
개발자로 후회없는 삶 살기
첫 번째 미션(Mmdetection 결과로부터 Top-N Accuracy 추출) 본문
서론
첫 번째 과제는 AnnoWiz(자동 AI 라벨링 툴) 라벨링 결과를 정량적 지표로 추출하는 것입니다. 소프트웨어에 탑재된 모델 결과와 Mmdetection의 SOTA 모델 결과를 비교하면 소프트웨어를 사용하는 고객의 신뢰성을 보장할 수 있을 것입니다.
또한, 모든 과제는 부서원들께 PT 형식으로 발표하게 될 것이라고 했습니다. 교수님께 부여받는 AI 과제도 하고 매니저님께 받는 개발 미션도 하며, 이를 발표까지 하는 정말 좋은 인턴 경험이 될 것 입니다.
본론
1. mmdetection 결과 csv로 저장
2. vs code python 디버깅 조사 및 수행
- Mmdetection 결과로부터 Top-N Accuracy 추출
=> 미션
1) test.py를 샘플 이미지에 대해 돌렸을 때 나오는 각 이미지 당 precision, recall, accuracy 등 평가 지표를 csv로 저장
2) 학습 시킨 모델 환경을 Docker 이미지로 만들어서 배포
현업에서 모델을 직접 모델링하는 경우는 거의 없다고 합니다. 데이터 입력단의 전처리와 출력 결과 처리가 제일 중요하기에 확실히 제 것으로 만들면 좋을 것입니다.
=> test.py 실행으로 알아보는 mmdetection 실행 과정
1) 지난 미션 리뷰
_base_ = [
'../_base_/models/mask_rcnn_r50_fpn.py',
'../_base_/datasets/coco_instance.py',
'../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
]위 코드는 예전 내장 mask_rcnn을 사용할 때 본 코드입니다. 이를 분석하면 이번 과제의 실행 과정을 알 수 있습니다. 지난 과제를 할 때 coco.py, coco_instance.py, mask_rcnn_r50_fpn.py를 수정하였습니다.
coco_instance.py, mask_rcnn_r50_fpn.py는 위 __base__에 나와있으니 이해가 되는데 coco.py는 왜 수정해야 하는 지 의문이었습니다.
-> 이유 분석
# dataset settings
dataset_type = 'CocoDataset'
data_root = 'data/coco/'그 이유는 coco_instance를 보면 CocoDataset을 타입으로 하는 데
@DATASETS.register_module()
class CocoDataset(CustomDataset):그것이 coco.py에 클래스로 존재하기 때문이었습니다. 이렇게 알게된 사실을 이번 미션에 적용해 보겠습니다.
2) 미션 시작
_base_ = [
'../_base_/models/mask_rcnn_r50_fpn_nia31.py',
'../_base_/datasets/kfashion.py',
'../_base_/schedules/schedule_1x_nia31.py', '../_base_/default_runtime.py'
]이번 미션의 __base__ 코드는 이러합니다. 따라서 이번엔 kfashion.py에 정의된 타입의 클래스를 작성한 파일을 수정해야 합니다.
@DATASETS.register_module(force=True)
class KFashionDataset(CocoDataset):kfashion.py에 정의된 타입의 클래스가 KFashionDataset이었습니다. 하지만 KFashionDataset은 내부에 CLASSES 지정만 있고 별다른 코드가 없었고, CocoDataset을 상속 받기에 역시 coco.py를 수정하면 됩니다.
=> 평가 지표를 뽑는 접근 방법
이제 수정해야 할 파일을 알았다면 평가 지표를 뽑기 위해 test.py를 실행할 때 어디서 평가를 하는 지 알아야 합니다. 이번에 굉장히 많은 시행 착오를 했고 다차원의 행렬도 살펴보았으며 코드를 디버깅으로 순차적으로 따라가 보기도 했습니다. 정말 귀중한 경험이니 이를 잘 정리해 보겠습니다.
처음에는 정말 test.py의 어디를 봐야 할 지 하나도 모르겠었습니다. 근데 봐야할 코드를 알게 되니 접근하는 방법이 눈에 보였습니다.
