
개발자로 후회없는 삶 살기
spring PART.스프링 트랜잭션 적용 본문
서론
※ 이 포스트는 다음 강의의 학습이 목표임을 밝힙니다.
https://www.inflearn.com/roadmaps/373
우아한형제들 최연소 기술이사 김영한의 스프링 완전 정복 - 인프런 | 로드맵
Spring, MVC 스킬을 학습할 수 있는 개발 · 프로그래밍 로드맵을 인프런에서 만나보세요.
www.inflearn.com:443
본론
- 문제점들
이제 발생한 문제들을 스프링으로 해결해보겠습니다.
1. 어플리 케이션 구조

어플은 3가지 계층으로 컨트롤러(= 웹 요청과 응답), 서비스(=비즈니스 로직), 레포(=db 접근 처리)입니다.
-> 순수한 서비스 계층
이 3개중 가장 중요한 것은 비즈니스 로직이 있는 서비스입니다. 시간이 흘러서 UI가 바뀌고 db 기술이 바뀐다고 해도 비즈니스 로직은 그대로 유지되어야합니다. 이렇게 하려면 서비스 계층을 특정 기술에 종속적이지 않게 개발해야합니다. 그래서 순수한 자바 코드로만 작성합니다. 컨트롤러, 레포를 두는 이유도 서비스를 유지하기 위해서입니다.
-> 지금 작성한 코드의 문제점
public void accountTransfer(String fromMemberId, String toMemberId, int money) throws SQLException {
// 시작
Member findMember = memberRepositoryV1.findById(fromMemberId);
Member toMember = memberRepositoryV1.findById(toMemberId);
memberRepositoryV1.update(fromMemberId, findMember.getMoney() - money);
validation(toMember);
memberRepositoryV1.update(toMemberId, findMember.getMoney() + money);
// 커밋, 롤백
}서비스를 순수하게 유지하는 것이 좋다고 했는데 서비스 V1을 보면 특정 기술에 종속적이지 않고 순수한 자바 코드로만 되어있습니다.
con.setAutoCommit(false);
// 시작
bizLogic(con, toMemberId, money, fromMemberId);
con.commit();근데 트랜잭션을 적용한 V2는 트랜잭션을 시작하는 것, 커낵션을 가져오는 것 같은 JDBC 기술이 트랜잭션은 비즈니스 로직이 있는 서비스 계층에서 시작하는 것이 좋다고 해서 서비스에 작성되어있습니다. 결과적으로 jdbc 기술에 의존하여 비즈니스 로직보다 jdbc를 사용해서 트랜잭션을 처리하는 코드가 더 많고 jpa로 바꾸면 서비스 코드를 모두 바꿔야합니다. 서비스가 하나면 다행인데 비즈니스가 여러개라서 수십개면 수십개의 서비스 클래스를 다 바꿔야합니다.
2. 문제점 정리

1) 트랜잭션 문제
con.setAutoCommit(false);
// 시작
bizLogic(con, toMemberId, money, fromMemberId);
con.commit();jdbc 기술이 서비스 계층에 누수되는 문제가 있습니다. 서비스 계층은 기술에 종속하지 않고 순수 자바로 짜고 로직만 있어야했는데 트랜잭션을 시작한다고 했으니 현재는 con.setAutoCommit(false);, con.commit(); 등이 있으나 어쩔 수 없었습니다.
> 또한 커낵션을 파라미터로 계속 넣어 유지해야하고 try catch 문도 너무 많아서 복잡한데 서비스가 100개면 100개에 다 이코드를 넣어야합니다.
2) 예외 누수
public Member findById(String memberId) throws SQLException레포에서 jdbc 구현 기술을 throw로 다 날려서 예외가 서비스 계층으로 전파됩니다. SQL 예외가 레포에서 다 던져서 서비스로 올라와서 서비스에서 처리하던가 또 던져야합니다. 근데 이게 jdbc 전용 기술이라서 jpa로 바꿔면 나중에 jpa 예외로 바꿔야합니다. 근데 잡아서 처리하면 다 try로 처리해야해서 더 골치아픕니다.
3) jdbc 반복 문제
레포에 작성한 코드가 다 순수 jdbc를 사용해서 유사 코드 반복이 많습니다.
-> 스프링과 문제 해결
이 많은 문제를 스프링이 다 해결해줍니다. 서비스를 순수하게 유지하며 다 해결해줍니다.
- 트랜잭션 추상화
현재 서비스는 트랜잭션을 위해 jdbc 기술에 의존하고 있습니다. jpa로 바뀌면 다 바꿔야하기에 이를 추상화해야합니다.
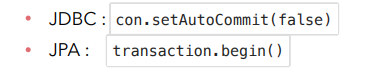
jdbc의 경우 수동 커밋이 set인데 jpa는 begin입니다. 이 두개가 완전히 달라서 트랜잭션을 사용하는 코드가 다르니 서비스 계층을 다 바꿔야합니다. jdbc를 사용하다가 jpa로 변경하면 서비스 계층 코드도 함께 수정해야합니다.
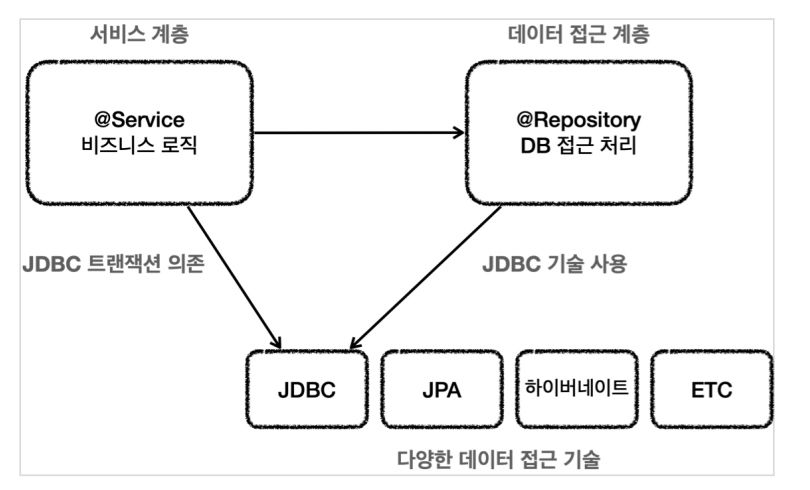
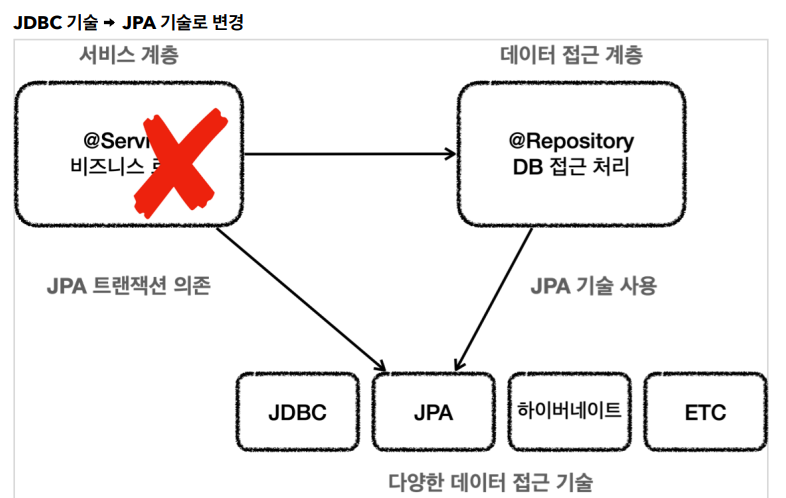
이것이 단일 책임 원칙을 안 따르는 것으로 jpa로 바꾸면 데이터 계층인 레포만 바꿔야하는데 서비스도 바꿔야하는 다연발로 다 바꿔야하는 것입니다.
-> 트랜잭션 추상화
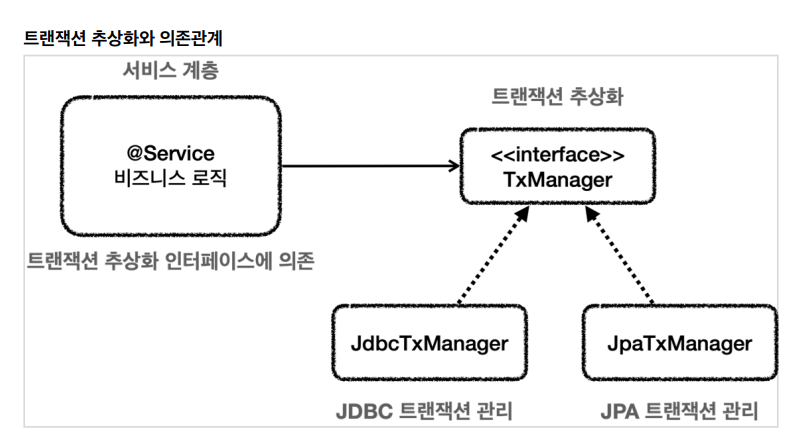
단순하게 생각하면 인터를 만들어서 추상화하면 됩니다. 인터를 만들고 구현체를 DI로 갈아끼우면 되는 것입니다. Txmanager라고 만들고 트랜잭션 시작하는거 커밋하는거 롤백하는거로 트랜잭션은 사실 트랜잭션 시작하고 로직 끝나면 커밋하거나 롤백하는 것만 있으면 됩니다. 매우 단순합니다.
> 그리고 이 인터를 기반으로 jdbc, jpa 구현체를 구현하고 DI로 갈아끼우면 됩니다. jdbc 구현체는 시작을 set으로 재정의하고 jpa 구현체는 시작을 transacion.begin으로 하면 되는 것입니다. 트랜잭션 시작을 con.set이 아니라 매니저.으로 하여 서비스 코드는 매니저에만 의존하게 짜면 실제로 동작하는 것은 DI로 넣은 구현된 역할이 수행될 것이라는 것입니다.
그러면 서비스는 특정 기술에 의존하는 것이 아니라 txmanager라는 추상화된 인터에만 의존하고 이제 원하는 구현체를 주입하기만 하면 되는 것입니다. 스프링이 이래서 OCP와 DIP를 만족하도록 기능을 제공하는 것입니다.
- 스프링 트랜잭션 추상화

