
개발자로 후회없는 삶 살기
[문법] 자바 Set에 데이터 추가 삭제가 O(1)인 이유 본문
서론
※ 아래 내용을 다룹니다.
- Hash 알고리즘
- Set 자료구조 내부 원리
- hashCode와 Equals를 재정의 해야 하는 이유
본론
- List vs Set 특징 비교
1. List
1) 인덱스가 있다.
2) 중복을 허용한다.
3) 순서가 있다.
2. Set
1) 인덱스가 없어서 순서가 없다.
2) 중복을 허용하지 않고 유일한 요소만 저장할 수 있다.
3) 요소를 포함하고 있는지 중복을 체크하는 속도가 매우 빠르다.
자바의 Set은 위와 같은 특징을 가지고 있어서, 중복 제거 할 때 용이하게 사용되고, 순서가 필요한 경우엔 사용할 수 없다. 3번 특징처럼 체크 속도가 왜 이렇게 빠른지 구현하면서 알아보자.
- Set의 문제점
public class MyHashSetV0 {
private int[] elementData = new int[10];
private int size = 0;
public boolean add(int value) {
if (contains(value)) {
return false;
}
elementData[size] = value;
size++;
return true;
}
private boolean contains(int value) {
for (int data : elementData) {
if (data == value) {
return true;
}
}
return false;
}직접 구현해본 Set은 인덱스가 없기 때문에 추가, 삭제, 중복제거 정도만 구현하면 Set의 기능을 구현할 수 있다.
-> 단순하게 직접 구현한 set 시간복잡도
저장 : 중복 체크를 해야 해서 On
삭제 : 데이터를 찾아야 해서 On
중복 체크 : On
배열을 사용하여 단순하게 구현한 Set은 유일한 요소를 저장하는 특징 때문에 저장을 할 때마다 중복을 체크하여 On의 시간 복잡도를 가진다. 이것을 자바에서는 해시 알고리즘을 사용하여 최적화했다.
- 해시 알고리즘
데이터를 찾는 검색 성능을 평균 O(1)로 비약적으로 끌어올릴 수 있다. 지금까지 검색은 모든 데이터를 다 봐야했는데 어떻게 이런 것이 가능할 지 알아보자.

배열은 index의 위치를 사용하면 데이터를 찾을 때 O1이고 index만 알면 O1로 찾을 수 있다. 즉, 데이터를 검색할 때 인덱스를 알 수 있으면 O1로 성능을 끌어올릴 수 있다.

저장하는 값을 인덱스로 사용하면 배열 [저장하는 값]으로 데이터가 있는 지 없는 지 바로 찾을 수 있고 중복 체크를 할 때 O(1)이 걸려서 O(1)로 데이터를 저장할 수 있다. 값이 1 이면 1번 인덱스, 8이면 8번 인덱스에 넣고 데이터 1을 찾을 때 arr[데이터 1]로 idx에 데이터 번호를 넣으면 바로 찾을 수 있다.
🚨 메모리 낭비
하지만, 이렇게 하면 저장하고자 하는 데이터의 크기만큼의 사이즈의 배열이 필요하다. 입력 값이 100이면 값을 인덱스로 사용하기 때문에 OOB가 안 뜨게 하기 위해서 100만큼 배열의 크기를 잡아야 한다. 데이터의 값을 인덱스로 사용한 덕분에 O1의 검색 속도를 얻었지만, 낭비되는 메모리 공간이 너무 많아서 속도와 메모리 공간의 트레이드 오프이다.
int 범위 : -21억 ~ 21억
필요한 메모리 : 4B * 42억 = 17GB (필자 컴퓨터 메모리 16GB)
int 범위의 데이터를 저장하는데 컴퓨터 메모리를 거의 다 사용하게 되는 문제점이 발생한다. 근데 사용자가 1만 입력한다면 42억-1개는 모두 낭비가 된다. 매우 빠른 검색 성능을 보장하지만, 저장하고자 하는 데이터의 범위가 크면 클수록 저장하고자 하는 데이터의 값을 인덱스로 사용하는 방식은 사용하기 어려워 보인다.
