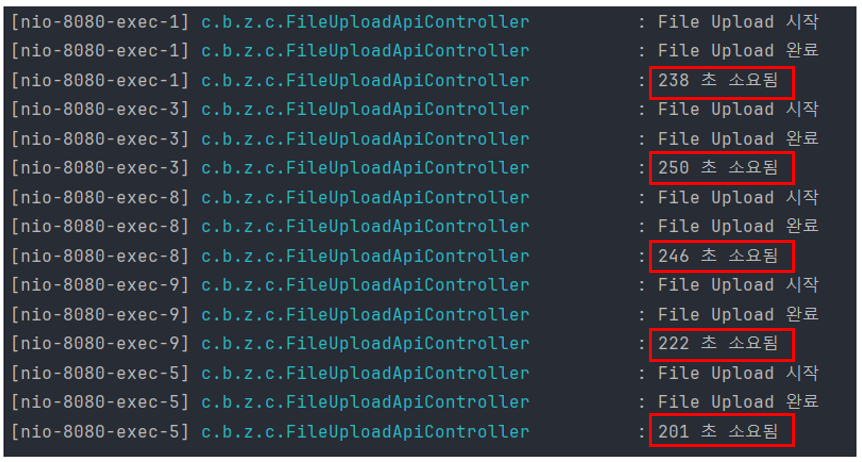
1MB 단위로 나누었을 땐 오히려 평균 227초가 소요되었습니다. 청크 단위로 분할 하더라도 순차적으로 업로드하는 것이기 때문에 시간 단축은 없을 거라 예상했습니다.
🚨 더 오래 걸린 이유는?
기본 업로드 방식은 네트워크 I/O가 패킷 개수만큼 만 발생하는데 반해, 파일을 나눌 경우 하나의 패킷을 나눈 청크 개수만큼 네트워크 IO가 일어나서 더 오래 걸리는 것으로 판단 할 수 있었습니다.
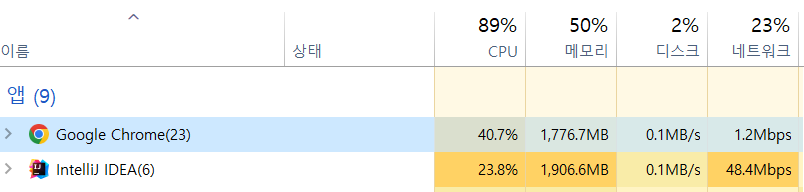
실제로 네트워크 I/O가 더 많이 일어나나 보겠습니다. 청크 단위로 나누지 않은 기본 업로드는 네트워크를 23% 잡지만
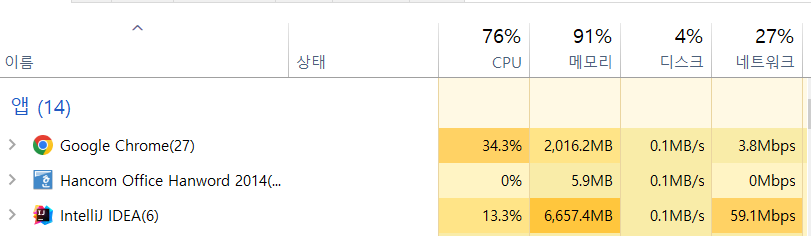
청크 단위로 쪼갠 것이 27%로 확실히 더 많이 먹는 모습이 보입니다. 앞으로 다양한 청크 사이즈로 테스트를 해보겠습니다.
