
개발자로 후회없는 삶 살기
Augmentation PART.albumentation 활용 본문
서론
albumentation를 사용해야하는 이유와 다양한 활용 방법을 알아봅니다.
본론
- albumentation 장점

albumentation 토치 비전보다 빠르고 종류도 많고 탐지나 세그먼트 데이터에도 증강을 적용할 수 있습니다.
def _transforms(self):
return A.Compose([
A.RandomResizedCrop(height=150, width=300, scale=(0.3, 1.0)),
A.Resize(100, 100),
ToTensorV2()
])또한 사용 방법도 토치 비전과 동일해서 기존 코드에 바로 적용할 수 있습니다. A.Compose로 토치 비전과 동일하게 증강을 적용하기 위한 객체를 생성합니다.
image = Image.open(self.file_paths[index])
image = np.asarray(image) / 255.
image = self.transform(image = image)["image"]정의한 증강 객체를 이미지에 적용하고, ["image"]으로 증강된 이미지를 바로 얻을 수 있습니다. image에 해당하는 데이터를 단순히 넘겨주기만 하면 data가 변경됩니다.

이 점이 바로 albumentation의 핵심이라고 말할 수 있습니다.
- 파이토치에서 사용 방법
def _transforms(self):
return A.Compose([
A.RandomResizedCrop(height=150, width=300, scale=(0.3, 1.0)),
A.Resize(100, 100),
A.OneOf([
A.VerticalFlip(p=1)
], p = 0.5),
ToTensorV2()
])파이토치에서 사용하려면 증강이 적용된 데이터를 torch로 변환해야 합니다. ToTensorV2를 마지막에 추가하여 torch 타입으로 변환할 수 있습니다.
=> 다양한 조합 방법
보통 List에 담아서 사용할 수 있지만, 보다 다채롭운 기법들을 알아봅니다.
1) OneOf
OneOf는 List에 있는 방법 중 하나를 적용합니다. 이때 선택 확률을 상세하게 정할 수 있어, 해당 augmentation이 선택 될 지 말 지를 확률로 줄 수도 있습니다.
OneOf([
HorizontalFlip(p=1),
RandomBrightness(limit=0.2, p=1),
]아무값도 주지 않으면 해당 그룹 중 하나를 무조건 증강에 사용하는 데 동일 확률로 그룹 요소 중 하나를 선택합니다.
OneOf([
HorizontalFlip(p=1),
RandomBrightness(limit=0.2, p=1),
], p=0.2),p를 주면 이 그룹 중 하나를 무조건 선택하는 것이 아닌 p 확률로 그룹을 선택할 지 말 지 결정합니다. 따라서 해당 그룹의 증강을 아예 적용하지 않을 수 도 있습니다. 이 코드는 80%의 확률로 원본 상태를 유지하고, 20%의 확률로 두 증강 중 하나를 수행하며, 1/2의 확률로 수평으로 뒤집히며, 다른 1/2의 동일 확률로 무작위로 밝기가 조정됩니다.
2) AutoAug
"AutoAugment: Learning Augmentation Strategies from Data”
AutoAug는 "데이터로부터 증강 전략을 학습한다."라고 소개하며, 자동으로 데이터의 크기와 타입을 선택하도록하는 것을 목표로합니다. 또한 강화학습을 사용하여 효과적인 증강 기법을 찾는다.
-> Search Space
Search Space는 5개의 하위 증강 정책이 포함되어 있으며, 각 sub_policy에는 크기와 확률 매개변수를 갖는 두 개의 증강 기법이 있고 이 하위 정책들은 증강 순서에 민감합니다. 16개의 증강 기법 중에서 선택하며 각 기법의 크기와 확률 매개변수는 각각 10개와 11개의 균일한 간격 값으로 분할되어 있습니다.
-> Search algorith
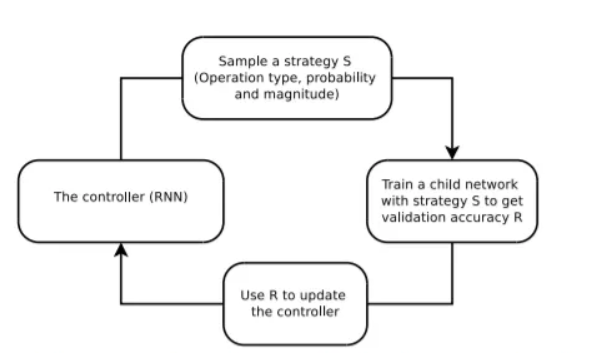
검색 알고리즘은 RNN 컨트롤러와 학습 알고리즘 2개로 이루어져 있고 이를 Proximal Policy Optimization algorithm. 이라고 부릅니다. RNN은 증강 기법을 Search Space에서 찾고 이 기법들로 child model을 학습시키는데 이 하위 모델이 예측된 5개의 하위 정책으로 생성된 증강 데이터로 훈련됩니다. 그리고 하위 모델이 RNN 컨트롤러를 학습하기 위한 보상 신호로 사용됩니다.
-> 결과적으로 ✅
AutoAug는 지금까지의 자동 증강 기법 중 가장 좋은 결과를 보였습니다. 하지만, 큰 컴퓨터 사양에 의존합니다.
3) RandAug
"Practical automated data augmentation with a reduced search space"
RandAugment은 과감하게 ss를 줄여 훈련 절차의 계산 부하를 완화시킨 증강 기법입니다. 해당 모듈은 2개의 파라미터 (N, M)를 가지고 이를 학습 과정에서 자동으로 튜닝합니다.
-> Search Space
N개의 기법 중에서 균등 분포로 학습 기법을 고릅니다. RandAug에서 사용하는 균등 확률 접근 방식은 샘플의 다양성을 유지하면서 공간을 줄입니다. 또한 기법에 적용할 크기의 변환 범위를 M으로 제어하는데, 이는 증강을 위한 최적의 크기가 모델 및 훈련 세트의 크기에 따라 달라지며, 더 큰 네트워크에는 더 큰 데이터 왜곡이 필요하기 때문입니다.
-> Search algorith
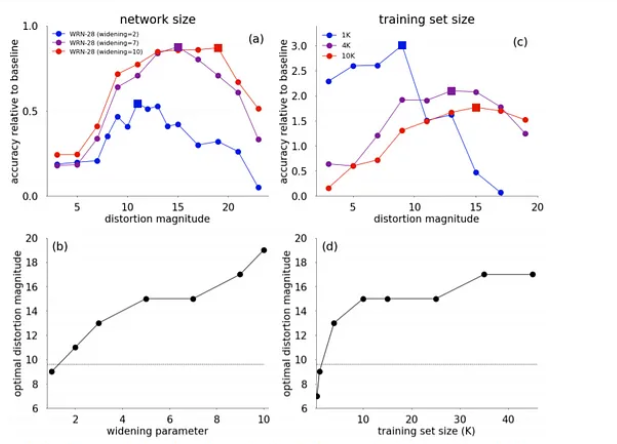
RandAugment는 최적의 N과 M을 찾기 위한 grid search를 합니다. 결과적으로 검증 셋에서 최고의 성능을 보이는 검증 기법 조합을 찾습니다.
=> RandAugment 구현