스프링이 이미 다 구현해 뒀습니다. 우리는 스프링이 제공하는 트랜잭션 추상화 기술을 가져다 사용하면 되고 데이터 접근 기술에 따른 구현체도 다 구현해 뒀습니다. 플랫폼 트랜잭션 매니저라는 인터가 있고 여기에 시작, 커밋, 롤백이 있고 서비스는 이 인터에만 의존하여 코드를 짭니다.

구현체를 보면 get, commit, rollback이 시작, 커밋, 롤백이고 이것을 다 구현해 뒀습니다. 결론은 지금 jdbc 기술에 의존하여 서비스에 트랜잭션 코드를 짜놨는데 기술이 바뀌면 다 바꿔야하니 인터에 의존하게 코드를 짜야하고 그것을 스프링 것을 가져다 쓰면 되는 것입니다. 앞으로는 스프링이 제공하는 트랜잭션 인터인 트랜잭션 매니저를 쓰는 법을 알아보겠습니다.
- 트랜잭션 동기화
트랜잭션 매니저는 2가지 일을 하는데 추상화와 리소스 동기화를 합니다. 리소스 동기화는 트랜잭션을 유지하기 위해 트랜잭션의 시작부터 끝까지 같은 커낵션을 유지하는 것입니다. 이전에는 파리미터로 넘겨서 작성했는데 이러면 코드가 지저분해지고 메서드 오버로딩해야하는 문제가 있습니다.
-> 트랜재션 매니저 동기화
스프링은 동기화 매니저를 제공하는데 쓰레드 로컬을 사용해서 커낵션을 동기화해주는데 트랜잭션 매니저는 내부에서 이 트랜잭션 동기화 매니저를 사용합니다. 쓰레드 로컬은 커낵션을 안전하게 보관해주는 것입니다.
> 동기화 매니저는 쓰레드 로컬을 사용하기 때문에 멀티 쓰레드 상황에 안전하게 커낵션 동기화를 할 수 있고 따라서 커낵션이 필요하면 트랜잭션 동기화 매니저를 통해 커낵션을 획득하면 됩니다. 이전처럼 파라미터로 커낵션을 전달하지 않아도 됩니다.
-> 동작
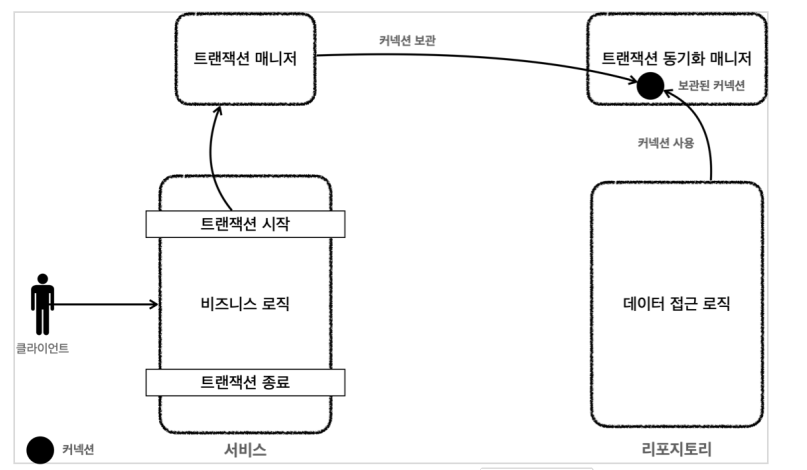
1. 트랜잭션을 시작하려면 커낵션이 필요한데 비지니스 로직이 트랜잭션 매니저에 "트랜잭션 시작하세요"라고 하는 것으로 그러면 매니저는 데이터 소스를 통해 커낵션을 만들고 그 안에서 만든 커낵션에 수동 커밋 이런 것을 다 하고 트랜잭션을 시작합니다.
2. 매니저는 시작된 커낵션을 동기화 매니저에 보관합니다. 이전에는 우리가 커낵션을 들고 파라미터로 넣었는데 이제는 보관을 합니다.
3. 레포에서 커낵션이 필요한데 보관된 커낵션을 꺼내서 사용합니다. 따라서 파라미터로 커낵션을 전달하지 않아도 됩니다.
4. 커밋이나 롤백하여 트랜잭션이 종료하면 매니저는 동기화 매니저에 보관된 커낵션 꺼내서 커밋과 롤백을 하고 커낵션을 제거합니다.

