
개발자로 후회없는 삶 살기
감정인식을 활용한 실시간 노래 추천 서비스 본문
서론
이 프로젝트는 얼굴 영상에서 감정을 인식하여 노래를 추천해주는 것을 목표로 합니다. 굉장히 기본적인 프로젝트라고 볼 수 있는데 저희는 실시간으로 영상을 계속 입력하여 모델 트래픽 처리, 안드로이드 결과 처리 등이 필요합니다. 필자가 했던 K-empowerment bootcamp에서 진행한 프로젝트입니다.
-> 데일리 회고
'[대외활동]/[K-Software Empowerment BootCamp]' 카테고리의 글 목록
hsb422.tistory.com
이 프로젝트의 전체 과정은 위 링크를 참고해 주시기 바랍니다.
-> 전체 코드
https://github.com/SangBeom-Hahn/Today_Feeling
GitHub - SangBeom-Hahn/Today_Feeling: 실시간 AI 감정 인식을 활용한 맞춤형 힐링음악 추천 서비스
실시간 AI 감정 인식을 활용한 맞춤형 힐링음악 추천 서비스. Contribute to SangBeom-Hahn/Today_Feeling development by creating an account on GitHub.
github.com
본론
- 프로젝트 주제
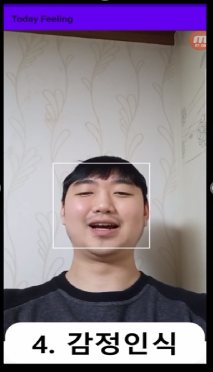

휴대폰 카메라와 컴퓨터 웹캠을 켜 놓으면 실시간으로 사용자의 얼굴을 입력 받아 현재 감정을 인식하고 현재 감정에 매칭되는 장르의 노래를 추천해주는 어플리케이션을 개발합니다. 공부나 업무를 할 때 저희 어플리케이션을 켜 놓으면 실시간으로 추천받는 노래를 통해 스트레스를 줄이고 업무 효율을 높일 수 있을 거란 기대를 가지고 있습니다.
=> 세부 목표
① github 및 jira 등 활용하여 협업
② 기획 단계와 설계 단계를 직접 수행해 봄으로써 개발 프로세스의 전체 경험
③ AI 파트
④ 학습시킨 모델을 어플리케이션에 적재 및 서비스 최적화
- 프로젝트 시작
1. github 및 jira 등 활용하여 협업
-> github : https://github.com/SangBeom-Hahn/Today_Feeling
-> jira

2. 기획 단계와 설계 단계를 직접 수행해 봄으로써 개발 프로세스의 전체 경험
① 프로젝트 기획 단계
- 프로젝트 주제 선정
- 협업 방식(커밋, 브랜치, PR)
- 타임라인 작성
- 주제 구체화
- 서비스 기능, 설계 정리
- 기획서 작성 및 발표
- 회의 방식 정립
② 프로토타입
③ 프로젝트 설계 단계
- AI 논문 조사, 코드 실행


주제에 맞는 AI 모델을 리서치합니다. 이때 일단은 논문을 읽는 것보다 코드가 있는 sota 모델을 실행해서 결과를 보는 것에만 집중합니다. 이후 돌리는 데 성공하고 목적에 맞는 결과를 낸다면 그 모델을 우리 프로젝트에 맞게 학습시키는 것에 총력을 다합니다.
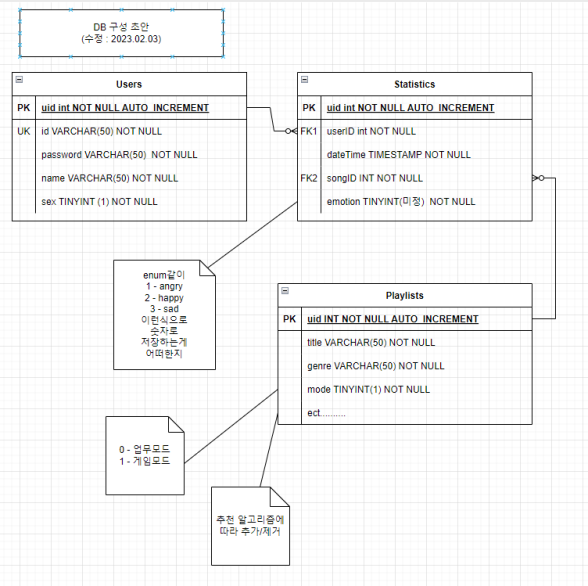
- DB 설계
- 백엔드 api 설계(기능 명세서)

