
개발자로 후회없는 삶 살기
[문법] 실무에서 보통 ArrayList를 쓰는 이유 (동적 배열 원리, Linked와 성능 비교) 본문
서론
※ 아래 내용을 다룹니다.
- 배열
- 리스트
- ArrayList
- 각각의 성능 비교
본론
- ArrayList와 배열의 차이점
배열의 단점 : 동적으로 배열의 크기를 조절할 수 없고, 너무 크게 잡으면 메모리가 낭비된다.
이러한 단점을 극복하는 ArrayList는 배열의 문제점을 해결하고 간편하게 사용할 수 있도록 도와주는 자료구조이다. 직접 간단하게 구현해보면서 실제 ArrayList 클래스 내부 구조를 파악해보자

ArrayList 내부 구현 코드를 보면 Object 배열을 사용하고 기본 크기는 10이다.
🚨 범위를 초과하면 어떻게 될까?

배열을 사용하기 때문에 범위를 초과하면 당연히 OOB 에러가 난다.
- 동적 배열
우리가 원하는 리스트는 동적으로 저장할 수 있도록 크기가 커지는 것이다. 따라서 ArrayList 내부적으로 요소가 초과되면 동적으로 배열 크기를 늘리도록 구현되어 있다.
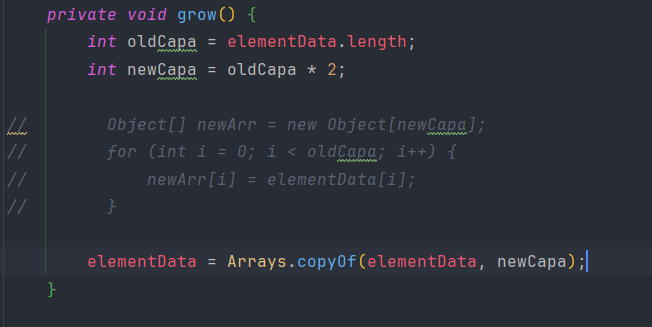

간단하게 구현한 코드는 왼쪽이고 실제 코드는 오른쪽이다. 큰 배열을 만들고 capa 늘리고 기존 배열을 복사해서 넣어버리고, 새로운 배열을 바라보도록 하면 된다.
리스트 : 순서가 있고 중복이 가능한 자료구조
배열 리스트 = ArrayList : 배열을 사용한 리스트
리스트의 정의를 사전적으로 보면 더욱 이해하기 쉽다. 자바에서는 리스트에 제네릭을 적용하여 특정 타입을 명시하며, 제네릭을 사용하지 않으면 Object 배열이라서 정수, 문자열 전부 다 넣을 수 있다. 하지만 인터페이스의 하위 클래스이고 수정도 불가능하여 반드시 제네릭을 사용하여 1가지 타입만 사용하게 된다. (파이썬에서는 제네릭을 적용하지 않아서 다양한 타입을 모두 넣을 수 있다.)
🚨 Object를 제네릭을 하면?
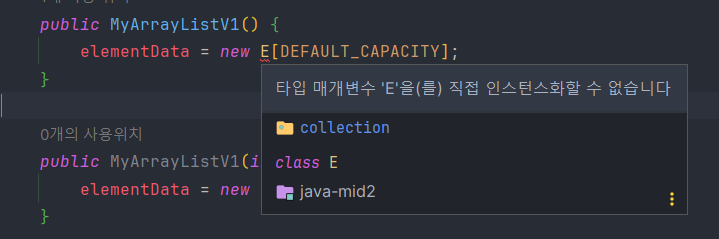
배열을 제네릭으로 하면 타입 safe 하지 않을까? 하지만, 제네릭은 런타임에 타입 이레이저에 의해 지워지므로 제네릭을 생성자에 사용할 수 없다.
- List 자료구조 인터페이스
List는 중복을 허용하고 순서가 있는 자료구조로 ArrayList와 LinkedList는 내부 구조가 달라, 상황 별 성능은 다르지만, 동일한 기능을 제공한다. 실제 사용하는 입장에선 둘을 구분하지 않고 동일한 목적을 이룰 수 있는 것이다. 자바는 List 인터페이스를 두고 ArrayList와 LinkedList를 구현체로 가진다.
