

개발자로 후회없는 삶 살기
DB 설계 PART.DB 설계 및 구축 본문
서론
※ 이 포스트는 다음 강의의 학습이 목표임을 밝힙니다.
https://www.youtube.com/playlist?list=PL9hiYwOHVUQduJN7Pf_kOR8htpJU7K1H8
2020 데이터베이스
www.youtube.com
본론
테이블을 만들 때는 만드는 규칙이 있습니다. 테이블을 정확하고 효율적으로 설계하는 법을 알아봅니다.
- 기본키와 외래키
1. 기본키
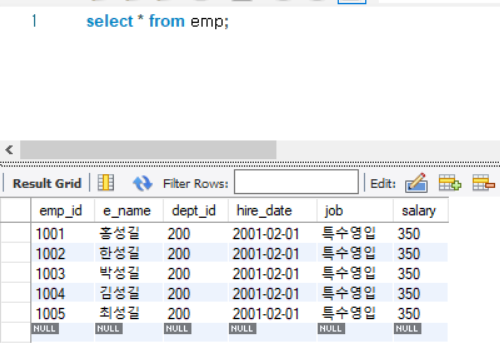
기본키와 외래키는 DB 설계에서 참조 관계를 다룰 때 정확이 설계해야 하는 부분입니다. 테이블에 동일한 인물이 두 명있거나 같은 데이터가 들어있는 것을 방지하기 위해 pk를 만들어야 합니다.

'1001' pk를 중복 입력하면 중복 에러가 발생합니다. 한 번 pk를 넣어두면 같은 pk를 또 넣을 수 없어서 중복을 방지 할 수 있습니다.
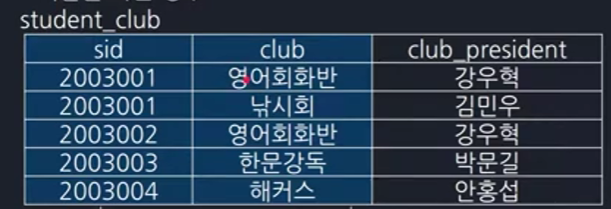
기본키는 컬럼 여러개를 조합해서 만들수 도 있는데 후보키 개념의 '유일성과 최소성'을 만족할 수 있으면 기본키의 후보가 될 수 있습니다. 예시로 '학생_동아리 테이블'을 보면 한 학생(ex '2003001')이 여러 개의 동아리를 가입할 수 있어서 sid만으로 데이터를 구분할 수 없습니다.
> 그래서 학생과 동아리를 합쳐서 기본키로 만들어야 합니다. 이렇게 되면 학생과 동아리를 조합해서 중복이 되는 데이터는 없습니다. (사실 이 관계는 한 학생이 여러개의 동아리에 가입할 수 있고 하나의 동아리에 여러 학생이 들어올 수 있어서 M:N 관계이고 맵핑 테이블을 만들어야 합니다.)
2. 외래키
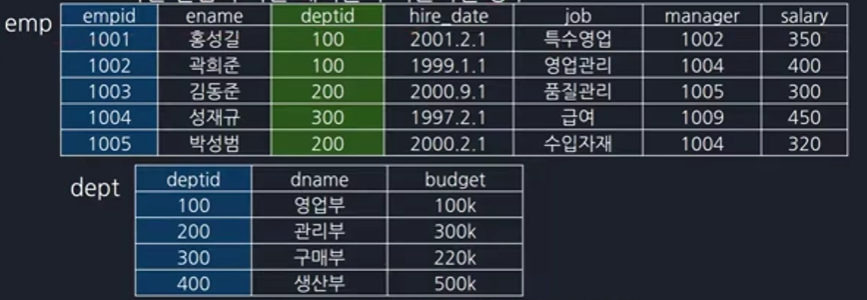
어떤 컬럼이 다른 테이블의 기본키인 경우가 있습니다. '이 사원이 어떤 부서인가'를 나타낼 때 부서 테이블의 기본키를 사원 테이블의 컬럼으로 사용합니다. 사원 테이블이 부서 테이블을 참조하고 있다는 것을 의미합니다.

개채 무결성을 생각했을 때 기본키가 아닌 키는 외래키로 사용될 수 없습니다. 현재는 사원 테이블의 dept_id가 부서 테이블의 dept_id를 참조한다고 선언하지 않았기에 모든 값이 다 들어갈 수 있습니다.

이렇게 외래키를 설정함으로써 사원 테이블과 부서 테이블에 관계를 주었습니다.

