
개발자로 후회없는 삶 살기
spring PART.스프링 트랜잭션 이해 본문
서론
※ 이 포스트는 다음 강의의 학습이 목표임을 밝힙니다.
https://www.inflearn.com/roadmaps/373
우아한형제들 최연소 기술이사 김영한의 스프링 완전 정복 - 인프런 | 로드맵
Spring, MVC 스킬을 학습할 수 있는 개발 · 프로그래밍 로드맵을 인프런에서 만나보세요.
www.inflearn.com:443
본론
- 스프링 트랜잭션 소개
트랜잭션이 왜 필요한지 앞서 학습했습니다. 내부 원리를 알아봤고 이번 시간부터 더 깊이있게 학습하고 다양한 기능들을 자세히 알아보겠습니다.
-> 복습
public void accountTransfer(String fromId, String toId, int money) throws
SQLException {
Connection con = dataSource.getConnection();
try {
con.setAutoCommit(false); //트랜잭션 시작
//비즈니스 로직
bizLogic(con, fromId, toId, money);
con.commit(); //성공시 커밋
} catch (Exception e) {
con.rollback(); //실패시 롤백
throw new IllegalStateException(e);
} finally {
release(con);
}
}데이터 접근 기술들은 트랜잭션 처리에 차이가 있습니다. 둘 다 커낵션 획득하고 try해서 성공하면 커밋하고 실패하면 롤백하는 것은 같은데
EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpabook");
EntityManager em = emf.createEntityManager(); //엔티티 매니저 생성
EntityTransaction tx = em.getTransaction(); //트랜잭션 기능 획득
try {
tx.begin(); //트랜잭션 시작
logic(em); //비즈니스 로직
tx.commit();//트랜잭션 커밋
} catch (Exception e) {
tx.rollback(); //트랜잭션 롤백
} finally {
em.close(); //엔티티 매니저 종료
}
emf.close(); //엔티티 매니저 팩토리 종료트랜잭션 매니저와 em 쓰는 부분을 보면 두 개의 코드가 완전히 다릅니다. 그래서 jdbc 기술을 사용하다가 jpa로 바꾸면 트랜잭션 코드를 다 변경해야했고 스프링이 이런 문제를 해결하기 위해 트랜잭션 추상화를 제공합니다.

트랜잭션을 사용하는 입장에서는 트랜잭션 추상화를 통해 둘을 동일한 방식으로 트랜잭션을 사용할 수 있게 되는 것입니다. jdbc 탬플릿을 쓰고 서비스에 @트랜잭션을 붙이면 jdbc 트랜잭션 코드가 있는 프록시가 빈 등록되고 jpa를 쓰면 jpa 트랜잭션 코드가 있는 프록시가 등록됩니다.
> 스프링은 플랫폼 트랜잭션 매니저라는 인터를 통해 트랜잭션을 추상화했고 단순하게 트랜잭션을 획득하고 커밋하고 롤백하는 로직이 구성되어있습니다.
-> 그림

서비스에서 트랜잭션이 필요하면 플랫폼 트랜잭션 매니저 인터에 의존하고 구현체는 원하는 대로 갈아끼우면 되는 것입니다. 이것을 다 스프링이 제공해줘서 개발자가 직접 트랜잭션 인터페이스를 작성할 일이 없고 어떠한 데이터 접근 기술을 사용하는 지를 자동으로 인식하여 적절한 트랜잭션 매니저 구현체를 빈으로 등록해줍니다. 탬플릿과 Mybatis를 쓰면 데이터 소스 트랜잭션 매니저를 등록해주고 jpa를 사용하면 jpa 트랜잭션 매니저를 빈으로 등록합니다.
- 스프링 트랜잭션 사용 방식
매니저를 사용하는 방법은 2가지로 선언적과 프로그래밍 방식으로 @트랜잭션이 선언적이고 이것만 달면 됩니다. 프로그래밍 방식은 직접 try catch를 짜는 것입니다. 실무에서는 무조건 선언적으로 합니다.
-> 선언적 트랜잭션 AOP

선언적 트랜잭션을 하면 프록시 AOP가 적용됩니다. 도입전에는 서비스 로직에서 트랜잭션을 직접 지저분하게 작성하고
TransactionStatus status = transactionManager.getTransaction(new DefaultTransactionDefinition());
try {
//비즈니스 로직
bizLogic(fromId, toId, money);
transactionManager.commit(status); //성공시 커밋
} catch (Exception e) {
transactionManager.rollback(status); //실패시 롤백
throw new IllegalStateException(e);
}서비스가 직접 데이터 계층에 접근했습니다.

도입하면 트랜잭션 프록시를 자동으로 만들어주고 빈이 등록되고 프록시에서 서비스를 호출해서 사용했고 프록시가 서비스의 자식 클래스였습니다. 트랜잭션 코드는 다 프록시에 있고 비즈로직을 중간에 위임해서 호출하는 것이었습니다.
public class TransactionProxy {
private MemberService target;
public void logic() {
//트랜잭션 시작
TransactionStatus status = transactionManager.getTransaction(..);
try {
//실제 대상 호출
target.logic();
transactionManager.commit(status); //성공시 커밋
} catch (Exception e) {
transactionManager.rollback(status); //실패시 롤백
throw new IllegalStateException(e);
}
}
}적용전에는 서비스에 비즈로직과 트랜잭션 처리 로직이 섞여있었는데

적용하면 서비스 로직은 비즈로직만 깔끔하게 순수하게 남습니다.

