
개발자로 후회없는 삶 살기
[문법] 다양한 연관관계 매핑 본문
서론
※ 과거에 기록한 내용에서 중요한 부분만 발췌하여 모두가 이해하기 쉽게 다시 서술한다.
본론
- 엔터티 매핑 소개

객체와 테이블을 매핑하고 필드와 컬럼, 기본키, 연관관계를 매핑한다.
- 객체와 테이블 매핑 @Entity
Entity가 붙은 클래스는 JPA가 관리하는 엔터티로, 붙지 않으면 jpa와 전혀 관계 없는 클래스이다.
→ 주의점
1) 기본 생성자
2) final, enum, 인터페이스, 이너 클래스 불가
3) 필드에 final 불가
jpa는 리플랙션을 하기 때문에, 기본 생성자가 필수이다.

name은 실제 테이블에서 매칭되는 테이블을 골라서 매핑할 수 있다.
- 스키마 자동 생성
jpa는 엔터티 분석 기능으로 어플 로딩 시점에 테이블 자동 생성 기능을 제공한다.
장점 ✅
보통 개발을 할 때 설계를 다 마치고 구현을 하는데, 전부 다 create 쿼리를 사용해서 테이블을 다 만들어야 하는데 JPA는 알아서 만들어준다. 이렇게 생성된 DDL을 직접 사용하면 안되고, 적절히 다듬어서 사용하면 된다.
→ 속성 종류
create : 기존 테이블 삭제 후 생성
create-drop : create와 동일한데, 어플을 끄면 테이블을 삭제함
update : 변경분만 반영
valid : 엔터티와 테이블의 정상 매핑됐는지만 확인
none : 자동 생성을 하지 않음

update를 하면 필드가 변경되었을 때 alter 쿼리가 나온다.
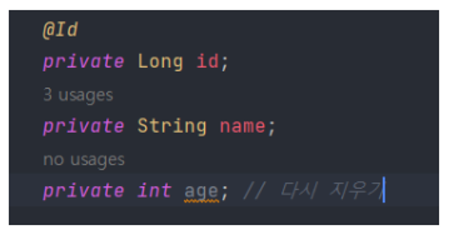
age 필드를 테이블에 추가하고 싶은데 drop은 하기 싫을 때 alter을 하고 싶다면 update를 사용한다.

validate는 차이점 감지만 한다. aaa 필드가 member 테이블에 없으니 에러가 발생한다.
→ 자동 생성 주의점
create, update, create-drop은 운영 단계에서 사용하면 안된다.

개발 초기 단계에는 create나 update를 사용하고 테섭이나, 운영 섭에서 create를 절대로 사용하면 안된다. create는 이미 있는 테이블을 제거하기 떄문에 데이터가 다 날라간다. 자동 생성은 로컬에서만 하고 여러명이 함께 쓰는 서버는 사용하지 않는다. 또한, 운영 서버에 반영할 때는 auto가 만들어준 sql을 그대로 사용하지 않고 잘 따져셔 새로 만들어야 한다.
- 필드와 컬럼 매핑

새로운 요구 사항에 대해, 컬럼 매핑을 해보자.

varchar보다 큰 용량의 데이터를 넣을 때 lob을 사용할 수 있다.

생성된 것을 보면 age는 integer로 됐는데, JPA가 dialect에 맞게 최적의 타입으로 쿼리를 날려준다. Lob은 테이블에 clob으로 들어가고, enum은 varchar로 들어간다.
→ 매핑 어노테이션 정리

1. Transient

필드에는 있는데, 실제 DB에는 매핑되지 않고 메모리에서만 사용하고 싶은 경우 transient를 사용한다.

