
개발자로 후회없는 삶 살기
[최적화] Redis Stream에 적절한 RedisSerializer를 사용하자 본문
🚨 서론 (문제 상황)
Redis는 단순 데이터 저장뿐만 아니라, 캐싱, 메세지 콜백 등 다양한 기능으로 활용도가 매우 높다. 그 중 정밀한 이벤트 핸들러를 제공하는 Redis Stream을 사용하고자 했고, 일반 (키-벨류, 해시맵) 형태가 아닌 특수한 자료구조라서, 사용하기 전에 자세히 알아보고자 한다.
본론
- 자바의 직렬화 & 역직렬화
직렬화 : 자바의 Object를 다른 컴퓨터의 자바 시스템에서 사용할 수 있도록 저장하는 것을 의미한다. Object를 연속된(Serial) 바이트 스트림 형태로 포맷 변환하는 기술이다.
역직렬화 : 바이트 스트림을 원래대로 자바 시스템의 Object로 변환하여 로드하는 기술이다.

JVM 클래스 로더 시스템을 보면 클래스 정보가 메서드 영역에 저장되고 Object가 힙, 힙 내부에 호출되는 메서드 정보가 스택에 저장되며, 힙과 스택에 Object 정보가 저장된다. 직렬화가 동작할 때, 스택과 힙 영역에 상주하고 있는 객체 데이터를 직렬화를 통해 바이트 스트림 형태로 변환하여 Redis 같은 외부 저장소에 저장해두고, 다른 컴퓨터에서 가져와, 역직렬화를 통해 자바 객체로 변환해서 JVM 메모리에 적재하는 것으로 보면 된다.
[Core] JVM의 역할과 동작 원리
서론※ 과거에 기록한 내용에서 중요한 부분만 발췌하여 모두가 이해하기 쉽게 다시 서술한다. 본론- JVM, JDK, JRE, JAR 구분1. JVM자바 바이트 코드를 어떻게 실행할 지에 대한 표준 스펙으로 바이
hsb422.tistory.com
JVM 클래스 로더 내용은 위 블로그에서 확인할 수 있다.
- 직렬화 vs JSON 비교
둘 다 Object를 메모리가 아닌 저장 공간(디스크 등)에 저장하는 방식이며, 직렬화가 보다 Java에 친화적이라는 차이를 가지고 있다. primitive 타입이나, 배열 등은 JS나 파이썬에서도 공통적으로 지원하는 자료형이라서 JSON으로 변환을 해도 다른 시스템에서 이용할 수 있다. 하지만, 자바에서만 제공하는 자료형(컬랙션, 인터페이스, 커스텀 클래스)은 JSON으로 변환 시, 사용이 어려울 수 있다.
✅ 그렇다면 왜 직렬화를 알아야 하는 것일까?
1) primitive 타입이 아닌 자바의 온갖 레퍼런스 타입(클래스, 인터페이스, 사용자 커스텀 자료형)의 경우 JSON으로 변환 시, 사용에 한계가 있다. 그래서 이들을 외부로 내보내기 위해선 각 데이터를 매칭시키는 별도의 파싱이 필요한다.
2) 직렬화를 사용하면 파이썬이나 JS와 같은 다른 시스템에서는 사용하지 못할지라도, 별다른 파싱 없이, 자바의 레퍼런스 타입(컬랙션, 인터페이스, 커스텀 클래스)을 외부로 내보낼 수 있다.
3) 역직렬화를 통해 읽어들이면 데이터 타입이 자동으로 맞춰지기 때문에 별다른 파싱 없이, JVM 시스템에 로드 후 자바 클래스의 기능들을 곧바로 이용할 수 있다.
따라서 직렬화된 데이터를 문자열로 변환하여 DB에 저장해두고 꺼내 쓰기도 한다. (DB는 바이트 데이터를 저장하는 것을 권장하지 않기 때문)
- 자바 직렬화 사용법
import java.io.Serializable;
class Customer implements Serializable {
int id; // 고객 아이디
String name; // 고객 닉네임
String password; // 고객 비밀번호
int age; // 고객 나이
public Customer(int id, String name, String password, int age) {
this.id = id;
this.name = name;
this.password = password;
this.age = age;
}
}Serializable 인터페이스를 구현해야만, 직렬화를 할 수 있다. 자바 시스템에 직렬화가 허용된 클래스임을 명시한다. 오직 인스턴스 필드만 직렬화되며 static 등 클래스 레벨 필드는 직렬화되지 않는다.