이제 emp 테이블에 500번을 추가하면 부서 테이블의 기본키에 없는 데이터이므로 없는 데이터를 참조했다고 에러가 나옵니다. 참조 관계에서는 참조가 되는 테이블이 부모 테이블인데 부모 테이블에 없는 기본키를 외래키로 자식 테이블에 넣으려 했다고 에러가 발생합니다. 따라서 어떤 컬럼이 다른 테이블의 기본키일 경우 참조 관계가 발생하고 넣을 수 있는 데이터가 제한됩니다.
- 정보 시스템 구축과 DB 설계
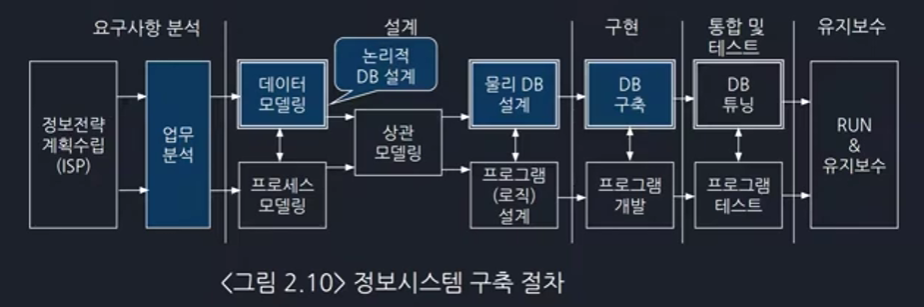
SW를 개발할 때 요구사항 분석 후에 DB 설계를 합니다. 프로그램을 개발하는 것은 DB 설계가 끝난 다음에 하며 먼저 설계가 완료되어야 하고 설계에서 가장 중요한 것이 DB 설계입니다. 따라서 DB가 없는 상태에서는 개발이 안 됩니다.
=> 데이터 모델링
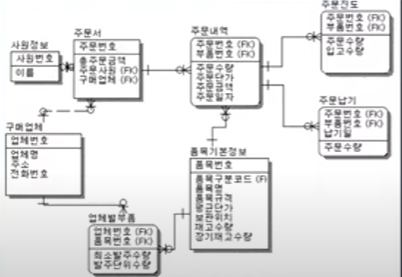

첫번째 논리적 설계에서는 DB ERD를 작성합니다. 논리적 설계에서 Entity가 테이블과 같은 말입니다. 실제 세계를 컴퓨터 세계에 넣기 위해서 추상화 해보겠습니다.
ex) 도서관 시스템
예를들어서 도서관 시스템을 만들고 싶은 상태입니다. 그럴 때 요구사항은 이러합니다.
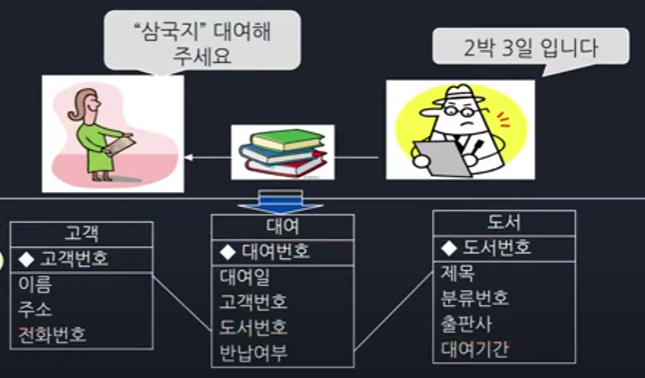
사람이 도서관에 간다.
사람이 도서관에서 삼국지 책을 대여한다.
도서관에는 고객이 여러명 올 수 있다.
고객은 한 번에 여러개의 책을 대여할 수 있다.
이런 식으로 실제 시스템을 사용하는 사람들의 실태를 분석하고 이 시스템에 필요한 기능을 정의하는 것이 요구사항 분석이고 이를 바탕으로 고객, 대여, 도서 개체와 관계를 정하여 DB를 설계합니다. 이를 ERD로 그리고 이를 최적으로 만드는 것이 시스템 성능에 매우 중요하게 작용합니다.
-> 엔터티 도출
다음 요구사항을 보고 엔터티를 도출해보겠습니다. 이 엔터티가 이후 객체와 맵핑될 것입니다. 여기서 DB 설계에 필요한 요구사항은 이러합니다.

