
개발자로 후회없는 삶 살기
[문법] 스프링 데이터 JPA 기능 본문
서론
※ 과거에 기록한 내용에서 중요한 부분만 발췌하여 모두가 이해하기 쉽게 다시 서술한다.
본론
- 스프링 데이터 JPA 적용
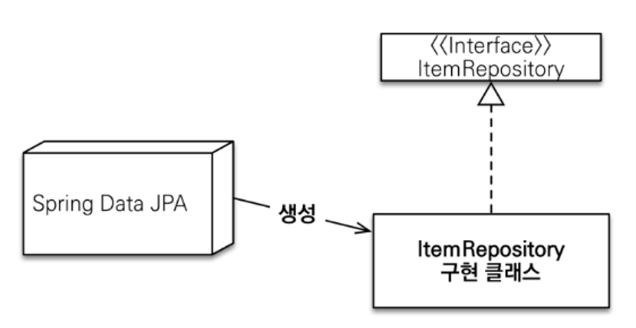
스프링은 Repositoy를 인터페이스로 구현체를 CGLIB으로 등록해서 편리한 기능을 제공한다.
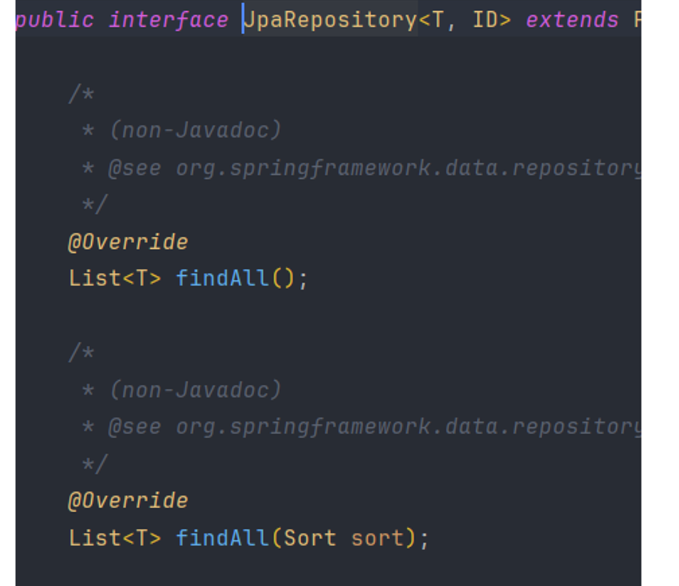
Jpa 레포지토리에는 find 관련 메서드들이 이미 구현되어 있어서, 가져다 사용하면 된다.
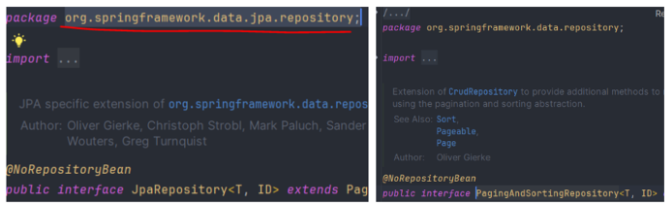
jpa 레포지토리는 RDB 관련 메서드만 제공한다. Page Sort는 data 하위 인터페이스로 레디스 몽고를 다 지원한다. 몽고와 레디스도 페이지와 정렬을 지원하므로 추상화한 것이다.
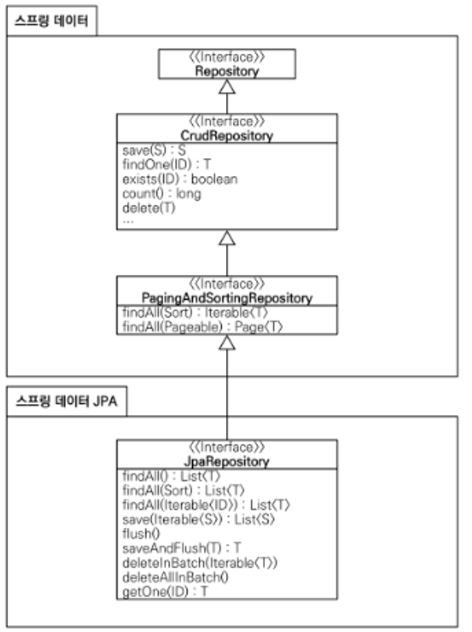
스프링 데이터는 데이터 공통 기술이고 스프링 데이터 JPA는 RDB 기술이다. 몽고, 레디스를 쓰면 스프링 데이터를 다 사용할 수 있다.
- 쿼리 메서드 기능
이처럼 findAll 같은 공통 기능을 제공하는데, 다른 기능이 더 필요하면 어떻게 할까? 순수 JPA에서는 find, persist 외에 다른 기능은 jpql로 직접 작성해야 했다.

where 문에 name을 검색하고 싶다.
find와 같은 공통 기능은 모든 도메인에 적용 가능한데 name은 개발자마다 개발하는 게 달라서 모든 도메인에 적용할 수 있는 것이 아니고, 이를 메서드 이름으로 할 수 있다.
⇒ 메서드 이름으로 쿼리 생성 기능

순수 jpa로 나이와 이름을 기준으로 where를 하려면 jpql로 짜야한다. 그래서 이것을 스프링에서 메서드 이름으로 jpql을 짜서 구현체에 넣어준다.

