
개발자로 후회없는 삶 살기
[최적화] Redis Stream 내부 ObjectHashMapper를 이용하여 HASH 역직렬화 자동화하기 본문
[최적화] Redis Stream 내부 ObjectHashMapper를 이용하여 HASH 역직렬화 자동화하기
몽이장쥰 2024. 11. 24. 22:01🚨 서론 (문제상황)
@Bean
public RedisTemplate<String, AccessTokenSaveResponseDto> redisTemplate(
RedisConnectionFactory redisConnectionFactory,
ObjectMapper objectMapper
) {
Jackson2JsonRedisSerializer<AccessTokenSaveResponseDto> jsonRedisSerializer =
new Jackson2JsonRedisSerializer<>(AccessTokenSaveResponseDto.class);
jsonRedisSerializer.setObjectMapper(objectMapper); // 여기 ✅Redis의 Serializer는 내부적으로 ObjectMapper를 사용하여, 객체 ↔ JSON 직렬화, 역직렬화를 수행한다.
@Async
public void sendModelMessage(MessageResponseDto message) {
try {
ObjectRecord<String, String> record = StreamRecords.newRecord()
.in(CLOTHES.toString())
.ofObject(objectMapper.writeValueAsString(message)) // 여기
.withId(RecordId.autoGenerate());
streamRedisTemplate.opsForStream()
.add(record);
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
}필자의 경우 AI 추론 파이프라인을 만들기 위해 Redis Stream을 사용하였고, 내부적으로 Hash 자료구조인 것을 몰라, JSON으로 변환하여 데이터를 주고 받았었다. StringRedisSerializer는 자체적으로 직렬화하는 기능이 없어서, 외부에서 직렬화를 해서 입력해주어야 하기 때문인데, ObjectMapper가 큰 오버헤드가 있는 것은 아니지만, 다음과 같은 문제가 있다.
1) String 직렬화 방식은 단순한 데이터에 적합한데, 이는 추후 데이터의 형태가 복잡해지고, 다양해지면 적용하는 것이 옳지 않음
2) Redis Stream의 Hash 자료구조의 ObjectHashMapper를 사용하면 최적화 가능
따라서, 이때 사용되는 ObjectMapper란 무엇인지 알아보고, 데이터 역/직렬화 구조를 개선해보고자 한다.
본론
- Jackson이란?
객체 -> JSON : 직렬화
JSON -> 객체 : 역직렬화
자바 객체와 JSON 간의 변화를 직렬화라고 부른다. JAVA 내 보편적으로 많이 사용되는 JSON 라이브러리가 Jackson이며, 그 동작 방식과 사용 방법에 대해서 알아보자.
-> Object Mapper를 이용한 직렬화, 역직렬화
implementation 'com.fasterxml.jackson.core:jackson-databind:2.15.3'
Jackson은 위 의존성으로 사용할 수 있으며,
1) POJO를 JSON으로 읽고 쓰고 변환
2) 사용자 직렬화, 역직렬화 커스텀 기능
위 기능을 제공한다.
public class ObjectMapper
extends ObjectCodec
implements Versioned,
java.io.Serializable // as of 2.1
{ObjectMapper는 Databind 모듈에 위치한 클래스로, POJO(순수 자바 객체) 또는 JSON 트리 모델을 JSON으로 읽고 쓰고 변환하는 기능을 제공한다.
-> 객체 to JSON
1) writeValue
2) writeValueAsString
3) writeValueAsBytes
ObjectMapper를 활용한 객체에서 JSON으로 직렬화하는 메서드는 3가지가 있다.
1) writeValue
@Test
@DisplayName("")
void MessageTest() throws IOException {
ObjectMapper objectMapper = new ObjectMapper();
Message message = new Message(ObjectType.T_SHIRTS, "store", false);
objectMapper.writeValue(new FileOutputStream("message.json"), message);
}writeValue를 통해서 객체를 File, OutputStream 등 다양한 방식으로 직렬화 할 수 있다.
2) writeValueAsString
@Async
public void sendModelMessage(MessageResponseDto message) {
try {
ObjectRecord<String, String> record = StreamRecords.newRecord()
.in(CLOTHES.toString())
.ofObject(objectMapper.writeValueAsString(message))
.withId(RecordId.autoGenerate());
streamRedisTemplate.opsForStream()
.add(record);
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
}API 서버에서는 이 방식을 가장 많이 사용한다. Redis Stream에 이 메서드를 사용하여 데이터를 저장하면