✅ 나머지 연산
나머지 연산으로 저장하는 값의 크기만큼 배열 사이즈를 잡아서 메모리가 낭비되는 문제를 해결할 수 있다.
배열의 크기 = 10
저장하는 값 = 1, 12
나머지 = 1, 2
나머지 연산을 하면 12를 저장하고자 해도 나머지는 2라서 저장하고자 하는 값만큼 배열 사이즈를 잡지 않아도 된다. 나머지 연산으로 데이터 저장을 O(1)로 하는 것과 메모리 낭비 모두를 잡았다.
-> 해시 인덱스
배열의 인덱스로 사용할 수 있도록 원래의 값을 계산한 인덱스를 해시 인덱스라고 한다. 나머지 연산한 1, 2가 해시 인덱스이다. 해시 인덱스로 배열의 인덱스로 사용해보자.
arr[1] = 1
arr[2] = 12
arr[해시 인덱스] = 데이터 값
나머지 연산을 통해서 구한 해시 인덱스를 인덱스로 사용하여 데이터를 저장할 수 있다. 배열의 값으로 인덱스를 구하고 값을 저장하기 때문에 O(1)로 빠른 성능을 제공한다.
static final int CAPACITY = 10;
public static void main(String[] args) {
Integer[] arr = new Integer[CAPACITY];
arr[hashIndex(1)] = 1;
arr[hashIndex(2)] = 2;
arr[hashIndex(5)] = 5;
arr[hashIndex(8)] = 8;
arr[hashIndex(14)] = 14;
arr[hashIndex(99)] = 99;
System.out.println("arr = " + Arrays.toString(arr));
}
static int hashIndex(int value) {
return value % CAPACITY;
}이제 저장과 조회는 모두 hashIndex를 먼저 구해서 저장할 인덱스를 찾고 배열에 저장한다. 나머지 연산을 통해서 배열의 크기를 넘지 않고 메모리 낭비도 해결했다.
🚨 해시 충돌
하지만, 이렇게 하면 저장할 위치가 충돌할 수 있다는 한계가 있다.
데이터 값 = 2, 12
해시 인덱스 = 2, 2
해시 인덱스가 같아지는 문제를 해시 충돌이라고 한다. Set에서 유일한 요소를 저장하기 위해서 중복 체크를 한다고 했는데, 이는 전혀 다른 문제로 요소가 다른데 인덱스가 같아서 덮어 쓰게 되는 것이다.
✅ 해시 충돌 해결
해시 충돌을 낮은 확률로 일어날 수 있다고 가정하면 실마리가 보인다. 해시 충돌이 일어나면 단순하게 같은 해시 인덱스의 값을 같은 인덱스가 같이 저장하는 것이다. 배열 안에 배열을 또 만들어서 함께 저장한다.
-> 해시 충돌 시 조회
1을 조회하기 위해선 1번 인덱스로 가서 배열은 전체를 순회한다.
해시 인덱스 = 1, 1, 1, 1
저장 데이터 = 1, 11, 21, 31
해시 충돌 시엔 데이터를 동일한 해시 인덱스에 함께 저장한다. 1, 11, 21, 31 저장 후 31을 조회하면 총 3번의 충돌이 일어나고 이를 배열 안에 함께 저장한다. 31을 조회하는 최악의 경우 On의 시간 복잡도를 가진다. 하지만 확률적으로는 넓게 퍼지기 때문에 대부분은 O1의 성능을 제공하고 가끔 해시 충돌이 발생해도 대부분의 경우 O1이다. 즉, 대부분은 O1이니 가끔 일어날 On은 수용하자는 전략이다.