1) demo로 해보기

저희가 구해야 하는 값은 위 이미지에서의 클래스와 숫자입니다. 그렇다면 demo를 실행해서 구할 수 있다면 test에서도 같은 원리이지 않을까? 하여 demo에서 먼저 평가 지표 값을 구해보기로 했습니다. 근데 "The model and loaded state dict do not match exactly"라는 오류가 떴습니다.
import cv2
import matplotlib.pyplot as plt
# config 파일을 설정하고, 다운로드 받은 pretrained 모델을 checkpoint로 설정.
# config 파일과 pretrained 모델을 기반으로 Detector 모델을 생성.
from mmdet.apis import init_detector, inference_detector
config_file = 'configs/NIA31/mask_rcnn_r50_fpn_1x_coco_na31.py'
checkpoint_file = 'checkpoints/NIA_3-1.pth'
model = init_detector(config_file, checkpoint_file, device='cpu')
img = 'demo/gaurdigan_demo.jpg'
out_file = "demo/result.jpg"
# inference_detector의 인자로 string(file경로), ndarray가 단일 또는 list형태로 입력 될 수 있음.
results = inference_detector(model, img)
from mmdet.apis import show_result_pyplot
# inference 된 결과를 원본 이미지에 적용하여 새로운 image로 생성(bbox 처리된 image)
# Default로 score threshold가 0.3 이상인 Object들만 시각화 적용. show_result_pyplot은 model.show_result()를 호출.
# show_result_pyplot(model, img, results)
show_result_pyplot(
model,
img,
results,
palette='coco',
score_thr=0.3,
out_file=out_file)
type(results), len(results) # (list, 80)
print(results)
print(model.__dict__)이를 해결하기 위해 검색을를 해보던 중 model.__dict__라는 메서드를 알게 되었습니다. 메서드를 출력하면 model의 내부 설정을 알 수 있습니다. 근데 거기에 13개의 클래스가 명시되어 있었습니다.
# 13개의 클래스
CLASSES = ('blouse', 'cardigan', 'coat', 'jacket', 'jumper', 'shirt', 'sweater', 't-shirt', 'vest', 'pants', 'skirt', 'onepiece(dress)', 'onepiece(jumpsuite)')제가 하고 있는 미션의 카테고리는 6개의 클래스입니다. 근데 이것을 보고 교수님이 학습시키신 모델은 13개로 했다는 말씀이 기억났습니다. 따라서 모든 클래스를 다시 13개로 설정을 해주었고 그 결과 domo.py는 잘 돌아갔습니다.

또한 demo 코드를 보면 show_result_pyplot에서 result라는 인자가 보입니다. 저는 show_result_pyplot 코드를 하면 result.jpg과 생기길래 show_result_pyplot의 인자에 score가 담겨있을 수도 있다고 생각했습니다.
2) test.py로 해보기
test.py를 밑에서 다룰 디버깅을 활용해 실행해 보던 도중 score를 구하는 의심되는 곳을 발견했습니다.
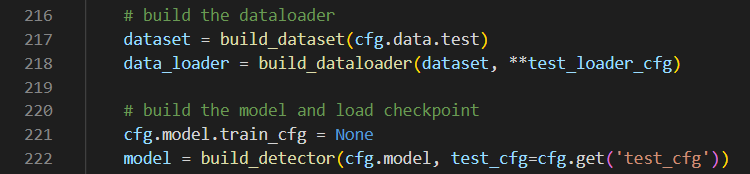

이곳으로 모델이 결과를 뽑을 때 '>'라는 progress bar가 보이는 데 저는 bar가 하나씩 채워질 때마다 result.jpg가 하나씩 생기길래 'bar가 생기는 곳을 디버깅해보면 되겠구나'라는 생각을 하게 되었습니다. 또한 제가 지금까지 봐왔던 model, dataset, dataloader가 singel_gpu_test의 인자로 들어갔습니다.
model.module.show_result(
img_show,
result[i],
bbox_color=PALETTE,
text_color=PALETTE,
mask_color=PALETTE,
show=show,
out_file=out_file,
score_thr=show_score_thr)따라서 single_gpu_test에 들어가보니 demo와 같이 show_result라는 메서드가 있었고 result[i]를 인자로 주니 해당 메서드만 파헤치면 score를 구할 수 있을 것이라는 확신과 함께 show_result 메서드가 한 번 실행될 때마다 result.jpg가 생기는 것을 또 확신할 수 있었습니다.
if isinstance(result[0], tuple):
bbox_result, segm_result = result[0]
if isinstance(segm_result, tuple):
segm_result = segm_result[0] # ms rcnn
else:
bbox_result, segm_result = result, None
bboxes = np.vstack(bbox_result)
labels = [
np.full(bbox.shape[0], i, dtype=np.int32)
for i, bbox in enumerate(bbox_result)
]
labels = np.concatenate(labels)
# draw segmentation masks
segms = None
if segm_result is not None and len(labels) > 0: # non empty
segms = mmcv.concat_list(segm_result)
if isinstance(segms[0], torch.Tensor):
segms = torch.stack(segms, dim=0).detach().cpu().numpy()
else:
segms = np.stack(segms, axis=0)result[i]를 파헤치기 위해 위와 같은 후처리 코드를 구현했습니다. 추론 결과 행렬로부터 bbox와 segm를 추출하고 1개의 입력에 대해 bbox, segm, cls 예측 결과를 하나로 결합합니다.