객체가 JSON 형태로 변환되고 문자열 타입으로 Redis에 저장된다.
-> JSON to 객체
String json = "{\"id\":2,\"objectType\":\"T_SHIRTS\",\"storeFilePath\":\"storeFilePath\",\"refine\":true}";
Message message1 = objectMapper.readValue(json, Message.class);JSON을 객체로 변환하는 메서드는 readValue가 있다. 저장된 JSON 문자열을 그대로 String 타입으로 초기화하고 String 값과 클래스 타입을 명시하면 로드하여 객체로 불러와 바로 사용할 수 있다.
- Redis Hash

이제부턴 Redis에서 객체를 Hash 형태로 저장하는 방법을 알아보고, Hash 데이터 ↔ 자바 Object간 역/직렬화를 알아보자. Spring 공식 문서에 따르면 객체를 Hash 형태로 저장하면 보다 정교하게 객체를 저장할 수 있다고 한다. 레디스 Hash는 필드-값 페어들의 컬랙션이다. 레디스에서는 이를 Record 타입이라고 한다.
✅ 필드-값인건 알겠는데 왜 Record일까?
Redis hash는 필드-값 여러개를 문자열로 관리하고 이는 자바의 HashMap과 유사하고 필드와 값 모두 문자열로 관리한다.

위 내용을 예제로 알아보자, player:42라는 객체의 name 필드의 값이 jinwoo / level 필드의 값이 10으로 저장된다. player:42라는 키에 5가지 필드와 값이 페어로 저장된 것을 나타낸다.
-> 스프링 Hash Mappers
스프링에서는 객체를 Redis Hash 구조로 저장하고 불러올 수 있다. 객체를 JSON으로 변환하는 ObjectMapper처럼 HashMapper는 객체를 해시 데이터로 변환하고 불러온다.
public class Person {
String firstname;
String lastname;
// …
}
public class HashMapping {
@Resource(name = "redisTemplate")
HashOperations<String, byte[], byte[]> hashOperations;
HashMapper<Object, byte[], byte[]> mapper = new ObjectHashMapper();
public void writeHash(String key, Person person) {
Map<byte[], byte[]> mappedHash = mapper.toHash(person);
hashOperations.putAll(key, mappedHash);
}
public Person loadHash(String key) {
Map<byte[], byte[]> loadedHash = hashOperations.entries(key);
return (Person) mapper.fromHash(loadedHash);
}
}HashMapper 내부 구현 코드를 보면 key를 문자열로 받고, Map을 데이터로 넣는 것을 볼 수 있다. 이것을 위 예제로 접목시키면 player:42 키에 5가지 필드 데이터를 Map에 필드-벨류 페어로 저장하는 것으로 볼 수 있다. Hash는 키-벨류를 문자열로 저장한다고 했지만, Redis는 바이트 스트림 로우 데이터를 저장하므로 byte[]로 나타낸 모습이다.
-> Jackson2HashMapper
스프링에서 제공하는 HashMapper 종류를 알아보자. Jackson2HashMapper는 해시의 필드 값을 JSON 형태로 저장하는 Mapper이다. 단순 primitive 타입은 단순 값이 매핑되고 복합 유형(객체, 컬랙션, Map)등은 중첩 JSON으로 표시된다.

