
개발자로 후회없는 삶 살기
spring PART.데이터 접근 기술 활용 방안 본문
서론
※ 이 포스트는 다음 강의의 학습이 목표임을 밝힙니다.
https://www.inflearn.com/roadmaps/373
우아한형제들 최연소 기술이사 김영한의 스프링 완전 정복 - 인프런 | 로드맵
Spring, MVC 스킬을 학습할 수 있는 개발 · 프로그래밍 로드맵을 인프런에서 만나보세요.
www.inflearn.com:443
본론
- 스프링 데이터 JPA 예제와 트레이드 오프
여러가지 배운 데이터 접근 기술을 실무에 사용할 때 팁을 배워봅니다.

스프링 데이터 JPA 예제를 보면 서비스가 레포 구현체V2를 사용하고 레포가 스프링 데이터 JPA 프록시 구현체를 썼습니다. 중간에서 레포 구현체 V2가 어댑터 역할을 해서 서비스 코드를 전혀 변경하지 않아도 되는 장점이 있었습니다.
-> 고민
여기서 고민이 있습니다. OCP를 맞추기 위해서 중간에 어댑터가 들어가서 구조적으로 복잡하고 클래스도 많습니다. 그냥 서비스에서 스프링 데이터 JPA 구현체를 쓰면 편리해지지 않을까 싶습니다.
유지보수 관점에서 보면 서비스를 변경하지 않고 레포를 변경할 수 있는 좋은 점이 있지만 구조가 복잡해지면서 어댑터 코드와 실제 코드 둘 다 유지보수해야하는 문제가 생깁니다. DI를 위해서 유지보수 할게 더 생기는 것입니다.
> 지금까지 맨날하던 얘기와 다른 얘기를 하고 있습니다. 맨날 DI가 제일 중요하다고 말했는데 사실 실용성을 위해서 구조, DI 등 여러가지 고민이 필요합니다. 생각보다 몇 가지를 더 고민해야합니다.
-> 다른 선택
private final ItemRepository itemRepository;
private final SpringDataJpaItemRepository repository;
@Override
public Item save(Item item) {
repository.save(item);
return itemRepository.save(item);
}그냥 서비스 코드를 직접 스프링 데이터 JPA 코드를 쓰는 것입니다.

이러면 DI를 포기하는 대신 구조를 단순하게 가져가는 트레이드 오프가 있습니다.
- 트레이드 오프
구조의 안정성이냐(DI), 개발의 편리성냐의 문제로 둘 중에 정답이 없습니다. 어떤 상황에서는 구조의 안정성이 매우 중요할 수 있고 어떤 때는 단순한게 중요할 수도 있습니다. 단순한 플젝이고 확장이 일어나지 않을 상황이면 절대로 DI의 구조를 신경쓰는게 중요하지 않습니다. (제가 한 중간 점검은 개발의 편리성을 선택해야합니다.) 어설픈 추상화는 독이 될 수 있습니다. 추상화는 더 개발비용이 들기 때문입니다. 추상화 비용을 넘어설 만큼 효과가 있을 때 추상화를 선택합니다. 따라서 현재 상황에 맞는 선택을 하는 개발자가 좋은 개발자입니다.
- 실용적 구조
private final EntityManager em;
private final JPAQueryFactory query;
public JpaRepositoryV3(EntityManager em) {
this.em = em;
this.query = new JPAQueryFactory(em);
}QueryDSL
를 사용한 레포는 스프링 데이터 JPA를 안쓰고 직접 순서 jpa를 썼습니다. 스프링 데이터 JPA를 살리면서 QueryDSL도 사용해보겠습니다.