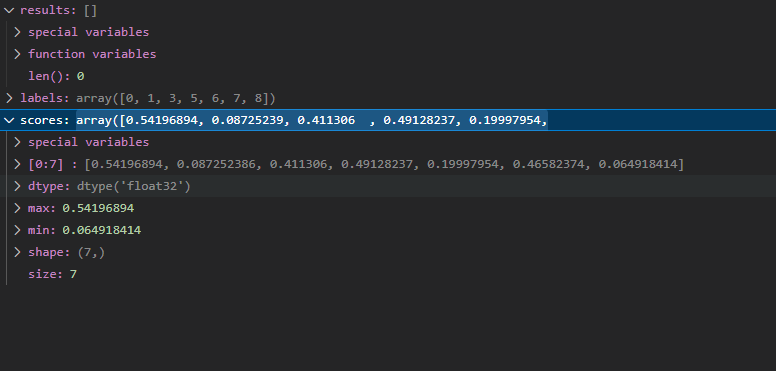
결과를 해석해 보면 하나의 이미지에서 7개의 객체에 가능성을 두고 있고 그 객체의 라벨은 labels에 저장되고 confidence는 scores에 들어있습니다. 이를 디버깅을 통해 알아냈습니다.
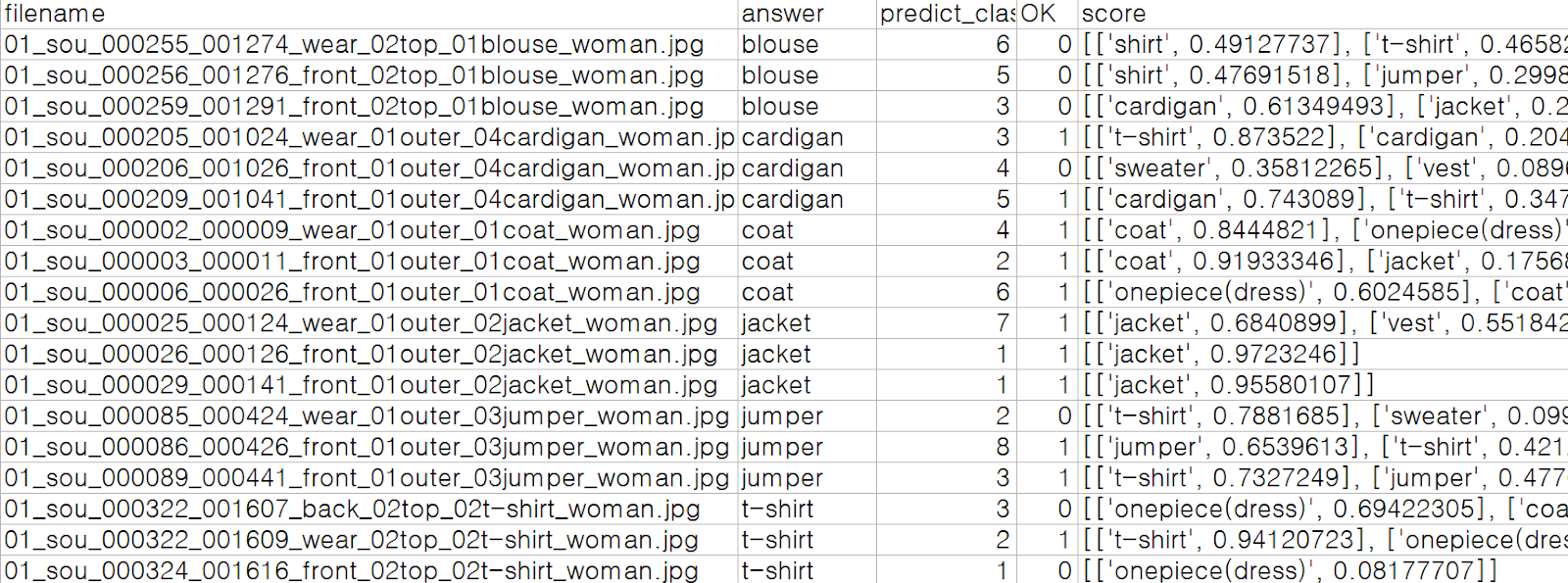
results 변수에 들어있는 요소들을 뽑아내어 이미지 별로 score 등의 평가 지표를 뽑아내어 미션을 성공하였습니다. Top3 Acc와 mAP, 당사 모델이 상위 3개의 confidence의 클래스에 속하는 지를 도출하였습니다. 이것을 대시보드 페이지에서 모델 검증에 사용할 것입니다.