동기화 매니저는 TransactionSynchronizationManager 이것으로 쓰레드 로컬에 보관합니다. 참고로 스레드 로컬을 사용하면 스레드마다 별도의 저장소가 생겨서 A 스레드가 오면 A 스레드 전용 B면 B 전용으로 저장소가 부여되어서 해당 스레드만 데이터에 접근할 수 있어서 동시에 여러 스레드가 같은 커낵션을 사용하는 일은 발생하지 않습니다.
> 그냥 데이터를 안전하게 보관해줘서 멀티 스레드에서 안전하게 보관할 수 있다고 생각하면 됩니다. 이렇게 하여 커낵션을 파라미터로 넣을 필요 없고 트랜잭션 매니저가 커낵션을 만들고 동기화 매니저에 보관하고 레포가 예전처럼 파라미터가 아닌 동기화 매니저를 통해서 꺼내씁니다.
- 트랜잭션 매니저 코드 적용
레포지토리를 바꿀 것입니다. DataSourceUtils.getConnection(), DataSourceUtils.relaeseConnection()을 쓸 것이고 이게 트랜잭션 동기화 매니저에 접근하여 커낵션 획득하고 닫고 하는 것입니다.
-> 커낵션 가져오기
public Connection getConnection() throws SQLException {
Connection con = DataSourceUtils.getConnection(dataSource);
log.info("get connection={}, class={}", con, con.getClass());
return con;
}아래 getConnection 메서드의 커낵션 가져오는 부분을 DataSourceUtils.getConnection(datasource)를 하여 가져옵니다. 트랜잭션 동기화 매니저를 사용하려면 DataSourceUtils를 사용해야합니다.

이 코드를 따라가보면 동기화 매니저에 보관된 커낵션을 가져옵니다.
-> 닫기
private static void release(Connection con) {
if (con != null) {
try {
con.setAutoCommit(true);
con.close();
} catch (Exception e) {
log.error("error", e);
}
}
}커낵션을 파라미터를 안 받을 때는 그냥 닫고 받을 때는 레포에서 안 닫고 서비스에서 자동 커밋으로 바꾸고 닫았는데
1) 닫을 때
// 이전
JdbcUtils.closeResultSet(rs);
JdbcUtils.closeStatement(stmt);
JdbcUtils.closeConnection(con);
// 이후
JdbcUtils.closeResultSet(rs);
JdbcUtils.closeStatement(stmt);
// JdbcUtils.closeConnection(con);
DataSourceUtils.releaseConnection(con, dataSource);닫을 때를 보면 이제 DataSourceUtils.relaeseConnection(con, datasource) 를 써서 트랜잭션 동기화를 써야하고 얻을 때 닫을 때 이렇게 써야합니다.
2) 안 닫을 때
예전에 파라미터로 받을 때 find와 update를 오버로딩으로 2개 만들고 안 닫고 커낵션 유지했었는데 이제 이것이 필요가 없습니다. 파라미터 메서드를 지웁니다.
-> 설명
1. DataSourceUtils.getConnection()
이거는 동기화 매니저가 보관하는 커낵션이 있으면 해당 커낵션을 반환합니다. 위에서 동기화 매니저에서 보관하는 것을 가져오는 코드를 봤으니 동기화 매니저를 사용해 가져옵니다. 이것이 개념에서 레포에서 동기화 매니저에 접근하여 보관된 커낵션을 가져온다고 했던 것입니다.
> 근데 이게 서비스에서 트랜잭션을 시작해서 동기화 매니저에 커낵션을 넣어놨으면 레포가 가져가서 쓰는게 말이 되는데 서비스에서 트랜잭션을 안 쓰면 레포에서 꺼낼 커낵션이 없습니다. > 그런 경우에 새로운 커낵션을 생성해서 반환합니다.
2. DataSourceUtils.relaeseConnection()
커낵션을 직접 con.close나 jdbcUtils.closeCon으로 닫아버리면 커낵션이 유지되지 않는 문제가 발생합니다. 우리는 트랜잭션 동안 커낵션이 살아있어야합니다. 이 메서드는 커낵션을 바로 닫는게 아니고 트랜잭션을 사용하기 위해 동기화된 커낵션인지 체크하여 동기화 매니저에서 가져온 동기화된 커낵션이면 유지하고 아니면 닫습니다.
레포에서 DataSourceUtils.relaeseConnection()를 했는데 "어? 지금 닫으려는 커낵션이 동기화 매니저의 커낵션이네?"하면 안 닫고 남겨두고 동기화 매니저가 관리하는 커낵션이 아니면 그냥 바로 닫습니다.
> 그냥 update하는 메서드는 자동 커밋으로 트랜잭션을 사용하지 않는 동기화 매니저가 관리하지 않는 커낵션이니 그냥 닫고 서비스의 accountTran에서 불린 update면 안 닫습니다.
- 서비스에 스프링 트랜잭션 적용
// 이전
private final MemberRepositoryV2 memberRepository;
private final DataSource dataSource;
public void accountTransfer(String fromMemberId, String toMemberId, int money) throws SQLException {
Connection con = dataSource.getConnection();
try {
con.setAutoCommit(false);
// 시작
bizLogic(con, toMemberId, money, fromMemberId);
con.commit();
// 커밋, 롤백
} catch (IllegalStateException e) {
con.rollback();
throw new IllegalStateException(e);
} finally {
release(con);
}
}
private void bizLogic(Connection con, String toMemberId, int money, String fromMemberId) throws SQLException {
Member findMember = memberRepository.findById(fromMemberId, con);
Member toMember = memberRepository.findById(toMemberId, con);
memberRepository.update(fromMemberId, findMember.getMoney() - money, con);
validation(toMember);
memberRepository.update(toMemberId, findMember.getMoney() + money, con);
}서비스에서 트랜잭션 기술 코드를 그대로 쓰는 것을 없애야합니다. 데이터 소스 주입을 하지 말고 플랫폼 트랜잭션 매니저를 주입받습니다. 매니저가 다 해줄 것이고 트랜잭션 시작, 커밋, 롤백을 매니저의 것으로 바꿔야합니다. 이렇게 해야 jdbc 같은 특정 기술이 아닌 트랜잭션을 추상화한 매니저에만 의존하게 됩니다.
-> 적용 후 변경 코드
// 이후
private final MemberRepositoryV3 memberRepository;
private final PlatformTransactionManager transactionManager;
public void accountTransfer(String fromMemberId, String toMemberId, int money) throws SQLException {
TransactionStatus status = transactionManager.getTransaction(new DefaultTransactionDefinition());
try {
// 시작
bizLogic(toMemberId, money, fromMemberId);
transactionManager.commit(status);
// 커밋, 롤백
} catch (IllegalStateException e) {
transactionManager.rollback(status);
throw new IllegalStateException(e);
}
}
private void bizLogic(String toMemberId, int money, String fromMemberId) throws SQLException {
Member findMember = memberRepository.findById(fromMemberId);
Member toMember = memberRepository.findById(toMemberId);
memberRepository.update(fromMemberId, findMember.getMoney() - money);
validation(toMember);
memberRepository.update(toMemberId, findMember.getMoney() + money);
}
1) 시작
getTranscation(new DefaultTransactionDefinition())하고 속성을 생성해서 넣어줍니다. 이 속성에 트랜잭션 타임아웃 등 설정할 수 있습니다. 반환을 받고 이것을 커밋에 넣을 것입니다.
public Connection getConnection() throws SQLException {
Connection con = DataSourceUtils.getConnection(dataSource);
log.info("get connection={}, class={}", con, con.getClass());
return con;
}이제 이렇게 하면 아까 개념에서 말했듯이 매니저에서 수동 커밋을 한다고 했습니다. 이러면 트랜잭션이 시작이 되는 것이라서 setAutoCommit 지우고 로직에 파라미터로 con 안 넣어도 됩니다. 지금 서비스에서 사용하는 레포가 트랜잭션 동기화 매니저를 사용하는 것인데 getTranscation하면 매니저가 커낵션 만들고 동기화 매니저에게 넣어주는 것이라서 파라미터로 넣지 않아도 레포에서 get할 때 동기화 매니저에 보관된 커낵션을 꺼냅니다.
2) 커밋, 롤백
매니저의 커밋 메서드에 반환한 트랜잭션을 넣고 롤백도 넣습니다.
3) 릴리스
생각해보면 커밋되거나 롤백될 때 트랜잭션 종료이니 릴리스가 당연히 되어야합니다. 매니저가 알아서 해주니 삭제합니다.
이렇게 하니 비즈니스 로직에서 파라미터를 넣는 것은 동기화 매니저에서 꺼내와서 해결했고 jdbc 기술에 의존하는 것도 추상화하였습니다. 나중에 transactionManager로 DataSourceTransactionManager를 주입할 것입니다. 이것이 jdbc 매니저이고 나중에 jpa를 쓰면 jpa 매니저를 주입하면 됩니다.
-> 테스트
private MemberRepositoryV3 memberRepository;
private MemberServiceV3_1 memberService;
@BeforeEach
void beforeEach() {
DataSource dataSource = new DriverManagerDataSource(URL, USERNAME, PASSWORD);
PlatformTransactionManager transactionManager = new DataSourceTransactionManager(dataSource);
memberRepository = new MemberRepositoryV3(dataSource);
memberService = new MemberServiceV3_1(memberRepository, transactionManager);
}주입을 받아야하는데 이전에는 서비스에 데이터 소스를 직접 주입했는데 이제는 추상화된 매니저를 쓰기 때문에 트랜잭션 매니저를 데이터소스 매니저로 생성해서 넣어줍니다.
이렇게 하고 바로 돌리고 실행해보면 데이터 소스가 없다는 에러가 뜹니다. 트랜잭션 매니저를 DataSourceTransactionManager로 생성할 때 데이터 소스를 넣어줘야합니다. ★ 위에서 "이전에는 데이터 소스를 직접 주입했는데 이제는 서비스에서 추상화된 매니저를 쓰기 때문에 트랜잭션 매니저로 데이터소스 매니저를 생성해서 넣어줍니다."라고 했는데 매니저도 추상화하지만 그 안에는 커낵션 가져오는 것, 커밋, 롤백하는 것이 있습니다.
> 개념에서 말했듯이 로직에서 트랜잭션을 시작하면 매니저가 데이터 소스에서 커낵션을 생성한다고 했습니다. 그래서 데이터 소스가 내부에 필요하고 커낵션을 만들어야 트랜잭션에서 setAutocommit하고 만든 커낵션 동기화 매니저에 넣어줄 수 있습니다.
-> 설명
트랜잭션 매니저를 주입 받았습니다. accountTransfer를 하면 매니저를 통해 getTransaction으로 트랜잭션을 획득합니다. 그러면 트랜잭션 매니저가 데이터 소스를 받으니 커낵션을 만들고 수동 커밋하고 동기화 매니저에 보관합니다.
그리고 로직을 수행하면 find를 호출하면 커낵션을 getConnection로 획득하는데 DataSourceUtils.getConnection(dataSource)로 획득하고 이게 동기화 매니저에 있는 트랜잭션 시작한 커낵션을 가져옵니다.