-> 청크 사이즈 100MB
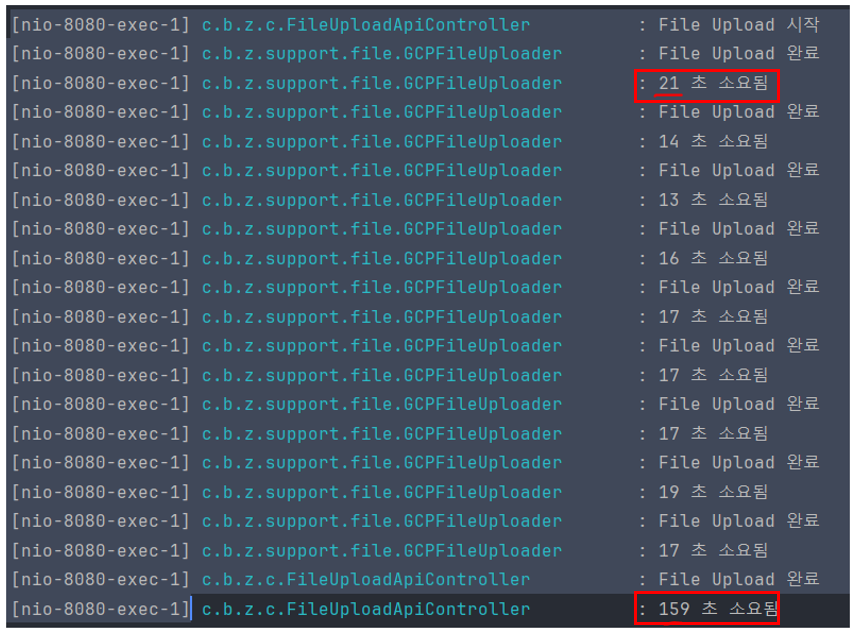
100MB로 쪼갠 경우 역시 더 오래 걸리는 경우도 있고, 아닌 경우도 있었습니다.
-> 청크 사이즈 200MB
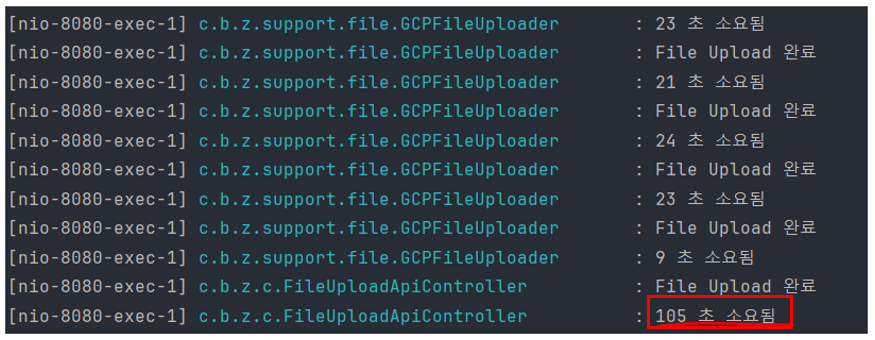
가장 빠른 건 200MB로 쪼갠 것으로 기본 파일 업로드보다 10초 정도 개선되었습니다.
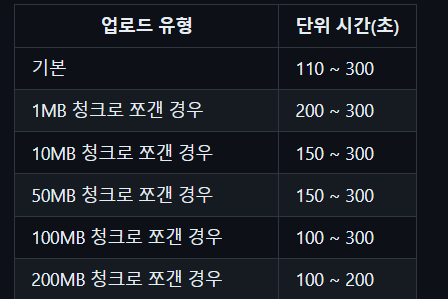
🚨 왜 빨라진 거지?
순차적으로 업로드하는 것이기 때문에 시간이 단축될 것이라는 기대는 못했는데, 200MB 청크 사이즈가 기본 파일 업로드보다 더 빠른 속도를 보였습니다. 제가 생각하는 이유를 나열해 보겠습니다.
1) 서버 측 처리 속도
GPT의 대답 : 서버 측에서도 파일을 한 번에 처리하는 것보다 작은 청크 단위로 처리하는 것이 더 빠를 수 있습니다. 서버는 동시에 많은 양의 데이터를 처리하는 것보다 작은 양의 데이터를 빠르게 처리하는 데 더 효율적일 수 있습니다. GPT의 말에는 신뢰성이 부족했습니다.
2) 네트워크 I/O
네트워크 연결 품질이 불안정하거나 대역폭이 낮은 경우 한 번에 보낼 수 있는 데이터 단위가 작기 때문에 작은 단위로 보내는 게 더 빨리질 수 있습니다. 즉 네트워크 I/O로 인한 속도가 빨라진 거라고 생각할 수 있습니다.