-> 그림
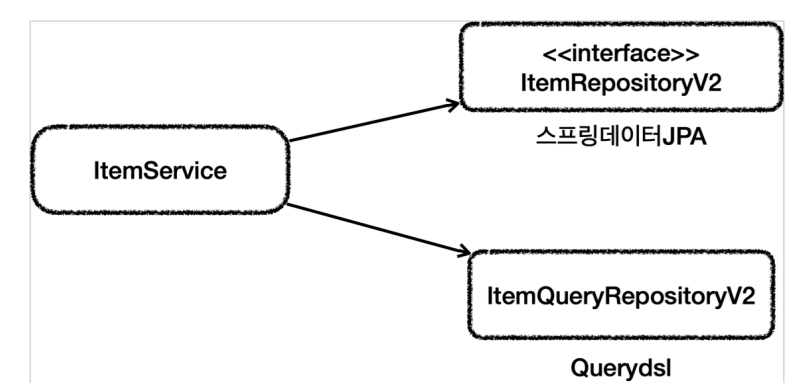
이전에는 서비스가 스프링 데이터 JPA를 주입받아서 사용하는 item 레포 구현체를 사용했는데 서비스가 스프링 데이터 JPA를 직접 쓰고 복잡한 쿼리는 쿼리레포를 만들어서 복잡한 동작 쿼리는 QueryDSL를 쓰게 하는 것입니다. 그러면 간단한 것은 스프링 데이터 JPA를 쓰고 복잡한 것은 QueryDSL를 쓰는 것으로 서비스에서 사용하는 레포를 2개로 나눠서 분리하는 것입니다.
> 이렇게 2개를 분리하면 기본 crud와 단순 조회는 스프링 데이터 JPA가 담당하고 복잡한 쿼리는 QueryDSL가 담당합니다. 이렇게 하기 위해서는 서비스의 코드를 바꿔야하긴 합니다. 구조를 실용적으로 바꾸는 것입니다.
- 구현
1) 스프링 데이터 JPA 인터페이스
public interface ItemRepositoryV2 extends JpaRepository<Item, Long> {
}item 레포 V2를 만드는데 얘가 스프링 데이터 JPA 인터가 되도록 jpa 레포를 상속받습니다. 이전에 만든 스프링 데이터 JPA를 사용하지 않고 새로운 스프링 데이터 JPA를 만든 후 이것을 서비스에서 바로 쓰는 것입니다. 지금 만드는 item 레포는 스프링 데이터 JPA이지 item 레포 인터를 구현하는 구현체가 아니고 item 레포 인터도 아닙니다.
> 그냥 상속만 받고 끝냅니다. 기본적인 crud와 스프링 데이터 JPA관련 특화 기능만 넣고 쿼리 메서드와 jpql 작성은 하지 않습니다. 나중에 필요하면 넣으면 됩니다. 지금 가장 실용적인 구조를 위해서 간단한 crud는 제공받는 거 쓰고 복잡한 것은 QueryDSL를 쓰기 위함입니다.
2) QueryDSL 구현 레포지토리
@Repository
public class ItemQueryRepositoryV2 {
private final JPQLQueryFactory query;
public ItemQueryRepositoryV2(EntityManager em) {
this.query = new JPAQueryFactory(em);
}여기는 findAll 동적 쿼리 메서드만 따로 작성합니다. 쿼리 팩토리를 생성하고 em을 config에서 직접 넣어주기 위해 em을 생성자에서 주입받아서 넣도록 작성합니다.
public List<Item> findAll(ItemSearchCond cond) {
Integer maxPrice = cond.getMaxPrice();
String itemName = cond.getItemName();
List<Item> result = query
.select(QItem.item)
.from(QItem.item)
.where(likeItemName(itemName), maxPrice(maxPrice))
.fetch();
return result;
}복잡한 코드는 이 부분만 유지보수합니다. 복잡한 동적 쿼리의 경우 실무에서 매우 복잡하기에 이런 방식을 사용할 수 있습니다. 원래 QueryDSL를 사용했던 item 레포는 item 레포 인터 구현체라서 4개의 메서드를 다 구현해야 했었는데 이제는 findAll만하고 implements를 붙이지 않습니다.
- 서비스 코드 수정
public interface ItemService {
Item save(Item item);
void update(Long itemId, ItemUpdateDto updateParam);
Optional<Item> findById(Long id);
List<Item> findItems(ItemSearchCond itemSearch);
}서비스 V2를 만듭니다. 얘는 서비스 인터를 구현하는 것은 그대로 입니다. 서비스 인터는 저장, 수정, id로 찾기, 여러개 찾기를 가지고 있었고 이제 이 구현체를 QueryDSL와 스프링 데이터 JPA를 나눠서 구분해서 사용하도록 할 것입니다.