JSON을 객체로 바로 변화하는 ObjectMapper처럼 만약 Redis Hash에 JSON 형태로 저장이 되어있다면 내부적으로 ObjectMapper를 사용하여, 바로 변환하여 사용할 수 있다.
1) Normal Mapping(flatten 인자 false)

참조 객체가 JSON 형태로 저장된다.
2) Flat Mapping(flatten 인자 true)

모든 필드가 객체 그래프로 최상단으로 저장된다.
-> ObjectHashMapper


해시에 JSON 형태가 아닌, 위와 같은 형태일 땐, ObjectHashMapper를 사용하여 객체와 해시 데이터간 변환을 한다.

이는 인자로, RedisConverter가 필요하다. 기본으로 구현된 Converter는 Redis byte[]에서 속성 값을 매핑하고 가져온다.
1) _class = org.example.Person : 객체 클래스 정보
2) firstname = rand : 단순 변수
3) address.city = emond's field : 복합 변수
✅ Redis Stream Object Hash 데이터 역/직렬화 자동화
이제 앞서 배운 내용을 토대로 Redis Stream을 통한 데이터 역/직렬화를 자동화한다.
-> Redis Stream의 Hash 직렬화

공식문서에 따르면 Redis Stream은 RedisTemplate에 4개 중 3개의 직렬화를 해야한다.
@Bean
public RedisTemplate<String, Object> streamRedisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(redisConnectionFactory);
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(new StringRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setHashValueSerializer(new StringRedisSerializer());
return redisTemplate;
}그래서 필자는 (Key, HashKey, HashValue)에 문자열 직렬화를 적용했다. 아래 포스트에서 ValueSerializer에 어떠한(JDK, String, Jackson) 직렬화 방식을 적용해도 동일한 직렬화가 진행됐었는데 애초에 3가지 직렬화만 적용하면 된다고 나와있다.
[최적화] Redis Stream에 적절한 RedisSerializer를 사용하자
🚨 서론 (문제 상황)Redis는 단순 데이터 저장뿐만 아니라, 캐싱, 메세지 콜백 등 다양한 기능으로 활용도가 매우 높다. 그 중 정밀한 이벤트 핸들러를 제공하는 Redis Stream을 사용하고자 했고, 일
hsb422.tistory.com
이 내용은 이 포스트를 참고하자.
-> Hash 역직렬화
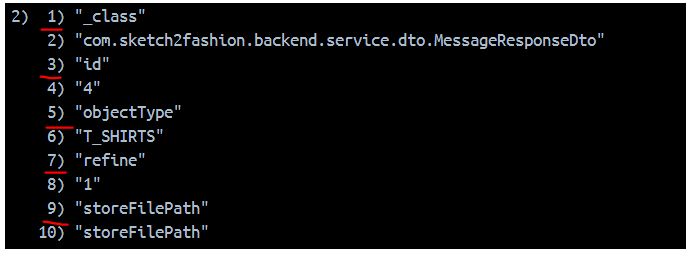
위 직렬화 설정을 통해서 데이터를 레디스에 저장하면, 이처럼 저장된다. 이는 위에서 player:42가 저장된 방식과 동일하다. 그렇다면 Hash 형태로 잘 저장이 된 것이니, 역직렬화도 가능할 것이다.