책과 음반을 판매한다.
회원가입을 한 회원만 책을 주문할 수 있다.
이때 엔터티는 책, 음반, 회원, 주문입니다. 회원과 책, 음반은 시스템에 사용되거나 시스템을 이용할 데이터 목록으로 들어갈 것이라서 일반적으로 생각할 수 있습니다.
그럼 주문을 보겠습니다. 책과 회원은 현재 아무 관계가 없습니다. 근데 회원이 책을 주문할 때 관계가 생깁니다. 이를 쉽게 생각하면 '나의 주문 목록'으로 볼 수도 있습니다. 회원이 책을 주문했을 때 주문도 데이터가 생길 것이고 '회원이 책을 주문한다.' 이런 요구사항이 있다면 회원, 책, 주문이 엔터티가 되는 것입니다.

다음 예제를 보겠습니다. 여기서 DB 설계에 필요한 요구사항은 이러합니다.
학생이 동아리에 가입한다.
주문 관계에서와 같이 '학생이 동아리에 가입한다.'라고 보면 학생, 동아리, 가입 3개가 엔터티입니다. 학생과 동아리는 역시 일반적이고 전혀 관계가 없던 학생과 동아리가 가입을 하면서 관계가 생깁니다. 동아리 회장과 지도교수, 동아리 방 속성을 가지고 분류라는 속성에는 '학술, 종교, 봉사, 레포츠, 기타' 데이터가 들어갈 수 있습니다.
-> 관계 도출
엔터티를 도출했으면 관계를 도출할 차례입니다.
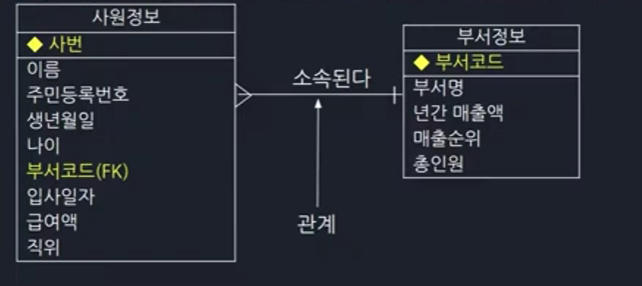
그림에서 사원정보 테이블은 부서정보 테이블의 부서 코드를 가지고 있습니다. 이 둘의 관계는 참조 관계로 이때 누가 먼저 있는 지 본다면 부서와 사원 중에 부서가 먼저 있습니다. 왜나하면 부서가 없으면 사원에 부서코드가 fk로 들어갈 수기 때문입니다. 먼저 부서가 있고 그 사원이 어떤 부서에 들어가는지 결정되는 것입니다.
> 이 소속관계는 부서가 부모, 사원이 자식으로 '자식 테이블의 fk는 부모 테이블의 pk'라는 ERD에서 변하지 않는 진리를 가집니다. 부모가 먼저 있고 자식이 나중에 있는 것입니다.
EX) 학생, 과목 관계

현재 학생과 과목은 아예 관계가 없습니다. 학생 안에 과목 속성이 있지 않습니다. 그런데 학생이 처음에는 관계가 없다가 수강 신청을 하므로써 관계가 맺어집니다. 수강 신청을 하면서 과목 테이블이 수강 과목 테이블로 되고 관계가 생깁니다.

이때는 학생이 1, 과목이 N 관계를 가집니다. 학생에서 바라보는 카디널리티는 N개이고 과목에서 바라보는 카디널리티는 1개입니다. 그냥 과목이었다면 N대 M일 텐데 수강 과목이 되면서 1 : N이 되고 1의 관계가 부모테이블이고 N이 자식 테이블입니다.
> 여기서 자식 테이블의 fk는 부모 테이블의 pk인 것이 수강과목이 학생의 학번을 가지고 있는 것으로 성립합니다. 앞에서도 사원이 N, 부서가 1이라서 자식인 N쪽이 부모인 1쪽의 PK를 FK로 가졌습니다.
> 남자 한명과 여자 두명의 삼각관계로 보면 남자는 두명을 바라보는 데 여자는 1명을 바라볼 때 남자가 1 여자가 N의 관계입니다. 남자쪽에서 여자를 봤을 때는 둘인데 여자쪽에서 바라봤을 때는 하나라는 것을 생각하면 쉽습니다. 학생에서 과목을 바라봤을 때는 여러개인데 과목에서 학생을 바라봤을 때는 하나입니다.
EX2) 학생, 신체 관계
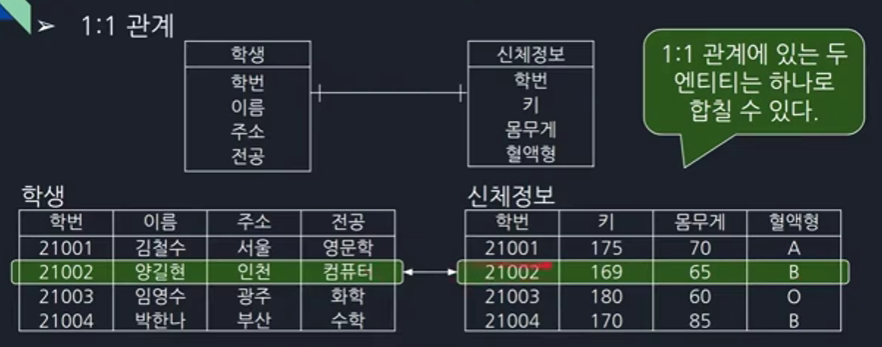
학생과 신체는 1대1입니다. 1대1 관계는 엔터티를 하나로 합칠 수 있습니다. 나누는 이유는 필수 정보인 학생, 선택 정보인 신체를 나눠 공간 절약을 고려할 때 엔터티를 2개로 관리합니다. 이렇게 데이터가 꽉 채워져있으면 엔터티를 합치는 게 좋고

