
개발자로 후회없는 삶 살기
SW bootcamp PART.팀 Project 3주차(모델 학습, 추론) 본문
서론
팀 프로젝트 3주차 내용입니다.
본론
- 중간 점검 및 피드백
=> 2.15 중간 발표 점검 및 피드백
1) 모델을 서비스에 활용하기 위해서는 서버와 프론트에 모델을 올려보고 테스트 해보는 것을 되도록 빨리 해봐야한다. 현재 아무팀도 모델 올려보는 테스트를 안 해봤는데 올려보면 많은 에러가 발생할 것이고 그것을 처리하는 것이 제일 관건일 것이다.
2) 우리 팀은 모델을 서버가 아닌 프론트에 직접 이식하는 것을 발표에 강조하라 이 부분이 다른 팀과 차별점이 될 것이다.
- 타임라인


마지막 주 회의와 함께 타임라인을 정했습니다. 저는 모델 학습을 마무리하고 ML 파트 발표 준비를 합니다.
- 모델 비교
1. Affectnet


특징 : 장점이 없고 정확도가 65%
2. Landmark using CNN



특징 : cnn만 사용한 것이 아닌 랜드마크와 hog로 feature를 추출한 모델, 정확도 76%
3. Medium using CNN



특징 : 튜닝하지 않은 정확도가 70%이고 학습 데이터를 바꿔서 진행하기 용이함. 하지만 랜드마크나 hog등 데이터에서 특징을 추출하는 포인트가 없어서 모델에 멋이 없음
=> 결론 : official 모델들이 눈에 띄는 기술들을 사용하지만 정확도에는 큰 차이가 없습니다. 3번의 경우 더 많은 데이터로 학습을 하면 정확도가 증가할 가능성이 있기에 3번으로 결정하였습니다. 하지만 너무 밋밋하니 cnn이 아닌 efficientnet으로 백본을 바꾸고 기분 추출 알고리즘에 랜드마크 기술을 넣을 예정입니다.
+ 또한 프레임 단위로 시간에 따른 가중치 알고리즘을 구현하여 모델 예측 결과에 신빙성을 높일 것입니다.
- 모델 고도화
이제 모델도 완벽히 정해졌고 고도화하는 작업만 남았습니다. 따라서 해야할 일은 다음과 같습니다.
1. 한국 데이터로 학습
서버 gpu로 모델을 돌리기 전에 aihub 데이터 셋을 전처리 해야합니다. 또한 기존에 사용했던 백본을 일반 cnn으로 하지말고 aihub를 참고하여 efficientnet으로 변경하는 것도 필요합니다.
1) 전처리
① 라벨 데이터와 원천 데이터 맵핑
용량이 매우 큰 데이터로 작업을 진행하는 것이 처음이라 매우 어려웠고 하드웨어 장비의 지원도 상당히 많이 필요했습니다. 현재 제 노트북에 C 드라이브에 용량이 없어서 매우 곤란한 상황이었는데 데이터는 D에 있어도 상관없다는 것을 알게되었습니다.
> 하지마 제 노트북은 D드라이브도 용량이 없어서 서버 노트북의 D 드라이브에 저장하였습니다. 이제 저장한 데이터를 wsl로 옮겨서 진행해야합니다.
> 여기서 발생한 문제!! : wsl은 윈도우 소프트에어로 C드라이브를 차지합니다. 따라서 wsl의 프로젝트 폴더에 D에 저장한 데이터를 옮기는 순간 C 드라이브가 부족한 것이 됩니다.
> 이걸 해결한 방법은 그냥 D 드라이브에 풀고 학습할 때 wsl에서 D에 접근하는 것입니다. wsl에서 윈도우에 zip을 풀려면 관리자 권한이 있어야했고 윈도우에서 C의 wsl 폴더의 내용을 처리할 때도(삭제하거나 등등) 권한이 필요한 것을 알게되었습니다.
> 이렇게 준비된 데이터를 np 형식으로 바꾸고 저장하려고 했습니다. 하지만 np로 바꾸는 과정에서 시스템 RAN Killed가 뜨면서 터져버립니다.
file_path = glob.glob("/mn/emo/한국인 감정인식을 위한 복합 영상/Training/*/*.jpg")
독립 = np.array([plt.imread(file_path[i]) for i in range(len(file_path))], dtype = object)
종속 = np.array([file_path[i].split('/')[-1][:2] for i in range(len(file_path))], dtype = object)
print(종속)저는 지금까지 이미지를 np로 만들 때 이 코드를 사용하였는데 데이터의 개수가 97000장에 사이즈가 각각 1MB이니 RAM이 버티질 못하였습니다.
=> 해결하기 위한 고민
하나, find 명령어를 사용하여 10만장의 데이터를 5만장으로 줄입니다. > 하지만 이 후 똑같이 터져버립니다.
둘, 얼굴 crop > 밑에서 다루겠습니다.
② 얼굴 crop
학습을 시키기 위해 안드로이드와 프론트 개발자 분들에게 lite한 얼굴인식 모델이 필요하다고 말씀드렸고 프론트에서 얼굴 인식에 성공하여 모델 학습과정에서도 얼굴 crop이 필요하게 되었습니다.