-> 객체 직렬화 ObjectOutputStream
public static void main(String[] args) {
// 직렬화할 객체
Customer customer = new Customer(1, "홍길동", "123123", 40);
// 외부 파일명
String fileName = "Customer.obj";
try (
FileOutputStream fos = new FileOutputStream(fileName);
ObjectOutputStream out = new ObjectOutputStream(fos)
) {
out.writeObject(customer);
} catch (IOException e) {}
}코드를 실행하면, Customer 객체가 바이트 스트림 형태로 포맷 변환되어 .obj 형식으로 저장된다. 보통 직렬화를 명시하기 위해 OBJ 파일로 저장한다.
-> 역직렬화 ObjectInputStream
public static void main(String[] args) {
// 외부 파일명
String fileName = "Customer.obj";
// 파일 스트림 객체 생성
try(
FileInputStream fis = new FileInputStream(fileName);
ObjectInputStream in = new ObjectInputStream(fis)
) {
// 바이트 스트림을 다시 자바 객체로 변환 (캐스팅이 필요)
Customer deserializedCustomer = (Customer) in.readObject();
System.out.println(deserializedCustomer);
} catch (IOException | ClassNotFoundException e) {}
}역직렬화 시, 생성자 없이 객체를 로드하여 자바 시스템에서 사용할 수 있다. (하지만, 이는 단점이 될 수 있다.)
- 자바 직렬화의 단점
1. 용량이 크다
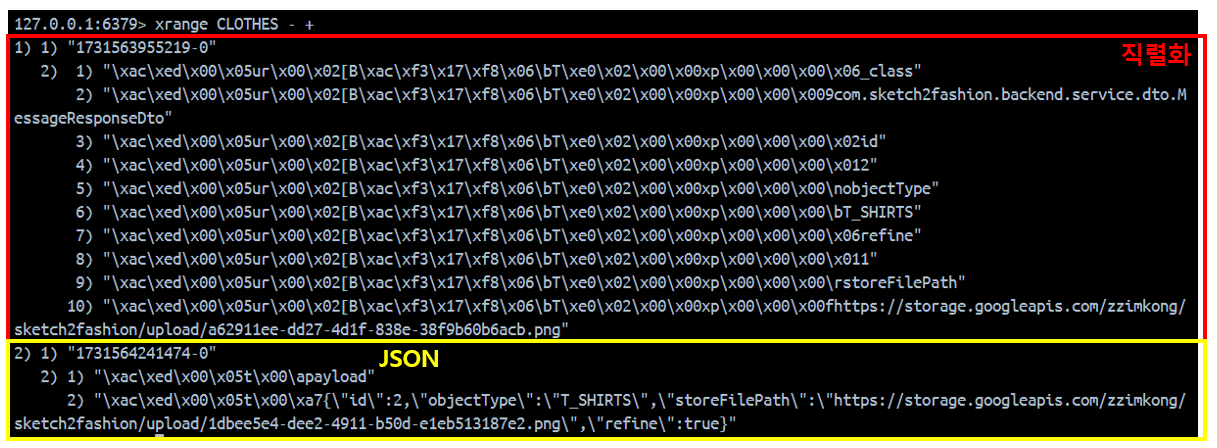
직렬화를 할 때, 필드 정보뿐 만 아니라, 클래스 메타 데이터도 함께 저장하여, JSON 보다 용량이 2배 이상 크다. 따라서 장기적으로 저장되는 데이터나 대용량 데이터는 직렬화를 하기 전에 올바른 선택인지 고심해야 한다. (지양하라.)
2. 보안 이슈
역 직렬화를 할 때 생성자가 필요하지 않으며, 이는 명백히 자바 에코 시스템에 위반된 동작이다. 개발자가 생성자를 통해서 객체를 생성하도록 의도했지만, 개발자 의도대로 동작하지 않아서 보안상 이슈가 발생할 수 있다. (마치 Builder 패턴의 단점과 같다.)
- Redis 직렬화
이 포스팅이 직렬화를 다룬 이유가 지금부터 시작된다. 이 예제는 일반 키-벨류나 해시 키-벨류 자료구조가 아닌 Redis Stream 자료구조를 대상으로 한다. 일반 자료구조도 직렬화가 요구될 때 키와 벨류에 상황에 맞는 직렬화를 설정해주면 동일하게 사용할 수 있다.