이렇게 작성하면 위 jpql이 동작한다.
→ 쿼리 조건
1. 조회
findxxxBy : 전체 조회
findxxxByxxx : 특정 필드를 조건으로 조회 (ex : findById)
xxx에는 아무거나 들어가도 된다. findAllBy에서 All은 임의로 넣은 것이다. findAllBy는 뒤에 필드가 없으면 전체 조회를 의미하고 findxxxBy가 전체 조회라서 그렇다.
2. count
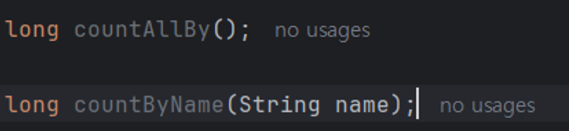
모든 행 조회와, 특정 검색 조건을 넣을 수 있고 long 타입으로 개수를 반환한다.
3. 기타
existsxxxBy : bool 반환
deletexxxBy : 삭제 쿼리 후 int 반환
findxxx의 xxx에 distinct를 붙이면 select 절에 distinct가 붙는다.
limit : findFirst3 : 위에서 3개 조회
짤막한 쿼리를 짜는 경우 메서드 이름이 좋다.
- @Query
복잡한 코드는 쿼리 메서드로 하면 메서드 명이 너무 길어진다. 레포지토리에 복잡한 쿼리를 바로 칠 수 있다. 네임드 쿼리의 모든 장점(컴파일 오류, 파싱, 메모리 캐싱)을 가지고 있다.

파라미터는 이름 방식으로 한다.
→ 장점
1) 메서드 길이가 길어지는 문제 해결
2) 문자인데 컴파일 오류 제공
3) 복잡한 jpql을 바로 사용 가능
간단할 때 : 메서드 이름
복잡한 정적 쿼리 : @Query
복잡한 동적 쿼리 : Dsl
→ 값 가져오기

엔터티 말고 값을 가져오려면, 객체 그래프를 사용한다.

dto로 할 수 있고 패키지 경로를 전부 요구한다.

in 절에 여러개 조건을 넣으려면 컬랙션을 사용하면 된다.
- 반환 타입
스프링은 단건, 컬랙션, 옵셔널 등 다양한 반환 타입을 가져간다.

스프링은 다양한 반환 조건을 제공한다. jpql에서는 singleList는 1개, 0개 혹은 2개 이상이면 예외 발생, ResultList는 0개면 빈 List, 1개 이상을 제공했는데, 스프링에서는 단건 조회를 Opt를 제공한다.

단건 조회에서 여러개를 찾으면 jpa 예외가 발생하고,

스프링 예외로 변환되어 날라온다.
- 페이징

jpa에서도 페이징을 추상화해서 제공한다.

이 인터페이스는 jpa가 data.으로 rdb가 아니고 전체 데이터에서 가능하게 인터페이스했다. 어떤 데이터베이스든 페이징과 정렬을 사용할 수 있다.
page : 페이징, cnt 쿼리
slice : limit + 1
List : 페이징 쿼리만 나감
특별한 반환 타입을 적용할 수 있다.

이것들을 사용해보자
1) Page

조회할 때 검색을 사용하고, 정렬을 하고 페이징을 0번 페이지, 3개의 데이터를 가져와보자

특정 나이 조건을 넣고 두번째 인자로 페이져블로 페이지 정보를 넣는다. 검색은 검색 조건으로 넣고 정렬, 페이지 정보는 Pageable로 넣는다.
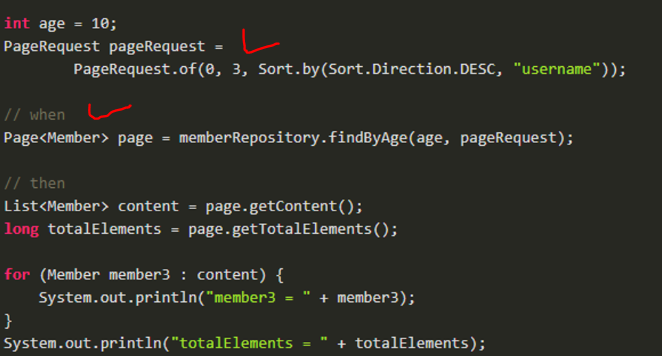
스프링은 페이지 시작이 0번으로 3개의 데이터를 가져온다. req의 부모가 Pageable이라서 그대로 넣으면 된다. Content는 페이지 결과 내용물, totalCnt를 가져온다.