기획 단계에서 필요한 기능을 정하고 설계를 정리했다면 이번엔 제대로 설계를 합니다. 백엔드의 경우 api 명세서를 작성하는 데 프론트와 데이터를 주고 받을 때 어떻게 호출하고 어떻게 반환할 건지 그리고 데이터의 형식은 뭐고 쿠키 방식인지 세션 방식인지 등, 호출 URL, get-post 방식 등 모두를 적습니다.
-> 필요한 이유
프론트 개발자가 3명있고 앱 개발자가 5명 있다고 하면 api 명세서를 작성하지 않으면 회원가입을 할 때 누구는 userid라고 하고 어떤 곳은 uid라고 합니다. 이를 방지하기 위해 누구나 보고 할 수 있도록 명세서가 필요합니다.
- 프론트엔드(+앱) UI 기능 설계(기능 명세서)
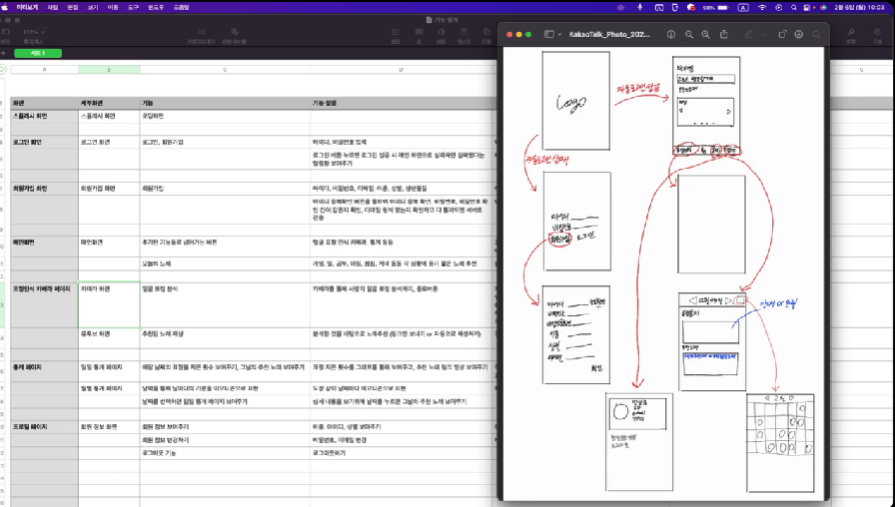



백엔드가 기능을 api로 설계했다면 프론트도 설계해야합니다. 필요한 기능별로 세세하게 어떤 처리를 해야하는지 텍스트로 정리하는 개념입니다.
+ 페이지별 기능 명세서

