
개발자로 후회없는 삶 살기
손그림 의류 검색 서비스 본문
서론
이 프로젝트는 사람이 손으로 그린 의류 스케치로 실제 쇼핑몰에서 판매하는 의류를 검색해주는 서비스를 제공하는 것을 목표로 합니다. 필자가 속한 연합 동아리(BOAZ)에서 진행한 팀 프로젝트 임을 밝힙니다.
-> 데일리 회고
https://hsb422.tistory.com/category/%5B%EB%8C%80%EC%99%B8%ED%99%9C%EB%8F%99%5D/%5BBOAZ%5D
'[대외활동]/[BOAZ]' 카테고리의 글 목록
hsb422.tistory.com
이 프로젝트의 전체 과정은 위 링크를 참고해 주시기 바랍니다.
-> 전체 코드
https://github.com/SangBeom-Hahn/shopping-helper
GitHub - SangBeom-Hahn/shopping-helper: 👗 SHOPPING HELPER - 손그림 의류 검색 서비스
👗 SHOPPING HELPER - 손그림 의류 검색 서비스. Contribute to SangBeom-Hahn/shopping-helper development by creating an account on GitHub.
github.com
본론
- 프로젝트 주제




손으로 그린 의류 sketch로 실제 의류 이미지를 생성하고 이미지 검색을 통해 실제 쇼핑몰에서 판매하고 있는 유사 제품과 매칭시켜주는 서비스를 개발합니다. 쇼핑을 할 때 키워드가 생각이 안 나거나 키워드로 검색했는데 원하는 결과가 안 나오는 경우 필자가 개발한 서비스의 필요성을 느꼈습니다.
=> 세부 목표
① edge detection : DexiNed edge detection을 사용하여 객체에서 테두리를 추출합니다.
② 채색 : 테두리만 존재하는 스케치에 고객이 원하는 색을 입힙니다.
③ 실제 이미지로 변환 : 스케치 이미지를 실제 의류 이미지로 생성합니다.
④ 이미지 검색 : 의류 이미지를 검색 엔진에 넣어 실제 판매하고 있는 유사 상품을 검색하고 이를 서버로 구현합니다.
- 프로젝트 구성도 작성
1) 1차 PR
2) 2차 PR
- 프로토 타입

총 2가지 모델을 학습 시킨 후 서비스에 활용할 때 하나의 파이프라인으로 통합하여 최종 결과물을 낼 것입니다.
- 형상 관리
노션을 통해 진행하였습니다.
- 프로젝트 시작
1. edge detection



canny, LDC, DexiNed 등 다양한 edge detection을 비교해 보았고 모델 성능에 선명한 edge가 도움이 될 거라 생각하여 DexiNed를 사용하였습니다. DexiNed를 사용하여 객체에서 테두리만 추출고 카테고리 별로 directory를 나누어 별도의 폴더에 실제 이미지와 테두리 이미지 훈련 데이터 pair를 준비하였습니다.
2. 채색
1) 목표(참고 1)


본 저자의 영상을 보면 edge 이미지에 원하는 색깔로 채색을 하는 것을 확인할 수 있습니다.
-> 주목할 포인트
① 고객은 꼼꼼히 완벽하게 채색을 하는 것이 아닌 점을 찍거나 색깔선 한 줄 정도를 그리면 완벽하게 채색이 된다는 것입니다.
② 검은색 선으로 영역을 나누면 원본 스케치에서 커스터마이징 한 이미지를 만들 수 있습니다.
∴ 이러한 이점으로 채색 모델을 최종 채택하기로 결정하였습니다.