- Vscode Python 디버깅 조사 및 수행
-> Vscode 디버깅이란?
저는 지금까지 .py 파일 하나 짜리를 디버깅하기 위해서는 print()를 사용했습니다. 근데 python test.py를 하면 그 콘솔 출력이 안 찍혔습니다. 교수님께서는 python은 빌드된 라이브러리를 실행하는 것인데 제가 한 것은 로컬 코드라서 실행하더라도 print의 적용이 안 됐다고 말씀해 주셨습니다. 그래서 이런 대용량 코드를 실행해서 변수 하나의 디버깅을 하기 위해서는 파이썬 디버깅 모드를 사용해야 합니다.
1) launch.json 설정 (참고 1)
{
// Use IntelliSense to learn about possible attributes.
// Hover to view descriptions of existing attributes.
// For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387
"version": "0.2.0",
"configurations": [
{
"name": "Python: Current File",
"type": "python",
"request": "launch",
"program": "${file}",
"args": [
"configs/NIA31/mask_rcnn_r50_fpn_1x_coco_na31.py",
"checkpoints/NIA_3-1.pth",
"--eval", "segm",
"--show-dir", "results/mask_rcnn_r50_fpn_1x_coco_na31_hsb2"
],
"console": "integratedTerminal",
"justMyCode": true
}
]
}launch.json을 수정하여 디버깅을 수행할 수 있습니다. args는 위처럼 인자를 주면
python tools/test.py configs/NIA31/mask_rcnn_r50_fpn_1x_coco_na31.py
checkpoints/NIA_3-1.pth --eval
segm --show-dir results/mask_rcnn_r50_fpn_1x_coco_na31_hsb2이와 같은 cli 명령어처럼 디버깅을 할 수 있습니다.
2) 중단점 지정하기
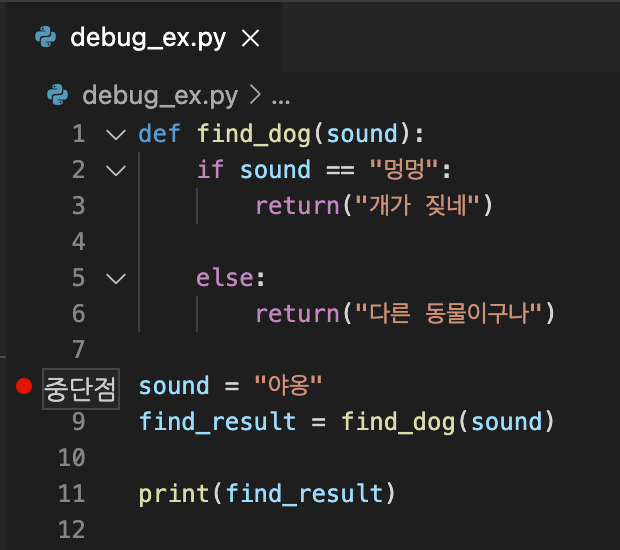
중단점을 찍는 것은 해당 라인 이전까지만 실행하기 위함합니다. 즉 빨간색 점으로 표시한 라인 전까지 코드가 실행되기를 원한다는 의미입니다. 라인 8에 중단점을 찍으면 7까지 실행됩니다. 중단점을 찍더라도 실행은 무조건 실행하려는 파일을 클릭하고 실행해야 합다.
3) 디버그 모드 UI

라인을 다 무시하고 중단점에서만 멈춥니다.

중단점이 있는 py 파일은 아래 UI처럼 중단점부터 라인 하나하나 실행하는 데 다른 모듈로 들어가면 중단점 만날 때까지 쭉 수행합니다.

중단점부터 라인 하나 하나 씩 실행하고 중단점이 없어도 라인마다 끊김니다.

A 모듈이 B 모듈 함수를 호출해서 B 함수가 수행되다가 끝나기 직전에 이걸 누르면 A가 B 모듈을 호출하고 끝난 직후로 넘어갑니다. 원래 맨위에 버튼의 경우 호출 끝나면 중단점까지 쭉 가고 중단점 없으면 종료됩니다. 위 버튼들을 적절히 섞어 사용하면 유용할 것 입니다.