-> 의존 관계 주입
부모-자식 관계에서 다형적 참조로 OCP을 이룰 수 있는데, 자료구조에서도 이를 유용하게 활용할 수 있다. 구체적으로 구현된 자식 클래스 보다 상위 클래스인 부모 클래스가 추상화 되어 있다고 해서 추상적인 인터페이스에 의존한다고 표현한다.
public class BatchProcessor {
private final MyArrayList<Integer> list = new MyArrayList<>();
}List를 사용하는 클라이언트 코드에서 new로 생성하면 구체적인 클래스에 의존한다.
public class BatchProcessor {
private final MyLinkedList<Integer> list = new MyLinkedList<>();
}BatchProcessor라는 클래스를 만들고 데이터를 "앞에 추가하는 일이 많은 상황"이라고 가정해보자 그러면 링크드 리스트를 사용하는게 효율적이다. 하지만, 이러면 ArrayList를 LinkedList로 변경할 때 사용한 모든 코드의 변경이 일어난다. 리스트의 맨 앞에 추가하는 성능이 중요한 경우 LinkedList로 변경하기 쉽지 않다.
-> 추상화와 의존관계 주입
public class BatchProcessor {
private final MyList<Integer> list;
public BatchProcessor(MyList<Integer> list) {
this.list = list;
}
}이를 추상적인 List 인터페이스를 의존하고 생성자로 주입 받으면 코드의 변경 없이 구현체를 변경할 수 있다. DIP와 DI를 통해서 OCP를 만족할 수 있다. 어레이 리스트보다 상위에 있어서 더 추상적인 것이라고 표현하고 추상적인 인터페이스에 의존한다고 한다.
✅ 연결 리스트와 배열 리스트의 시간 비교
앞에서 동적 배열 원리에 대해서 알아보았다. 그러면 이제 배열 리스트의 어떠한 점 때문에 실무에서 ArrayList를 가장 많이 사용하는지 알아보자.
-> 배열 리스트 장점
맨뒤에 추가 O1
모든 인덱스 조회 O1
-> 단점
메모리 낭비
중간에 추가+제거 On
처음에 추가+제거 On
배열리스트의 장단점은 대략적으로 위와 같고
-> 링크드 리스트 장점
필요한 만큼만 노드를 써서 메모리 낭비 해결
맨 앞에 추가 O1
맨 앞에 삭제 O1
-> 단점
마지막에 추가 On
조회 On
배열 리스트와 동일하게 중간에 추가+제거 On
링크드 리스트의 장단은 위와 같다. 둘의 내부 구조는 정확히 둘의 단점을 보완하고 각각의 장점은 서로의 단점이 된다. 프로젝트 성격에 따라서 원하는 리스트를 잘 선택해야 한다. 보통 앞에 추가는 연결리스트가 빠르고 나머지는 배열 리스트가 빠르다.
public void logic(int count) {
long startTime = System.currentTimeMillis();
for (int i = 0; i < count; i++) {
list.add(0, i);
}
long endTime = System.currentTimeMillis();
System.out.println("크기: " + count + ", 계산 시간: " + (endTime - startTime) + "ms");
}두 자료구조의 성능 차이는 가장 맨 앞에 추가할 때 제일 크게 차이가 난다. 두 자료구조의 내부 구조 차이에 따라서 배열은 전부 다 한 칸 씩 뒤로 밀어야 하고, 링크드 리스트는 노드만 추가하면 되기 때문이다. (On vs O1) 5만개의 데이터를 맨 앞에 추가하는 코드는 위와 같다.


배열 리스트 : 1초
연결리스트 : 0.0002초
기능은 동일하지만, 내부 자료 구조 차이에 따라서 큰 성능 차이가 나며, 데이터의 규모가 커지면 커질 수록 성능 차이도 크다. 실제로 배민에서 맨 앞에 추가하는 로직을 ArrayList를 써서 배치 프로그램이 지연되는 문제를 연결 리스트로 바꾼 경험이 있다고 한다.
데이터 추가
데이터 제거
데이터 조회
데이터 검색
실무에서는 자료 구조의 위 기능을 주로 사용하며, 위의 데이터 추가 예시처럼 다양한 기능을 체크해보면서 왜 어레이를 실무에서 사용하는 지 알아보자.
-> 데이터 추가 시간 복잡도 비교
| ArrayList | 링크드 리스트 | |
| 앞에 추가 | O(n) | O(1) |
| 중간에 추가 | O(n) | O(n) |
| 뒤에 추가 | O(1) | O(n) |
데이터 추가에서 시간 복잡도는 위와 같으며,
ArrayList : 동적 배열 형태의 List
링크드 리스트 : 노드와 연결 형태의 List
이는 List라는 기능은 동일하지만, 내부 구조가 다르기 때문이다.