2) 채색 모델 코드 분석
① 데이터 형식 및 전처리
=> 설명
| Data | 데이터 수 | Train 데이터 수 | Val 데이터 수 | 세부사항 |
| 1 | 2543 | 1889 | 654 | hat |
| 2 | 2589 | 1912 | 677 | pants |
| 3 | 2549 | 1892 | 657 | t-shirts |
| 4 | 1537 | 1886 | 651 | skirt |
pix2pix 모델은 입력으로 pair 이미지가 필요합니다. target은 실제 의류 이미지를 사용하였고 src 이미지는 보유하고 있는 target 이미지를 edge detection 해주기만 하면 되기에 간편합니다. 이것이 GAN의 엄청난 위력입니다.
출처 : fashion-outfit-items(참고 5)
=> 전처리
-> 분산되어 있는 target 이미지를 하나의 dir에 모으는 함수
def create_target_images():
pathname = f'{config.ZAPPOS_DATASET_SNEAKERS_DIR}/*/*.jpg'
filename = os.path.basename(filepath)
img_target = load_img(filepath, target_size=(config.IMG_HEIGHT, config.IMG_WIDTH))
img_target = np.array(img_target)
img_target_filepath = os.path.join(config.TRAINING_TARGET_DIR, filename)
save_img(img_target_filepath, img_target)
만약 target 이미지들이 여러 클래스명의 dir에 분산되어 있을 시 하나의 dir로 모으는 작업이 필요합니다.
-> target 이미지에 edge detection을 하여 src 이미지를 만드는 함수
# 모인 target 이미지를 edge detection하여 테두리 이미지로 만드는 함수
def create_source_imgs(target_dir, source_dir):
pathname = f'{target_dir}/*.jpg' # data/training/target
print(pathname)
for filepath in glob.glob(pathname):
img_target = load_img(filepath, target_size=(config.IMG_HEIGHT, config.IMG_WIDTH))
img_target = np.array(img_target)
img_source = detect_edges(img_target) # 아 소스 이미지는 엣지 이미지구나
filename = os.path.basename(filepath)
img_source_filepath = os.path.join(source_dir, filename)
save_img(img_source_filepath, img_source)하나의 dir에 target 이미지를 모았습니다. 이제 아까 위에서 말했던 edge detection을 하여 src 이미지를 만들어야 합니다.
-> edge detection 함수
def detect_edges(img):
img_gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
img_gray = cv2.bilateralFilter(img_gray, 5, 50, 50)
img_gray_edges = cv2.Canny(img_gray, 45, 100)
img_gray_edges = cv2.bitwise_not(img_gray_edges) # invert black/white
img_edges = cv2.cvtColor(img_gray_edges, cv2.COLOR_GRAY2RGB)
return img_edgestarget 이미지를 edge detection 하는 함수입니다.
② 모델
-> 판별자 모델 구조
d = Conv2D(64, (4,4), strides=(2,2), padding='same', kernel_initializer=kernel_weights_init)(merged)
d = LeakyReLU(alpha=0.2)(d)
# C128
d = Conv2D(128, (4,4), strides=(2,2), padding='same', kernel_initializer=kernel_weights_init)(d)
d = BatchNormalization()(d)
d = LeakyReLU(alpha=0.2)(d)
# C256
d = Conv2D(256, (4,4), strides=(2,2), padding='same', kernel_initializer=kernel_weights_init)(d)
d = BatchNormalization()(d)
d = LeakyReLU(alpha=0.2)(d)
# C512
d = Conv2D(512, (4,4), strides=(2,2), padding='same', kernel_initializer=kernel_weights_init)(d)
d = BatchNormalization()(d)
d = LeakyReLU(alpha=0.2)(d)
# second last output layer
d = Conv2D(512, (4,4), padding='same', kernel_initializer=kernel_weights_init)(d)
d = BatchNormalization()(d)
d = LeakyReLU(alpha=0.2)(d)판별자는 일반적인 합성곱 신경망 구조를 띠고 있습니다. 생성자가 만든 가짜 이미지나 원래 존재하는 실제 이미지를 입력으로 받아 featuer를 추출하고 가짜인지 진짜인지 맞추도록 학습합니다.