✅ Redis Stream 자료구조 형태
Stream 자료구조에 대해 간단히 알아보자. Stream은 Key-Value 형태의 자료구조로 랜덤 ID를 키로 가지고, Entry라는 Record 형태의 데이터를 값으로 가진다.
Redis hashes are record types structured as collections of field-value pairs.
공식 문서에 따르면 Redis Hash은 키-벨류 형태의 Record 타입이라고 한다. 즉, Stream의 Entry 내부적으로도 Hash 키-벨류 형태를 가지는 것을 짐작할 수 있다.
public class MessageResponseDto {
private Long id;
private ObjectType objectType;
private String storeFilePath;
private Boolean refine;
public static MessageResponseDto from(Message message) {
return new MessageResponseDto(
message.getId(),
message.getObjectType(),
message.getStoreFilePath(),
message.getRefine()
);
}
}아래 내용을 이해하기 위해, 앞으로 사용할 Entry를 보자. MessageResponseDto라는 클래스의 객체를 Entry로 저장하면
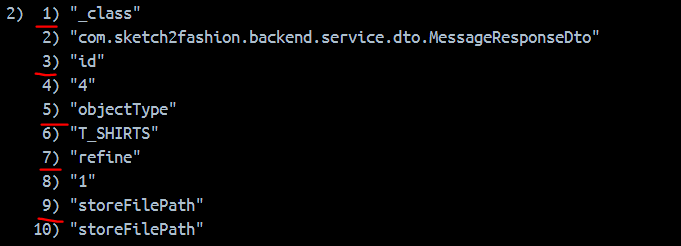
키-벨류 컬랙션 형태를 띄기 위해서 필드명이 키, 필드값이 벨류 형태로 저장된다. 1, 3, 5, 7, 9번이 필드명이고 2, 4, 6, 8, 10번이 필드 값인 페어 형태이다.
-> RedisTemplate
JDBC 템플릿처럼 Redis In-Memory DB 데이터 소스를 가지고 커넥션을 연결하여 Java 객체를 Redis에 바이트 스트림 데이터로 저장하는 역할이다. Redis는 정보를 바이트 로우 데이터 형식으로 저장하며, RedisTemplate이 CRUD 기능을 추상화하여 제공한다. RedisTemplate에서 자바의 Object와 Redis 저장소(외부 저장소) 의 바이너리 데이터 간의 직렬화/역직렬화를 자동으로 수행한다.
✅ 대표적인 구현체
JdkSerializationRedisSerializer, StringRedisSerializer, JacksonJsonRedisSerializer 등등
위에서 설명한 바와 같이 자바의 Obj 직렬화는 OutputStream을 사용한 바이트 스트림으로 저장되며, Redis에 저장되는 데이터는 바이트 로우 데이터라서, 직렬화된 자바 객체를 바로 저장할 수 있다. 즉, 레디스 클라이언트인 Spring에서 바이트로 변환을 하여 저장해야 하고, 사용할 때는 거꾸로 역직렬화를 해야 한다.
https://hsb422.tistory.com/entry/%EB%AC%B8%EB%B2%95-1
[문법] 자바 입력 데이터 저장 방식
서론※ 과거에 기록한 내용에서 중요한 부분만 발췌하여 모두가 이해하기 쉽게 다시 서술한다. 본론- 자바의 인코딩 방식1. 자바 내부적으로는 문자열이 UTF16으로 인코딩 된다.2. 문자
hsb422.tistory.com
자바의 데이터 저장 방식은 위 블로그를 참고하자.
🚨 넣을 땐 편하지만, 꺼낼 땐 쉽지 않다
절대 간과하면 안되는 부분은 역/직렬화 부분이다. Redis를 사용할 때 이 부분에서 삽질(파싱, 올바른 직렬화 방식 선택 등)을 많이 하게 된다. 필자가 그랬듯이...
- Spring RedisTemplate Serializer 종류와 사용시 주의할 점
따라서, Redis는 유저 커스텀 객체와 로우 바이트 데이터 간의 전환을 위해 Redis Serializer 인터페이스를 제공하며, Client에서 직접 직렬화를 해서 Redis에 넣는 작업을 제거하고 객체를 넣기만 하면 Redis가 알아서 직렬화해서 저장해준다.