-> 데이터 추가 성능 비교
| ArrayList | 링크드 리스트 | |
| 앞에 추가 | 106ms | 2ms |
| 중간에 추가 | 49ms | 1112ms |
| 뒤에 추가 | 2ms | 2195ms |
실제 시간을 구해보아도 앞에 추가하는 경우만 링크드 리스트가 빠르고 나머지는 ArrayList가 훨씬 빠른 것을 볼 수 있다. (하지만, 중간에 추가하는 경우는 ArrayList가 훨씬 빠르다.)
-> 데이터 검색 시간 복잡도 비교
| ArrayList | 링크드 리스트 | |
| O(n) | O(n) |
검색의 경우 찾으려는 데이터를 ArrayList는 전부 확인을 해야 하고 링크드 리스트는 노드의 데이터를 전부 봐야 해서 O(n)이다.
-> 데이터 검색 성능 비교
| ArrayList | 링크드 리스트 | |
| 115ms | 492ms |
하지만, 실제 시간을 구해보면 ArrayList가 5배 정도 더 빠르다.
🚨 왜 ArrayList가 더 빠를까?
이 부분에서 ArrayList를 사용하는 이유가 극명하게 나타난다.
ArrayList : 동적 배열 형태의 List
링크드 리스트 : 노드와 연결 형태의 List
ArrayList는 배열을 사용하고 링크드 리스트는 노드를 사용한다고 했다.
배열 : idx 별 연속된 메모리 주소
링크드 리스트 : 노드 별 랜덤 메모리 주소
배열은 연속된 메모리에 요소를 저장하는 특성이 있고 링크드 리스트는 메모리의 어떤 위치에 노드가 할당될 지 알 수 없는 차이가 있다. 이것이 성능 차이로 이어진다.
1) 순차적 접근 속도로 앞에서부터 끝까지 On으로 검색을 해도 연속된 데이터를 훑으므로 메모리 접근 속도가 빠르다.
2) CPU 캐시 활용도 ↑ : CPU는 연산을 하기 위해서 메모리로부터 데이터를 읽는데, 두 장치간 속도 차이로 인해 지연시간이 발생한다. 따라서 캐시를 두어 지연시간을 극복하는데 연속된 데이터일 경우 캐시에 함께 저장될 확률이 높아서 캐시 히트 확률이 높아진다.
3)링크드 리스트는 메모리 상에 흩어져서 만들어져서 cpu 캐시 효율이 떨어지고 메모리 접근 속도가 느릴 수 있다. (캐시 미스 확률 높음)
이와 같은 배열의 연속된 특성 덕분에 ArrayList의 검색 속도가 훨씬 빠르다. 우리는 이를 통해서 연속된 공간에 저장하는 것이 프로그램 성능에 좋은 영향을 준다는 것을 알 수 있었다. 이론적으로 링크드 리스트는 검색 데이터를 조회만 하는 On이고 어레이는 다 뒤로 밀어야 해서 링크드 리스트가 더 빠르지 않을까 생각할 수 있지만, 현재 컴퓨터 시스템의 메모리 접근 패턴을 봤을 때 어레이가 거의 모든 기능에서 비교적 빠르고, 앞에 추가만 링크드 리스트가 빠르다.
- List 인터페이스
중복을 허용하고 순서가 있는 리스트의 정의를 그대로 구현하여 메서드로 제공하는 자바의 List 인터페이스이다. List는 배열과 비슷하지만, 크기가 동적으로 변화하는 컬렉션을 다룰 때 유연하게 사용할 수 있다. (Capa가 50%을 넘어가면 증가한다.)
🚨 중간에 추가하는 속도는 왜 ArrayList가 더 빠를까?
위에서 ArrayList의 중간에 추가하는 것도 ArrayList가 더 빠른 것을 확인했다.
ArrayList : 중간에 추가하고 이후 요소 한 칸 씩 이동
링크드 리스트 : 추가할 위치를 찾고 연결하면 끝
이론상으론 링크드 리스트가 더 빨리 동작할 것처럼 보이는데 말이다. List의 구현체 ArrayList 내부를 보면 왜, 이론적으로 느릴 것 같은 부분도 실제론 더 빠른 지 알 수 있다.