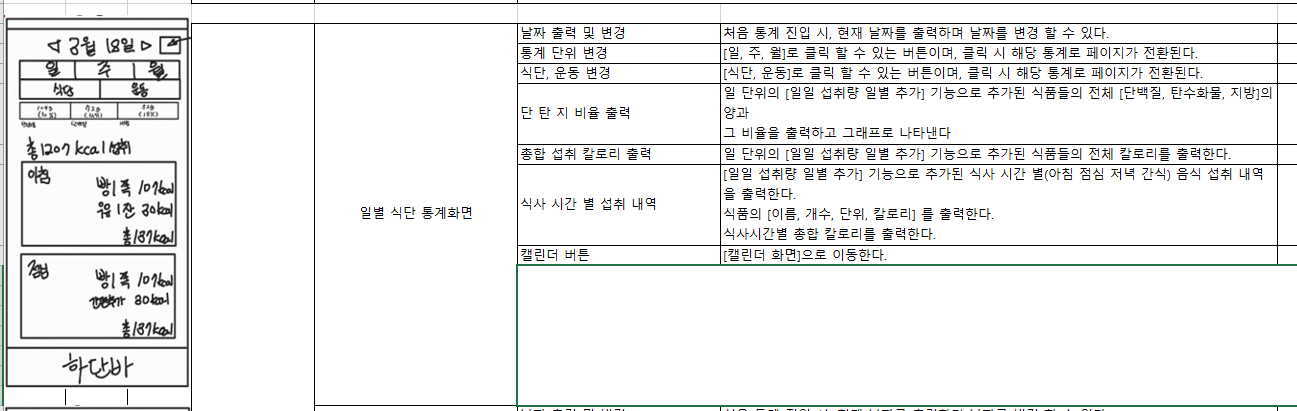
프론트에서는 위에서 기능 명세서로 큰 틀을 잡았지만 추가로 페이지별로 더욱 세세하게 하나하나 꼼꼼하게 기능을 명세합니다. 어쨌든 프론트는 페이지의 이동이기 때문에 정말 꼭 필요한 중요한 과정입니다.
3. AI 파트
1) Face Detection
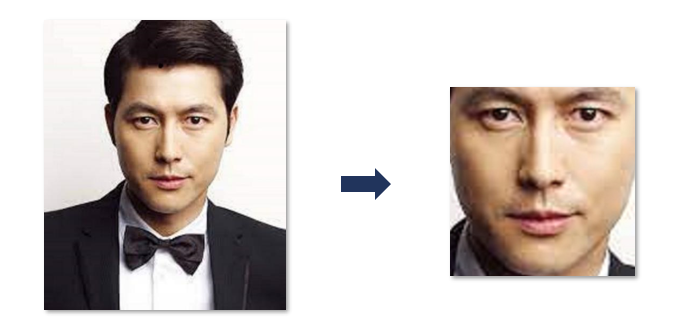
감정 인식을 하기 위해서는 얼굴에 집중하여 모델 학습을 해야합니다. 물론 행동이나 자세 등도 감정에 영향을 미칠 수 있겠지만 이는 특이사항으로 볼 수 있기에 항상 눈, 코, 입의 위치가 정해져있는 얼굴을 추출한다면 모델의 성능이 좋을 것이라고 생각하였습니다. Opencv Haar Cascades를 이용해서 전처리 해주었습니다.
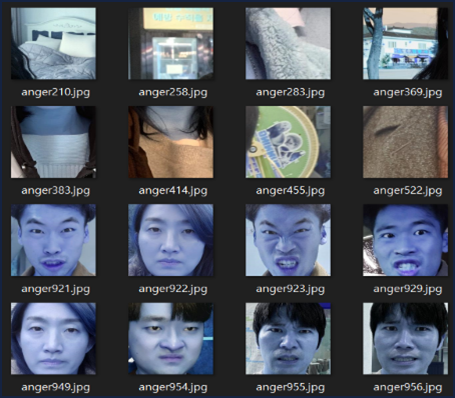
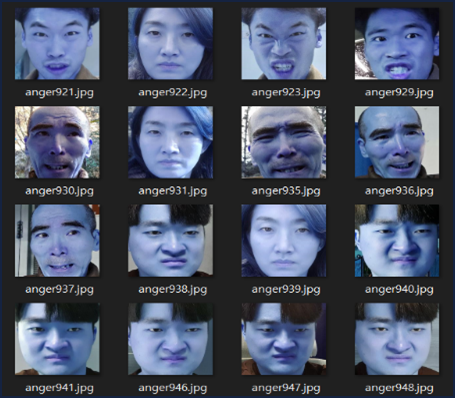
Haar Cascades는 다른 얼굴 탐지에 비해 속도가 빠르고 인자를 적절히 조절하면 다양한 크기의 얼굴을 캐치할 수 있습니다. 인자 기본값의 경우 얼굴이 아닌 것을 얼굴로 착각한 결과가 보입니다. maxSize를 주면 지정한 크기보다 큰 객체는 무시됩니다. maxSize 500으로 정확히 원본 이미지에서 얼굴만 캐치할 수 있었습니다.