무조건 트랜잭션 매니저를 통해 동작하고 매니저가 커낵션 조회하고 트랜잭션 시작하고 (set auto commit false), 동기화 매니저에 커낵션 보관하고 프록시에서 비즈로직을 호출하면 데이터 계층에서 동기화 매니저의 커낵션을 꺼내서 사용하는 것이었습니다. 이런 트랜잭션 매니저를 프록시 내부에서 호출하는 것이었습니다. 개발자는 트랜잭션이 필요한 곳에 @트랜잭션만 붙이면 되고 스프링의 트랜잭션 AOP가 이 어노를 인식해서 트랜잭션을 처리하는 프록시를 적용해줍니다.
- 트랜잭션 적용 확인
이제 @트랜잭션이 일어날 때 어떤 일이 일어나나 깊이있게 알아보고 여러가지 옵션들을 살펴보고 스프링 트랜잭션의 다양한 기능을 코드로 직접 알아봅니다. 트랜잭션을 적용할 때 지금 트랜잭션이 되고 있나 없나를 어떻게 확인하는지 알아봅니다.
@Slf4j
static class BasicService {
@Transactional
void tx() {
log.info("call tx");
boolean txActive = TransactionSynchronizationManager.isActualTransactionActive();
log.info("tx Active = {}", txActive);
}
void nonTx() {
log.info("call nonTx");
boolean txActive = TransactionSynchronizationManager.isActualTransactionActive();
log.info("tx Active = {}", txActive);
}
}@트랜잭션을 하면 단순히 어노 하나로 적용할 수 있는데 실제 되고 있나 확인하기 난감합니다. 확인하는 방법이 있습니다. 패키지를 만들고 Tx 테스트 클래스를 만듭니다. AOP가 동작해야하니 스프링 부트 테스트가 필요합니다. 여기서 서비스를 하나 만들고 2가지 메서드를 만듭니다. 트랜잭션이 적용되는 것과 안 되는 것입니다. 로그를 찍어서 확인하고 isActual 메서드로 트랜잭션이 있는지 없는지 바로 확인을 할 수 있습니다. 현재 이 메서드안에서 트랜잭션이 적용되어있는지 맞냐고 물어봐서 알 수 있습니다.

테스트 config를 만들고 서비스를 빈 등록하고 AutoWird를 하고 @Test 메서드를 만듭니다. 프록시가 된 것인지도 확인하고

서비스의 메서드 2개를 호출해서 트랜잭션이 적용된 것인지 확인해봅니다. 첫 번째 테스트로 트랜잭션을 적용한 메서드를 호출하지 않아도 @트랜잭션이 붙어있으면 빈 등록 시점에 프록시를 등록합니다. 실행해보면 트랜잭션이 붙은 메서드만 True가 나옵니다.
- 등록과정

스프링 컨테에 트랜잭션 프록시가 어떻게 등록되는지 살펴봅니다. @트랜잭션이 클래스나 메서드에 하나라도 있으면 트랜잭션 AOP가 프록시를 만들어서 컨테에 등록합니다. 실제 basic 서비스 대신에 CGLIB 서비스가 컨테에 등록됩니다. 그리고 프록시는 내부에 실제 서비스를 참조합니다. 실제 객체 대신에 프록시가 스프링 컨테에 들어있는게 핵심이고 AutoWired하면 프록시가 주입된다는 것입니다. 실제 basic 서비스는 등록도 안됩니다.
@Autowired BasicService basicService;프록시가 basic 서비스를 상속받아서 만들어져서 BasicService 타입으로 프록시 주입이 가능합니다.
- 동작 방식

동작방식을 보기 위해 로그를 하나 추가합니다. 프록시가 호출하는 것을 볼 수 있는 로그입니다.

그리고 tx를 호출해보면 트랜잭션 인터셉터가 tx를 호출해서 Getting 트랜잭션으로 트랜잭션을 획득했고 @트랜잭션이 붙은 메서드가 끝나면 커밋하고 completing transaction을 말해줍니다. 커밋이나 롤백하면 completing을 말해줍니다. nontx를 호출하면 트랜잭션을 하지 않기에 로그를 남기지 않습니다.
-> 그림

근데 @트랜잭션이 있으면 nonTx도 basic 서비스에 있으니 프록시가 basic 서비스 클래스 전체가 생기니 nonTx도 트랜잭션이 적용되어야 하는 것 아닌가 궁금합니다. tx를 호출하면 프록시의 tx가 호출이 됩니다. 여기서 프록시가 tx 메서드를 트랜잭션을 사용할 수 있는지 확인해봅니다. 이 메서드에 @트랜잭션이 있으니 "트랜잭션 적용이네!"라고 한번 더 확인하고 따라서 트랜잭션을 시작합니다. 그 후 커밋하고 트랜잭션을 종료합니다.
> nonTx도 호출은 프록시의 nonTx가 호출됩니다. 프록시는 클래스 단위로 만들어지기 때문에 @트랜잭션이 메서드에 있어도 클래스 전체가 프록시로 생성되고 등록됩니다. 근데 @트랜잭션이 없으니 프록시가 확인해보고 "아 트랜잭션이 아니네"하고 트랜잭션이 안 됩니다.
+ TransactionSynchronizationManager.isActualTransactionActive(로 현재 쓰레드에 트랜잭션이 적용되어있는지 가장 확실하게 확인할 수 있는 기능입니다.) 이렇게 해서 트랜잭션을 확인할 수 있는 법을 알아봤고 이제 트랜잭션이 되고 있나 확인하려면 TransactionSynchronizationManager.isActualTransactionActive()로 확인하면 됩니다.
- 트랜잭션 적용 위치
클래스 단위와 메서드 단위 @트랜잭션의 적용위치에 따른 우선순위가 있습니다. 예를들어 클래스에도 붙이고 메서드에도 붙였을 때 readonly라는 옵션이 어디에 적용될 지를 알아봅니다.
> 스프링에서 우선순위는 항상 더 구체적이고 자세한 것이 높은 우선순위를 가집니다. 이것만 기억하면 스프링에서 발생하는 대부분의 우선순위를 쉽게 기억할 수 있습니다. 그러니 메서드가 더 구체적이라서 우선순위를 가집니다.
- 테스트
@Transactional(readOnly = true)
static class LevelService{
@Transactional(readOnly = false)
public void write() {
log.info("call write");
println();
}
public void read() {
log.info("call read");
println();
}
public void println() {
boolean ac = TransactionSynchronizationManager.isActualTransactionActive();
log.info("tx active = {}", ac);
boolean readOnly = TransactionSynchronizationManager.isCurrentTransactionReadOnly();
log.info("tx readonly = {}", readOnly);
}
}Level 서비스를 만들고 클래스에는 readOnly를 t라고 하면 트랜잭션은 원래 읽기와 쓰기가 다 되는데 이렇게 하면 쓰기 작업을 할 때 못하게 되고 읽기 전용으로 트랜잭션이 만들어집니다. 메서드는 readonly f라고 합니다. 클래스 전체에 읽기 전용이 많은데 특정 메서드가 f여야해서 readonly f로 한 상황입니다. read 메서드에 readonly를 안 붙이면 클래스 단위에 붙어있어서 자동으로 T가 됩니다.
이번엔 TransactionSynchronizationManager에 지금 readonly 옵션이 뭐가 적용되고 있는지 isCurrentTransactionReadOnly 확인할 수 있습니다. 이것을 각 메서드에 출력해봅니다.
-> 실행 결과
@Test
void orderTest() {
levelService.write();
levelService.read();
}서비스를 빈으로 등록하고 write와 read를 실행해보면