@Configuration
@RequiredArgsConstructor
public class SpringDataJpaConfig {
private final SpringDataJpaItemRepository repository;
@Bean
public ItemService itemService() {
return new ItemServiceV1(itemRepository());
}
@Bean
public ItemRepository itemRepository() {
return new JpaRepositoryV2(repository);
}
}이전에는 서비스가 스프링 데이터 JPA를 사용하는 item 레포 인터 구현체를 주입받아서 사용했는데 이제 서비스가 직접 스프링 데이터 JPA를 사용하는 것입니다.
@Service
@Transactional
@RequiredArgsConstructor
public class ItemServiceV2 implements ItemService{
private final ItemQueryRepositoryV2 itemQueryRepositoryV2;
private final ItemRepositoryV2 itemRepositoryV2;
@Override
public Item save(Item item) {
return itemRepositoryV2.save(item);
}
@Override
public void update(Long itemId, ItemUpdateDto updateParam) {
Item findItem = itemRepositoryV2.findById(itemId).orElseThrow();
findItem.setItemName(updateParam.getItemName());
findItem.setPrice(updateParam.getPrice());
findItem.setQuantity(updateParam.getQuantity());
}
@Override
public Optional<Item> findById(Long id) {
return itemRepositoryV2.findById(id);
}스프링 데이터 JPA 와 QueryDSL를 주입받습니다. 이러면 스프링 데이터 JPA이니 그냥 단순한 것들은 바로 사용하면됩니다. update가 스프링 데이터 JPA를 사용하기에 @Transactional을 붙입니다.
@Override
public List<Item> findItems(ItemSearchCond itemSearch) {
return itemQueryRepositoryV2.findAll(itemSearch);
}복잡한 findItems는 QueryDSL에 작성한 findAll을 가져와서 사용합니다. 굉장히 서비스를 빨리 만들었습니다.
-> 설정
@Configuration
@RequiredArgsConstructor
public class V2Config {
private final EntityManager entityManager;
private final ItemRepositoryV2 itemRepositoryV2; // springData JPA
@Bean
public ItemService itemService() {
return new ItemServiceV2(itemQueryRepositoryV2(), itemRepositoryV2);
}
@Bean
public ItemQueryRepositoryV2 itemQueryRepositoryV2() { // 쿼리 dsl
return new ItemQueryRepositoryV2(entityManager);
}
@Bean
public ItemRepository itemRepository() {
return new JpaRepositoryV3(entityManager);
}
}config 설정을 만듭니다. 서비스를 v2로 바꾸고 스프링 데이터 JPA는 구현체가 자동으로 스프링이 등록해주니 주입을 받고 직접만든 QueryDSL 레포만 등록합니다. QueryDSL가 findAll만 있지만 QueryDSL를 사용하는 레포는 직접 등록해줘야 했습니다.
그리고 서비스의 인자로 스프링 데이터 JPA와 QueryDSL 두개를 넣어줍니다. 스프링 데이터 JPA는 그냥 직접 등록말고 스프링이 자동 등록하고 주입받아서 쓰는 것이 가능합니다. 스프링 데이터 JPA는 스프링이 자동으로 등록해주니깐 가져다 쓰고 퀴리 dsl은 findAll만 따로 만들어서 빈 등록하는 것입니다. 원래 항상 item 레포 인터를 구현해서 4개의 메서드를 다 가지고 있었는데 분리해서 item 레포 구현체처럼 쓸 것은스프링 데이터 JPA로 하는데 스프링 데이터 JPA는 인터만 만들면 되니 인터만 만든 것이고 item 레포 구현체처럼 쓸 게 아닌 findAll만 둘 것은 QueryDSL로 만들어서 넣은 것입니다.