+ 끝나면 close를 하는데 레포가 close할 때 동기화 매니저에서 꺼낸 거면 커낵션 안 닫고 그냥 데이터 소스에서 find를 해서 그 순간 커낵션을 만든 호출이라면 닫습니다.(when은 동기화 매니저 then은 그 순간 커낵션 생성) 그러고 트랜잭션이 종료되고 로직이 종료하면 성공하면 커밋을 하는데 그러면 매니저가 커밋하고 리소스를 릴리즈하고 동기화 매니저의 커낵션도 정리합니다. 알아서 매니저가 정리해줘서 release 코드가 사라집니다.
-> 그림
앞에한 로직을 그림으로 정리하겠습니다.

1) 클라의 요청으로 로직 accountTran이 시작합니다.
2) transactionManager.getTransaction(new DefaultTransactionDefinition())을 합니다. 이러면 jdbc 트랜잭션 매니저가 주입됩니다.
3) 트랜잭션 매니저가 커낵션이 필요하니 커낵션을 가지고 있는 데이터 소스로 생성합니다.
4) 그리고 수동 커밋하고 동기화 매니저에 보관합니다. 이게 transactionManager.getTransaction(new DefaultTransactionDefinition());하면 일어나는 일입니다.
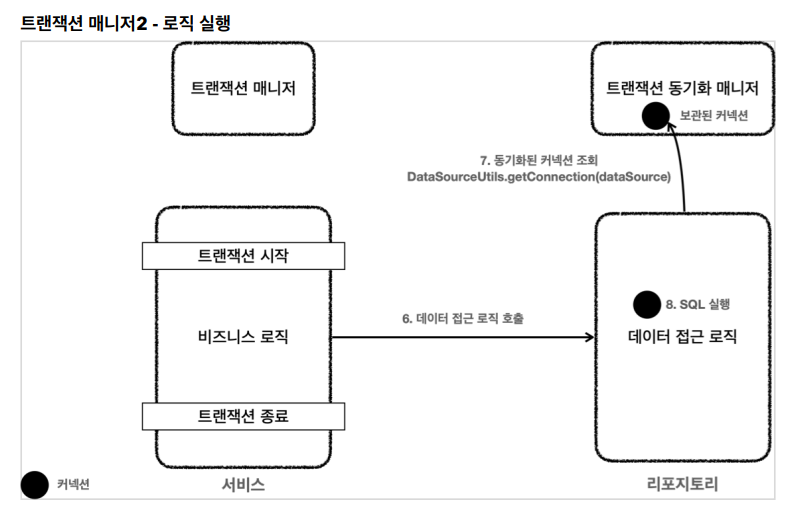
5) 트랜잭션을 시작했고 로직을 시작하면 update, find를 하는데 이때 커낵션을 파라미터로 전달할 필요가 없고 레포는 커낵션이 필요하면 동기화 매니저로부터 DataSourceUtils.getConnection(dataSource);로 가져오고 이것으로 커낵션을 유지합니다.
6) 이렇게 획득한 커낵션을 통해 sql을 db에서 수행합니다.
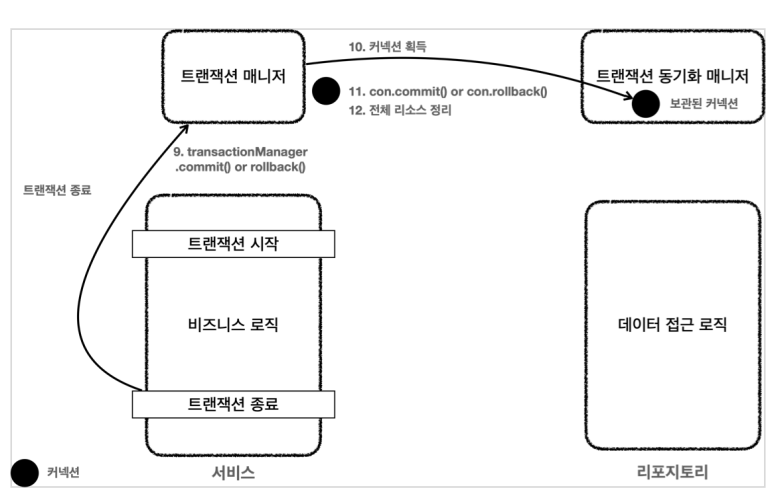
7) 로직이 종료하고 커밋이나 롤백하여 트랜잭션이 종료하면 동기화 매니저로부터 커낵션을 꺼내서 획득한 커낵션으로 트랜잭션을 커밋하거나 롤백합니다. 커낵션이 있어야 커밋과 롤백을 할 수 있었습니다.( con.close(); )
8) 그리고 매니저가 동기화 매니저의 커낵션을 제거하고 커낵션을 자동 커밋으로 바꾸고 con.close를 해서 커낵션을 종료하고 풀을 사용하면 풀로 반환합니다.
-> 정리
추상화를 해서 서비스는 jdbc에 의존하지 않고 트랜잭션 매니저 인터에 의존합니다. 그래서 이제 DI만 바꾸면 jdbc를 쓰다가 jpa를 쓰면 new DataSourceTransactionManager(dataSource);를 바꾸면 서비스 코드는 변경하지 않아도 됩니다. 동기화 매니저 덕분에 이제 파라미터로 커낵션을 넘기지 않아도 됩니다.
- 문제점
트랜잭션 로직을 보면 try catch로 트랜잭션을 시작하고 로직을 수행하고 성공하면 커밋하고 롤백하는 반복되는 코드가 보입니다. 이런 서비스 클래스가 회원, 주문 등 여러 개가 있으면 DB 접근 할 때마다 반복이 될 것입니다. 이 코드가 다 똑같고 달라지는 부분은 로직 부분외에 트랜잭션 관리 코드는 똑같습니다. 이럴 때 템플릿 콜백 패턴을 사용하면 트랜잭션 시작, 커밋, 롤백 반복을 해결할 수 있습니다.
-> 트랜잭션 탬플릿
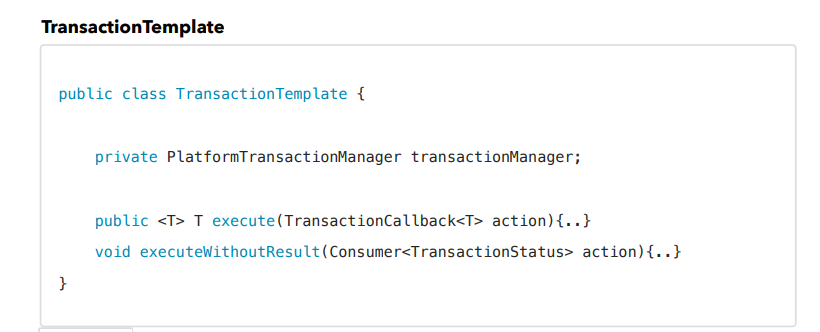
콜백 패턴을 적용하려면 탬플릿을 제공하는 클래스를 작성해야합니다. 스프링은 TransactionTemplate라는 탬플릿 클래스를 제공합니다. 이 클래스 안에 트랜잭션 관리 코드(시작, 커밋, 롤백)이 다 들어가 있고 개발자는 비즈니스 로직만 따로 작성하면 됩니다. 코드를 보면 트랜잭션 매니저가 필요하고 실행하는 메서드가 제공됩니다.
- 반복 제거 구현
try {
// 시작
bizLogic(toMemberId, money, fromMemberId);
transactionManager.commit(status);
// 커밋, 롤백
} catch (IllegalStateException e) {
transactionManager.rollback(status);
throw new IllegalStateException(e);
}이 반복하는 코드를 제거할 것입니다.
private final MemberRepositoryV3 memberRepository;
// private final PlatformTransactionManager transactionManager;
private final TransactionTemplate txTemplate;