처음에는 트랜잭션이 호출되고 write가 호출되고 readonly가 f가 되고 read는 t로 됩니다. write가 readonly가 f라서 클래스가 t여도 f가 우선순위가 높게 적용됩니다.
- 정리
1. 우선순위
트랜잭션을 사용할 때는 다양한 옵션을 사용할 수 있습니다. 그때 클래스에 readonly 옵션 t를 붙이고 메서드에 f를 붙이면 메서드에 f가 적용이 됩니다. 인터페이스의 경우 구현체가 더 우선순위가 높습니다. 그런데 인터페이스에 @트랜잭션을 주는 것은 권장하지 않습니다.
2. 클래스에 적용하면 메서드에 자동 적용
그리고 클래스에 작성하면 메서드에도 자동으로 적용이 됩니다. @트랜잭션이 메서드에 없는 경우에만 해당됩니다. readonly는 false가 기본값으로 읽고 쓰기가 다 됩니다.
- 트랜잭션 AOP 주의사항 프록시 내부 호출
실무에서 진짜 많이 하는 실수, 면접에서 많이 나오는 질문인 트랜잭션을 적용했는데 적용이 안 되는 경우가 있습니다. 그래서 롤백이 안 되는 경우가 있습니다. 거래에서 내 돈은 빠졌는데 다른 사람의 돈은 증가가 안되는 상황이 있습니다. 매우매우 중요한 부분입니다.
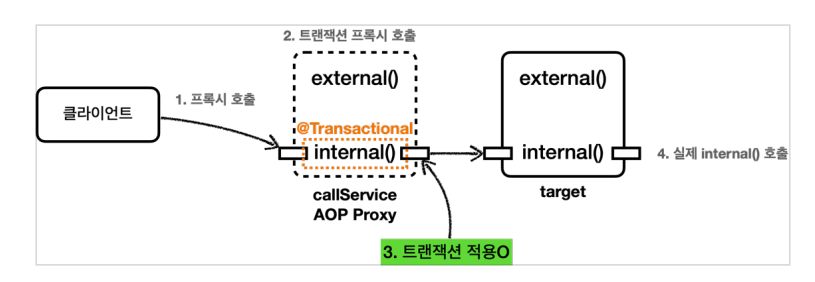
@트랜잭션을 사용하면 스프링 트랜잭션 AOP가 적용이 되고 프록시가 만들어지고 프록시 객체가 먼저 요청받아서 트랜잭션 시작하고 프록시를 통해 실제 객체를 호출해줍니다. 만약에 프록시를 거치치 않고 직접 대상 객체를 호출하면 당연히 try catch가 없으니 트랜잭션이 적용되지 않을 것입니다.
> AOP를 적용하면 대상 객체 대신에 프록시를 스프링 빈으로 등록하고 프록시 객체를 주입받아서 사용하여 대상 객체를 직접 호출하는 문제는 일반적으로 발생하지 않습니다.
> ★ 하지만 대상 객체의 내부에서 다른 메서드를 내부 호출하면 프록시를 거치지 않고 대상 객체를 직접 호출하는 문제가 발생합니다. 이렇게 되면 @트랜잭션이 있어도 트랜잭션이 적용되지 않습니다. 실무에서 반드시 한 번은 만나서 고생하는 문제라서 꼭 이해해야하고 파급효과가 크다는 것을 뇌새겨야합니다.
- 테스트
static class CallService {
public void external() {
log.info("call external");
println();
internal();
}
@Transactional
public void internal() {
log.info("call internal");
println();
}서비스를 또 하나 만듭니다. ex는 외부에서 호출하는 메서드입니다. internal은 @트랜잭션이 있는 메서드입니다. ex에서 요청이 들어오고 여기서 internal을 호출합니다. ex에는 트랜잭션이 없어도 되고 in에는 트랜잭션이 있어야하는 상황인 것입니다.
@Autowired
private CallService callService;
@Test
void internalCall() {
callService.internal();
}
@Test
void externalCall() {
callService.external();
}서비스 클래스를 등록하고 주입받으면 이 서비스는 in에 @트랜잭션이 있어서 CallService가 프록시로 주입됩니다. internel을 바로 호출하는 internalCall 메서드를 만들고

실행하면 외부에서 호출한 것이니 제대로 트랜잭션이 적용되어서 getting transaction을 하고 active가 됩니다. in 메서드는 트랜잭션이 붙었었고 이것을 callService.internal()로 직접 호출했으니 트랜잭션이 잘 적용이 된 모습입니다.