3) 네트워크 단편화
단편화 : 패킷을 MTU 크기로 자르는 것
MTU : 인터넷상에서 전달할 수 있는 패킷의 최대 크기
이더넷 환경에서 기본 MTU: 1500byte
기본 L4 헤더 : 20byte
기본 L3 헤더 : 20byte
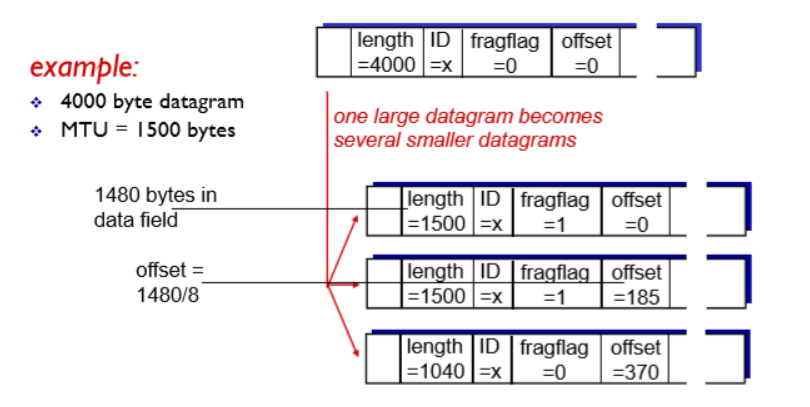
동영상과 영상 구분 없이 어떤 데이터를 흘려보내면 캡슐화, 역캡슐화를 통해 데이터를 받아들입니다. 데이터 스트림을 MSS 기반으로 자르고 각각 자른 세그먼트들을 인터넷상으로 전달하게 되는데, 각 네트워크는 MTU라는 최대 패킷 전송 단위를 가지고 있어서 MTU보다 큰 데이터는 단편화라는 과정이 이루어지고 이 과정 자체가 네트워크 적인 오버헤드를 유발할 수 있습니다.
위 사진처럼 기본 헤더를 제외한 1460byte의 MTU에서 발생하는 단편화 오버헤드를 제거하여 속도 개선이 있을 수 있다고 예상할 수 있습니다.
- 방안 2, data prefetch 업로드 방식
방안 1은 아직 순차적으로 업로드 하기 때문에 유의미한 속도 개선이 있지는 않았습니다.
✅ 병렬로 업로드 한다면?
만약, 모든 청크를 병렬로 업로드하고 스토리지에서 재조합 한다면 눈에 띄는 개선이 있을 거라고 예상됩니다. 하지만, 순서가 유지되어야 하는 동영상 특성에 따라 병렬로 업로드를 했을 경우 파일이 손상되었습니다. 따라서 메모리에는 병렬로 로드하고 스토리지에는 순차적으로 업로드하는 아이디어를 떠오렸습니다.

이는 데이터를 미리 로드하는 방식으로 청크 단위로 로드할 때 메모리 로드와 스토리지 업로드가 반복되는데
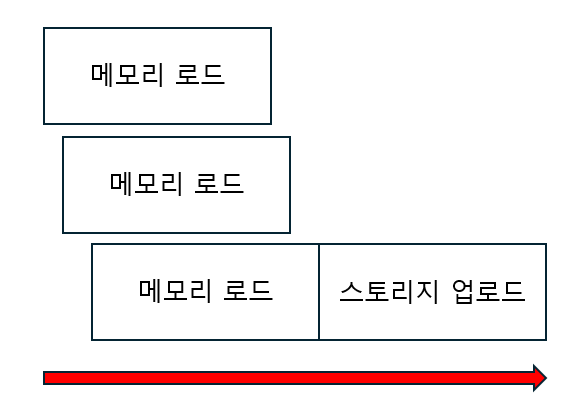
메모리에 로드하는 것을 미리 하여 스토리지 업로드는 막힘없이 진행될 수 있어 속도가 빨라질 거란 기대를 했습니다.