public MemberServiceV3_2(MemberRepositoryV3 memberRepository, PlatformTransactionManager transactionManager) {
this.memberRepository = memberRepository;
this.txTemplate = new TransactionTemplate(transactionManager);
}트랜잭션 매니저 주입을 주석처리하고 트랜잭션 탬플릿을 선언하고 설정을 해줘야합니다. 밖에서 설정하고 주입 받아도 되는데 몇 가지 설정을 위해 롬복 생성자가 아닌 서비스 생성자를 만들고 매니저를 파라미터로 받습니다.
> 위에 템플릿 클래스를 봤을 때 매니저가 선언되어 있는데 탬플릿을 쓰려면 매니저가 필요해서 그렇습니다. 탬플릿은 그냥 클래스라서 빈에 등록하고 주입하기보단 매니저를 받는 코드로 쓰는 경우가 관례입니다.
-> 사용법
// 탬플릿 코드
public void accountTransfer(String fromMemberId, String toMemberId, int money) throws SQLException {
txTemplate.executeWithoutResult((status) -> {
try {
bizLogic(toMemberId, money, fromMemberId);
} catch (SQLException e) {
throw new IllegalStateException(e);
}
});
}
// 사라지는 코드
TransactionStatus status = transactionManager.getTransaction(new DefaultTransactionDefinition());
try {
// 시작
bizLogic(toMemberId, money, fromMemberId);
transactionManager.commit(status);
// 커밋, 롤백
} catch (IllegalStateException e) {
transactionManager.rollback(status);
throw new IllegalStateException(e);
}탬플릿이 매니저를 감싸고 있어서 매니저가 하는 생성, 커밋, 롤백을 다 수행해 줄 것입니다. 지금은 반환값이 없어서 두 실행 메서드 중 executeWithoutResult를 해서 인자로 매니저의 트랜잭션 생성하는 코드의 TransactionStatus status = transactionManager.getTransaction(new DefaultTransactionDefinition());로 만든 status를 파라미터로 넣고 로직을 넣으면 끝납니다. status 안에 트랜잭션 시작, 수동 커밋, 동기화 매니저로 보내는 것이 들어있습니다. 로직에서 sqlEx가 터지는데 try로 잡습니다. 이렇게 하면 try로 하던 트랜잭션 관리 로직이 전부 사라집니다.
> execute를 하면 이 코드 안에서 트랜잭션을 시작하고 로직을 하고 로직이 끝났을 때 성공하면 커밋하고 예외가 터지면 롤백합니다. 탬플릿 덕분에 트랜잭션을 시작하고 커밋 롤백하는 코드가 다 제거됩니다.
-> 동작
트랜잭션을 시작하고 이전에 시작하면 생기는 status를 그냥 파라미터로 넣어주고 성공하면 커밋하고 예외가 발생해야 롤백합니다. (언체크 예외가 발생하면 롤백하고 그외 예외는 커밋하는데 뒤에서 다룹니다.)
- 정리
탬플릿 덕분에 트랜잭션 관리 반복 코드를 제거할 수 있었습니다. 이전에는 트랜잭션 시작 > 로직 > 커밋 > 롤백을 다 서비스 코드에 작성했어야 했는데 이제는 탬플릿만 호출하면 매니저를 받고 그 안에 비즈니스 로직만 따로 만들어서 넣으면 됩니다.
근데 아직 해결되지 않은 문제가 있습니다. 코드가 줄기는 했는데 아직 서비스 로직에 트랜잭션 관리 로직이 남아 있습니다. 이렇게 두 로직이 한 곳에 있으면 두 관심사가 하나의 클래스에 있는 것이라서 결과적으로 코드를 유지보수하기 어려워집니다. 서비스 로직은 가급적 핵심 비즈니스 로직만 있어야합니다. 하지만 트랜잭션 기술을 사용하려면 어쩔 수 없이 트랜잭션 코드가 나와야합니다. 이를 트랜잭션 AOP로 해결합니다.
- 트랜잭션 AOP
많은 문제를 해결했지만 아직 서비스에 순수 로직 외에 트랜잭션 관리 코드가 남은 문제를 해결하지 못했고 이것을 AOP를 통해 프록시를 도입하면 문제를 해결할 수 있습니다. @Transactional을 사용하면 스프링이 AOP를 사용해서 트랜잭션을 편리하게 처리해줍니다.
- 프록시를 통한 문제 해결
-> 프록시 도입 전