-> 생성자 모델 구조
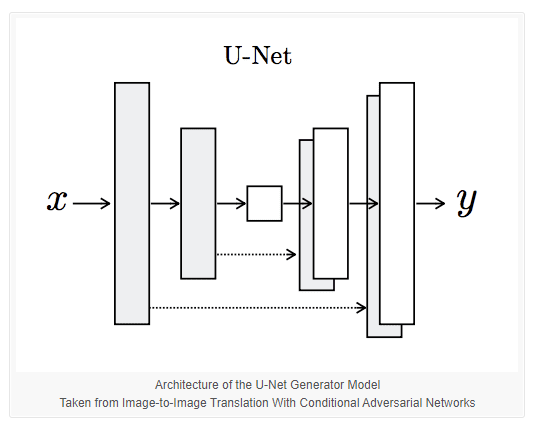
입력으로 cgan처럼 target을 받기는 하지만 그 라벨이 정수가 아닌 이미지이기 때문에 Unet를 생성자로 사용했습니다.
# encoder model
e1 = _encoder_block(input_src_image, 64, batchnorm=False)
e2 = _encoder_block(e1, 128)
e3 = _encoder_block(e2, 256)
e4 = _encoder_block(e3, 512)
e5 = _encoder_block(e4, 512)
e6 = _encoder_block(e5, 512)
e7 = _encoder_block(e6, 512)
# bottleneck, no batch norm and relu
b = Conv2D(512, (4,4), strides=(2,2), padding='same', kernel_initializer=kernel_weights_init)(e7)
b = Activation('relu')(b)
# decoder model
d1 = _decoder_block(b, e7, 512)
d2 = _decoder_block(d1, e6, 512)
d3 = _decoder_block(d2, e5, 512)
d4 = _decoder_block(d3, e4, 512, dropout=False)
d5 = _decoder_block(d4, e3, 256, dropout=False)
d6 = _decoder_block(d5, e2, 128, dropout=False)
d7 = _decoder_block(d6, e1, 64, dropout=False)인코더 블럭에서 모델의 너비와 높이를 줄이고 깊이를 늘리고 디코더 파트에서 깊이를 줄이고 너비와 높이를 원형상으로 복원합니다.
3) 학습
-> 생성자 가짜 이미지 입력 학습 예시

생성자 입력 : edge에 pointing 된 이미지와 target label의 pair 이미지
판별자 입력 : 생성자 출력 이미지와 target label 이미지
> edge 이미지가 생성자에 입력되기 전에 point를 찍는 전처리가 수행되고 실제 target label 이미지와 pair로 생성자에게 입력되어 채색된 결과물을 생성하면 판별자의 입력 쌍으로 들어가서 real or fake를 출력하여 판별자의 출력 오차로 학습합니다.
4) 학습 결과 test


평가 : 사용자가 원하는 색깔로 채색이 되었으며 검은색 선은 스케치로 인식합니다. 하지만 번지는 경향이 있으므로 학습 시간을 늘려야 합니다.
3. 실제 이미지로 변환
1) 목표(참고 2) :

고객이 그린 스케치를 실제 의류 이미지로 변환해 줍니다. 채색의 경우 스케치라는 사실은 그대로인데 스케치 위에 색만 입힌 것입니다. 이번에는 결과물이 스케치가 아닌 실제 의류 이미지입니다.
-> 우려할 점 : 분명 실제 의류 이미지를 생성하는 것은 의미 있는 장점이라고 할 수 있습니다. 하지만 출력 결과물의 색깔을 고객이 원하는 색으로 선택할 수 없습니다. 이러한 경우 고객은 스케치만 입력으로 넣고 모델이 만들어 주는 대로 이미지 검색을 수행해야 할 수도 있습니다.
-> 그러면 어떻게 해야 할까?