그런데 external을 호출하면 처음에 @트랜잭션이 없으니 트랜잭션이 없고 internal을 호출하면 트랜잭션이 적용이 될 것입니다. 실행해보면 트랜잭션을 하지 않습니다. ex는 @트랜이 없으니 당연히 트랜잭션을 하지 않습니다. 근데 internal도 안됩니다. getting transcation을 하지 않습니다. tx active도 false입니다.
-> 설명
internalCall은 @트랜잭션이 있으니 트랜잭션 프록시는 트랜잭션을 적용합니다. 위에서 @트랜잭션이 메서드나 클래스에 있으면 프록시가 등록이 되고 실행할 메서드를 호출하는데 @트랜잭션이 있으면 트랜잭션을 적용하고 없으면 적용하지 않는다고 했는데 @트랜잭션이 있으니 실행합니다. 지금까지 했던 service.internal()인 일반적인 방법입니다. 클라이언트에서 @트랜잭션이 붙은 메서드를 직접 호출한 것입니다.
근데 externalCall을 하면 external()을 하고 그런데 내부에서 internal을 호출하고 이 경우 트랜잭션이 적용이 안 됩니다. 트랜잭션이 아닌 실제 callService에서 남긴 로그만 확인됩니다.
-> 이러한 발생 이유

실제 호출되는 흐름을 보겠습니다. 클라에서 (service.으로 호출하는 것이 컨트롤러에서 하는 것으로 컨트가 클라입니다.) external을 호출합니다. 이는 external이 속한 서비스 클래스의 메서드 하나라도 @트랜잭션이 있어서 프록시의 external을 호출합니다. ex에는 @트랜잭션이 없어서 트랜잭션을 적용하지 않고 넘깁니다. 실제 타겟 서비스 클래스의 ex를 호출합니다.
> 그런데 문제는 ex 내부에서 in을 호출합니다. 이러면 프록시를 거치지 않고 내 꺼를 그냥 호출한 것입니다. 트랜잭션을 적용하려면 다 트랜잭션 코드가 프록시에 있는데 그것을 다 무시하고 타겟 클래스에서 내꺼를 호출한 것입니다.
void external() {
println();
internal();
}왜냐하면 자바에서는 앞에 생략하면 this.internal가 됩니다. 따라서 타겟 클래스의 in이 호출됩니다. 그러니 당연히 트랜잭션 코드가 없어서 트랜잭션이 적용이 안 됩니다. in은 트랜잭션이 필요한 코드인데 트랜잭션이 안되어서 계좌이체라면 내 돈은 나가고 상대 돈은 안 나가는 상황이 발생할 수 있습니다.
- 프록시 방식의 AOP 한계
그래서 트랜잭션이 적용이 안됩니다. @트랜잭션을 만들면 프록시를 만들고 프록시에서 트랜잭션을 다 적용하는 것인데 그러면 @트랜잭션이 안붙은 메서드 내부에서 호출이 일어나면 this 때문에 프록시를 적용할 수 없습니다. @트랜잭션이 붙은 메서드에서도 트랜잭션이 적용되고 타겟 클래스의 메서드를 호출하기에 무조건 시작 메서드가 트랜잭션이 되든 안 되는 메서드 내부에서 호출이 일어나면 프록시가 적용이 안 되고 트랜잭션도 적용이 안 됩니다.
어떻게 해결할 수 있을까요? 실제 로직에 트랜잭션 코드를 넣는 방법이 있습니다. 근데 설정이 너무 어려워서 잘 사용하지 않습니다. 그래서 실무에서는 interanal 메서드를 별도의 클래스로 분리합니다. 즉 무조건 트랜잭션이 적용되어야하는 메서드는 분리해서 사용해야 하는 것입니다.
- 새로운 테스트
static class InternalService {
@Transactional
public void internal() {
log.info("call internal");
println();
}
public void println() {
boolean ac = TransactionSynchronizationManager.isActualTransactionActive();
log.info("tx active = {}", ac);
}
}in을 아예 다른 클래스로 만드는 것입니다. 그러면 내부 호출이 아닌 외부 호출로 바뀌게 됩니다. 클래스 자체를 분리합니다.
@Slf4j
@RequiredArgsConstructor
static class CallService {
private final InternalService internalService;
// 이전
public void external() {
log.info("call external");
println();
internal();
}
// 이후
public void external() {
log.info("call external");
println();
internalService.internal();
}
public void println() {
boolean ac = TransactionSynchronizationManager.isActualTransactionActive();
log.info("tx active = {}", ac);
}
}그러면 원래 CallService에서 internalService를 주입받아서 써야하고 internal()을 internalService.internal()인 외부호출로 바꿔서 this.를 internalService.으로 내부호출을 외부호출로 바꿉니다.

외부호출이면 무조건 AOP가 호출이 됩니다. 모든 주입받아서 호출되는 것은 등록된 프록시 클래스가 먼저 사용되기 때문입니다. 실행해보면 internal이 외부호출로 트랜잭션이 적용되어서 잘 동작합니다.
-> 그림

클라가 처음에 CallService에서 ex를 호출합니다. 얘는 주입받은 internal 서비스의 internal()을 호출하고 인터널 서비스는 @트랜잭션이 있어서 프록시입니다. 따라서 트랜잭션이 적용된 internal()이 호출됩니다. 실무에서는 이렇게 별도의 클래스로 분리하는 방법을 사용합니다.
- public 메서드만 트랜잭션 적용

