
개발자로 후회없는 삶 살기
[최적화] 졸업자 전체 조회 JPA 쿼리 튜닝 본문
서론
학과 홈페이지의 서버 부하의 80%는 복잡한 DB 연관관계 설계로 인해 조회 시 전송 데이터와 발생 쿼리량이 높기 때문입니다. 이를 JPA 쿼리 튜닝으로 해결하기 위한 고민과 테이블 재 설계 과정을 기록합니다.
본론
- 졸업 프로세스

저희 학교는 졸업 프로세스에 따라 졸업 신청을 4번 하게 되며 따라서 졸업자 목록 테이블과 4개의 졸업 신청 테이블의 연관 관계로 설계되어 있었습니다.
🚨 이처럼 설계한 이유

여러 명의 학생이 졸업을 하고 한 학생이 여러번의 졸업 신청을 하기에 다대다 매핑 관계로 설계하고 신청을 할 때마다 student_id가 apply 테이블에 등록했습니다.
졸업을 신청 > apply 테이블에 신청한 학생 id 등록(새 apply id + 동일 student_id) > 이 과정을 (접수, 제안서, 중간, 최종 보고서) 4번 반복
관리자가 학생의 제안서를 조회하고자 하면 apply에서 학생의 제안서 apply_id를 찾고 proposal 테이블에 검색하는 원리입니다. 학생이 신청하는 단계가 4개이므로, 4개의 테이블에 매핑할 apply_id를 apply 테이블에서 findAll로 찾고 URI에 매핑하도록 설계했던 것입니다. 즉, 졸업자를 학생을 조회하면 학생에 대한 쿼리 1번과 apply 관련 쿼리 1번, 총 2번이 발생합니다.
🚨 졸업자 전체가 200명이라면?
졸업자 전체 조회 : 쿼리 1번
200명의 apply id 4개 : 쿼리 200번
데이터 전송 : 200명의 신청 접수, 제안서, 중간 보고서, 최종 보고서 테이블 id
총 201번의 쿼리가 발생하고 800개의 추가 데이터 전송이 발생합니다.