① 채색 모델의 결과를 실제 이미지로 바꾸는 과정을 추가로 만들면 해결할 수 있습니다. 하지만 이때 데이터 구축에 문제가 생깁니다. 채색 모델의 경우 target 이미지는 원래 존재하였지만 src 이미지는 따로 만들어 주어야 했습니다. 이때는 target 이미지를 edge detection을 하는 것만으로 src 이미지를 만들 수 있었습니다. 하지만 실제 이미지로 변환하는 경우에는 채색 모델의 결과물들이 src 이미지가 됩니다. 따라서 수천 장의 모델 결과물이 수반됩니다. 이는 시간적으로 큰 비용입니다.
② 실제 이미지로 변환하는 모델이 고객이 원하는 이미지를 선택할 수 있도록 한 번에 많고 다양한 변환 결과를 반환하면 됩니다. 딱 한 개만 반환한다면 고객의 마음에 들지 않아 서비스를 종료할 수도 있지만 여러 개를 반환하고 그중 고객의 마음에 가장 가까운 결과를 선택하도록 한다면 어느 정도 차이를 줄일 수 있습니다.
2) 변환 모델 코드 분석
① 데이터 형식 및 전처리
=> 설명
이 또한 pix2pix 모델이라 pair 이미지가 필요합니다. src와 target 이미지 역시 채색 모델과 동일하다. 위에서 edge detection한 결과물을 그대로 사용하였습니다.
=> 전처리
본 논문에서는 웹 상에 올라가 있는 pair 이미지를 케라스의 tf.keras.utils.get_file로 다운로드하여서 사용합니다. 따라서 내 custom 이미지로 학습을 하기 위해서는 입력 파이프라인을 수정해주어야 합니다.
> 이때 매우 큰 문제가 있었습니다. 웹 상에 올라가 있는 이미지는 pair 이미지가 붙어 있습니다. 따라서 코드 상에서도 모든 함수의 인자가 1개의 이미지를 대상으로 하고 있습니다. 또한 모든 함수들이 tensorflow의 tf.data API를 사용하였기에 내부 코드를 바꾸는 것도 어려움이 있었습니다.
-> 이미지 로드 함수
> 수정 전
def load(image_file):
# Read and decode an image file to a uint8 tensor
image = tf.io.read_file(image_file)
image = tf.io.decode_jpeg(image)
# Split each image tensor into two tensors:
# - one with a real building facade image
# - one with an architecture label image
w = tf.shape(image)[1]
w = w // 2
input_image = image[:, w:, :]
real_image = image[:, :w, :]
# Convert both images to float32 tensors
input_image = tf.cast(input_image, tf.float32)
real_image = tf.cast(real_image, tf.float32)
return input_image, real_image붙어 있는 이미지를 반으로 나누는 코드가 필요합니다.
> 수정 후
def load(input_file, real_file): # real이 오른쪽
real_image = tf.io.read_file(real_file)
input_image = tf.io.read_file(input_file)
real_image = tf.image.decode_jpeg(real_image)
input_image = tf.image.decode_jpeg(input_image)
real_image = tf.cast(real_image, tf.float32)
input_image = tf.cast(input_image, tf.float32)
return input_image, real_image이미 pair 이미지가 떨어져 있는 채로 준비되어 있기 때문에 나누는 코드를 제거합니다.
-> tf.data API 입력 파이프라인 설정 함수
> 수정 전
train_dataset = tf.data.Dataset.list_files(str(PATH / 'train/*.jpg'))
train_dataset = train_dataset.map(load_image_train,
num_parallel_calls=tf.data.AUTOTUNE)
train_dataset = train_dataset.shuffle(BUFFER_SIZE)
train_dataset = train_dataset.batch(BATCH_SIZE)
tf.data.Dataset.list_files(str(PATH / 'train/*.jpg'))으로 이미지 1개만 입력으로 받습니다.