-> ArrayList 중간에 add 구현 코드
중간 위치에 데이터를 추가하면 추가할 위치 이후의 모든 요소를 한 칸씩 뒤로 이동시켜야 하는데 이를 메모리 고속 복사 연산으로 최적화했다.
public void add(int index, E e) {
if (size == elementData.length) {
grow();
}
shiftRightFrom(index);
elementData[index] = e;
size++;
}
private void shiftRightFrom(int index) {
for (int i = size; i > index; i--) {
elementData[i] = elementData[i - 1];
}
}위 코드처럼 코드 레벨에서 한 개씩 옮기는 것이 아니라,
public void add(int index, E element) {
rangeCheckForAdd(index);
modCount++;
final int s;
Object[] elementData;
if ((s = size) == (elementData = this.elementData).length)
elementData = grow();
System.arraycopy(elementData, index, // 여기
elementData, index + 1,
s - index);
elementData[index] = element;
size = s + 1;
}System.arraycopy()를 사용하여 시스템 레벨에서 옮길 요소를 한 번에 옮겨버린다. ArrayList는 추가할 위치를 찾고 한 칸 씩 옮기는 것으로 인해서 On이라는 같은 시간 복잡도를 가지더라도, 링크드 리스트보다 오래걸릴것 같지만,
연속된 메모리 공간 = (순차적 접근 속도, CPU 캐시 활용성)
메모리 고속 복사
내부적으로 최적화되어 있어서 링크드 리스트보다 훨씬 빠른 속도로 중간에 요소를 추가할 수 있고, 이러한 이유 때문에 실무에서는 보통 ArrayList를 사용한다. 맨 앞에 추가와 삭제하는 경우만 있다면 링크드 리스트를 쓰겠지만, 맨 앞에 추가, 삭제 외 다양한 기능이 사용된다면 ArrayList를 사용해야 하는 것은 아닐지 다시 고민해봐야 할 것이다. (하지만 데이터가 많아지면 중간에 추가하는 것은 링크드 리스트가 더 빠르다.)
✅ 자바에서 제공하는 링크드 리스트의 장점
1) 이중 연결 리스트 구조
2) 맨 마지막 노드를 Last 변수로 참조
자바에서는 링크드 리스트도 위 2개의 기능으로 효율성을 높이고 있다.
1) 마지막 데이터 추가 : O(n)이 아닌 O(1)의 시간 복잡도
2) 역방향 조회 : 역방향 조회가 가능하여 추가할 위치가 중간보다 작으면 앞에서부터 순회하고, 중간보다 크면 뒤에서부터 순회하여 시간 단축
3) 검색 : 맨 앞에서부터 데이터를 비교 해야하니 여전히 O(n)
4) 중간에 추가 : 역방향 조회를 해도 앞에서부터 오나 뒤에서부터 오나 중간까지 와야해서 O(n)
따라서, 마지막 데이터 추가, 조회 기능의 시간이 개선 되었고, 조회는 역방향 조회가 가능하더라도 메모리 연속성 때문에 ArrayList가 더 빠른 모습을 보인다.
- 성능 비교 결론
검색 : ArrayList의 연속성 때문에 ArrayList가 빠름
중간에 추가 : ArrayList의 연속성과 고속 메모리 복사 때문에 ArrayList가 빠르지만 링크드 리스트도 역방향 조회로 뒤쪽에 가까운 요소 추가는 속도 개선
학과에서 배우길 [중간에 추가]가 연결리스트가 더 빠를 것 같지만, 메모리 접근 속도와 CPU 캐시 히트될 확률이 매우 높음, 메모리 고속 복사 때문에 배열 리스트가 훨씬 빠르다.
※ 런타임, 컴파일 타임 의존관계
컴파일 타임 의존 관계 : BatchProcessor 코드에 나와 있는 그대로 의존한 관계 (현재는 List에 의존)
런타임 의존 관계 : 런타임에 실제 Processor의 List에 할당되는 의존 관계 (ArrayList에 의존)
컴파일 타임 의존 관계는 코드에 나와있는 그대로를 의미하기 때문에 코드를 수정하지 않는 한 변경될 수 없어서 코드 변경 시 모든 코드의 변경이 일어나는 것이고 런타임 의존 관계는 할당되는 객체에 따라서 의존 관계가 달라질 수 있기 때문에 DI가 가능하다. 의존관계를 클라이언트 코드를 정의할 때 미리 초기화하여 결정하는 것이 아니라, 런타임에 객체를 생성하는 시점으로 미뤄서 코드의 재사용성을 높이고 수정을 막는다.
'[백엔드] > [Java | 학습기록]' 카테고리의 다른 글
| [문법] 자바 Set에 데이터 추가 삭제가 O(1)인 이유 (0) | 2025.03.02 |
|---|---|
| [문법] 제네릭과 와일드카드 사용법 (0) | 2025.02.24 |
| [Core] JVM의 역할과 동작 원리 (0) | 2024.06.19 |
| [문법] 자바 해시를 사용한 데이터 형식(HashMap, HashSet) (0) | 2024.06.05 |
| [문법] 오류를 핸들링하는 방법 (0) | 2024.06.05 |