-> 충돌 구현 예시
public static void main(String[] args) {
LinkedList<Integer>[] buckets = new LinkedList[CAPACITY];
for (int i = 0; i < CAPACITY; i++) {
buckets[i] = new LinkedList<>();
}
add(buckets, 1);
add(buckets, 2);
add(buckets, 5);
add(buckets, 8);
add(buckets, 14);
add(buckets, 99);
add(buckets, 9);
System.out.println("buckets = " + Arrays.toString(buckets));
}배열 요소를 링크드리스트로 하는 배열을 만들었다. 해시 충돌을 할 때만 하나의 해시 인덱스에 여러 데이터를 저장할 텐데, 충돌이 거의 안 일어나므로 필요함 메모리만 사용하기 위해서 링크드리스트 를 선택했다.
// 저장
static void add(LinkedList<Integer>[] buckets, int value) {
int hashIndex = hashIndex(value);
LinkedList<Integer> bucket = buckets[hashIndex];
if (!bucket.contains(value)) {
bucket.add(value);
}
}
// 조회
private static boolean contains(LinkedList<Integer>[] buckets, int searchValue) {
int hashIndex = hashIndex(searchValue);
LinkedList<Integer> bucket = buckets[hashIndex];
return bucket.contains(searchValue);
}
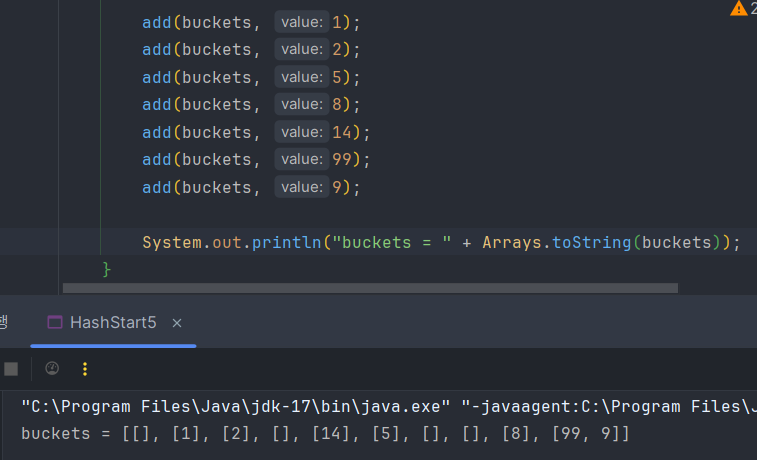
저장 : 해시 인덱스 구하기 > 중복 체크On > 데이터 저장
중복 체크는 충돌이 일어난 요소 개수만큼만 순회하므로 거의 O(1)이다.
조회 : 해시 인덱스 > 중복 체크 = 링크드 리스트 순회 On
99를 저장하고 해시 인덱스가 같은 9를 저장하면 해시 충돌이 일어나고 contains는 해시 충돌 횟수만큼만 순회한다. 즉, O(해시 충돌 횟수)만큼만 순회해서 거의 없는 거라고 보고 조회 전체는 O(1)이라고 보면 된다. 원래 조회가 전체 순회를 해서 On이 걸리고 시간이 오래 걸렸던 것을 해시 인덱스로 빠르게 O1로 검색한다.
- 정리
기존 Set에서 데이터를 저장할 때 중복 체크를 위해서 On이 발생하는 문제가 있었다. 이를 해시 알고리즘을 통해서 O(1)로 개선했다. 빠르게 중복 체크하고 저장과 조회를 할 수 있는 것이다. 해시 충돌로 인한 순회는 빼고 생각하면 된다
배열이 크고 입력 하는 데이터가 작으면 충돌은 거의 안 일어난다.
너무 작으면 : 충돌이 많이 일어남
너무 크면 : 메모리 낭비
하지만 배열이 크다고 해서 CAPA로 나눈 나머지이기 때문에 언제든 충돌이 일어날 수 있고 CAPA를 75%로 두고 기준으로 잡고 사용하는 것이 효과적이다.