> 수정 후
# 이게 꾸역 꾸역 하는 내 버전(input이 A)
import glob
input_path_name = './trainA/*.jpg'
real_path_name = './trainB/*.jpg'
# print(glob.glob(input_path_name))
train_dataset = tf.data.Dataset.from_tensor_slices((glob.glob(input_path_name), glob.glob(real_path_name)))
train_dataset = train_dataset.map(load_image_train,
num_parallel_calls=tf.data.experimental.AUTOTUNE)
train_dataset = train_dataset.shuffle(BUFFER_SIZE)
train_dataset = train_dataset.batch(BATCH_SIZE)tf.data.Dataset.from_tensor_slices((glob.glob(input_path_name), glob.glob(real_path_name)))로 입력을 데이터와 라벨 2개를 받도록 코드를 수정합니다.
② 모델
-> 판별자 모델 구조
inp = tf.keras.layers.Input(shape=[256, 256, 3], name='input_image')
tar = tf.keras.layers.Input(shape=[256, 256, 3], name='target_image')
x = tf.keras.layers.concatenate([inp, tar]) # (bs, 256, 256, channels*2)
down1 = downsample(64, 4, False)(x) # (bs, 128, 128, 64)
down2 = downsample(128, 4)(down1) # (bs, 64, 64, 128)
down3 = downsample(256, 4)(down2) # (bs, 32, 32, 256)
zero_pad1 = tf.keras.layers.ZeroPadding2D()(down3) # (bs, 34, 34, 256)
conv = tf.keras.layers.Conv2D(512, 4, strides=1,
kernel_initializer=initializer,
use_bias=False)(zero_pad1) # (bs, 31, 31, 512)
batchnorm1 = tf.keras.layers.BatchNormalization()(conv)
leaky_relu = tf.keras.layers.LeakyReLU()(batchnorm1)
zero_pad2 = tf.keras.layers.ZeroPadding2D()(leaky_relu) # (bs, 33, 33, 512)위와 동일하게 일반적인 합성곱 신경망에 Input이 2갈래인 모양입니다.
-> 생성자 모델 구조
down_stack = [
downsample(64, 4, apply_batchnorm=False), # (bs, 128, 128, 64)
downsample(128, 4), # (bs, 64, 64, 128)
downsample(256, 4), # (bs, 32, 32, 256)
downsample(512, 4), # (bs, 16, 16, 512)
downsample(512, 4), # (bs, 8, 8, 512)
downsample(512, 4), # (bs, 4, 4, 512)
downsample(512, 4), # (bs, 2, 2, 512)
downsample(512, 4), # (bs, 1, 1, 512)
]
up_stack = [
upsample(512, 4, apply_dropout=True), # (bs, 2, 2, 1024)
upsample(512, 4, apply_dropout=True), # (bs, 4, 4, 1024)
upsample(512, 4, apply_dropout=True), # (bs, 8, 8, 1024)
upsample(512, 4), # (bs, 16, 16, 1024)
upsample(256, 4), # (bs, 32, 32, 512)
upsample(128, 4), # (bs, 64, 64, 256)
upsample(64, 4), # (bs, 128, 128, 128)
]채색 모델과 동일하게 Unet 구조의 생성자입니다.
3) 학습
-> 생성자 가짜 이미지 입력 학습 예시

생성자 입력 : edge-real pair 이미지
판별자 입력 : 생성자 출력 이미지와 target label 이미지
> 생성자 출력 이미지와 target label 이미지가 판별자의 입력쌍으로 들어가서 real or fake를 출력하여 판별자의 출력 오차로 학습합니다.
-> 실제 target label 이미지 입력 학습 예시

판별자 입력 : 실제 target label 이미지와 fake 이미지
> 실제 target label 이미지와 fake 이미지가 판별자의 입력쌍으로 들어가서 real or fake를 출력하여 판별자의 출력 오차로 학습합니다.
4) 학습 결과 test

평가 : 생성 이미지가 실제 의류 이미지가 나왔고 실제 이미지와 다른 다채로운 색깔을 담고 있고 있습니다.