Stream은 기본적으로 ObjectHashMapper를 사용한다고 한다. 즉, ObjectHashMapper를 사용하여 역/직렬화를 수행하며, 이를 위해 RedisConverter를 구현해줘야 한다.
@Bean
RedisMappingContext redisMappingContext() {
RedisMappingContext ctx = new RedisMappingContext();
ctx.setInitialEntitySet(Collections.singleton(MessageResponseDto.class));
return ctx;
}
@Bean
RedisConverter redisConverter(@Qualifier("redisMappingContext") RedisMappingContext mappingContext) {
return new MappingRedisConverter(mappingContext);
}
@Bean
ObjectHashMapper hashMapper(RedisConverter converter) {
return new ObjectHashMapper(converter);
}위 처럼 Convert를 구현하여 역직렬화할 데이터 타입을 명시하고
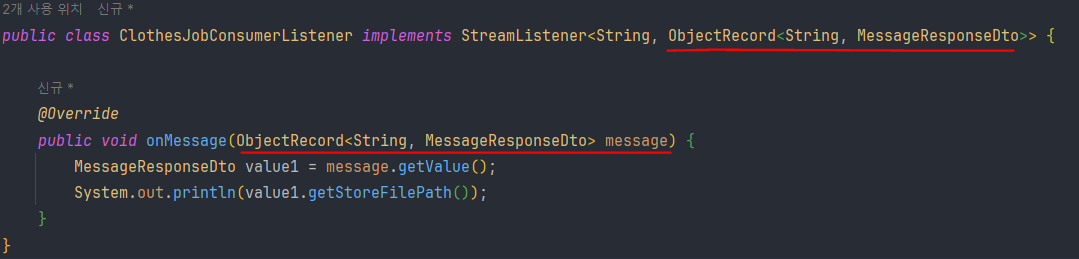
리스너 컨테이너에서 메세지가 도착했을 때 자동 실행하는 메세지 콜백 기능을 활용하여 메세지를 출력해보면,

별도의 파싱 없이, 해시 데이터를 객체로 정확히 역직렬화하는 것을 확인할 수 있다.
✅ 정리
1. 직렬화 방법
@Async
public void sendModelMessage(MessageResponseDto message) {
try {
ObjectRecord<String, String> record = StreamRecords.newRecord()
.in(CLOTHES.toString())
.ofObject(objectMapper.writeValueAsString(message))
.withId(RecordId.autoGenerate());
streamRedisTemplate.opsForStream()
.add(record);
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
}직렬화 방법이 자바 시스템에 최적화 되어있다. 과거에 JSON 형태로 저장할 땐, ObjectMapper를 별도로 사용하여 JSON으로 변환했지만
@Async
public void sendModelMessage(MessageResponseDto message) {
ObjectRecord<String, MessageResponseDto> record = StreamRecords.newRecord()
.in(CLOTHES.toString())
.ofObject(message)
.withId(RecordId.autoGenerate());
streamRedisTemplate.opsForStream()
.add(record);
}현재는 객체만 넣으면 내부에서 ObjectHashMapper를 사용하여 자동 직렬화를 한다.
2. 역직렬화 방법
@Override
public void onMessage(final ObjectRecord<String, String> message) {
String modelMessage = message.getValue();
MessageResponseDto messageResponseDto = objectMapper.readValue(extractJson(modelMessage), MessageResponseDto.class);과거엔 JSON을 String으로 꺼내서 별도의 파싱 이후, readValue를 메서드를 또 사용했지만
@Override
public void onMessage(ObjectRecord<String, MessageResponseDto> message) {
MessageResponseDto value1 = message.getValue();
System.out.println(value1.getStoreFilePath());
}현재는 자동으로 Object를 로드한다.
3. 저장되는 데이터
과거에는 해시의 벨류에 JSON이 들어갔다면
현재는 해시의 특성에 맞게 필드-값이 들어가서 데이터 저장에 최적화 되어있다.
참고
https://docs.spring.io/spring-data/redis/reference/redis/redis-streams.html
'[백엔드] > [spring+JPA | 이슈해결]' 카테고리의 다른 글
| [최적화] Cache 도입을 위한 데이터 접근 방식 문제점 분석하기 (0) | 2024.12.01 |
|---|---|
| [최적화] Redis Stream에 적절한 RedisSerializer를 사용하자 (2) | 2024.11.23 |
| [최적화] Spring 환경 AI 서비스 실시간 스트림 파이프라인 구축 (with Redis Stream) (0) | 2024.11.11 |
| 자바 PART.무한의 값 처리 BigDecimal (0) | 2023.11.27 |
| spring PART.postman으로 login 테스트 할 때 받아온 토큰을 요청 헤더에 자동으로 넣는 방법 (0) | 2023.08.18 |