1. JdkSerializationRedisSerializer
JDK에서 제공하는 기본 Serializer를 사용하는 Redis Serializer이다. Redis는 이것을 디폴트로 사용하기 때문에 따로 설정하지 않으면 자동으로 이것을 사용한다.
-> 문제점
JdkSerializationRedisSerializer는 JDK에서 기본으로 제공하는 자바 직렬화를 사용한다. 즉 JDK 직렬화의 문제점을 그대로 가지게 된다.
1) JDK Serializer를 구현해야 한다.
자바의 기본 Serializer는 Serializer 인터페이스를 구현한 객체만 직렬화를 할 수 있다. 이는 Serializer라는 기술에 의존해서 유연하지 못한 구조를 발생시킨다.
@Configuration
public class RedisConfig {
@Value("${spring.redis.data.host}")
private String host;
@Value("${spring.redis.data.port}")
private int port;
@Bean
public RedisConnectionFactory redisConnectionFactory() {
return new LettuceConnectionFactory(new RedisStandaloneConfiguration(host, port));
}
@Bean
public RedisTemplate<String, MessageResponseDto> redisTemplate() {
RedisTemplate<String, MessageResponseDto> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(redisConnectionFactory());
return redisTemplate;
}
}LettuceConnection에 별다른 설정을 하지 않으면, 자동으로 JDK 직렬화 방식이 선택된다.
https://jojoldu.tistory.com/418#
Jedis 보다 Lettuce 를 쓰자
Java의 Redis Client는 크게 2가지가 있습니다. Jedis Lettuce 둘 모두 몇천개의 Star를 가질만큼 유명한 오픈소스입니다. 이번 시간에는 둘 중 어떤것을 사용해야할지에 대해 성능 테스트 결과를 공유하
jojoldu.tistory.com
Redis Connection에 대한 설명은 위 블로그를 참고하자.
@Async
public void sendModelMessage(MessageResponseDto message) {
ObjectRecord<String, MessageResponseDto> record = StreamRecords.newRecord()
.in(CLOTHES.toString())
.ofObject(message)
.withId(RecordId.autoGenerate());
redisTemplate.opsForStream()
.add(record);
}위 코드는 Redis 스트림에 데이터를 입력하는 방식으로

데이터를 넣어보면, 넣고자 하는 클래스에 Serializer를 구현하지 않아서 포맷 변환이 불가능하다는 예외가 발생한다. 넣고자 하는 데이터 객체인 MessageResponseDto에 java.io.Serializable을 구현해줘야 한다.
2) 용량
앞서 말했듯이, JDK 직렬화는 객체 메타 정보, 타입 정보를 같이 직렬화하여 용량을 많이 차지한다. 따라서, Redis 서버를 운영하는 컴퓨터에 메모리를 많이 차지한다.
3) 호환성 문제
JDK 자바 시스템에서만 직렬화가 가능하여 다른 시스템에서는 해당 데이터를 전혀 사용할 수 없다.
물론, 별도의 설정 없이 직렬화가 가능한 장점도 있지만, 위 문제로 인해 사용하지 않는 것을 추천한다.
2. GenericJackson2JsonRedisSerializer
두 번째로 알아볼 Serializer는 Jackon 라이브러리를 사용한 직렬화 방식이다.
-> Jackson 라이브러리
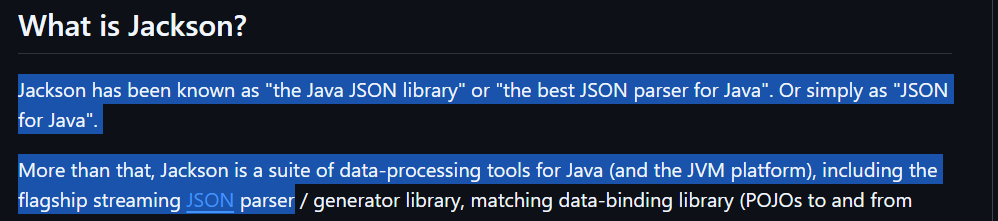
Jackson은 Java 플랫폼에 적합한 JSON 호환 라이브러리이다. JSON이기 때문에 JAVA가 아닌 타 시스템에서도 사용할 수 있다.