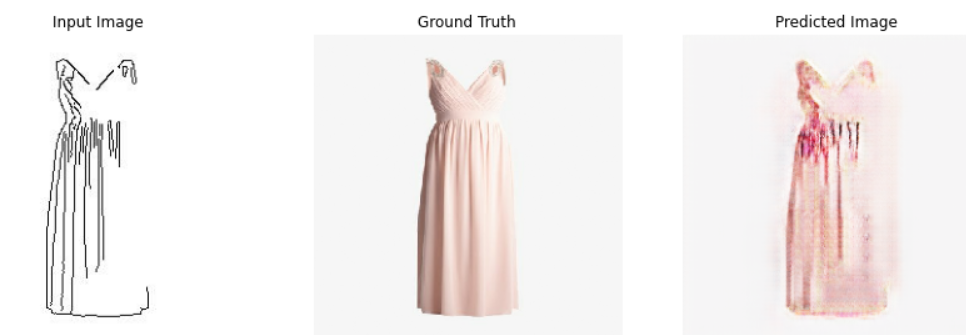
평가 : 생성 이미지가 실제와는 다른 뿌연 느낌의 이미지로 출력되었습니다. Ground Truth 우측 부분이 흰색과 구분이 되지 않아 input image가 제대로 edge detection 되지 않은 결과라고 볼 수 있습니다.
-> 전체 평가 : 생성한 이미지가 다양한 색을 가지고 있고 실제 이미지의 형태를 띠고 있다는 점에서 성공적입니다. 하지만 input 이미지 처리에서 데이터 가공에 더 주의를 기울여야 할 것 같습니다. 그래도 이 정도 결과물이면 이미지 검색 시에 유사한 도메인의 객체를 추천해 줄 것이라고 예상합니다.
4. 이미지 검색
1) 목표 (참고 3)
https://learn.microsoft.com/ko-kr/shows/ai-show/bing-visual-search
Bing Visual Search
Bing Visual Search를 사용하면 사용자가 이미지 내의 개체와 텍스트를 식별하여 인사이트를 파생시키고 랜드마크, 꽃, 패션, 유명인 등 범주에 대해 유사한 이미지와 개체를 찾을 수 있습니다. Bing Vi
learn.microsoft.com
위 영상을 보면 검색 엔진에 키워드가 아닌 이미지를 입력으로 넣어 검색을 하는 것을 알 수 있습니다. 우리는 채색을 한 스케치 이미지나 생성된 실제 의류 이미지를 검색 엔진에 넣어 유사 이미지 검색 결과를 얻고자 합니다.
-> 주목할 포인트
위의 영상처럼 이미지로 검색을 하는 것은 맞지만 우리가 원하는 것은 검색 결과가 이미지에 대한 설명이 아닌 의류를 파는 쇼핑몰의 URL입니다. 사용자가 직접 그린 스케치로 그와 유사한 상품을 파는 쇼핑몰을 검색할 수 있다면 처음에 프로젝트 주제로 잡았던 2가지(① 키워드가 기억이 안 나거나 적절하지 않을 때, ② 키워드로 검색을 해도 마음에 들지 않을 때)를 해결할 수 있습니다.
-> 채택한 API
MS visual search API를 채택했습니다.
2) 사용 결과
① 입력 이미지의 색감과 우측 가슴부의 마크까지 캐치했습니다.


하지만 핑크색 카라를 캐치하지 못하는 것을 보아 출력한 여러 개의 URL 중에서 가장 유사한 이미지를 보여주는 URL을 필터링하는 작업이 수반될 것이라고 생각합니다.