실행해보면 temp가 db에 생성되지 않았다.
2. column 매핑의 insertable

쿼리를 실행할 여부를 지정할 수 있다. name의 insertable을 false로 하면 실행을 안 하겠다는 의미로

name에 a를 넣고 저장해봐도
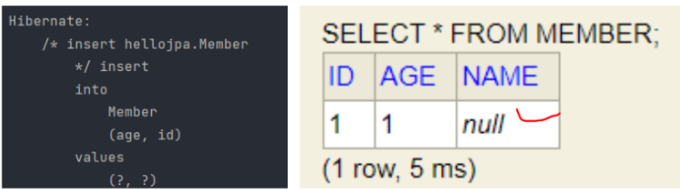
null이 들어간다. DB에 내용이 반영되지 않는다.
3. @ID
→ IDENTITY 전략 특징
identity는 애매한 부분이 있다. jpa는 커밋 시점에 쿼리를 날려야 pk를 알 수 있어서 identity는 pk를 모르는 상태로 컨텍스트에 저장된다. 근데 컨텍스트가 pk가 키라서 pk를 반드시 알아야한다. 따라서 identity 전략만 persist 시 바로 sql 쿼리가 날라간다.(원래 persist는 커밋 시점에 insert 쿼리가 날라간다.) 따라서,이러면 버퍼 라이팅이 불가능하다. 하지만, 버퍼 라이팅도 트랜잭션 단위로 동작하여 성능상 큰 효과는 없다.
- 연관관계 매핑
객체는 레퍼런스를 사용하는데 테이블은 외래키를 쓴다. 참조와 외래키를 매핑하는 법을 배운다.
→ 예제 시나리오

회원이 N, 팀이 1인 상황이다.
→ 테이블에 맞춘 설계

회원이 N측이라서 1측의 fk를 가져야 하는데 참조가 아닌 id를 외래키로 가진다.
1. 저장시 문제

fk를 지정하려면 먼저 팀을 영속화하고, 팀의 id를 가져와서 멤버에 저장한다.

setTeam을 해야할 것 같은데 연관 관계 매핑을 안해서 ID를 그대로 받는다.
2. 조회시 문제

팀을 조회하려면 멤버에서 팀의 id를 가져와서 다시 em.find를 해야한다.

객체는 참조를 해서 연관된 객체를 찾는데, 테이블은 외래키로 조인을 해서 이러한 패러다임의 차이가 있다.
- 단방향 연관관계
→ 객체 지향 모델링
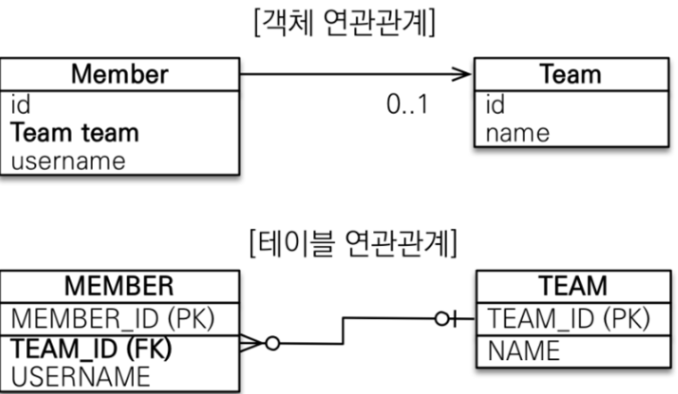
다측에 1측의 참조를 둔다.
→ 해결
1. 저장

이때도 팀을 영속화 해야하는데, jpa는 insert 할 때 pk를 가져오는데 지금 팀의 pk를 회원의 fk로 쓰기 때문에 반드시 팀의 pk가 필요하다. (참조가 fk로 변해서 db에 자동으로 저장된다고 생각하면 된다. 참조가 fk다.)
2. 조회

조회도 그냥 get하면 나온다.

jpa가 회원과 팀을 조인해서 한 번에 가져온다. 여기서 핵심은 jpa를 활용하면 객체의 참조와 db의 외래키를 매핑할 수 있다는 것이다.(매핑 = 참조와 fk 자동 변환)
3. 수정
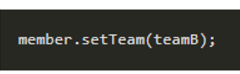
수정 시 다측에 참조를 바꿔주기만 하면 된다.
- 양방향 연관관계와 연관관계의 주인
지금까지 단방향을 봤고, member가 팀을 가지고 있어서 멤버에서 getTeam으로 팀으로 갈 수 있는데 팀에서는 멤버를 참조하지 않아서 멤버로 못 간다.