-> 장점
@Bean
public RedisTemplate<String, Object> streamRedisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(redisConnectionFactory);
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(new GenericJackson2JsonRedisSerializer());
return redisTemplate;
}Jackson 직렬화를 사용하려면 RedisTemplate에 따로 설정해주어야 한다. GenericJackson2JsonRedisSerializer는 별도의 Class Type을 지정하지 않아도 자동으로 직렬화해준다. JDK 직렬화와 다르게 Serializeable 인터페이스에 의존하지 않는다.
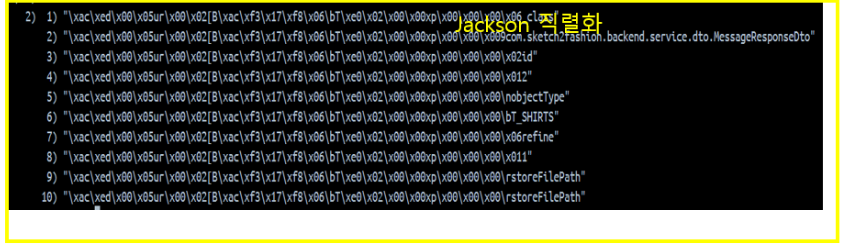
하지만 일반적인 키-벨류 형식에 데이터를 넣었을때와는 다르게, Stream에서는 JSON 형태로 보이지 않고 바이트 데이터 형태로 보인다. 이것이 Stream 자료 구조를 정확히 이해하고자 하는 시작점이 되었다. 이 같은 결과를 보이는 이유는 Stream이 Entry를 사용하기 때문이며, 이는 아래에서 알아보자
-> 단점
1) _class로 클래스 메타 정보를 함께 저장하여 대용량 데이터에서 용량 이슈가 발생한다.
2) _class 메타 정보로 인한 패키지 버저닝 이슈가 존재하여, 여러 자바 시스템을 운영할 때 패키지 정보가 다르면, 에러가 발생한다.
-> 중간 결론
1) _class 메타 정보로 인한 패키지 버저닝 이슈가 존재하여, 여러 시스템에서는 사용하기 쉽지 않지만, JSON으로 JAVA가 아닌 다른 종류 언어의 프레임워크와 통신 가능
2) 대용량 데이터가 아닐 경우 편하게 사용할 수 있다.
3) Serializer부터 클래스 타입까지 별도의 설정을 하지 않아도 편리하게 사용할 수 있다.
JDK 직렬화와 다르게 직렬화에 대한 설정(Serializer)을 해줄 필요없는 장점이 크게 다가온다.
3. StringRedisSerializer
@Async
public void sendModelMessage(MessageResponseDto message) {
try {
ObjectRecord<String, String> record = StreamRecords.newRecord()
.in(CLOTHES.toString())
.ofObject(objectMapper.writeValueAsString(message)) // 별도의 직렬화
.withId(RecordId.autoGenerate());
streamRedisTemplate.opsForStream()
.add(record);
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
}마지막은 String 값 그대로 저장하는 String 직렬화이다. 이는 객체를 Redis에 저장하기 위해서 직접 직렬화/역직렬화하는 로직을 구성해야 한다.
-> 장점

class 메타 데이터를 저장하지 않아서 용량 이슈에서 해결되고, 별도의 호환과 의존 관계가 없다.
-> 단점
primitive 타입이 아닌 JAVA 시스템만의 타입일 경우 별도의 로직을 작성하는 것이 번거로울 수 있다.
✅ 그렇다면 Stream에는 어떠한 직렬화를 사용해야 할까?
1) RedisTemplate에 어떤 설정을 해줘야 할까?
2) 어떤 직렬화 방법을 선택해야 할까?
여기서부터는 RedisTemplate에 직렬화를 적용했을 때, Redis Stream에 어떠한 결과물이 저장되는지 확인하면서 진행해보자. 위와 같은 것들을 알아볼 것이다.