② 쇼핑몰 결과 출력
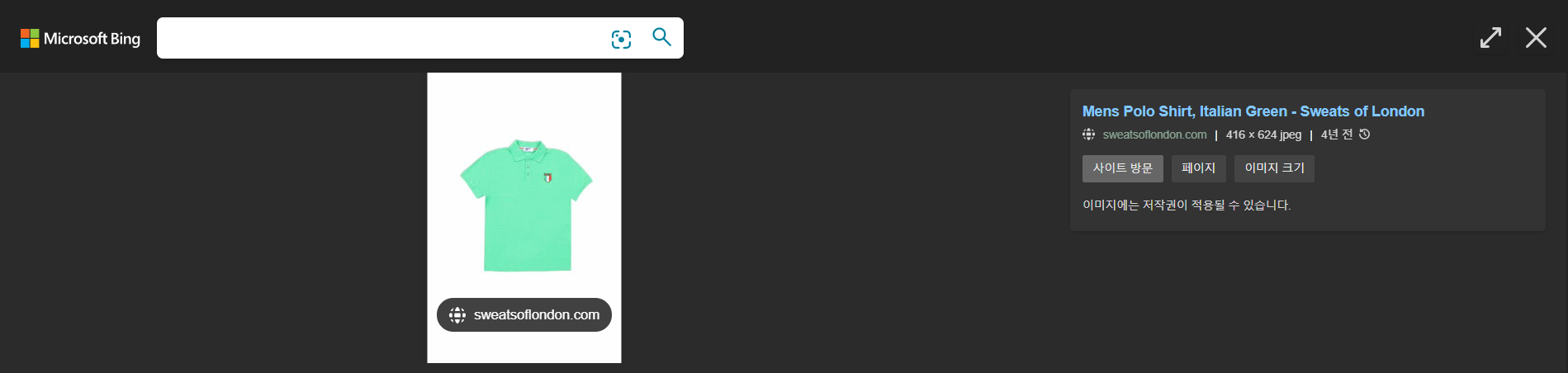
주목할 포인트였던 쇼핑몰 URL을 반환하고 해당 링크로 들어가면 실제 쇼핑몰과 연결됩니다.
-> 이 또한 처리할 것이 있습니다.
어떻게 보면 bing에 검색을 한 것이기 때문에 외국을 포함한 다양한 쇼핑몰을 결과로 반환합니다.
> 쇼핑몰 추천 지역을 한국으로 한정 짓는 것
> 이미지를 입력으로 넣으면 URL 텍스트만 뽑아서 고객이 보기 좋게 시각화하는 것
위의 두 가지 처리를 해주어야 합니다.
5. 전체 파이프라인
이제 위에서 준비한 모델과 검색 API를 전부 다 사용하여 서비스를 만들어 보겠습니다. 모델과 코드를 하나의 파일에 통합하고 사용자가 사용하기 편하게 MS 결과물을 시각화합니다.
https://github.com/SangBeom-Hahn/Sketch2Fashion
GitHub - SangBeom-Hahn/Sketch2Fashion
Contribute to SangBeom-Hahn/Sketch2Fashion development by creating an account on GitHub.
github.com
Flask를 이용하여 인공지능에 친화적인 웹 서버를 구현하였고 ngrok를 통해 배포하였습니다.


깃허브 링크에서 확인되는 데모를 보면 스케치를 수정하고 수정한 스케치에 원하는 색을 입히고 이미지 검색으로 실제 쇼핑몰에서 판매하고 있는 상품의 이미지를 시각화합니다.
