
개발자로 후회없는 삶 살기
오픈소스 SW PART.MLops 본문
서론
교과목 9주차 강의 내용을 정리해 보겠습니다.
본론
- MLOps란?
=> DevOps란?
개발과 운영을 같이 해보자 모바일 게임을 보면 운영하면서 계속 수정을 합니다.(개발, 이슈 수정, 운영을 거의 동시에 이루어집니다.)
-> 이런 게 가능한 것이 도구들 덕분입니다.
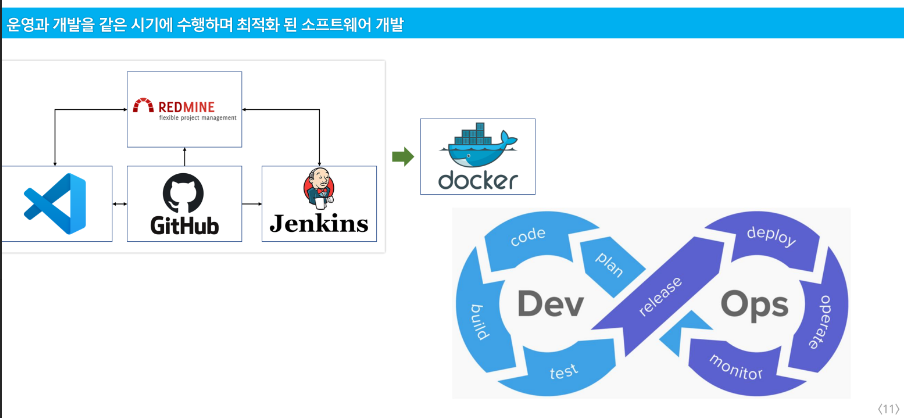
젠킨스의 역할인 통합을 사람이 하니 빌드가 오래 걸렸습니다(휴먼에러 + 수동 타이핑) > 이제는 젠킨스가 모아서 도커로 이미지로 만들어서 배포하니 어느 환경에서든 거의 다 잘 동작합니다. > 이런 것을 '인공지능에 써보자!' 하여, 이를 ML 시스템에 적용한 것이 MLOps입니다.
=> 이것을 ML에 왜 넣을까요?
1. 어떻게 해야 최적화된 ML 알고리즘이 나오는지 손수 하이퍼 파라미터 튜닝에 영향을 많이 받아서 최적화된 모델이 모든 환경에서 100% 적용되지 않습니다.
2. A로 조정한 하이퍼 파라미터는 숫자 5를 잘 보고 B로 조정한 하이퍼 파라미터는 7을 잘 본니다. 엔지니어가 각 숫자를 잘 보는 하이퍼 파라미터 세트를 다 잘 기억할 수 있을까요? 없습니다.
-> 어떤 세트가 우리가 원하는 목적에 가장 적합한 모델인지 버전 관리를 해야합니다.
3. 학습데이터에 따라 결과가 달라집니다.
-> 모델별, 하이퍼 파라미터 별, 데이터 별로 최적화된 모델을 찾고 관리하는 게 어렵습니다. + 일일히 팀원들에게 환경을 맞춰주는 게 힘듭니다.
∴ 이런 하이퍼 파라미터 튜닝을 devops 개념을 적용하여 자동화해보자는 것입니다.
=> MLOps는 ML의 전체 Lifecycle를 관리해야 합니다.
MLOps란 단순히 ML 모델뿐만 아니라, 데이터를 수집하고 분석하는 단계(Data Collection, Ingestion, Analysis, Labeling, Validation, Preparation), 그리고 ML 모델을 학습하고 배포하는 단계(Model Training, Validation, Deployment)까지 전 과정을 AI Lifecycle로 보고, MLOps의 대상으로 보고 있습니다.
ML에 기여하는 Engineer들(Data Scientist, Data Engineer, SW Engineer)이 이 Lifecycle을 관리하고 모니터링해야 합니다.