비어있으면 필수 정보는 꽉 채워서 유지하고 선택 정보는 있는 사람만 선택하는게 좋습니다.
EX3) 제품, 제조업체 관계

제품에서 제조 업체를 봐도 N개, 업체에서 봤을 때도 N개면 M:N 관계입니다. 이런 M:N 관계에서는 둘 사이의 맵핑하는 맵핑 테이블을 하나 더 만들어야 합니다. M:N 관계는 서로 소속 관계가 없는 것으로 TV가 삼성에 소속되지 않고 삼성이 세탁기에 소속되지도 않습니다. 소속 테이블이 없어서 맵핑 테이블이 필요하게 됩니다. 맵핑 테이블은 어떤 제조업체가 어떤 제품을 만드는 지 나열하는 관계가 전부 들어있습니다.

M:N을 1:N 2개로 만들어 보겠습니다. 어떤 회사가 어떤 제품을 만드는 지 별도의 테이블을 가지게 됩니다. 그러면 ERD가 바뀌게 되고 제품_제조업체 맵핑 테이블이 생기고 양쪽 테이블의 pk를 fk로 가져서 어떤 제조업체가 어떤 제품을 만드는 지 나열하게 됩니다.
-> 외래 식별자의 역할

현재 사원과 부서는 아무 관계가 없습니다. 사원 테이블에 부서 테이블의 pk를 fk로 가지는 순간 '이 사원이 어떤 부서에 속해있다'는 관계가 생깁니다. 소속되는 쪽이 fk라는 정보를 가지고 있고 소속하는 쪽은 정보를 가지고 있지 않습니다.
- ERD 설계 실습
앞에서 공부한 내용을 토대로 논리적 모델링을 진행합니다. 논리적 모델링을 할 때는 테이블과 컬럼만 보며 컬럼 타입(INT) 없어야 하고 한글로 작성해도 되고 물리적 모델링을 할 때는 fk, index를 고려하고 영어로 작성해야 합니다. 현재 논리적 모델링을 워크밴치로 해서 물리적 모델링을 한다고 착각할 수 있는데 ERD를 워크밴치 도구로 그린다고 보면 됩니다. 따라서 현재 논리적 모델링에서는 null이냐 fk냐를 신경쓰지 않습니다.
1번)
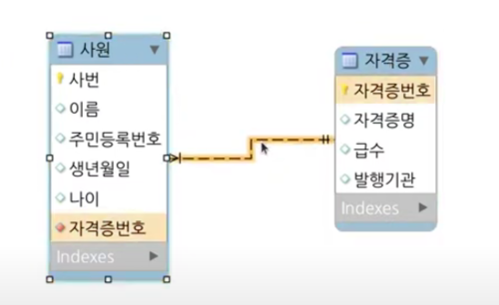
사원과 자격증 중에서 누가 부모일까요? 누가 누구에 들어가는지를 보면 사원이 자격증을 가지고 있는 것이 사람 입장에서 보면 자연스러워서 사원 테이블에 fk를 자격증 테이블의 pk로 하는 것이 좋을 것 같습니다.
하지만 사원과 자격증의 관계는 사원이 가지고 있는 자격증이 1번은 정처기, 2번은 리눅스 마스터, 3번은 컴활 이렇게 가지는 관계입니다.
그러면 이 관계는 사원이 자격증에 속할까요? 자격증이 사원에 속할까요? ✅
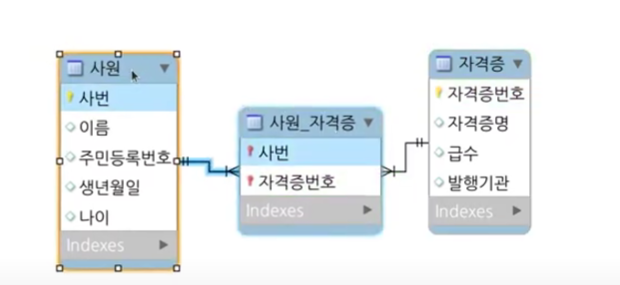
보면 1명의 사원이 N개의 자격증을 딸 수 있고 어떠한 자격증을 한 사람만 딸 수 있는 것이 아닌 여러 사람이 딸 수 있습니다. 따라서 M:N 관계입니다. 사원_자격증 테이블은 사원별로 어떤 자격증을 땄는지 맵핑하는 리스트가 담겨있습니다. 이렇게 참조 관계를 결정할 때는 몇 대 몇인지를 보는 것이 가장 정확한 방법입니다.
2번)

