
개발자로 후회없는 삶 살기
MMLab PART.커스텀 파이프라인 제작 본문
서론
MMdetection을 이용해서 convnext 백본 cascade rcnn 모델 학습 파이프라인을 제작하는 과정을 공유합니다.
본론
- mmdetection/configs에 config 파일 만들기
python tools/train.py \
${CONFIG_FILE} \
[optional arguments]학습을 할 때 config 파일을 인자로 주기 때문에 config 파일을 커스터마이징하면 원하는 동작을 수행할 수 있습니다.

faster_rcnn r50의 config 파일입니다. faster_rcnn은 위 4개의 파일로 학습을 진행하며 각 파일을 수정하면 됩니다.
주의사항 🚨
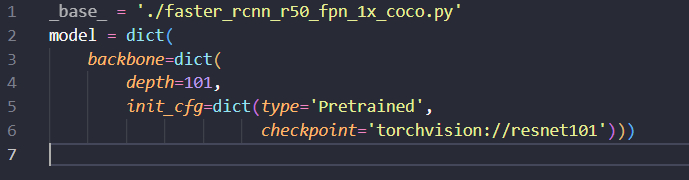
faster_rcnn r101 같은 경우는 r50의 config를 베이스로 재정의할 수 있습니다. 재정의를 할 경우 mmdetection 프레임워크 형식에 맞게 구현이 되어 있어야 합니다.
-> 커스텀 config 파일 제작

기존에도 3개의 convext를 사용하는 config가 있습니다.

resnet을 사용하는 config를 보면 faster rcnn과 동일하게 coco_detection과 스케쥴러를 사용하고 있고 모델만 변경해 주었습니다.

저는 convnext를 사용할 것이기 때문에 faster_rcnn r101 config처럼 재정의 해줄 것입니다. config에서 사용할 4개의 파일은 아직 만들지 않았기에 base는 비워두고 백본 모델만 재정의 합니다.
- _base_/models 모델 만들기

기존에는 resnet을 사용한 모델들이 정의되어 있습니다. 여기에 convnext를 백본으로 사용하는 cascade rcnn 모델을 만들 것입니다.

mmlab 프레임워크에 맞는 형식으로 모델을 정의해야 사용할 수 있습니다. 모델의 타입, 백본, nect 등을 형식에 맞게 정의합니다.
- mmdetection/configs/_base_/datasets coco_detection

사용하는 데이터 셋은 faster_rcnn과 동일하게 coco_detection으로 탐지 문제에 맞는 데이터 셋을 사용합니다. 이 부분도 목적에 맞게 재정의하면 원하는 데이터 셋을 만들 수 있습니다.
주의 🚨

아직 main에 merge 되지 않은 최신 모델의 경우 위 경로의 파일을 수정해야 할 수도 있습니다.
- _base_/schedules 수정

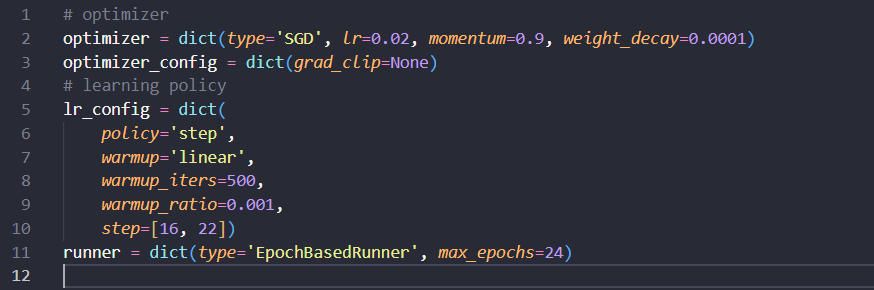
기본으로 사용하는 스케쥴러는 _2x입니다. 이 부분을 수정하면 최적화함수, 스케쥴러, 에폭을 수정할 수 있습니다.

저는 Adam을 사용하도록 수정해 주었습니다.

이제 처음에 만들어 놓은 config에 모아주면 셋팅이 끝납니다.
- tool/test.py 컴파일
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=1000 ] = -1.000
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=1000 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=300 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=1000 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = -1.000test를 했는 데 이런 결과가 나올 때가 있습니다. 이때 테스트 데이터 셋이 제대로 들어가는 지, 어디가 잘 못 된건지 컴파일하는 방법을 알아보겠습니다.
1. 테스트 데이터 지정
python tools/test.py \
configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py \
./faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
--eval bbox위 테스트 명령어에 테스트 데이터 셋을 따로 명시해야 할까요? 아닙니다.

config에 경로가 명시되어 있어서 val set을 구축할 때와 같이 json만 잘 만들면 됩니다.
2. test 파이프라인 추적
1) tool/test.py를 실행
2) mmdet/apis/test/single_gpu_test 실행
3) 그 결과를 가지고 tool/test에서 mmdet/datasets/coco/COCOdataset의 evaluate실행
4) 동일 파일에서 evaluate_det_segm 실행
5) evaluate_det_segm에서 그 결과를 log로 남김
위 과정을 다 디버깅하면서 텐서가 제대로 나오나 확인하는 과정이 필요할 수 있습니다.
3. test.json 경로에 train.json 넣어보기

3번 과정을 가장 먼저 해봐야 합니다. -1이 나오는 이유는 실제로 하나도 탐지를 못 했을 때입니다. 따라서 train.json을 넣었는 데 점수가 나오면 위에 과정은 다 잘 되는 것이고,
학습에서 일반화 성능이 떨어지는 것 뿐입니다. 따라서 더 학습 파이프라인을 사용해야 합니다. 또한 학습 과정에서도 val set을 만들기 전이라 test.json을 넣은 적이 있었는 데 그때도 -1이 나오는 것은 정말 탐지를 못 하는 것이었단 것을 알게 되었습니다. 반드시 val set을 만들어야겠습니다.
결론
mmdection을 활용하여 원하는 학습 파이프라인을 만들어 보았습니다. 프레임워크 형식으로 정의만 되어 있다면 원하는 모델을 자유자재로 학습할 수 있는 강력한 기능입니다.
'[AI] > [딥러닝 | 이슈해결]' 카테고리의 다른 글
| [최적화] 학습 속도 개선(AMP, Prefetch) (0) | 2024.01.18 |
|---|---|
| [최적화] GPU 풀 구현기 2 (0) | 2024.01.12 |
| Augmentation PART.albumentation 활용 (2) | 2023.12.19 |
| [최적화] GPU 풀 구현기 1 (0) | 2023.12.09 |
| Pytorch PART.데이터 로더, 폴더 활용(Collate, Sampler 등) (0) | 2023.12.04 |