클라가 서비스 로직을 호출하면 여기서 트랜잭션을 시작하고 로직도 했습니다. 탬플릿을 써도 결과는 같았습니다.
-> 도입 후
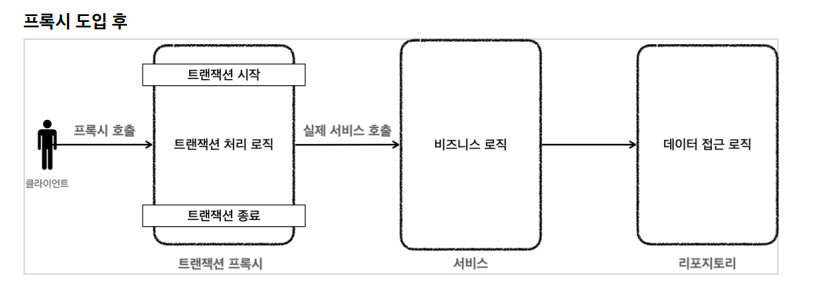
서비스 로직을 그대로 두고 트랜잭션 프록시를 만듭니다. 프록시는 대리인인데 클라가 서비스를 직접 호출하는게 아니고 "클라가 프록시를 호출하면 여기서 트랜잭션을 시작하고 프록시가 실제 서비스를 호출"하고 응답이 오면 프록시에서 트랜잭션을 종료하는 것입니다.
- 코드

이런 코드를 스프링이 다 만들어주고 스프링 빈으로 만들어줍니다. 코드 예시를 보면 서비스에는 순수한 로직만 남습니다.

프록시 코드는 서비스 코드를 target으로 가지고 클라는 프록시를 호출하면 트랜잭션을 시작하고 실제 대상을 호출하고 성공하면 커밋, 실패하면 롤백합니다.
// 실제 서비스
public void accountTransfer(String fromMemberId, String toMemberId, int money) throws SQLException {
TransactionStatus status = transactionManager.getTransaction(new DefaultTransactionDefinition());
try {
// 시작
bizLogic(toMemberId, money, fromMemberId);
transactionManager.commit(status);
// 커밋, 롤백
} catch (IllegalStateException e) {
transactionManager.rollback(status);
throw new IllegalStateException(e);
}
}서비스에 있던 코드와 완전 동일하게 작성되어있는데 이것을 실제 서비스에 두는 것이 아닌 서비스에는 로직만 있고 프록시가 서비스를 호출하여 로직을 수행하고 클라는 서비스가 아닌 프록시를 호출하여 트랜잭션 관리를 하면 프록시가 서비스도 호출해주니 관리와 로직을 다 하는 개념입니다.
> 프록시가 관리 로직을 모두 가져가고 트랜잭션 시작 후 실제 서비스를 대신 호출해줘서 덕분에 서비스에는 순수한 비즈니스 로직만 남습니다.
- 트랜젝션 AOP란?