try (final InputStream inputStream = fileData.getContent()) {
// 사전 준비
final int CHUNK_SIZE = 1024 * 1024 * 200;
final String fileName = fileData.getStoreFileName();
final byte[] fileBytes = inputStream.readAllBytes();
final int numChunks = (int) Math.ceil((double) fileBytes.length / CHUNK_SIZE);
final List<CompletableFuture<byte[]>> futures = new ArrayList<>();
// 메모리 업로드
for (int i = 0; i < numChunks; i++) {
final int start = i * CHUNK_SIZE;
final int end = Math.min(start + CHUNK_SIZE, fileBytes.length);
futures.add(CompletableFuture.supplyAsync(() -> {
log.info("청크 단위 메모리 업로드 중");
final byte[] chunkBytes = new byte[end - start];
System.arraycopy(fileBytes, start, chunkBytes, 0, end - start);
return chunkBytes;
}));
}
CompletableFuture.allOf(futures.toArray(new CompletableFuture[0])).join();
// 스토리지 업로드
BlobInfo blobInfo = BlobInfo.newBuilder(bucket, fileName)
.setContentType(fileData.getContentType())
.build();
try (final WriteChannel writer = storage.writer(blobInfo)) {
for (CompletableFuture<byte[]> future : futures) {
final long start2 = System.currentTimeMillis();
writer.write(ByteBuffer.wrap(future.join()));
log.info("중간 File Upload 완료");
log.info("{} 초 소요됨", (System.currentTimeMillis() - start2) / 1000);
}
}
return String.format("%s/%s/%s", "https://storage.googleapis.com", bucket, fileName);
}첫 번째 for문에서 CompletableFuture를 사용하여 메모리 로드가 병렬적으로 일어나고 메모리 로드가 끝난 시점부터 두 번째 for문에서 순차적으로 스토리지 업로드를 수행합니다.
-> 청크 사이즈 100MB
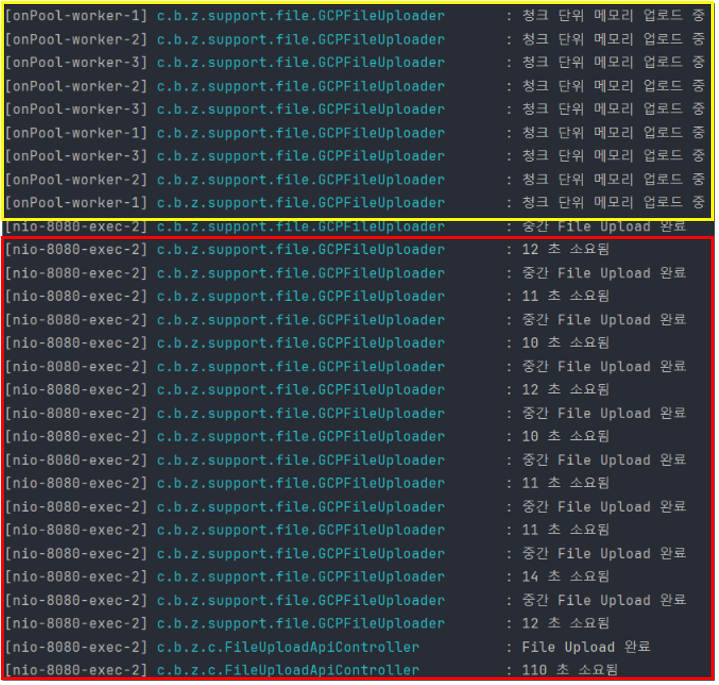
메모리 로드는 멀티 쓰레드로 Non Blocking으로 수행하고 storage 업로드는 순차적으로 일어납니다. 청크로 나누기만 했을 때보다 평균 청크 업로드 속도가 7초 정도 빨라졌습니다.