@Slf4j
@RequiredArgsConstructor
public class TestDataInit {
// private final ItemRepositoryV2 itemRepository;
private final ItemRepository itemRepository;
/**
* 확인용 초기 데이터 추가
*/
@EventListener(ApplicationReadyEvent.class)
public void initData() {
log.info("test data init");
itemRepository.save(new Item("itemA", 10000, 10));
itemRepository.save(new Item("itemB", 20000, 20));
}
}이렇게 이 2개만 있으면 됩니다. 하지만 Testdatainit에서 분리하기 전 레포를 사용해서 기존 것도 필요합니다. private final을 바꾸면 되긴 합니다. app에 import 바꾸고 어플을 돌리면 성공합니다.
- 정리
이 구조는 간단하고 빠른 구조입니다. 작고 변경할 일이 없는 경우 이렇게 설계할 수 있습니다. 구조적인 유연성은 DI를 못해서 떨어지지만 실용적으로 빠르게 개발할 수 있습니다. 처음에는 단순하게 이렇게 접근하고 추후에 프로젝트가 커지면 추상화를 리팩토링하는 것이 좋다고 생각합니다. 처음부터 프로젝트 규모가 크다면 처음부터 역할과 구현을 나누는게 필요합니다. 사실 이러한 것은 직접 고민해봐야 알 수 있고 고민의 시간이 쌓여서 좋은 개발자가 되는 것입니다.
- 다양항 데이터 접근 기술 조합
어떤 데이터 접근 기술을 사용하는 것이 좋을까요? 이건 정답이 있다기보단 비즈니스 상황과 현재 프로젝트 구성원의 역량을 보고 결정하는 것이 좋습니다. 탬플릿을 쓰면 sql을 직접 써야하지만 기술이 간단하여 sql에 익숙한 개발자라면 금방 적응할 수 있습니다.
> jpa는 개발 생산성에 혁신적일 수 있지만 학습량이 많습니다. 또한 매우 복잡한 통계 쿼리를 주로 사용하는 경우 맞지 않습니다.
-> 비즈니스 상황
해결해야하는 비즈니스 상황의 70 80%이 통계 쿼리를 작성해야하면 Mybatis를 사용하는 것이 좋습니다.
대부분 일반적인 로직이 있고 일부분 통계로직이라면 강사님의 추천방향은 스프링 데이터 JPA와 QueryDSL를 기본으로 사용하고 복잡한 쿼리를 써야하는 경우 sql 맵퍼를 함께 사용하는 것입니다. 영한님은 실무에서 95% 정도는 스프링 데이터 JPA와 QueryDSL 조합으로 해결하고 나머지 5%는 맵퍼를 함께 사용한다고 합니다.
- 트랜잭션 매니저 선택
jpa를 기본으로 쓰고 맵퍼(jdbc)를 상황에 따라 쓰는 것을 가정했을 때 트랜잭션 매니저를 고민해야합니다. jpa트랜잭션 매니저와 jdbc 데이터소스 트랜잭션 매니저가 다르기 때문입니다. 함께 사용하면 트랜잭션 매니저가 달라서 트랜잭션을 하나로 묶을 수 없는 문제가 발생할 수 있습니다.
하지만 jpa 트랜잭션 매니저가 jdbc 트랜잭션 매니저의 기능을 다 제공합니다. jpa도 내부에서 다 데이터 소스와 jdbc를 사용하기 때문이고 다 추상화해서 사용하는 것이기 대문에 jpa 트랜잭션 하나만 등록하면 jpa와 맵퍼 모두를 하나의 트랜잭션으로 묶어서 사용할 수 있습니다. 걱정하지 않고 그냥 사용하면 됩니다.
-> 주의점
jpa는 트랜잭션 커밋 시점에 db에 변경사항이 적용되는 것을 인지해야 합니다. save와 update 둘 다 커밋 시점에 db에 반영이 되고 select만 반영이 필요없으니 신경쓰지 않아도 되는 것입니다.
'[백엔드] > [spring | 학습기록]' 카테고리의 다른 글
| spring PART.트랜잭션 전파 기본 (0) | 2023.05.22 |
|---|---|
| spring PART.스프링 트랜잭션 이해 (0) | 2023.05.20 |
| spring PART.Querydsl (0) | 2023.05.18 |
| spring PART.중간점검 4 (0) | 2023.05.17 |
| spring PART.스프링 데이터 JPA (0) | 2023.05.17 |