스프링이 제공하는 AOP를 사용하면 프록시를 매우 편리하게 사용할 수 있습니다. 스프링 AOP를 직접 사용해서 트랜잭션 처리해도 되지만 스프링이 트랜잭션 용 AOP를 제공합니다. 개발자는 트랜잭션이 비즈니스 로직에 @Transactional만 붙이면 스프링 트랜잭션 AOP는 이 에노테이션을 인식해서 트랜 프록시를 적용해줍니다.
"@Transactional이 있으면 스프링이 트랜잭션 프록시를 실제 서비스 앞에 만들어주고 호출하게 해주는 구나"라고 생각하면 됩니다.
- 트랜잭션 AOP 적용
// 이전
private final MemberRepositoryV3 memberRepository;
// private final PlatformTransactionManager transactionManager;
private final TransactionTemplate txTemplate;
public MemberServiceV3_2(MemberRepositoryV3 memberRepository, PlatformTransactionManager transactionManager) {
this.memberRepository = memberRepository;
this.txTemplate = new TransactionTemplate(transactionManager);
}
public void accountTransfer(String fromMemberId, String toMemberId, int money) throws SQLException {
txTemplate.executeWithoutResult((status) -> {
try {
bizLogic(toMemberId, money, fromMemberId);
} catch (SQLException e) {
throw new IllegalStateException(e);
}
});
}
// 이후
private final MemberRepositoryV3 memberRepository;
public MemberServiceV3_4(MemberRepositoryV3 memberRepository) {
this.memberRepository = memberRepository;
}
public void accountTransfer(String fromMemberId, String toMemberId, int money) throws SQLException {
bizLogic(toMemberId, money, fromMemberId);
}이제 탬플릿이 없어지고 트랜잭션과 관련된 코드가 없어집니다. 로직만 남습니다. 트랜잭션관련 코드가 다 없어집니다.
@Transactional
public void accountTransfer(String fromMemberId, String toMemberId, int money) throws SQLException {
bizLogic(toMemberId, money, fromMemberId);
}@Transactional을 accountTransfer 메서드에 붙입니다. 이 뜻은 "난 이 메서드 호출할 때 트랜잭션 걸고 시작하겠다. 이 메서드가 끝나면 성공하면 커밋, 예외가 터지면 롤백하겠다" 입니다.
> 순수한 비즈니스 로직만 남기고 트랜잭션 관련 코드를 모두 제거했고 @Transactional을 붙였습니다. @Transactional는 메서드에 붙여도 되고 클래스에 붙여도 됩니다. 클래스에 붙이면 클래스 내부에 있는 외부에서 호출 가능한 메서드에 @Transactional이 다 붙습니다.
-> 테스트
// 이전
@BeforeEach
void beforeEach() {
DataSource dataSource = new DriverManagerDataSource(URL, USERNAME, PASSWORD);
PlatformTransactionManager transactionManager = new DataSourceTransactionManager(dataSource);
memberRepository = new MemberRepositoryV3(dataSource);
memberService = new MemberServiceV3_2(memberRepository, transactionManager);
}
// 이후
@BeforeEach
void beforeEach() {
DataSource dataSource = new DriverManagerDataSource(URL, USERNAME, PASSWORD);
PlatformTransactionManager transactionManager = new DataSourceTransactionManager(dataSource);
memberRepository = new MemberRepositoryV3(dataSource);
memberService = new MemberServiceV3_4(memberRepository);
}이제 서비스가 매니저를 받지 않습니다. 이전에는 서비스에 매니저를 생성자에 넣어서 transactionManager.getTransaction(new DefaultTransactionDefinition());로 트랜잭션을 시작하거나 탬플릿을 사용하면 탬플릿이 생성될 때 매니저를 넣어야 해서 서비스에 매니저를 넣어줘야했는데
> 이제는 프록시가 있어서 프록시에서 다 트랜잭션을 처리하기 때문에 서비스에는 트랜잭션과 관련된 코드, 레퍼런스가 아예 없어집니다.
-> 실행
그냥 실행하면 트랜잭션 적용이 안됩니다. 예외가 터졌는데 롤백이 안 된 것입니다. 이전에 트랜잭션을 직접 적용했을 때는 catch로 실패하면 롤백했는데 지금 트랜잭션이 안 된 것입니다.
> 왜 안됐냐면 지금 테스트는 스프링 컨테이너를 전혀 쓰고 있지 않습니다. 스프링 빈을 아예쓰지 않고 직접 생성자에 넣어주면서 테스트하고 있습니다. 스프링이 제공하는 AOP를 쓰려면 스프링 컨테이너에 빈을 등록하는 등 스프링을 써야합니다.
- 테스트에 스프링 사용
// 이전
@BeforeEach
void beforeEach() {
DataSource dataSource = new DriverManagerDataSource(URL, USERNAME, PASSWORD);
memberRepository = new MemberRepositoryV3(dataSource);
memberService = new MemberServiceV3_4(memberRepository);
}
// 이후
@Autowired
private MemberRepositoryV3 memberRepository;
@Autowired
private MemberServiceV3_4 memberService;
@TestConfiguration
static class TestConfig {
@Bean
DataSource dataSource() {
return new DriverManagerDataSource(URL, USERNAME, PASSWORD);
}
@Bean
PlatformTransactionManager transactionManager() {
return new DataSourceTransactionManager(dataSource());
}
@Bean
MemberRepositoryV3 memberRepositoryV3() {
return new MemberRepositoryV3(dataSource());
}
@Bean
MemberServiceV3_4 memberServiceV3_4() {
return new MemberServiceV3_4(memberRepositoryV3());
}
}1) @SpringBootTest : 테스트를 돌릴 때 스프링이 이 어노를 보고 스프링 컨테이너를 띄우고 빈을 등록하고 주입도 합니다.
2) DI : 이제 레포와 서비스를 빈에 등록하고 Autowired합니다. 이제 주입하던 beforeEach는 날리고 testconfiguration을 넣습니다. 그냥 Config 클래스에 직접 빈 등록하는 것을 static으로 내부 클래스로 만들고 직접 빈 등록하는 것입니다. 일반 Config는 @Configuration을 붙이는데 테스트에서는 Testconfiguration로 하는 것입니다. @SpringBootTest을 하면 스프링이 테스트에 필요한 것을 빈으로 등록하는데 @testconfiguration을 하면 거기에 원하는 빈을 추가로 등록해서 쓸 수 있습니다.
+ 프록시는 빈을 가져다 써야하는데 이렇게 하면 프록시에서 등록한 빈을 다 가져다 쓸 수 있습니다. 일단 데이터 소스와 매니저가 트랜잭션 AOP를 하는데 꼭 필요합니다. 레포와 서비스도 등록합니다.
-> 설명
스프링이 제공하는 트랜잭션 AOP는 매니저를 찾아서 사용하기 때문에 등록해야 합니다. 빈 등록이라도 없는 코드를 실행할 수는 없습니다. AOP도 다 내부에서 매니저로 트랜잭션을 시작하고 성공하면 커밋하고 할 것이기에 설정에서 빈 등록 해야합니다.
+ 프록시 적용 검증
@Test
void AopCheck() {
log.info("memberService class={}", memberService.getClass());
log.info("memberRepository class={}", memberRepository.getClass());
Assertions.assertThat(AopUtils.isAopProxy(memberService)).isTrue();
Assertions.assertThat(AopUtils.isAopProxy(memberRepository)).isFalse();
}AOP 트랜잭션이 걸렸는지 보고 싶어서 테스트를 만듭니다. 클래스 정보를 찍어보면 레포는 @Tran을 안붙여서 제대로 클래스 정보가 나오는데

서비스는 @Tran을 붙여서 CGLIB이 나옵니다. @Tran이 붙어있으면 붙은 클래스를 상속받아서 트랜잭션 프록시에 서비스의 비즈니스 코드가 있은 클래스를 재정의하고 대신 등록됩니다.