하지만 실시간 얼굴 인식이 좋지 않아 전처리에서만 사용하고 안드로이드에 탑재한 모델은 MLkit를 사용하였습니다.
2) 감정 인식
① 목표(참고 1)

본 논문을 보면 얼굴에서 랜드마크를 추출하여 feature extraction을 하여 얼굴에서 감정을 인식합니다.
-> 주목할 포인트
감정은 내면의 주관이 담긴 현상으로 표정만으로 정확히 인식하기 힘듭니다. 따라서 모델 결과의 신빙성을 높이려고 노력했고 시간에 따른 알고리즘을 계산하였습니다. 일정 시간 동안 가장 높은 비율의 감정을 최종 감정으로 선정하였습니다.
② 감정 인식 모델 코드 분석
하나, 데이터 형식 및 전처리
=> 설명
| Data | 데이터 수 | Train 데이터 수 | Val 데이터 수 | 세부사항 |
| 1 | 7853 | 7199 | 654 | anger |
| 2 | 6952 | 6275 | 677 | fear |
| 3 | 7624 | 6967 | 657 | happiness |
| 4 | 7191 | 6540 | 651 | neutral |
| 5 | 7499 | 6833 | 666 | sadness |
| 6 | 6988 | 6354 | 634 | surprise |
출처 : aihub 한국인 감정 인식데이터
=> 전처리
import cv2
import glob
category = ["fear", "neutral", "sadness", "surprise"] # "fear", "neutral", "sadness", "surprise"]
for i in category:
file_path = glob.glob(f"/mnt/d/emo/한국인 감정인식을 위한 복합 영상/RealTraining/{i}/*.jpg")
k = 0
for j in file_path:
# read the input image
img = cv2.imread(j)
k += 1
# convert to grayscale of each frames
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# read the haarcascade to detect the faces in an image
face_cascade = cv2.CascadeClassifier('/home/hancom/medium/haarcascade_frontalface_default.xml')
# detects faces in the input image
faces = face_cascade.detectMultiScale(gray, 1.3, 4, minSize = (200, 200))
print('Number of detected faces:', len(faces))
# loop over all detected faces
if len(faces) > 0:
for (x, y, w, h) in faces:
# To draw a rectangle in a face
# cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 255), 2)
face = img[y:y + h, x:x + w]
cv2.imwrite(f'/mnt/d/emo/한국인 감정인식을 위한 복합 영상/cropTraining/{i}/{i}{k}.jpg', face)Haar Cascades를 이용하여 원본 이미지에서 얼굴만 crop 합니다.
둘, 모델
-> Face Landmark 추출

앞에서 말했듯이 감정은 내면의 현상으로 얼굴 픽셀값만 보고 모델이 분류하는 것은 믿을 만한 정보가 아닙니다. 따라서 얼굴에서 랜드마크를 뽑아 feature를 추가로 부여합니다. 기존 51개의 랜드마크는 얼굴 전체를 추출 대상으로 잡았지만 감정에 영향을 많이 줄 것 같은 랜드마크를 gradCAM을 통해 찾아내어 34개로 축소하였습니다.

gradCAM으로 확인한 결과 눈, 눈썹, 입꼬리를 중심으로 찾은 랜드마크 조합에서 가장 높은 정확도를 보였고, 이는 표정 분류에 중요한 feature를 추출하여 모델 성능이 올라간 것으로 확신할 수 있습니다.
③ 학습
-> Data Augmentation

저희는 모바일과 웹 캠으로 서비스할 거라서 카메라 앵글과 그림자 등에 영향을 많이 받을 수 있습니다.
# data augmentation
train_datagen = ImageDataGenerator(
rotation_range=15, # 0~10도로 회전
width_shift_range=0.15, # 왼쪽 오른쪽으로 이동
height_shift_range=0.15, # 위, 아래로 이동
shear_range=0.15, # 0.15 라디안 내외로 시계반대 방향으로 기울기
horizontal_flip=True, # 좌, 우 대칭
brightness_range = [0.2, 1.0], # 랜덤하게 밝기
)따라서 영향을 덜 받기 위한 회전, 밝기 등의 데이터 증강만 뽑아서 해주었습니다.
-> Base 모델 변경
# build model
base_model = EfficientNetB0(input_shape = (img_width, img_height, img_depth), include_top = False, weights=None)베이스 모델을 현재 이미지넷에서 가장 높은 정확도를 보인 efficientnet으로 변경하여 훈련을 하였습니다.
④ 학습 결과 test