스프링의 트랜잭션 AOP 기능은 public 메서드에만 트랜잭션을 적용하도록 기본 설정이 되어있습니다. 그래서 그 외 접근 지정자는 트랜잭션이 적용이 안됩니다. 스프링이 public 외에는 다 막아둔 것입니다.
> @트랜잭션이 붙은 클래스에 다양한 접근 지정자의 메서드가 있어도 public이 붙은 메서드만 트랜잭션을 적용합니다. private나 protected는 애초에 트랜잭션을 걸고 싶지 않는 단순한 경우가 대부분입니다. 트랜잭션이 의도하지 않은 곳까지 트랜잭션이 과도하게 걸릴까봐 스프링이 막아놨습니다. public이 아니면 트랜잭션을 적용하는 경우가 없습니다. public이 아닌 곳에 @트랜잭션이 붙어있으면 예외는 아니고 트랜잭션 적용만 무시됩니다.
- 트랜잭션 AOP 초기화 시점
스프링 초기화 시점에는 트랜잭션 AOP가 적용되지 않을 수 있습니다. PostConstruct가 초기화 메서드인데 여기서 @트랜잭션이 있으면 적용이 안됩니다. 분명 초기화를 트랜잭션 안에서 하고 싶은 경우가 있을텐데 안됩니다.
-> 테스트
static class Hello {
@PostConstruct
@Transactional
void initV1() {
println();
}
public void println() {
boolean ac = TransactionSynchronizationManager.isActualTransactionActive();
log.info("tx active = {}", ac);
}
}
클래스를 만들고 post에 트랜잭션을 적용하고 빈으로 등록하고 그 안에 isAutal을 적습니다. 그러면 컨테이너가 뜨고 빈에 등록될 시점에 post가 수행될 것입니다.
public class InitTxTest {
@Autowired
private Hello hello;
@Test
void go() {
}따라서 go() 메서드에 아무것도 하지 않아도 컨테이너가 뜰 때 초기화 메서드를 호출해 줄 것입니다.

해보면 active가 false가 나옵니다. 초기화 코드에 트랜잭션을 함께 사용하면 트랜잭션이 적용이 안 됩니다. 실제 타겟 클래스 메서드가 호출됩니다. 왜냐면 초기화 코드가 먼저 호출되고 그 다음 트랜잭션 AOP가 적용되기 때문입니다.
-> 대안
static class Hello {
@PostConstruct
@Transactional
void initV1() {
println();
}
@EventListener(ApplicationReadyEvent.class)
@Transactional
void initV2() {
println();
}따라서 대안은 초기화 시점 말고 초기화 시점과 비슷한 스프링 컨테이너 다 만들고 준비 완료한 시점에 얘를 호출하게 하는 것입니다. 바로 EventListener에서 ready 이벤트를 하면 됩니다. 이러면 스프링 컨테이너가 다 떴다는 뜻은 빈, AOP, 컨테이너가 완전히 완성됐다는 의미입니다. 그러니 당연히 AOP가 적용된 상태에서 init이 적용됩니다.

실행해보면 post는 false가 나오고 그 다음에 event가 true가 나옵니다. 그만큼 post가 AOP 적용 전에 호출된다는 것을 알 수 있습니다. 따라서 트랜잭션 안에서 초기화를 해야하면 ReadyEvent를 클래스의 PostConstruct를 붙여야하는 메서드에 대신 붙여주면 됩니다.
- 트랜잭션 옵션 소개
1. value

트랜잭션을 사용하려면 먼저 스프링 빈에 등록된 매니저 중에서 어떤 매니저를 사용할지 알아야합니다. @트랜잭션을 할 때 이를 생략하면 기본으로 등록된 매니저를 사용하기 때문에 대부분 생략합니다. 근데 트랜잭션 매니저가 둘 이상이면 이름을 지정해야합니다. 즉 하나의 클래스에 jdbc와 jpa 트랜잭션 코드가 같이있으면 value를 써야하고 value 자체는 생략해도 됩니다.
2. rollbackFor
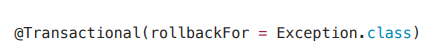
예외가 발생하면 기본 정책은 언체크 예외는 다 롤백하고 체크 예외는 커밋합니다. 그런데 "나는 Exception 예외는 커밋할 때도 롤백하고 싶다" 할 때가 있습니다. rollbackFor를 사용하면 기본 정책에 어떤 예외가 발생할 때 롤백할지 지정할 수 있습니다. 이렇게 하면 체크 예외가 발생해도 롤백할 수 있게 합니다.
3. noRollBackFor
위에 반대로 어떤 예외가 발생했을 때 롤백하면 안 되는지 지정할 수 있습니다. 보통 이것은 많이 안 쓰고 위를 씁니다.
4. isolation

트랜잭션 격리 수준을 지정하는 것으로 이전에 키멋된 읽기를 많이 사용한다고 했던 그것으로 어떤 트랜잭션마다 다 다르게 지정할 수 있습니다. 기본은 커밋된 읽기로 커밋을 해야만 다른 세션에서 볼 수 있는 것입니다.
6. readOnly
트랜잭션은 기본적으로 읽기 쓰기가 다 가능합니다. T를 하면 읽기 전용으로 트랜잭션이 생성이 되고 이 경우 해당 트랜잭션에서는 등록, 수정, 삭제가 안되고 select만 됩니다. 사용되는 곳이 크게 3개입니다.
1) 프레임워크
탬플릿을 예로 들면 탬플릿은 읽기 전용 트랜잭션에서 변경 기능을 호출하면 예외를 던집니다. 당연히 읽기 전용인데 쓰려고 하니 잘 못 호출된 것이라서 예외입니다. JPA는 데이터 변경을 하려면 플러시를 해서 복잡한 과정을 하는데 읽기 전용이면 그것을 생략합니다. 읽기 전용이면 어차피 변경이 안 될 것이니 플러시 자체를 호출할 필요가 없습니다. 따라서 변경이 안 일어나게 되니 플러시 자체를 없애버리고 이게 플러시가 안되는 것 만으로 스프링이 성능 최적화를 하는 것입니다.
+ 추가로 jpa는 변경 감지로 스냅샷을 가지고 있는데 이것도 변경이 있을 때만 하는 것이니 읽기 전용이면 스냅샷도 안 합니다.
2) JDBC 드라이버
얘는 읽기 전용 트랜잭션에서 변경이 발생하면 아예 예외를 던집니다.
3) 데이터베이스
db에 따라서 읽기 전용이면 "이 트랜잭션이 읽기만 하네?"하고 내부에서 쓰기에 대한 부분을 고민하지 않아도 되고 읽기에 대해서만 신경쓰도록 내부에서 성능 최적화가 됩니다. 결론적으로는 읽기 전용을 하면 쓰기를 안해도 되니 내부에서 최적화가 많이 일어납니다.
- 예외와 트랜잭션 커밋, 롤백