그래서 지금 등록한 게 실제 멤버 서비스가 아니고 멤버 서비스를 상속받은 프록시 코드라서 그 프록시 코드는 내부에 트랜잭션 관리 코드와 실제 서비스 target의 비즈니스 로직이 상속을 받으니 있으니 트랜잭션이 적용된 로직이 수행됩니다.
> 쉽게 생각해보면 @Transactional을 붙여서 트랜잭션 관리 코드와 로직 코드가 서비스에 같이 있는 것인데 우리가 작성한 코드는 로직밖에 없어서 확실히 분리가 된 것처럼 눈속임 하는 것입니다. AopUtils를 해보면 프록시가 true가 나옵니다.
- 트랜잭션 AOP 정리
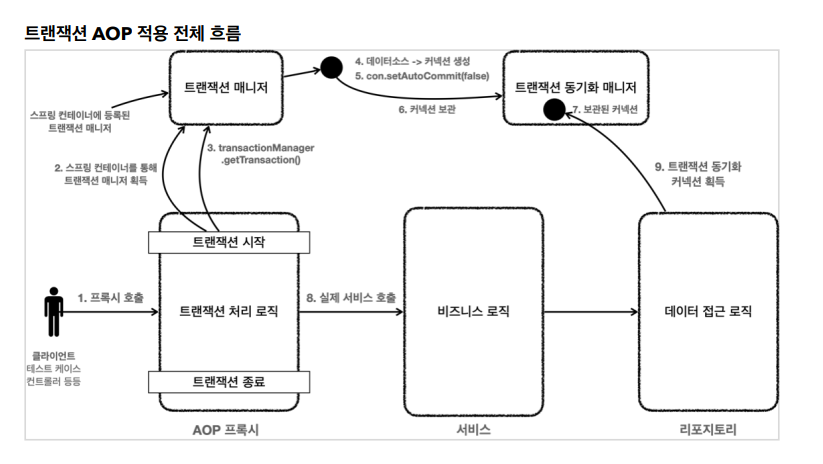
그림으로 트랜잭션 AOP를 정리해보겠습니다. @Transactional이 붙어있으면 스프링이 "너는 트랜잭션이 적용되는 프록시 클래스를 만들어야 겠구나"하고 프록시를 만듭니다. 이 프록시에서 트랜잭션을 다 처리하고 실제 서비스(부모)를 호출해줍니다.
memberService.accountTransfer(memberA.getMemberId(), memberB.getMemberId(), 2000);우리가 빈에 등록한 것은 memberService.accountTransfer을 할 때 프록시 서비스입니다. 주입받는 시점에 프록시 클래스를 주입하고 클라가 로직을 호출하면 프록시를 호출하고 프록시에서 매니저를 통해서 트랜잭션을 시작합니다. 그래서 매니저도 빈으로 등록해야합니다.
> 그 후에는 똑같이 데이터 소스를 통해 커낵션을 생성, 수동 커밋하고 동기화 매니저에 넣습니다. 그리고 프록시에서 실제 로직을 호출합니다. 그러면 실제 로직이 실행되고 그 로직에 find랑 update인 레포의 메서드가 있는데 그 레포가 getConnection을 DataSourceUtils.getConnection(dataSource);로 해서 동기화 매니저의 커낵션을 사용합니다. 끝나면 프록시에서 트랜잭션을 관리하는 코드가 있으니 성공하면 커밋, 실패하면 롤백합니다.
- 선언적 트랜잭션 관리 vs 프로그래밍 방식 트랜잭션 관리
1. 선언적
@Transactional 하나 붙이는 것을 말하며 "내가 이것을 트랜잭션으로 쓰겠다!" 선언하는 것입니다.
2. 프로그래밍
탬플릿이나 매니저를 통해 트랜잭션을 직접 짜는 것입니다. 둘 중에 실무에서는 선언적을 99.9% 사용합니다. 프로그래밍 방식은 스프링 기술 없이 간단하게 사용할 수 있다는 장점이 있어서 테스트에서 가끔 사용할 때가 있다.
- 스프링 부트의 자동 리소스 등록

부트가 등장하기 전에는 개발자가 직접 데이터 소스와 매니저를 직접 config에 빈 등록했습니다. 근데 부트를 쓰면 소스와 매니저를 직접 등록한 적이 없을 것입니다. 기존에는 데이터 소스와 매니저를 직접 빈으로 등록해야 했습니다. 그런데 부트가 나오면서 자동화 되었습니다.
-> 데이터 소스 자동 등록
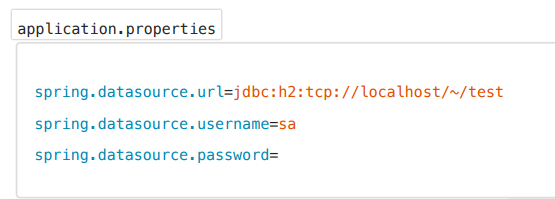
부트는 소스를 빈으로 자동 등록해서 dataSource라는 이름으로 빈 등록해줍니다. 개발자가 직접 소스를 빈으로 등록하면 부트가 자동으로 등록하지 않습니다. 부트는 프로퍼티스에 있는 속성을 사용해서 DataSource를 생성하고 빈 등록합니다. 데이터 소스가 설정 정보를 필요로 했었습니다.
> 부트가 제공하는 소스는 hikari 데이터 소스로 커낵션 풀과 관련된 이름이나 풀 접속 시간, 풀 개수 등 설정도 프로퍼티스에 지정할 수 있습니다.
-> 트랜잭션 매니저 자동 등록
@Bean
PlatformTransactionManager transactionManager() {
return new DataSourceTransactionManager(dataSource());
}transactionManager라는 빈 이름으로 등록해줍니다. 역시 개발자가 config로 매니저를 등록하려고 하면 부트가 등록하지 않고 개발자가 우선됩니다.
> 그러면 매니저는 jdbc와 jpa가 다르다고 했고 등록할 때 jdbc면 return new DataSourceTransactionManager(dataSource()); 이걸로 등록했는데 어떤 것을 등록할 지는 현재 등록된 라이브러리를 보고 판단하는데 jpa를 사용하는 라이브러리가 있으면 jpa 매니저를 빈으로 등록하고 jdbc 라이브러리가 있으면 DataSourceTransactionManager를 등록해줍니다.
+ 둘 다 있으면 jpa 매니저를 등록하는데 jpa 매니저가 jdbc 매니저 기능도 제공하기 때문입니다.
- 테스트
직접 config에 등록한 데이터 소스와 매니저를 지울 것입니다.
// 이전
@Bean
DataSource dataSource() {
return new DriverManagerDataSource(URL, USERNAME, PASSWORD);
}
@Bean
PlatformTransactionManager transactionManager() {
return new DataSourceTransactionManager(dataSource());
}
@Bean
MemberRepositoryV3 memberRepositoryV3() {
return new MemberRepositoryV3(dataSource());
}
@Bean
MemberServiceV3_4 memberServiceV3_4() {
return new MemberServiceV3_4(memberRepositoryV3());
}
// 이후
@TestConfiguration
static class TestConfig {
private final DataSource dataSource;
public TestConfig(DataSource dataSource) {
this.dataSource = dataSource;
}
@Bean
MemberRepositoryV3 memberRepositoryV3() {
return new MemberRepositoryV3(dataSource);
}
@Bean
MemberServiceV3_4 memberServiceV3_4() {
return new MemberServiceV3_4(memberRepositoryV3());
}
}근데 레포가 데이터 소스가 필요하니 생성자 주입하면 됩니다. 이렇게 하면 개발자가 직접 등록하지 않으니 스프링이 자동으로 등록하는 소스가 주입됩니다.
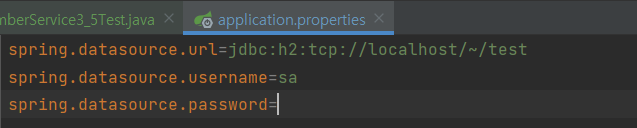
그냥 돌리면 안 되고 프로퍼티스에 설정해야합니다. 테스트 해보면 정상적으로 테스트를 성공합니다.
'[백엔드] > [spring | 학습기록]' 카테고리의 다른 글
| spring PART.스프링 데이터 접근 예외 처리 (0) | 2023.05.07 |
|---|---|
| spring PART.자바 예외 이해 (0) | 2023.05.06 |
| spring PART.트랜잭션 이해 (0) | 2023.05.03 |
| [문법] 커넥션과 데이터 소스 (0) | 2023.05.02 |
| [문법] JDBC 추상화를 한 이유 (0) | 2023.05.01 |