사원과 해외 근무지의 관계에 대한 문제입니다. 서로를 몇 대 몇으로 보는지 보면 사원은 하나의 근무지에서 일하고 근무지에는 사원이 여러명 있을 수 있으니 근무지가 1, 사원이 N입니다. 근무지가 사원에 속하는지 사원이 근무지에 속하는 지 생각해보면 근무지에 사원이 속하고 따라서 근무지가 더 먼저이니 근무지의 pk를 사원의 fk로 합니다.
3번)
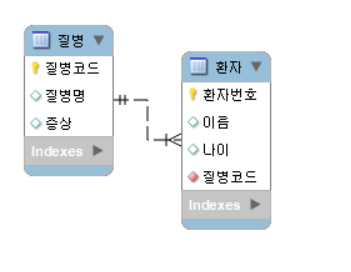
환자와 질병 관계를 보겠습니다. 역시 누가 먼저인지 봐야합니다. 조건 중에는 환자는 하나의 질병만 있다고 가정합니다. 따라서 질병이 1이고 환자가 N으로 환자가 질병에 소속됩니다. 질병에는 환자의 이름이 들어가지 않는데 환자의 서류에는 질병명이 박힙니다. 실제 현실에 대입해보면 환자를 담당하는 진료과는 1개로 볼 수 있습니다.
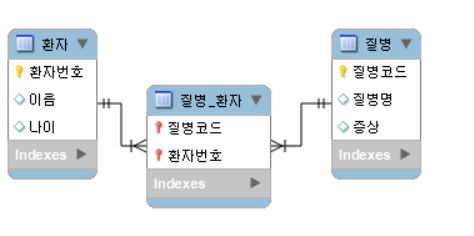
이건 환자가 1개의 질병만 걸린다는 조건하이고 실생활에서는 한 환자가 여러개의 병에 걸릴 수 있고 그 질병도 여러 환자가 걸릴 수 있습니다. 환자와 질병은 현실에서는 소속 관계가 없는 M:N 관계입니다.
환자_질병 테이블은 환자가 어떤 질병에 걸렸는지 매핑하는 리스트가 담긴 테이블로 환자와 질병이 소속 관계가 없어서 존재하는 테이블입니다. fk면서 pk가 될 때 관계가 실선이 됩니다.
fk가 pk는 아닐 때 점선이 됩니다. 환자_질병 테이블은 환자번호, 질병코드 2개를 조합해서 pk가 되기에 실선이 되는 것입니다. 이 또한 매우 중요한 사항으로 테이블에서 pk를 잘못 잡는 순간 이후는 의미가 없어집니다. 항상 pk를 잘 정하는게 중요합니다.
10번)

상품 코드가 tv, 냉장고일 수 있고 특정 회사 모델 코드일 수도 있습니다. 여기서는 모델 코드입니다. 상품과 업체는 상품이 업체에 소속된 코드입니다. LG라는 회사라면 회사에 휘센이라는 제품이 박혀있지 않고 휘센에 LG가 박혀있습니다. 업체가 부모, 상품이 자식입니다.
'[백엔드] > [DB | 학습기록]' 카테고리의 다른 글
| DB 설계 PART.인덱스 explain (0) | 2023.06.10 |
|---|---|
| DB 설계 PART.최적화와 인덱스 (0) | 2023.06.09 |
| DB 설계 PART.카카오톡, 이클래스, 교보문고 ERD 설계 (0) | 2023.06.08 |
| DB 설계 PART.네이버 영화 ERD 설계 (0) | 2023.06.08 |
| DB 설계 PART.정규화 (0) | 2023.06.07 |