1) KeySerializer
@Bean
public RedisTemplate<String, Object> streamRedisTemplate() {
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(redisConnectionFactory());
redisTemplate.setKeySerializer(new StringRedisSerializer()); // 여기
redisTemplate.setValueSerializer(new StringRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setHashValueSerializer(new StringRedisSerializer());
return redisTemplate;
}다른 자료구조는 보지 말고 KeySerializer만 보자
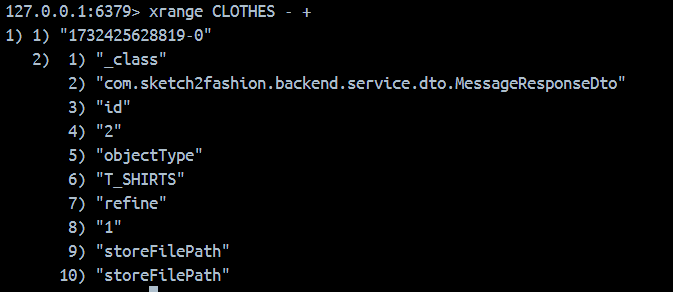
StringRedisSerializer로 하면 위와 같이 나오고
@Bean
public RedisTemplate<String, Object> streamRedisTemplate() {
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(redisConnectionFactory());
redisTemplate.setKeySerializer(new GenericJackson2JsonRedisSerializer());
redisTemplate.setValueSerializer(new StringRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setHashValueSerializer(new StringRedisSerializer());
return redisTemplate;
}GenericJacksonRedisSerializer로 하면

포맷 변환이 안된다는 예외가 발생한다.

레디스 공식문서에 Stream을 검색해보니, Stream의 요소를 Entry라고 칭하고, 각 Entry는 ID를 가진다고 나와있다. JAVA의 Map 타입이 내부에 Entry로 동작하는 것과 같이 키-벨류 형태의 저장소라는 것을 의미하는 것 같다.
ObjectRecord<String, MessageResponseDto> record = StreamRecords.newRecord()
.in(CLOTHES.toString())
.ofObject(message)
.withId(RecordId.of("1732425628817-0")); // 여기
streamRedisTemplate.opsForStream()
.add(record);Stream에 데이터를 넣을 때 ID를 넣게 되는데 원하는 문자열("1732425628817-0")을 지정해보면
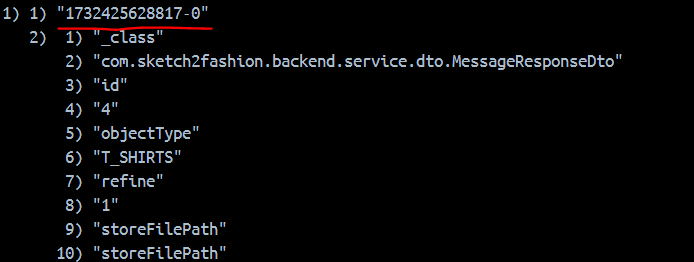
명시한 ID로 저장된다. 이를 통해 알 수 있는 것은 Redis Template의 withId 메서드는 entry ID를 의미하는 것이며, 반드시 String 직렬화를 사용해야, 포맷 변환이 가능하다.
2. ValueSerializer
@Bean
public RedisTemplate<String, Object> streamRedisTemplate() {
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(redisConnectionFactory());
redisTemplate.setKeySerializer(new StringRedisSerializer());
return redisTemplate;
}KeySerializer 예제에서는 키-벨류 쌍에 모두 직렬화를 명시했다. 위처럼 Value Serializer에 직렬화를 선택하지 않으면,
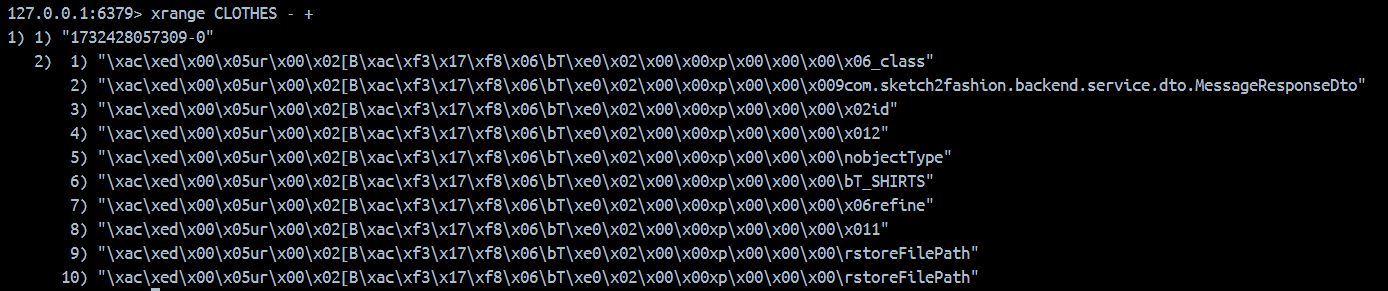
JDK 직렬화가 자동 선택되며, 객체의 필드와 필드 값이 모두 JDK 직렬화에 의해서 바이트 스트림 데이터로 변환되어 저장된다.