평가 : 얼굴을 포함하는 사람 이미지를 넣으면 얼굴만 crop하고 모델에 입력하여 감정을 인식합니다.
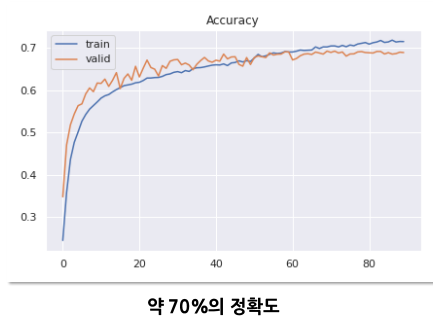
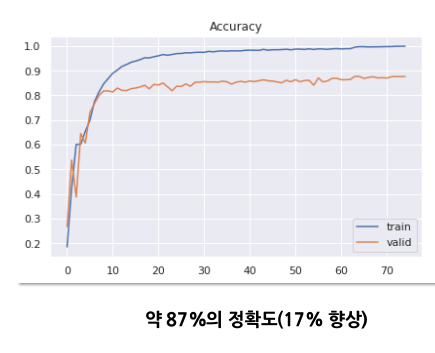
정확도를 확인해보면 기존 68개의 랜드마크를 사용한 왼쪽 그래프에 비해 17%의 정확도 향상이 있었습니다.
4. 학습시킨 모델을 어플리케이션에 적재 및 서비스 최적화
1) 목표(참고 2)
참고 2를 보면 안드로이드에서 face detection을 합니다. 저희는 이것을 캡쳐한 이미지가 아닌 실시간 웹캠에 적용할 것입니다. 프로토타입에서 봤듯이 모델은 안드로이드와 프론트에 탑재하였습니다. 그 이유는 실시간 영상처리 특성 때문에 AI 모델을 플라스크 서버에서 처리 할 시, 트래픽 과다가 예상되었기 때문입니다. 플라스크에 모델을 올릴 시 파이썬 기반 프레임워크이기 때문에 입력과 반환 처리가 쉬울 테지만 사용자가 실행활에 사용할 어플리케이션이라는 것을 감안하여 트레픽 고려하였습니다.
2) 모델 최적화