- 자바 hashCode
자바에서는 hashIndex를 구하기 위해선 입력 값을 몫으로 사용하여 나눗셈 연산을 한다. 몫이 숫자(해시코드)여야 하므로, 숫자로 바꾸는 연산을 하는 것이다. 따라서 입력 값을 숫자로 변환해주는 hashCode 함수를 제공한다. 문자열, 사용자 객체 등 레퍼런스 타입을 숫자로 표현하여 hashIndex를 구할 수 있다.
해시 함수 : 가변 입력을 고정 길이로 변환하는 함수
해시 충돌 : 해시 함수에 다른 값을 넣어도 같은 해시 코드가 나올 수 있다. 이 경우 해시 Set에서 동일 hashIndex의
링크드리스트에 함께 저장된다.
해시 인덱스 : 해시 코드를 Capacity로 나누기 연산을 하여 구현 배열에 저장될 위치 인덱스
-> Object hashCode
모든 객체의 해시 코드를 구하기 위해서 자바에서는 Object 클래스에 hashCode 함수를 제공한다. 기본 정의는 객체의 참조값을 기반으로 해시 코드를 만들어서 동등해도 동일하지 않으면 다른 해시 코드가 나온다. 따라서 재정의를 해줘야 한다.
public class Member {
private int id;
@Override
public boolean equals(Object object) {
if (this == object) return true;
if (!(object instanceof Member member)) return false;
return id == member.id;
}
@Override
public int hashCode() {
return Objects.hash(id);
}
}사용자 클래스에 필드를 기반으로 hashCode를 재정의했다. 이러면 다른 객체여도 id값이 같으면 같은 해시 코드를 반환하게 된다. 필드 값이 같으면 같은 해시 코드가 나오고 같은 Set의 해시 인덱스로 사용되도록 해야한다.
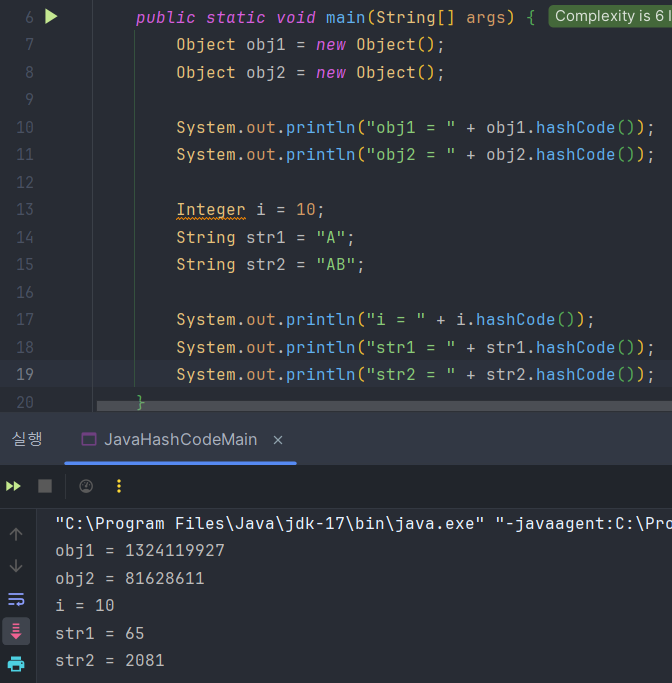
자바의 레퍼런스 타입은 미리 hashcode가 재정의 되어 있다. 범위가 너무 좁으면 해시 충돌이 발생할 수 있기 때문에 넓은 범위를 가진다.

정수 10은 항상 해시 코드 10이 나온다.