따라서 졸업자 전체 조회 시 졸업자 수 * 4만큼의 DB select를 하게 되어 DB 부하와 웹의 로딩 지연이 발생했습니다. 이제부터 JPA로 해결한 방법을 알아보겠습니다.
- JPA 쿼리 튜닝 결과
1. 졸업자 전체 조회 지연로딩
@Entity
@Getter
@Table(name = "graduation")
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Graduation extends BaseEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "graduation_id")
private Long id;
# 지연로딩 적용
@OneToMany(mappedBy = "graduation", fetch = FetchType.LAZY)
List<Apply> applies = new ArrayList<>();Graduation 테이블은 졸업자 목록을 관리하는 테이블입니다. 기존 레거시 코드는 모든 신청 정보와 연관되어 있어 졸업자 수 * 4만큼의 데이터가 한 번에 불러와졌습니다. 이를 지연로딩을 사용하면 findAll 쿼리 1번으로 원하는 정보에 대한 쿼리만 발생시켜 쿼리 발생을 단순화 시킬 수 있었습니다.
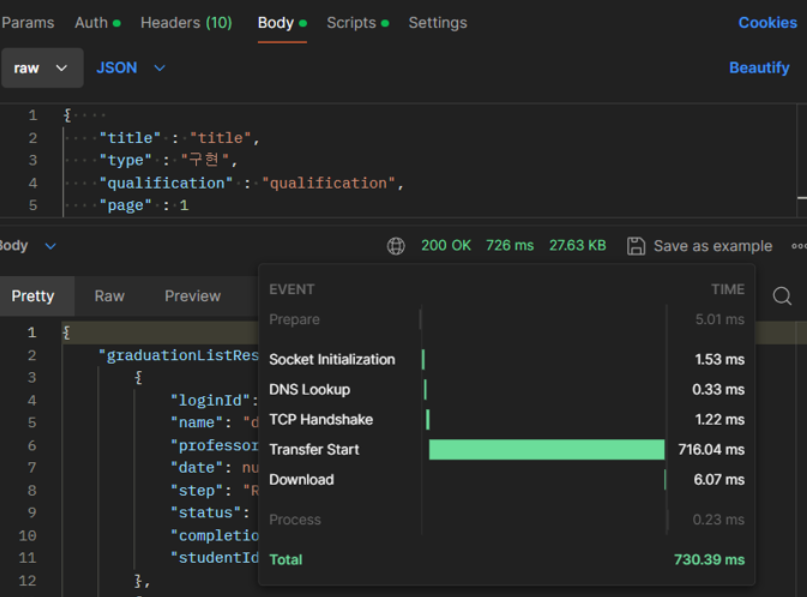
지연로딩을 적용한 결과 기존 대비 73%의 속도 개선을 확인할 수 있습니다.
2. 신청자 단건 조회 페치조인
public interface GraduationRepository extends JpaRepository<Graduation, Long> {
@Query("select g from graduation g left join fetch g.applys where g.status = :status and g.code != 'FINAL'")
Optional<Graduation> findByStatus(@Param("status") Boolean status);지연로딩으로 인해 단건 조회 시 4번의 쿼리가 추가로 발생했습니다. 이는 접속 사용자 수가 많은 졸업 신청 기간에 DB 서버의 네트워크 부하와 성능 부하를 야기할 수 있습니다. 이를 페치 조인을 사용하여 4번의 추가 쿼리를 1번으로 줄였습니다.
jpa:
open-in-view: false
hibernate:
ddl-auto: validate
properties:
hibernate:
show_sql: false
format_sql: false
default_batch_fetch_size: 1000페치조인을 1대N 관계에서 사용하면 중복 데이터 조회 문제가 발생하며 따라서 batch_size 옵션을 주었습니다. 사이즈는 DB 서버와 웹 서버의 CPU 점유율과 메모리 점유율을 확인하며 1000으로 정했습니다.
- 테이블 재설계
근본적인 문제를 해결하기 위해서는 테이블을 재설계 하는 것이 맞다고 판단됩니다.
기존 : 1명의 학생이 여러 번의 졸업을 신청함 -> 다대다
변경 : 하나의 졸업은 한명의 학생과만 매칭됨 -> 1대1
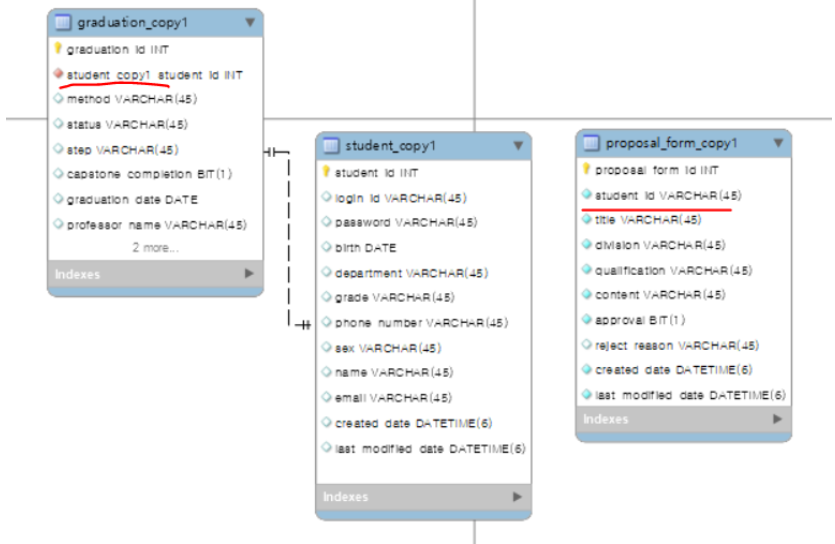
Student와 Graduation을 1대1로 매핑하고 졸업을 신청한 학생 id를 통해서 각각의 신청 테이블에 접근하도록 하여 불필요한 연관관계와 테이블을 제거했습니다.
결론
이렇게 하여 기존 레거시 코드에 존재하던 DB 부하로 인한 서버 다운 문제를 JPA 쿼리 튜닝으로 해결했습니다. 클라우드 환경이었다면 서버 다운 문제가 발생하지 않았을 수도 있지만, 학과 사무실의 물리 서버는 사양이 낮아 조회 작업에 취약했습니다. 이 문제를 직접 해결하면서 실제 서비스에서 발생할 수 있는 다양한 문제를 해결하고, 시스템의 속도를 개선하는 중요한 경험을 얻었습니다.
'[대외활동] > [캡스톤 디자인]' 카테고리의 다른 글
| [보안] RefreshToken, Redis 도입으로 성능 개선 및 탈취 당한 AccessToken 문제 방지 (0) | 2024.01.23 |
|---|---|
| 캡스톤 디자인 PART.JWT 관리자 정책 변경 (0) | 2023.08.18 |
| [보안] Jwt를 이용한 클라이언트 권한 인가 구현 (0) | 2023.08.02 |
| 캡스톤 디자인 PART.스프링 & 리액트 프로젝트 연동 (0) | 2023.07.22 |
| 캡스톤 디자인 PART.DB 모델링 변경사항 (0) | 2023.07.11 |