Page 반환 타입은 totalCnt 쿼리도 같이 날려준다. 그러면 나이가 10살인 Member를 찾고 0 페이지에서 3개를 가져온다.
getNumber : 현재 페이지 번호
getTotalPages : 전체 페이지 개수
isFirst : 첫 번째 페이지인지
hasNext : 다음 페이지가 있는지
Page 반환 타입은 Page와 cnt 쿼리가 가능하다. 현재 페이지 번호로는 게시판에서 현재 페이지 번호를 알 수 있다. 전체 페이지 개수도 알 수 있도 다음 페이지를 알면 게시판 밑에 다음 페이지 있어요, 이전 페이지 있어요를 다 할 수 있다.
2. Slice
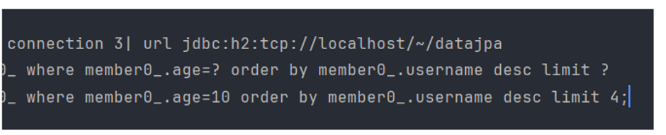
지금 3개 가져오라고 했는데 limit + 1로 해서 4개를 요청한다. 이걸로 다음 페이지가 있다면? 있다고 표시하고 미리 로딩해 놓거나, 기획에 따라서 Page를 Slice로 바꿨을 때 성능 개선이 엄청나질 수 있다.
3. List

Page를 하는데 total이 필요 없으면 List를 한다.
→ 카운트 쿼리 분리
페이징은 다 좋은데 total 쿼리가 데이터를 다 훑어야 해서 쿼리가 오래걸릴 수도 있다. 특히 조인을 했을 때 조인 결과의 카운터 쿼리나 원 테이블 쿼리 결과가 같아서 사실 조인을 할 필요가 없다. 그래서 조인이 되어있으면 조인을 하고 카운트 하는 성능 문제가 발생할 수 있고 카운트 쿼리를 조인에서 분리할 수 있다.

그냥 이렇게 조인한 테이블에서 페이지를 날리면 페이지를 할 때 조인을 한다.
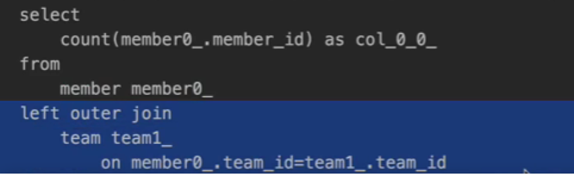
카운트를 할 때는 조인이 필요없는데 조인을 한다.

분리하면 페이징은 원하는대로 조인하는데

카운트 쿼리는 조인을 안 한다. 실무에서 쿼리가 단순할 때는 일반 Page를 쓰는데 조인을 하면 Page에서 count를 분리해야 한다.
→ API로 반환
Page 결과를 바로 API로 반환하면 도메인을 외부에 노출하는 거다. 그래서 dto로 바꿔야 한다.

page에서 map 메서드를 제공해서 바로 dto로 바꿀 수 있다. PageInfo가 dto다.
- EntityGraph
페치 조인을 jpa에선 jpql에 작성했는데, 스프링은 jpql을 안 쓰니 graph를 제공한다. @EntityGraph 어노테이션에 Paths를 같이 가져올 엔터리를 적어주면 된다.
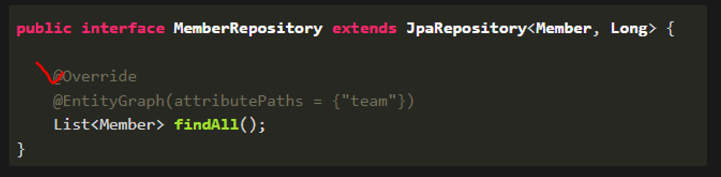
JPA에서 제공하는 메서드인 findAll 경우 오버라이드 해야한다.

jpql에 join fetch 없이 엔터티 그래프를 붙이면 페치 조인과 동일하게 동작하고,

메서드명으로 만들어도 엔터티 그래프로 jpql이 내부 동작할 때 페치 조인이 동작한다. 페이징 할 때, 다대1은 EntityGraph를 쓰고, 1대다는 배치 옵션 주면 될 것이다.
'[백엔드] > [JPA | 학습기록]' 카테고리의 다른 글
| [문법] JPQL과 페치 조인 성능 최적화 (0) | 2024.08.11 |
|---|---|
| [문법] 프록시 메커니즘과 부모 자식 life cycle (0) | 2024.08.11 |
| [문법] 연관관계 매핑 시 고려사항 (0) | 2024.08.11 |
| [문법] 다양한 연관관계 매핑 (3) | 2024.08.10 |
| [문법] JPA 동작 원리 (0) | 2024.08.09 |