위에서 배운 것처럼 변환 정도에 대한 Search Space가 있습니다.

또한 기법에 대한 SS가 있어 모델 학습 동안 M에 대한 변환 정도를 N개의 샘플링된 기법에 적용하여 최적의 기법 조합을 찾습니다. 후보가 될 수 있는 기법은 사용자 마음대로 지정하면 되고 albumentation을 그대로 사용할 수 있습니다. 하지만, 주의할 점은 모든 프로젝트와 모든 데이터마다 테스크에 맞는 알고리즘으로 조정되어야 합니다.
-> 학습에 적용

학습 시에 randAug를 적용하여 증강을 샘플링합니다.

M은 학습을 통해 조정되는데 이미 결정된 M에 대해 에폭 정확도가 검증 세트의 최고 정확도보다 낮을 때마다 M이 증가합니다. 이때 정확도와 최고 정확도의 차이 비율로 조정값이 결정됩니다. 하이퍼 파라미터 N과 M 그리고 적용할 수 있는 증강 기법을 변경하면서 테스트를 해보면 좋을 것입니다.
※ 깃허브 코드
실험 후 기재할 예정입니다.
-> 랜덤으로 어떤 기법이 선택됐는 지 추적할 수 있어야 하나요? 🚨
아닙니다. 추론 단계에서는 RandAug로 만들어진 여러 모델 중 top-k acc의 모델을 앙상블해서 사용합니다. 또한, 데이터 증강은 학습 단계에서만 사용하고 추론에서는 사용하지 않아서 어떤 기법을 조합했는 지 알 필요가 없습니다.
'[AI] > [딥러닝 | 이슈해결]' 카테고리의 다른 글
| [최적화] GPU 풀 구현기 2 (0) | 2024.01.12 |
|---|---|
| MMLab PART.커스텀 파이프라인 제작 (0) | 2024.01.09 |
| [최적화] GPU 풀 구현기 1 (0) | 2023.12.09 |
| Pytorch PART.데이터 로더, 폴더 활용(Collate, Sampler 등) (0) | 2023.12.04 |
| [최적화] 유연하게 확장 가능한 AI 학습 환경 구축 (0) | 2023.12.04 |