> 분명 1MB보다는 작은 이미지가 생기겠지만 그래도 C 드라이브의 용량이 버틸 수 없었고 이것을 wsl에서 하기 위해서는 D에 cropTraining이라는 폴더를 만들고 감정별 하위 폴더를 만든 후 crop한 이미지를 다시 저장하는 방법을 사용해야합니다.

> crop 결과 얼굴만 잘 잡히지 않아서 인자를 조절해보니 minSize를 200으로 두니 얼굴이 아닌 것은 무시하도록 crop이 잘 되었습니다.



> crop된 결과 이미지는 얼굴마다 사이즈가 달라 각기 다른 w, h를 보입니다. 따라서 resize를 하고 새로운 폴더 cropResizeTraining에 저장하였습니다. 그 결과 처음 원본이미지의 경우 폴더 하나당 15G였던 것에서 7G로 줄었습니다.
③ 이미지를 모델에 맞게 numpy 형식으로 변환
불행히도 이 상태에서 넘파이 형식으로 변환하려고 해도 RAM이 터졌습니다. nvidia-smi를 해봐도 GPU %가 올라가지 않고 GPU를 사용하지 않았습니다. 강사님께 여쭤보니 GPU는 학습에 사용하는 것이고 numpy를 사용한다고 해서 gpu를 쓰는 것이 아니며 jpg를 위 코드처럼 하나의 넘파이로 꽉 뭉치지 말고 jpg를 데이터 하나하나봐서 그때 그때 batch로 불러서 쓰고 RAM을 빼줘야 한다고 말씀해주셨습니다.!!
> 그렇게 해서 사용한 것이 tf data api(참고 6)입니다. 이제 성공한 내용에 대해 정리해보겠습니다.
-> 시도한 것
하나, 코랩 프로 플러스 사용
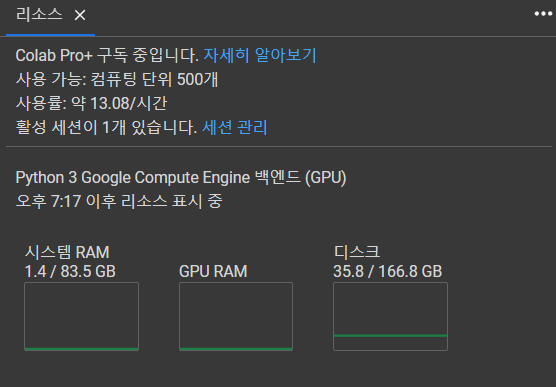

어느 한 강사님께서 RAM이 부족한 거면 코랩 프로 플러스로 해보라고 하셨지만 어마 무시한 피지컬의 코랩 프로 플러스도 위의 코드는 극복하지 못했습니다.

위 사진을 보면 엄청난 코랩 프로 플러스의 피지컬로 넘파이로 만드는 것까지는 성공했지만 train_test_split을 하는 순간 또 터져버립니다.
+ 다른 강사님께서 데이터가 크다고 코랩 프로 플러스를 사용하는 것은 좀 아닌 것 같다며 알려주신 내용이 tf data api입니다.
둘, tf data api
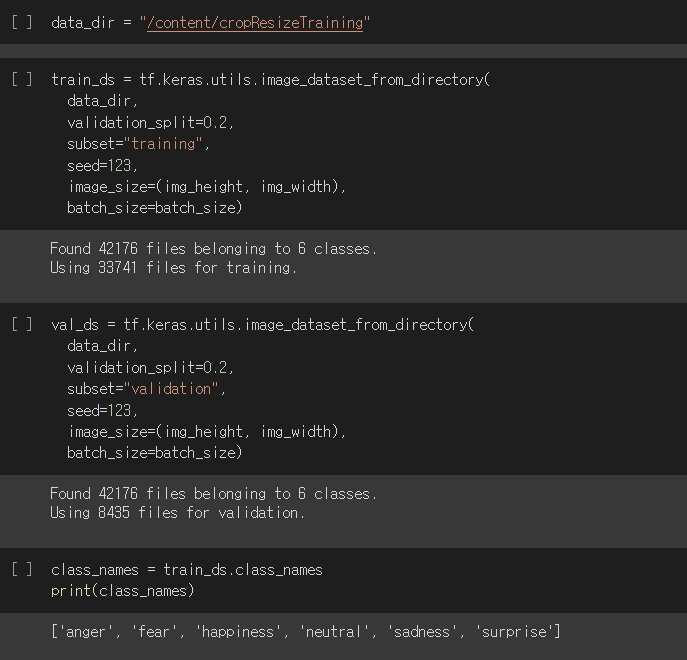
강사님께서는 딥러닝 기초를 공부할 때는 데이터의 크기가 작으니 위 코드처럼 numpy를 뭉쳐도 버티지만 이후에는 이 방식을 사용해야 한다고 알면된다고 말씀해주셨습니다.
-> 이때 발생한 에러 종류는 다음과 같습니다.
1: tf dataset api쓰면 compile에 categorical이 아니라 sparse를 써야한다.
2 : oprimizer에 optimizers가 두개면 안된다.
3 : fit에 steps_per_execution이라고 있는데 default로 두어야합니다.
=> 성공