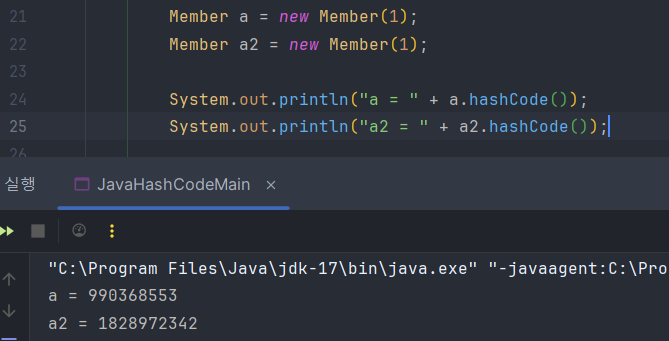
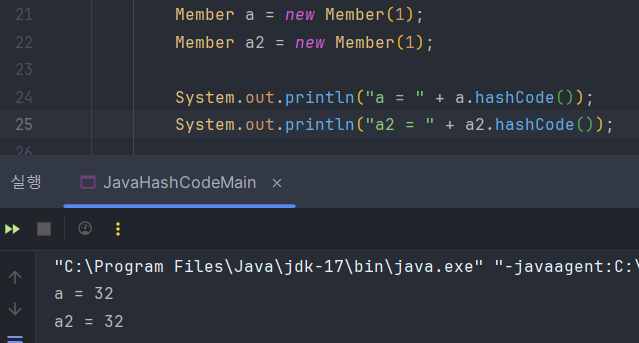
사용자 객체도 hashcode를 재정의 하기 전에는 해시 코드가 다르게 나오지만 재정의하면 같은 값이 나온다. 만약 hashCode를 재정의 하지 않으면 같은 입력이어도 다른 해시 코드가 나올 수 있고 그러면 Set에서 다른 hashIndex에 같은 값이 저장되고 중복체크도 되지 않는다. hashIndex가 같아야만 중복 체크를 할 수 있는데 다르니 중복값이 저장될 수 있다. 따라서 해시 자료 구조를 사용하기 위해선 반드시 hashCode를 재정의 해야 한다. hashcode를 구현해야만 같은 값을 넣었을 때 일관된 해시코드가 나오는 것이다.
✅ equals를 반드시 구현해야 하는 이유
해시 자료 구조를 사용할 때 hashCode만 재정의 하면 안된다. 그러면 이제, equals를 반드시 구현해야 하는 이유를 알아보자.
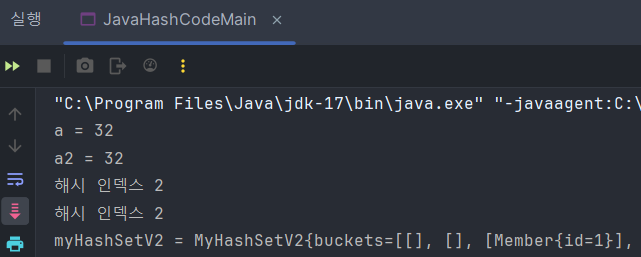
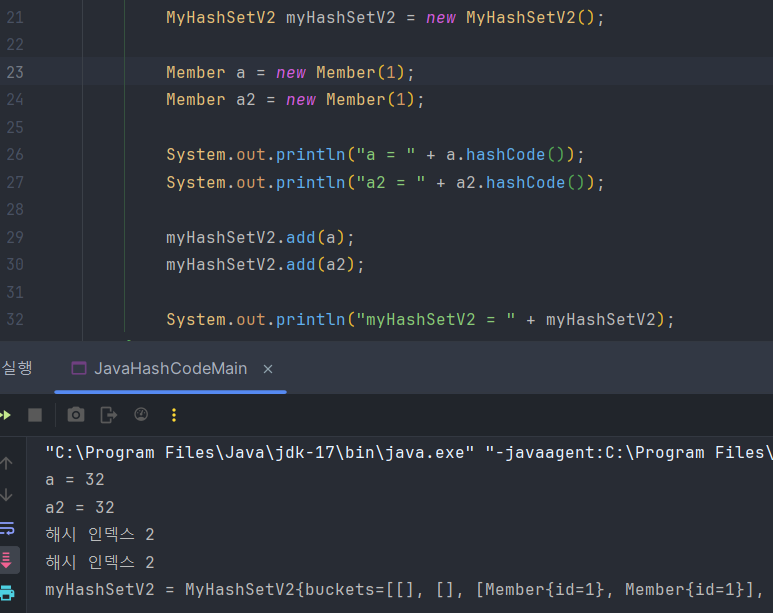
우선, 구현하지 않으면 동등한 객체가 Set에 저장되는 장애가 발생한다. 그러면 중복 저장 문제와 검색 실패 문제가 발생하게 된다.