트랜잭션 커밋과 롤백이 예외에 따라 동작하는 것을 알아봅니다. 예외가 발생했는데 내부에서 예외를 처리하지 못하고 트랜잭션 범위 밖으로 예외를 던지면 어떻게 될까요? 레포에서 발생해서 던지고 던져서 트랜잭션까지 오면 발생한 예외가 언체크면 롤백하고 체크면 커밋합니다.
- 테스트
이렇게 일어나나 확인해봅니다. 체크에서는 왜 커밋하는지도 알아봅니다. 정적 클래스를 하나 만들고 언체크가 일어나면 서비스 프록시에서 롤백하는 것과 체크가 일어나면 서비스 프록시에서 커밋하는 것, 체크 예외가 일어났는데 reollbackfor로 지정하면 체크라도 롤백하는 3가지를 알아봅니다.
1) 런타임 예외 롤백
static class RollBackService {
@Transactional
void RuntimeEx() {
log.info("call RuntimeEx");
throw new RuntimeException();
}throw new RuntimeEx로 런타임 예외를 던져서 롤백하게 합니다.
2) 체크 예외 커밋
@Transactional
void UnRuntimeEx() throws MyEx {
log.info("call UnRuntimeEx");
throw new MyEx();
}
static class MyEx extends Exception {
}체크 예외로 커밋되나 봅니다. 체크 예외를 하니 잡거나 throw로 던지거나 합니다. 트랜잭션에서 체크 예외가 발생하면 커밋을 해야합니다. "예외가 일어났는데 왜 커밋하지?" 싶습니다.
3) rollbackfor
@Transactional(rollbackFor = Exception.class)
void RollBackEx() throws MyEx {
log.info("call RuntimeEx");
throw new MyEx();
}체크 예외지만 MyEx는 예외가 발생해도 정책처럼 커밋하지 말고 롤백하도록 지정합니다. 서비스를 등록하고 주입받고 테스트를 돌려봅니다.
- 결과
1) 런타임 예외를 호출

트랜잭션 로그는 getting과 comp만 보여주고 커밋하거나 롤백하면 comp가 되는 것이라서 롤백인지 커밋인지 정확히 모릅니다. > 이를 로그로 확인하는 방법이 있습니다. 프로퍼티스에 추가합니다. 우리는 JPA 트랜잭션 매니저를 쓰기 때문에 테스트를 돌리면 jpa 트랜잭션 매니저가 로그를 남기기 시작합니다. 굉장히 상세하게 나오는데 트랜잭션을 만들고 만들 때 @트랜잭션이 붙은 메서드의 이름으로 만들어집니다. ( ex) runtimeEx )

그리고 rollback을 합니다. 언체크 예외가 터지면 트랜잭션이 롤백을 하는 것을 확인할 수 있습니다.
2) 체크 예외를 호출

체크 예외가 터지면 커밋이 되어야합니다. 로그를 보면 commit합니다.
3) rollbackfor

어떤 체크 예외는 롤백하고 싶습니다. MyEx가 체크 예외지만 커밋해야 하는데 롤백할 수 있습니다.
- 예외, 트랜잭션 커밋 롤백 활용
"왜 체크예외는 커밋하고 언체크를 롤백하지?"를 알아봅니다. 스프링은 기본적으로 체크는 비즈니스 의미가 있을 때 사용하고 런타임은 복구 불가능한 예외로 가정하고 정의합니다. 스프링의 가정이지 꼭 따를 필요없고 그때는 rollbackfor로 다 롤백하면 됩니다.
-> 비즈니스 의미란?
복구 불가능한 예외는 시스템에서 발생한 OOM, 네트워크 오류 등으로 이건 시스템에서 잡아 올린 예외이고 복구를 할 수 없고 공통처리부에서 처리하고 고객님께 "죄송합니다"라고 안내해야합니다. 런타임 예외는 이렇게 다 스프링 추상화 예외로 던져서 공통 처리부에서 처리합니다.
ex) 비즈니스 요구사항

예를 들어서 주문 시스템을 만듭니다. 주문을 하는데 3가지의 요구사항이 있습니다.
1) 정상인 경우
주문시 고객이 계좌나 카드로 입금해서 주문하기를 누르면 결제에 성공하면 주문 데이터를 저장하고 결과 완료를 합니다. 주문과 결제 상태 모두 성공하는 상황입니다.
2) 시스템 예외 요구사항
예외가 발생합니다. 이때 시스템 예외가 터져서 복구 불가능하다면 전체 데이터를 롤백해야합니다. 이게 요구사항으로 시스템이 복구가 안 되는 예외가 터지면 절대로 해결할 수 없으니 이런 건 다 런타임으로 처리합니다. 그래서 런타임은 복구가 불가능하다는 전체가 있고 시스템에서 발생한 오류고 복구가 안 된다는 뜻입니다.
3) 비즈니스 예외 요구사항
결제 잔고가 부족할 수 있습니다. 이때 우리의 요구사항을 이렇게 가정합니다 "주문 시 잔고가 부족하면 주문 데이터를 저장하고 결재 상태를 대기로 처리"합니다. 이 경우 고객에게 잔고 부족을 알리고 별도의 계좌로 입금하도록 안내하고 싶습니다. 고객이 별도의 계좌로 입금하면 대기를 완료로 바꿀 것입니다.
-> 정리
이때 잔고가 부족하면 NotEnoughMoneyException라는 체크 예외가 발생하도록 개발을 했다고 가정하였습니다. 이 예외는 시스템 예외가 아니고 정상 동작했습니다. 비즈니스 상황에서 문제가 되어서 발생한 예외입니다. 이런 예외를 비즈니스 예외라고 하고 이때는 반드시 처리해야하니 체크 예외를 고려할 수 있는 것입니다. > 이런 가정이 있는 것입니다. 비즈니스 예외는 체크로 잡아야 하고 커밋해야하는 예제를 이해하기 위한 가정입니다.
※ 예제

