
개발자로 후회없는 삶 살기
세번째 미션(koalpaca, kobert 다양한 task 조사 및 학습) 본문
서론
현재 진행하고 있는 koalpaca와 별도로 kobert를 조사하라는 임무를 받았습니다. kobert는 임베딩 모델 위주로 알아보라 하셨습니다. 이를 조사하고 학습한 과정을 정리하고 발생한 이슈를 적습니다.
본론
1. kobert 임베딩 task
2. kobert-koquard MRC task
3. kobert 다중 분류 task
4. koalpaca 환경 구축
5. koalpaca 학습 데이터 구축
6. koalpaca 훈련 및 이슈
- kobert 임베딩 task(참고 1)
etri의 kobert를 fine tuning한 모델입니다. 임베딩과 관련된 task를 할 수 있습니다.
1) 문장 유사도
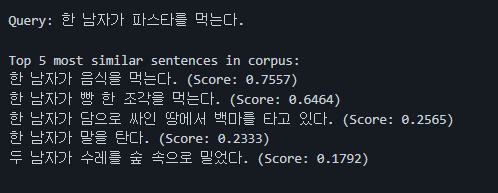
2) Clustering

- kobert-koquard MRC task(참고 2)
처음에는 koquard beginner로 하려고 했지만 tf 1.x를 사용하여 현재 NHN의 CUDA, CUDNN을 맞추기 힘들다고 판단하였습니다. 따라서 tf 2를 사용하는 위 모델을 사용했습니다.


왼쪽 사진으로 학습환경을 구축하고 오른쪽 학습 명령어를 실행합니다. 모델 타입을 kobert로 하여 지정하고 modal_name_or_path를 monologg/kobert로 하여 허깅페이스에서 다운받습니다.

학습 데이터는 KorQuAD_v1.0로 하였습니다.

MRC 기계독해 모델로 주어진 지문에서 질문을 하면 답변을 하는 task를 목적으로 학습합니다.
=> 결과


- kobert 다중 분류 task(참고 3)

skt의 네이버 댓글 감정 분류 튜토리얼입니다. 참고 링크에는 bert로 감정 분류 데이터를 학습시키는 방법이 담겨있습니다.
- 발생한 이슈
1. 우분투에서 용량 100% 차는 이슈
허깅 페이스의 from_pretrained 모델을 load하는 과정에서 우분투 용량이 초과했다는 에러 메세지를 받았습니다. 따라서 용량을 비우기 위해 어떤 파일을 삭제해야 하는지 알아보는 것이 필요했습니다. 윈도우의 경우 다운받은 경로를 설정할 수 있고 알기 쉬우니 휴지통으로 보내면 되는데 GUI가 아닌 리눅스이고 또 이런 경우가 처음이라서 정리합니다.
1) 허깅 페이스 모델이 우분투 어디에 저장되나 보기
처음에는 허깅페이스 모델이 따로 저장되는 것이 아닌가 하여 알아보기로 했습니다. ~/.cache/huggingface/hub에 저장되었고 해당 폴더의 용량을 알아보니 별로 차지하지 않았습니다. du -hs * 명령어로 현재 dir에 용량을 알아볼 수 있습니다. 따라서 다른 용량이 큰 파일이 있을 것이라고 생각했습니다.
2) 가상환경 용량 보기
가상환경이 저장된 /home/ubuntu/anaconda3/env에 들어가서 용량을 봐도 별로 안 먹었습니다.
=> 해결
용량이 없을 때 해결하는 방법을 알게되었습니다. /home에서부터 시작해서 하나씩 의심되는 폴더의 용량을 찾아보면 됩니다. 보니 그냥 /home에 많은 것을 다운 받아서 였습니다. NHN은 200G를 제공한다고 했고 대용량 파일은 /home이 아니라 /data에 저장하라고 했었습니다. 근데 지금 저를 비롯한 인턴들과 R&D 팀이 하나의 NHN 서버를 이용하니 그저 공간이 부족한 것이었습니다. 이번 기회로 클라우드를 사용할 때 왜 /data에 대용량을 주고 거기에 저장하라는 것인지 알게 되는 계기가 되었습니다.
2. 멀티 GPU 학습