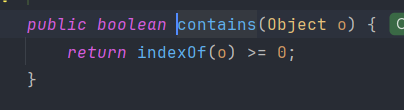
equals의 사용처는 set의 add나 contains를 할 때 hashIndex에 접근한 이후 hashIndex에 있는 링크드리스트 에 중복 데이터가 포함됐는지 확인하는 contains이다.
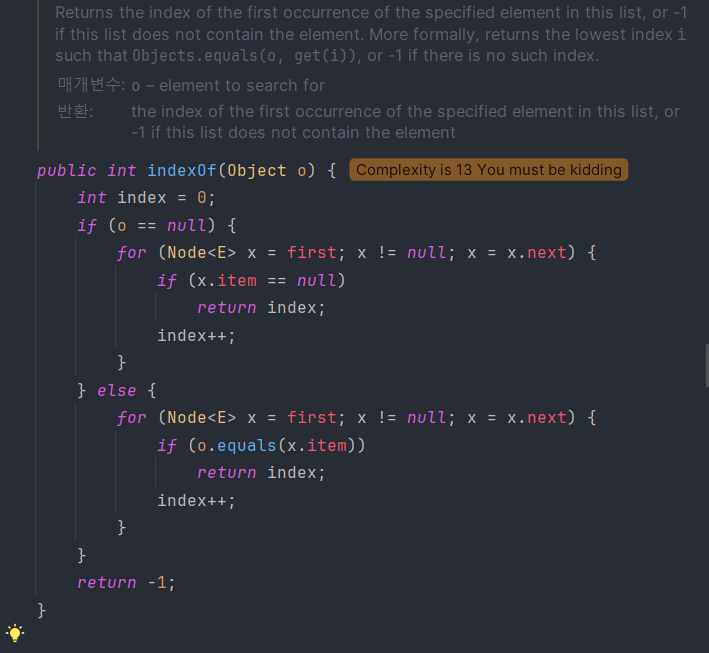
내부 구현 코드를 보면 링크드리스트의 모든 객체와 입력 객체를 equals로 비교한다. 따라서 만약 equals를 재정의 하지 않으면 Object의 기본 equals를 사용하여 참조값으로 비교를 하게 되고 동등한 객체라도 비교 결과가 False가 나온다. 따라서 해시 자료구조를 사용할 때는 중복 제거를 막기 위해서 반드시 hashCode와 equals를 모두 재정의 해야 한다.
+ 정리
증복등록 : hashCode를 재정의 하지 않으면 동등하더라도 hashIndex가 달라서 다른 곳에 중복 저장되고, equals를 재정의 하지 않으면 같은 hashIndex에 동등하더라도 참조값이 달라서 다른 값으로 판단하고 중복 저장됨.
검색 실패 : hashCode를 재정의 하지 않으면 hashIndex가 달라서 다른 곳에서 비교 검색을 하므로 검색이 실패하고, equals를 재정의 하지 않으면 같은 곳에서 검색하더라도 참조값이 달라서 검색 실패
'[백엔드] > [Java | 학습기록]' 카테고리의 다른 글
| [문법] 실무에서 보통 ArrayList를 쓰는 이유 (동적 배열 원리, Linked와 성능 비교) (0) | 2025.02.27 |
|---|---|
| [문법] 제네릭과 와일드카드 사용법 (0) | 2025.02.24 |
| [Core] JVM의 역할과 동작 원리 (0) | 2024.06.19 |
| [문법] 자바 해시를 사용한 데이터 형식(HashMap, HashSet) (0) | 2024.06.05 |
| [문법] 오류를 핸들링하는 방법 (0) | 2024.06.05 |