@Bean
public RedisTemplate<String, Object> streamRedisTemplate() {
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(redisConnectionFactory());
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(new StringRedisSerializer());
return redisTemplate;
}StringSerializer를 사용하면
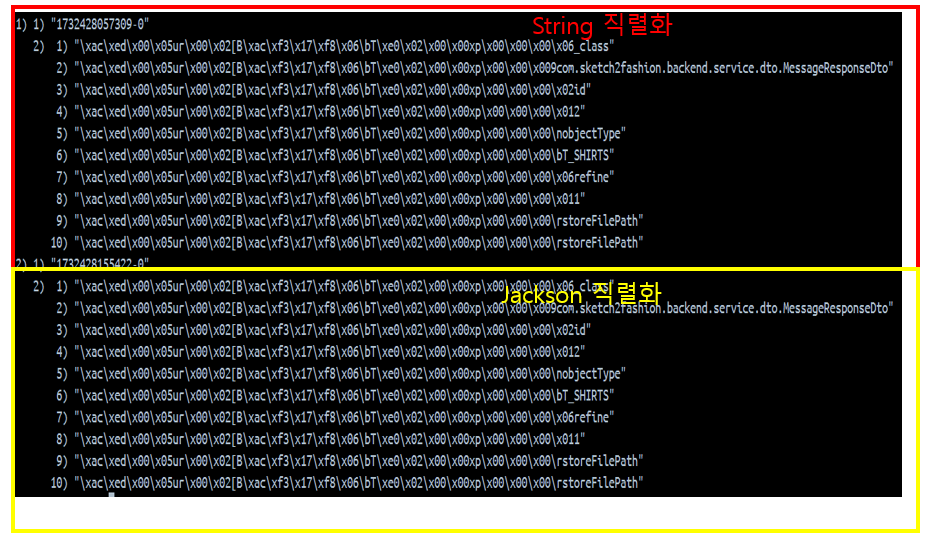
StringSerializer 직렬화를 한 경우와, Jackson 직렬화를 사용한 경우 모두 JDK 직렬화를 사용한 경우와 동일한 형태로 저장된다.
https://hsb422.tistory.com/entry/jackson-json
[최적화] Redis Stream 내부 ObjectHashMapper를 이용하여 HASH 역직렬화 자동화하기
🚨 서론 (문제상황)@Beanpublic RedisTemplate redisTemplate( RedisConnectionFactory redisConnectionFactory, ObjectMapper objectMapper) { Jackson2JsonRedisSerializer jsonRedisSerializer = new Jackson2JsonRedisSerializer(AccessTokenSaveResponseDto.clas
hsb422.tistory.com
이를 이해하기 위해선 레디스 스트림의 내부 구조가 Hash 구조인 것을 이해해야 한다. Stream에 Value는 Entry 타입이라서 ValueSerializer는 크게 의미가 없다.
3) HashKeySerializer
@Bean
public RedisTemplate<String, Object> streamRedisTemplate() {
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(redisConnectionFactory());
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(new StringRedisSerializer());
redisTemplate.setHashKeySerializer(new GenericJackson2JsonRedisSerializer());
redisTemplate.setHashValueSerializer(new StringRedisSerializer());
return redisTemplate;
}Stream이 키-벨류 형태의 데이터 구조라서, 키-벨류 직렬화를 사용하는 것은 어느 정도 이해가 된다. 근데 Hash는 어디에 사용되는 것일까?
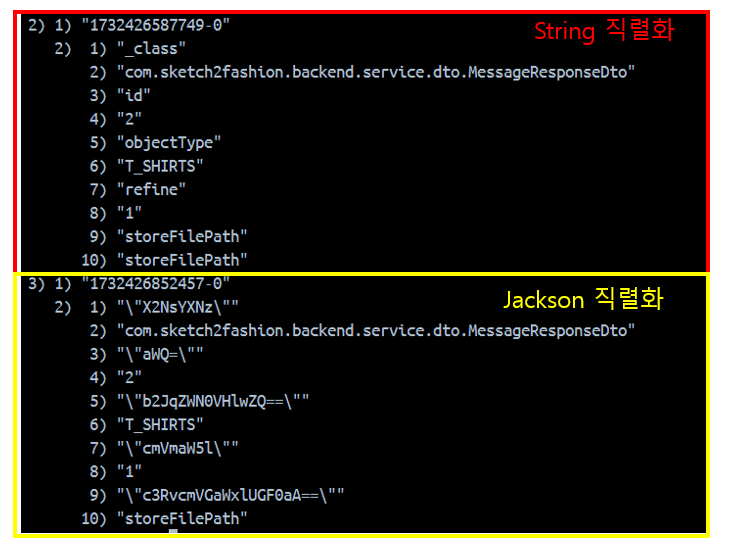
해시키를 사용했을 때 변화가 나타났다. 1, 3, 5, 7, 9번 데이터가 바이트 데이터로 변환되었는데, 아마도 HashKey는 객체의 필드명을 가리키는 것 같다.