-> 청크 사이즈 200MB
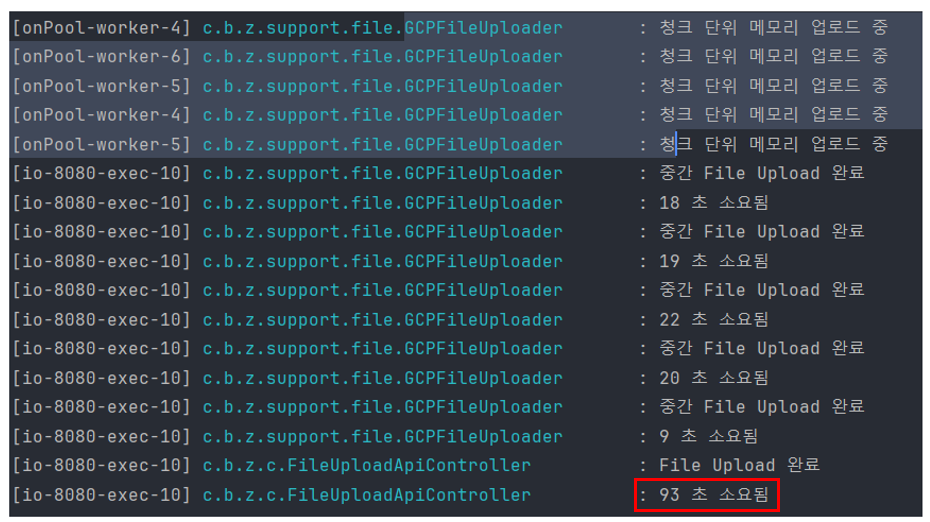
결과적으로 청크 사이즈만 쪼갰을 때 가장 빨랐던 200MB 청크에서 병렬 로드를 추가했을 때 가장 많은 업로드 시간 단축을 이뤘습니다.
✅ 빨라진 이유
네이버 부스트캠프 강천성 멘토님 : 파일 순서대로 메모리에 로드하고 업로드하는 것보다 파일을 업로드하는 동안 다른 파일을 미리 읽고 있으니 바로 network I/O를 탈 수 있어서 차이가 생기는 것 같습니다. data loader의 num worker가 동일한 원리로 gpu batch를 학습하는 동안 cpu는 미리 데이터를 읽어서 끝나자마자 다음 batch로 밀어 넣어주는 것입니다.
- 이외에 파일 업로드에서 고려한 것
1) 트랜잭션 묶음 : 어플리케이션 로직이 network I/O가 발생하는 로직과 하나의 트랜잭션에 묶여버리면 응답 시간이 너무 오래 걸려서 시스템 성능이 저하되고 부정적인 사용자 경험을 유발합니다. 이를 예방하기 위해 컨트롤러에서 별도의 업로더하고 비동기적으로 동작하게 합니다.
2) 병렬 쓰레드 : 보통 하나의 트랜잭션에서는 하나의 쓰레드를 사용하지만, 업로드 영상을 병렬적으로 메모리에 올리기 위해 별도의 트랜잭션에서 쓰레드 개수에 유의하며 병렬적으로 처리하도록 하였습니다.
결론
대용량 데이터를 업로드 할 때 발생하는 리소스를 최소화 하기 위해서 청크 분할과 병렬 메모리 로드를 사용하여 업로드 속도를 기존에 비해 30% 단축시킬 수 있음을 경험을 확인했습니다. 대용량 데이터 업로드는 보통 비동기 + Non Blocking 방식으로 레이턴시를 줄이는데, 그 외에도 최적화를 통해 서버의 성능에 영향을 최소화할 수 있는 방법을 배울 수 있었습니다.
'[대외활동] > [네이버 BoostCamp]' 카테고리의 다른 글
| [운영] 유저 트랜잭션 분석을 위한 로깅 전략 (0) | 2024.04.04 |
|---|---|
| [구현] 팀 프로젝트 추론 서버 배포 주의점 (0) | 2024.02.19 |
| [설계] 팀 프로젝트 9, 10주차(가구 모델 리서치, 슈가 뷰어, UXR 모델 확정) (0) | 2024.02.08 |
| [설계] 팀 프로젝트 8주차(모델 세미나, 평가 지표) (0) | 2024.01.29 |
| [설계] 팀 프로젝트 6, 7주차(프로젝트 진행 방식, 주제 구체화, 타당성 분석) (0) | 2024.01.12 |