모델은 opencv로 crop한 이미지로 학습하였습니다. opencv의 경우 이미지 형식이 RGB가 아닌 BGR이었습니다. 하지만 안드로이드의 경우 또 다른 이미지 형식이기에 이를 동일하게 맞춰줘야만 학습을 시킨 성과가 있었습니다.
> 강사님께 여쭈어보니 수많은 시행착오로 맞춰보는 수밖에 없다고 하셨습니다. 저와 안드로이드 개발자 분이 최종 제출까지 수 많은 실험을 하였고 안드로이드의 이미지 형식을 비트 단위로 변환하여 BGR로 바꿀 수 있었습니다.
3) 테스트 서버
강사님께서 말씀하시기를 내가 하는 파트가 있다면 만약 AI라면 다른 개발이나 디자인이 어떻게 돌아가고 있는지 구체적으로는 아니더라도 실행은 되도록 서로 공유를 해야한다고 하셨습니다. 저는 이 점을 정말 간과하였습니다. 따라서 프로젝트가 끝난 다음에야 개발자분께 여쭤보게 되었습니다. 그에 대해 정리합니다.
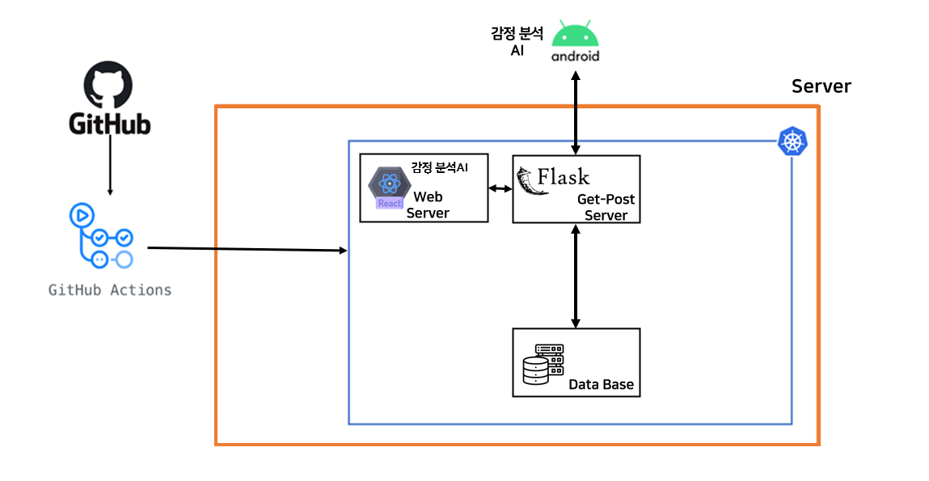
프로젝트의 전체적인 구조는 다음과 같습니다. 저는 지금까지 제 로컬에 인텔리제이에 웹 프로젝트를 만들고 그 안에 html과 jsp로 프론트를 작성하고 자바로 백엔드를 작성하였습니다. 하지만 이 프로젝트는 개발자가 웹, 앱, 서버가 모두 다르고 코드를 작성한 컴퓨터도 각 파트마다 다 달랐습니다.
-> CI/CD 개발자분 답변
① 일단 안드로이드는 깃헙에 프로젝트 root 폴더를 올린 겁니다. 그게 구글 플레이스토어에 올라가는 것과 같은 것으로 그것만 다운받으면 할 수 있는 개념으로 앱을 보면 됩니다.
② 신경 쓸 거는 웹과 서버입니다. 프론트 코드와 서버 코드는 각각 깃허브에 프로젝트 폴더가 다른 개발자들이 작성한게 올라가 있습니다. 그걸 CI/CD 개발자 분이 본인의 서버 노트북에 pull하고 모든 포트를 다 열어서 제가 localhost:8080하면 톰캣에 가는 것처럼 CI/CD 개발자 분의 노트북으로 접근할 수 있게 한 것입니다. 그렇다면 사용자는 URL로 프론트에 접근하고 그 프론트는 서버 노트북에 코드가 있고 프론트는 서버 노트북에 있는 백엔드 FLASK 코드와 데이터 교환을 하도록 되어있습니다.
③ 테스트 서버
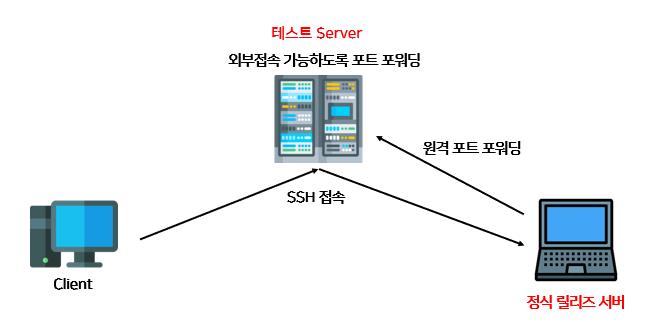
깃허브 액션은 깃허브에 push가 되거나 PR에 release 태그가 붙은게 감지된다면 자동으로 배포를 하는 개념입니다. 따라서 자동으로 배포되는 곳을 테스트 서버로 하고 테스트가 완료되면 정식 서버로 배포되도록 하였답니다. 정식 서버 배포는 CI/CD 개발자 분이 클릭해야 되도록 했답니다.
+ 시나리오 테스트

알파 테스트란 개발자가 개발한 환경에서 모든 시나리오를 실행해 봄으로써 에러가 발생하는 테스트 하는 것입니다. 이를 파일에 정의하고 테스트까지 해주었습니다.
결론
- 느낀점
1. AI를 할 때 가장 어려운게 모델링인 줄 알았는데 진짜 문제는 실제 사용할 때 환경과 학습환경이 달라서 답이 다르게 나오는 것이었습니다. 이건 정말로 경험하지 않으면 못하는 실전 경험이라고 생각합니다.
2. 개발 기획부터 배포, 테스팅까지 개발 전체 프로세스를 경험하였습니다. 또한 협업과 규칙도 정말 체계적으로 구성하였습니다.
참고
'[프로젝트] > [AI]' 카테고리의 다른 글
| AI hub의 일반상식 데이터를 활용한 Question & Answering (0) | 2022.12.29 |
|---|---|
| 오픈소스 SW 실습 final project (0) | 2022.12.18 |