이렇게 했더니 비로소 학습에 성공하였고 모델 정확도는 87%입니다.
④ inference


추론 결과 높은 정확도처럼 잘 예측하는 것을 알 수 있었습니다!
-> 느낀점
RAM이라는 컴퓨터 구조에 대해 알게되었습니다. 인공지능을 하려면 하드웨어가 기반이 되어야하는데 그 중 RAM을 배운 내용을 생각해보면 주기억장치였고 드라이브에서 데이터를 불러와서 연산을 하는 처리 공간이었습니다. 즉 처리를 하는 동안에는 RAM에 저장되며 기다린다고 해서 부하가 줄어드는게 아닌 처리가 끝나야 공간이 생깁니다. np를 만들 때 (50000, 256, 256, 3)의 데이터를 계속 처리하고 끝내질 않으니 RAM이 가득차서 터져버리는 것을 알게되었습니다.
> 따라서 ★ tf data api 마스터가 되어야합니다!!
2) efficientnet
efficientnet은 최근 가장 정확도가 높은 분류기이기도 하고 aihub 데이터 제공측에서도 efficientnet을 활용하였다고 하여 시험하기로 했습니다. 실험결과 기존 cnn보다 과적합이 빨리 왔고 한국 데이터로 학습을 해야 알 수 있을 것 같습니다.
2. 감정 분류 고도화 + 시간에 따른 표정 변화 통계 알고리즘
이 파트는 시간 관계상 프로젝트에 구현하지는 못했지만 디벨롭을 어떻게 할지에 대한 pt 전체 스토리를 만들기 위한 것입니다.
1) 시간에 따른 표정 변화 통계 내기(참고 1, 2)

일단 팀원들과 정한 시간에 따른 기분 예측 알고리즘은 감정 변화를 인식하면 기분을 예측해서 노래 추천을 하고 노래를 틀 동안은 감정 인식을 잠시 중지하였다가 끝나면 다시 인식을 재게하는 것입니다. 일단 이것을 목표로 잡고 테스트하기로 하였습니다.(모델에 전적으로 의지하는 알고리즘)
-> 추가 나만의 알고리즘
프레임 단위로 모델에 이미지를 입력하면 6개의 감정의 %가 프레임 개수만큼 나올 것이고 위 그래프처럼 나타낼 수 있습니다. 이것을 논문(참고 2)에 나온 수식을 활용하여 해당 프레임에서 느껴지는 감정을 뽑아내는 알고리즘으로 목표 알고리즘을 테스트하였는데 성능이 별로라는 생각이 들면 제 알고리즘을 새롭게 적용할 것입니다.
+ 프레임 단위를 수식에 적용할 프레임의 개수라고 정하고 그 만큼 이미지를 뽑아 감정을 계산한 후 노래를 추천하고 노래를 듣는 동안에는 감정인식을 중지했다가 노래가 끝나면 같은 과정을 반복하는 것을 생각하고 있습니다.
2) landmark using cnn(참고 3)
최종 선정한 모델로 학습까지 완료하였으며 논문을 읽고 발표에 담아내기로 했습니다.
3. facial using cnn 학습 완료
1) 가상환경 만들기
2) fer2013 서버 로컬에 다운받고 wsl로 옮기기
3) dlib face detector 다운
4) 필요 라이브러리 설치
5) convert 이미지
6) training
7) predict
8) hyper tuning
9) predict
-> 정확도 76로 일반 분류기와 별차이가 없었습니다.
4. lite한 얼굴 탐지 모델 찾기
tfjs, lite 모델을 찾았고 리엑트와 안드로이드에 적재하였습니다.(참고 4)
5. wandb 사용

저는 주로 tensorflow 모델을 사용하지만 이번 모델은 keras 모델이므로 wandb keras 공식 문서를 참고했습니다.(참고 5)
결론
이렇게 모델 학습까지 완료했고 프로젝트에서 AI 파트가 끝이 났습니다. 발표에서 제가 구상한 것을 뽐내고 성공적으로 마무리 하겠습니다!
참고
'[대외활동] > [네트워크형 캠퍼스 아카데미]' 카테고리의 다른 글
| SW bootcamp PART.마무리 (0) | 2023.02.24 |
|---|---|
| SW bootcamp PART.서버 원격 접속 + 로컬 GPU 연결 (0) | 2023.02.11 |
| SW bootcamp PART.팀 Project 중간 점검 (0) | 2023.02.09 |
| SW bootcamp PART.팀 project 2주차(모델 조사, 선정) (0) | 2023.02.05 |
| SW bootcamp PART.팀 Project 1주차(팀 빌딩, 주제 브레인스토밍) (0) | 2023.01.31 |