4) watch
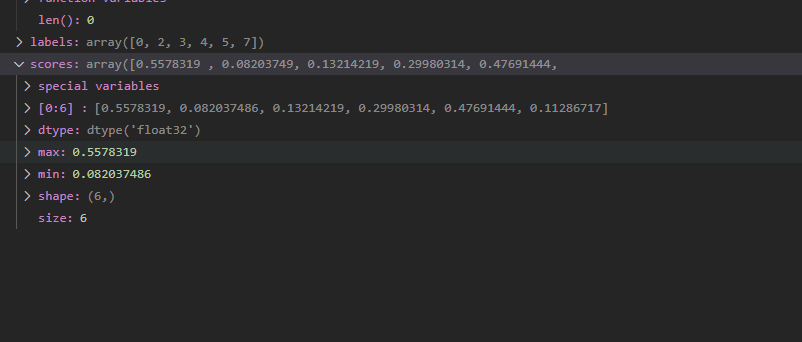
위처럼 보고 싶은 변수가 있으면 디버깅을 진행하면서 변수에 대입되는 값을 볼 수 있습니다.
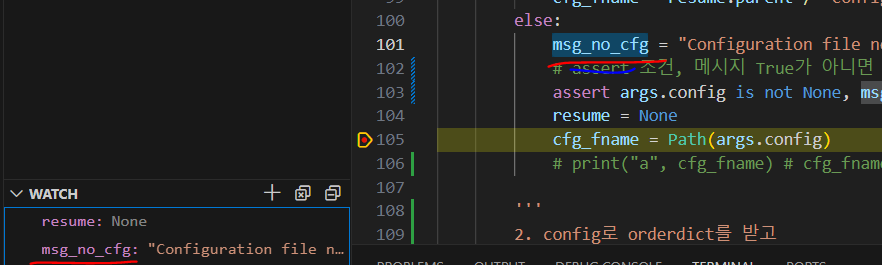
디버깅 되는 순간에 원래 없던 변수를 추가해도 바로 적용됩니다.
5) variable
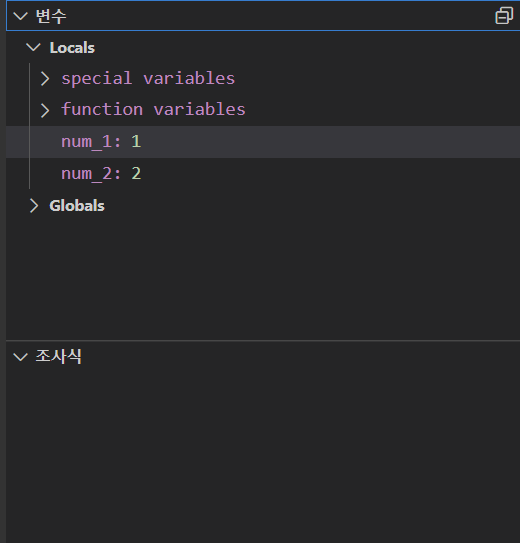
변수 윈도우에서는 변수를 직접 수정할 수 있으며 수정한 변수는 중단점 이후 실행부터 적용됩니다. 지역변수와 전역변수 모두 확인 가능합니다. 디버그 모드 도중 변수 위에 마우스를 올려도 변수에 대한 확인이 가능합니다.
- 느낀점
1) 교수님께서 demo와 image.py를 돌려봐서 결과 이미지가 저장되는 것을 보고 모델 출력값을 예상해 보라고 하셨는데 그 이유를 이해할 수 있었습니다.
2) 어떠한 어려운 모델이라도 모델 입출력을 찾으면 인사이트를 얻을 수 있으니 dataloader랑 result = model처럼 모델 선언하는 곳이 어디에 있나 유심히 찾아보면 됩니다.
3) 교수님께서 모델 출력이 행렬로 나올 것이라고 했는데 그 값이 result에 담겨있었고 result 변수를 디버깅을 통해 파헤쳐 다차원 행렬의 결과값을 이해할 수 있었습니다.
4) 프로젝트에 모델을 학습시키고 추론하려면 모델 이해가 100% 되어야 하는데 이번 기회에 그 어떤 모델도 이해할 수 있을 것 같습니다.
5) 이제 coco.py를 이해하였으니 custom.py를 돌려볼 때 coco.py의 결과와 비교하면 이해하기 수월할 것입니다.
참고
'[인턴] > [Annotation-AI]' 카테고리의 다른 글
| 네 번째 미션(한국어 ChatPDF 개발) (0) | 2023.05.21 |
|---|---|
| 직무교육 (0) | 2023.04.05 |
| 세번째 미션(koalpaca, kobert 다양한 task 조사 및 학습) (0) | 2023.03.29 |