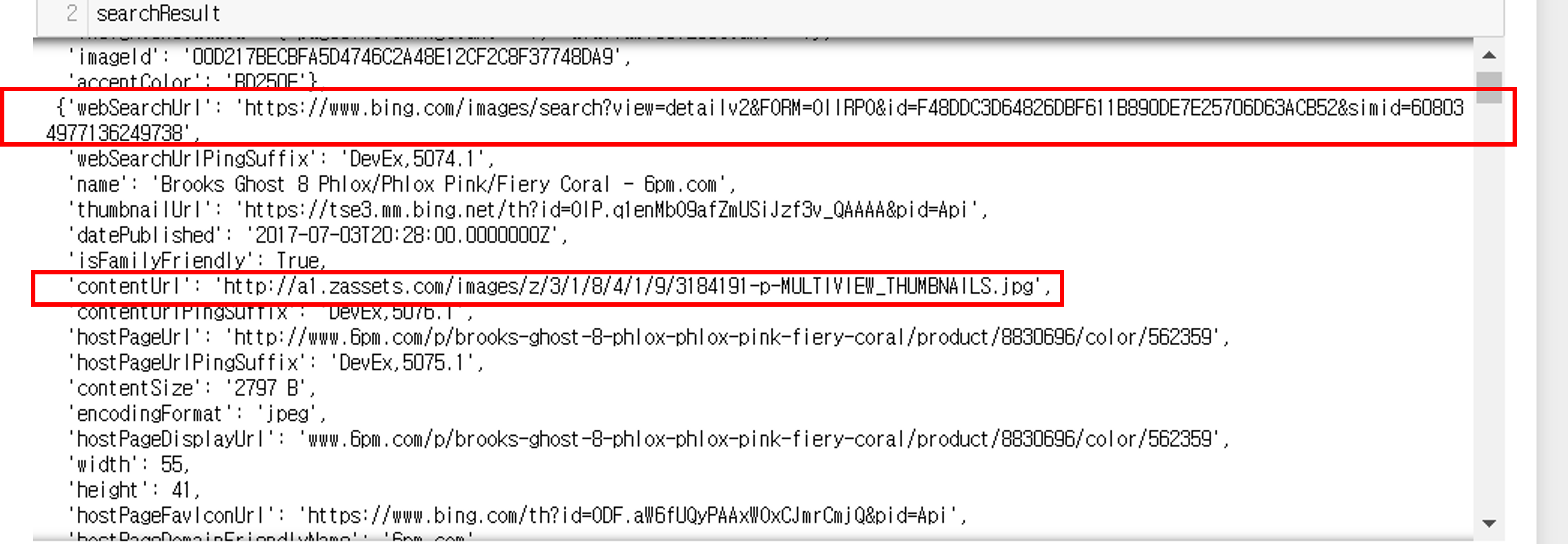
시각화되는 이미지는 API 사용 결과에서의 'contentUrl'입니다. 함께 반환되는 'webSearchUrl'을 검색하면 실제 상품을 판매하는 쇼핑몰로 이동할 수 있습니다.
결론
- 느낀 점
1. 학습을 시킬 때 모델마다 학습 환경과 데이터가 다릅니다. 학습은 각각 다른 환경에서 시키고 나중에 서비스화 할 때 하나의 환경으로 통일하는 것 일 수 있겠습니다.
2. GAN을 학습 시키는데 굉장히 많은 시간이 소요되었습니다. 코랩 환경에서 학습을 시켰기에 12시간 넘게 학습을 시키면 코랩 서버와의 연결이 끊겨버립니다. 따라서 가중치 파일을 저장하고 서버와의 접속이 정상화되면 이어서 학습을 시키는 방법을 이용하였습니다. 학습시 생성되는 산출물의 중요성을 실전 경험으로 익힐 수 있었습니다.
- 개선할 점
sketch rnn은 원하는 스케치가 있을 때 80% 정도 스케치하면 RNN 기반으로 이어질 스케치를 완성해줍니다. 이를 활용하면 러프한 사용자 스케치의 퀄리티를 높일 수 있을 거라 예상됩니다.
참고
'[프로젝트] > [AI]' 카테고리의 다른 글
| 감정인식을 활용한 실시간 노래 추천 서비스 (0) | 2023.03.08 |
|---|---|
| AI hub의 일반상식 데이터를 활용한 Question & Answering (0) | 2022.12.29 |
| 오픈소스 SW 실습 final project (0) | 2022.12.18 |