4. HashValueSerializer
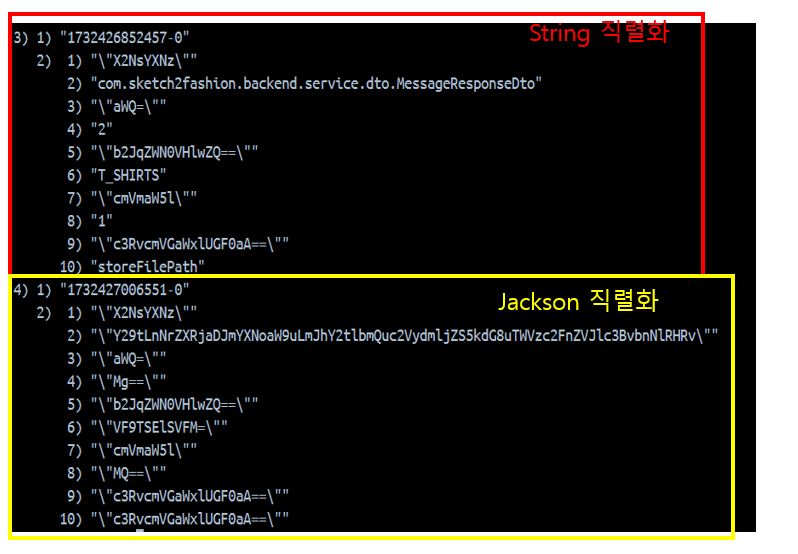
Value는 필드의 값이 직렬화된 것이 보인다.
✅ Stream RedisTemplate 설정 방법
| Key | Entry ID에 접근하는 Key이다. 무조건 String 직렬화를 사용해야 한다. |
| Value | Entry ID로 접근하는 Entry이다. Entry는 Record라는 해시 형태의 구조를 가지고 있다. |
| HashKey | 자바 Object를 Entry로 저장했을 때 객체 필드명 |
| HashValue | 자바 Object를 Entry로 저장했을 때 객체 필드값 |
이제 실습을 정리해보면 위와 같다.
@Bean
public RedisTemplate<String, Object> streamRedisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(redisConnectionFactory);
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(new StringRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setHashValueSerializer(new StringRedisSerializer());
return redisTemplate;
}필자는 현재, 위와 같은 설정으로 Redis Stream을 사용하고 있다. Stream의 Record의 키-벨류는 문자열 형태로 저장됐을 때 ObjectHashMapper에 의해 자동 역직렬화가 가능하기 때문이다.
결론
Redis Stream을 사용할 때 RedisTemplate 직렬화 설정을 어떻게 해야하는 지 알아보았다. 다음 포스트에서 Stream의 ObjectHashMapper를 다루고 있으니 이벤트 발생에 다른 데이터 처리를 알아보자.
참고
https://techblog.woowahan.com/2550/
'[백엔드] > [spring+JPA | 이슈해결]' 카테고리의 다른 글
| [최적화] Cache 도입을 위한 데이터 접근 방식 문제점 분석하기 (0) | 2024.12.01 |
|---|---|
| [최적화] Redis Stream 내부 ObjectHashMapper를 이용하여 HASH 역직렬화 자동화하기 (4) | 2024.11.24 |
| [최적화] Spring 환경 AI 서비스 실시간 스트림 파이프라인 구축 (with Redis Stream) (0) | 2024.11.11 |
| 자바 PART.무한의 값 처리 BigDecimal (0) | 2023.11.27 |
| spring PART.postman으로 login 테스트 할 때 받아온 토큰을 요청 헤더에 자동으로 넣는 방법 (0) | 2023.08.18 |