이전에 로직 상으로 문제가 발생했을 때 서비스에서 잡고 싶으면 잡을 수 있다고 했습니다. 이것이 비즈니스 로직 상 반드시 잡아야하는 예외면 이렇게 잡는다는 것이고 체크를 하는 이유는 throw를 선언해야하니 안 잡고 던지지도 않으면 컴파일 오류로 개발자에게 알려주기 때문입니다.
- 구현
-> 예외
public class NotEnoughMoneyException extends Exception{
public NotEnoughMoneyException(String message) {
super(message);
}
}app을 만듭니다. NotEnoughMoneyException를 만듭니다. 체크 예외로 만들 것이고 기존 매세지 정도만 받을 것이고 결제 잔고가 부족하면 발생하는 비즈니스 예외이고 체크 예외면 롤백을 안 하고 커밋하고 싶은 것입니다.

위에서 "비즈로직 예외가 발생하면 커밋을 칠 것이고 결제 상태를 대기로 처리할 것이고 고객에게 안내를 할 것입니다"라고 요구사항을 정했으니 롤백을 하면 안되는 것입니다. 저장하고 대기하고 잔고 부족 알려서 별도의 계좌로 다시 해야하니 롤백하면 안되고 롤백하면 데이터가 다 사라지고 고객이 뭘 주문했는지 다 사라지는 것이라서 롤백하면 안 됩니다. 따라서 비즈로직 예외를 커밋해야해서 체크 예외로 만드는 것입니다.
-> 주문 객체
@Entity
@Data
@Table(name = "orders")
public class Order {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String username; //정상, 예외, 잔고부족
private PayStatus payStatus; //대기, 완료
}주문을 위해 jpa를 사용할 객체를 만듭니다. id와 고객명, 결제 상태를 가지고 있고 주문한 고객의 이름이 뭐냐에 따라서 정상, 예외, 잔고부족을 할 것이고 상태는 (대기와 완료)입니다. jpa를 쓸 것이니 entity를 넣고 table을 넣으면 맵핑을 하는 것으로 Order 객체는 orders 테이블과 관리되는 것입니다. db의 order by 때문에 order 테이블 명은 못 만들어서 주문은 db에서 orders라고 많이 만듭니다. 테이블을 내장으로 자동으로 만들 것이라서 orders라고 해야합니다.
public enum PayStatus {
COMP("정상"),
WAIT("대기");
String desc;
PayStatus(String desc) {
this.desc = desc;
}
public String getDesc() {
return desc;
}
}원래 상태는 enum을 쓰는게 맞습니다.
- 레포지토리
public interface OrderRepository extends JpaRepository<Order, Long> {
}이것을 등록, 수정, 삭제, 조회하기 위해 가장 편리한 스프링 데이터 JPA를 만듭니다. 이렇게 하면 끝입니다.
- 서비스
@Slf4j
@RequiredArgsConstructor
@Service
public class OrderService {
private final OrderRepository orderRepository;서비스에서 등록, 수정, 삭제, 조회하기 위해 스프링 데이터 JPA를 주입받습니다.
-> 주문 메서드
여기에 비즈니스 요구사항을 주문 로직으로 만듭니다. 시스템 예외가 터지는 것과 비즈니스 예외가 터진 것을 생각해야 하고 여기서 런타임과 체크 예외마다 어떻게 커밋, 롤백이 동작하나 볼 것입니다.
@Transactional
public void order(Order order) throws NotEnoughMoneyException {
log.info("order 호출");
orderRepository.save(order);
log.info("결제 프로세스 진입");
if (order.getUsername().equals("예외")) {
log.info("시스템 예외 발생");
throw new RuntimeException("시스템 예외");
} else if (order.getUsername().equals("잔고부족")) {
log.info("잔고부족 비즈 예외 발생");
order.setPayStatus(PayStatus.COMP);
throw new NotEnoughMoneyException("잔고가 부족해요");
} else {
log.info("정상 승인");
order.setPayStatus(PayStatus.COMP);
}
log.info("결제 프로세스 완료");
}먼저 주문 데이터를 저장합니다. 일단 저장하는게 비즈로직 요구사항이었습니다. 그리고 결제를 합니다. 결제를 하고 있는데 사용자 이름이 예외면 시스템 예외가 터진 것으로 아무것도 못하는 복구 불가능한 상황이니 런타임 예외를 터뜨립니다.
사용자 이름이 잔고부족이면 비즈 로직 예외가 생깁니다. 잔고 부족이면 주문 상태를 대기로 바꾸고 잔고 부족 예외를 터뜨립니다. 체크예외라서 throw를 선언해야 합니다.
> 그리고 정상 승인이 되면 주문을 완료 상태로 처리합니다. 항상 서비스에 비즈 로직을 작성하는 것을 알아야합니다. 데이터 계층은 데이터에 접근만 하고 서비스에 비즈 로직을 작성합니다. 클라가 컨트롤러에서 주문을 폼으로 입력해서 MA로 받고 서비스에 인자로 넣어 비즈로직을 실행하는 상황입니다.
+ 잔고 부족은 상태는 대기되지만 order 객체의 데이터는 커밋되기를 기대하는 것입니다. 예외가 발생했는데 커밋되기를 기대하는 것입니다. 그래야 사용자의 데이터를 저장하고 사용자에게 잔고가 부족하니 다른 계좌를 쓰라고 안내를 할 수 있습니다.
- 테스트
주문 비즈니스 요구사항에 맞게 동작하나 보는 테스트 예제를 만듭니다.
1) 완료 테스트
@Test
void order() throws NotEnoughMoneyException {
Order order = new Order();
order.setUsername("정상");
orderService.order(order);
Order findOrder = orderRepository.findById(order.getId()).get();
assertThat(findOrder.getPayStatus()).isEqualTo(PayStatus.COMP);
}정상 주문이 들어왔을 때 저장이 잘 될 것입니다. 저장한 주문과 찾은 주문이 같을 것이고 결재 상태가 완료가 되어야합니다. 근데 돌려보면 테이블을 create 추가한 적이 없는데 테스트가 됩니다.