따라서 1측도 List로 참조를 만들어주면 양방향 연관관계가 된다.
→ 테이블

테이블 모양은 똑같다. 왜냐하면 테이블은 외래키로 조인하면 팀에서 회원으로 갈 수 있고 회원도 팀을 갈 수 있다. 테이블은 외래키 하나로 원래 양방향이 된다.

하지만, 문제는 객체로 팀은 회원을 가지지 않아서 회원으로 못 간다. 따라서 List로 둘 다 셋팅 해야하는 것이 객체와 테이블의 가장 큰 패러다임 차이이다.
→ 팀 엔터티

이제는 반대 방향으로도 객체 그래프 탐색이 가능하다.
→ 차이
1. 객체

객체는 단뱡향 관계 2개로 양방향을 만들 수 있다.
2. 테이블
테이블은 다측에 fk를 하나 두는 것으로, 끝난다. 테이블은 사실 방향이 없는 것으로 이 두 차이가 시작이다.
- 딜레마

다측의 fk를 변경해야 fk가 db에 반영될까?
1측의 List를 변경해야 fk가 db에 반영될까?
여기서 객체는 2개를 만들었는데 1측의 참조를 바꿨을 때 외래키가 업데이트 되어야 할까? 다측을 업뎃했을 때 외래키를 바꿔야 할까, 딜레마가 온다.
- 연관관계의 주인
그래서 둘 중 하나를 주인으로 잡고 주인만이 외래키를 변경할 수 있고 주인이 아니면 읽기만 가능하다.

주인 : 수정, 등록, 삭제, 조회
1측 : 조회만
다측이 주인이어야 한다. 회원은 외래키를 수정, 삭제할 수 있고, team의 members는 조회만 할 수 있다. JoinColumn이 있는 곳이 주인이다.
- 주의할 점
→ 주인에 안 넣고 1측에만 넣은 경우

진짜 주인에는 외래키를 넣지 않고 이름만 셋팅하고 1측에서 member를 넣는다.

실행해보면, team_id가 null이다. 주인에서 안 넣더라도, 1측에서 넣었는데 1측은 조회만 가능해서 적용이 안 된다.

주인에 1측을 set 해야만 db에 반영되기 때문이다.
✅ 주의사항
주인만이 fk에 수정 등의 반영이 가능하다. 따라서, 1측만 사용하더라도, 반드시 다측을 사용해서 fk 수정을 해야한다. 진짜 수정은 다측에서만 일어나지만 항상 순수 객체 상태를 고려하여 양쪽에 다 값을 셋팅하는게 맞다.
✅ 추천하는 방식
두 곳에 다 값을 넣기 위해서 연관관계 편의 메서드를 생성하라

멤버에 팀을 셋탕하는 시점에 팀에도 값이 들어가서 실수할 일이 없다.
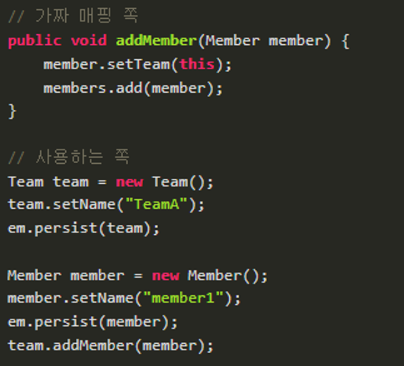
1측에서는 add 메서드를 사용해야 한다.
'[백엔드] > [JPA | 학습기록]' 카테고리의 다른 글
| [문법] 프록시 메커니즘과 부모 자식 life cycle (0) | 2024.08.11 |
|---|---|
| [문법] 연관관계 매핑 시 고려사항 (0) | 2024.08.11 |
| [문법] JPA 동작 원리 (0) | 2024.08.09 |
| JPA PART.프록시와 연관관계 관리 (0) | 2023.08.22 |
| JPA PART.고급 매핑 (0) | 2023.08.20 |