학습하려고 하는 kobert-koquard를 아무 생각없이 python train.py로 실행하면 멀티 GPU에러가 발생하였습니다. cuda_visible_devices = 2 python train.py 이렇게 하면 GPU의 번호와 개수를 지정하여 학습할 수 있습니다. NHN은 T4 8개를 주기에 사용하지 않는 2번을 지정하여 학습을 성공하였습니다.
- koalpaca 환경 구축
※ 이 포스팅은 다음 koalpaca 레포지토리를 분석하고 직접 실습한 내용을 기반으로 작성되었습니다.
https://github.com/Beomi/KoAlpaca
GitHub - Beomi/KoAlpaca: KoAlpaca: Korean Alpaca Model based on Stanford Alpaca (feat. LLAMA and Polyglot-ko)
KoAlpaca: Korean Alpaca Model based on Stanford Alpaca (feat. LLAMA and Polyglot-ko) - GitHub - Beomi/KoAlpaca: KoAlpaca: Korean Alpaca Model based on Stanford Alpaca (feat. LLAMA and Polyglot-ko)
github.com
1. 가상환경 셋팅

koalpaca는 alpaca의 파생으로 3.9+ 버전으로 돌아갑니다.
2. 훈련 소스 및 모델 가져오기
해당 레포지토리(참고 4)에서 훈련 소스를 가져오고 requirements로 학습 환경을 구축합니다.

23.03.28 기준, 기존 transformers 패키지에는 llama 관련 모듈이 없어 수정버전을 받아야 합니다.

허깅페이스 모델 저장소(참고 5)에서 모델 파일을 가져옵니다.

이를 NHN T4 환경에 구축하기 위해 /data 폴더에 다운받았으며 llama 모듈 내에 네이밍 오류로 LLaMA 를 Llama 로 소문자로 수정해주어야 합니다.

훈련 sh을 설정합니다. nproc_per_node로 할당 GPU 개수를 잡고 모델 경로를 다운로드한 모델 경로로 합니다. 현재 잡힌 GPU가 T4인데 이는 bf 방식을 지원하지 않아서 bf16을 fp16으로 수정합니다.
- koalpaca 학습 데이터 준비
기본적으로 Alpaca에서 제작한 데이터 셋을 기반으로 합니다.
1. 데이터 셋 번역

알파카 데이터셋은 다음과 같이 instruct, input, output으로 구성됩니다.
1) instruct: 실제 질문,
2) input: 답변을 위한 사전 정보,
3) output: 대답
레포지토리 저자분은 alpaca 데이터 셋을 한국어로 번역하여 koalpace 데이터 셋을 만들었습니다.

이때 output은 번역하지 않았는데 OpenAI의 ChatGPT를 통해 답변 데이터를 생성하였습니다.

완성된 데이터는 위와 같습니다.
- koalpaca 훈련 및 이슈
훈련 코드에 wandb를 사용한 부분이 있으므로 이후 이슈 부분에서 다루겠습니다.
1. 오류 발생

model을 GPU로 로드하면서 OOM이 발생하였습니다.
2. 오류 분석

koalpaca 레포지토리 저자의 환경은 Llama 7B를 모델로 학습할 때 A100 80GB 4대를 사용했습니다.

제 환경은 T4 16GB 8대 중 4대만 활용 가능했고 총 256 GB의 메모리가 부족했습니다. 따라서 GPU로 모델 로드 시 Vram공간이 끝까지 차다가 멈춰 용량 초과로 인한 훈련 불가 상태가 됩니다. 따라서 GPU Memory가 A100 80GB인 환경에서 확인된 오픈 소스이므로 해당 환경과 비슷하게 맞춰야 해결할 수 있습니다.
참고
'[인턴] > [Annotation-AI]' 카테고리의 다른 글
| 네 번째 미션(한국어 ChatPDF 개발) (0) | 2023.05.21 |
|---|---|
| 직무교육 (0) | 2023.04.05 |
| 첫 번째 미션(Mmdetection 결과로부터 Top-N Accuracy 추출) (0) | 2023.03.08 |