프로퍼티스에 추가하고 로그를 보면 스프링이 뜰 때 create table order를 합니다. 별도의 설정이 없으면 entity를 보고 테이블을 메모리 db에 만들어줍니다. 테스트할 때 schema.sql은 최소한으로 해줬어야 했는데 jpa를 쓰면 그것도 없어 해결해줍니다.

실행해보면 저장이 되고 상태 완료가 성공합니다. 또한 update도 있는데 스프링 데이터 JPA의 update 쿼리를 service의 order 메서드의 order에 set만 해도 다 jpql을 만들어줍니다. jpa는 커밋되어야 jpql이 나온다고 했는데 정상 흐름이니 커밋된 것도 확인할 수 있습니다.
2) 시스템 오류 테스트
@Test
void runTime() throws NotEnoughMoneyException {
Order order = new Order();
order.setUsername("예외");
orderService.order(order);
Optional<Order> orderOptional = orderRepository.findById(order.getId());
assertThat(orderOptional.isEmpty()).isTrue();
}시스템 오류로 런타임 예외가 터진 상황입니다. 주문의 이름이 예외라서 서비스에서 예외가 터진 것입니다. 얘는 런타임이라 롤백이 되어야하니 저장된 데이터가 없어야합니다. 따라서 테스트에서 저장한 것을 꺼냈을 때 findById가 옵셔널이니 옵셔널은 값이 있는지 없는지 확인할 수 있어서 isEmpty를 해서 이게 참이어야합니다.
> 시스템 예외는 런타임 예외였고 런타임 예외는 트랜잭션이 롤백하는 것이 정책이었습니다. 따라서 고객 주문 데이터가 DB에 없어야합니다.

로그를 보면 시스템 예외 발생 예외가 터지고 롤백합니다. 따라서 원래 요구사항에서 무조건 데이터 저장부터 하는데 시스템 예외가 터져서 롤백합니다. insert 쿼리 조차 안 보입니다. 원래 커밋 시점에 insert 쿼리를 날리는데 롤백이 되면 안 날립니다. 시스템에 문제가 생기면 다 롤백하는 것입니다.
3) 비즈니스 오류 테스트
@Test
void bizEx() throws NotEnoughMoneyException {
Order order = new Order();
order.setUsername("잔고부족");
try {
orderService.order(order);
} catch (NotEnoughMoneyException e) {
log.info("고객에게 알림");
}
Order order1 = orderRepository.findById(order.getId()).get();
assertThat(order1.getPayStatus()).isEqualTo(PayStatus.WAIT);
}얘는 잔고부족으로 체크 예외가 터져야하고 try로 잡아서 고객에게 잔고 부족을 알리고 안내합니다. 서비스를 호출하는 컨트롤러의 controladvice에서 이렇게 작성한 것입니다.
> 얘는 체크 예외라 저장이 되고 커밋이 되고 대기 상태로 된다고 했으니 저장한 데이터가 있어야하고 상태가 대기가 되어야합니다. 예외가 터졌는데 커밋을 하기를 기대하는 것입니다. 왜냐면 커밋을 해야 예외가 터지더라도 고객에게 잔고 부족을 안내하고 별도의 계좌로 입금할 수 있는 비즈니스 상황이기 때문입니다. 예외가 터지고 커밋한 것입니다. 예외와 커밋을 별개로 둘다 일어나야하고 잡는다고 안일어나는게 아닙니다.
+ 그니깐 서비스를 호출한 측에서 예외를 잡는 로직을 하게 하기 위해서 체크 예외는 커밋이 되도록 트랜잭션 매커니즘이 짜인 것입니다. 철저히 비즈로직에 맞춰서 동작하게 하면 됩니다.

로그를 보면 커밋이 되고 jpa는 커밋을 해야 변경하니 그때 insert, update도 일어납니다. 롤백이 안 되서 jpql을 jpa가 만듭니다. 정말 스프링은 웹 어플리케이션을 만들기 위한 프레임워크로 정책이 되어있는 것입니다.
- 정리
체크 예외를 비즈로직에서 어떻게 활용하는지 예제로 확인했습니다. 이건 마치 예외가 예외가 리턴 값처럼 사용된 것입니다. 비즈 문제 상황을 예외를 통해 알려준 것입니다. 예외를 던져서 서비스를 호출한 측에서 잡으라고 예외로 알려준 것입니다. 지금 이 비즈니스 상황에 이게 맞는 것입니다. 비즈상황에서도 체크 예외를 롤백하려면 rollbackfor하면 됩니다.
결론
정말 서비스에서 예외처리가 70이라는 것이 무슨 말인지 알겠습니다. 이렇게 스프링의 기본 컨셉을 활용하여 예외처리하면 효율적으로 비즈니스 로직을 만들 수 있습니다.
'[백엔드] > [spring | 학습기록]' 카테고리의 다른 글
| spring PART.트랜잭션 전파 활용 (0) | 2023.05.23 |
|---|---|
| spring PART.트랜잭션 전파 기본 (0) | 2023.05.22 |
| spring PART.데이터 접근 기술 활용 방안 (0) | 2023.05.19 |
| spring PART.Querydsl (0) | 2023.05.18 |
| spring PART.중간점검 4 (0) | 2023.05.17 |