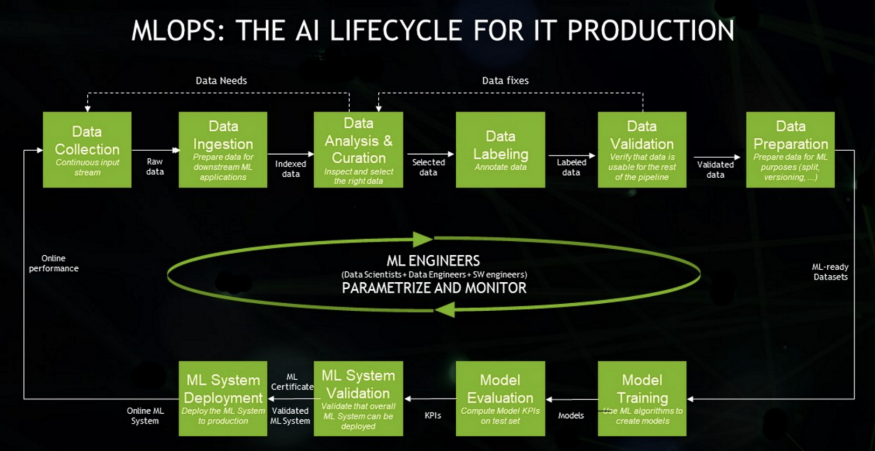
-> 내가 접한 지식으로는 데이터 사이언티스트가 데이터 라벨링, 분석, 검증 등 > 엔지니어가 데이터 수집, 저장 > SW 엔지니어가 ML sys 배포를 할 거라고 예상됩니다.(제 꿈은 밑에 부분인 ML System Deployment 담당자입니다.)
+ MLOps를 통해 수집 data부터 제품까지 high quality의 데이터를 공급할 수 있도록 하는 것입니다. > 즉 모델을 학습하기 위해 수집되는 데이터뿐만 아니라 모델을 사용한 서비스에도 데이터를 주기적으로 공급을 해야 합니다.
- ML 시스템 구성요소
머신러닝 시스템을 프로덕션 환경에 적용하고 운영하기 위해서는 단순히 좋은 머신러닝 모델만으로 가능한 것이 아닙니다. 머신러닝 모델이 ML 시스템의 핵심이기는 하지만, 전체 프로덕션 ML 시스템의 운영을 고려하면 모델 학습 자체는 오히려 작은 부분을 차지한다고 이야기하기도 합니다. 모델을 운영하기 위해 기반 데이터와 인프라를 포함한 모든 시스템이 유기적으로 돌아가야 합니다.
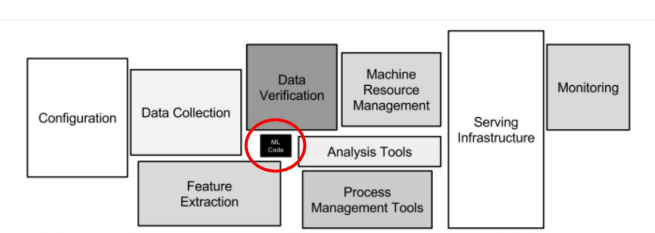
-> 위와 같은 ML 시스템의 운영을 위해 DevOps의 원칙을 적용한 것이 MLOps입니다.
1. 데이터
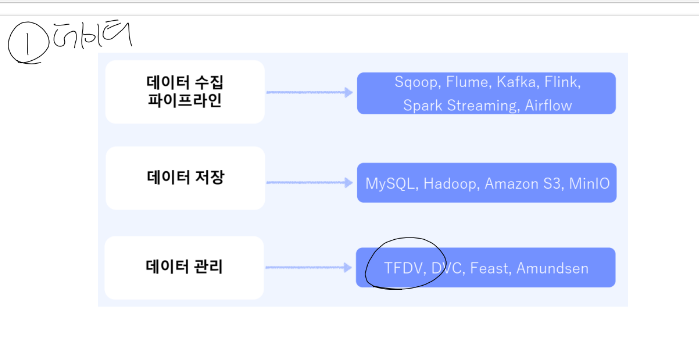
데이터를 어떻게 수집할 것인지, 데이터를 어디에 저장할 것인지(양이 너무 많고 입, 출력 오버헤드가 커서 단순하게 mysql에 안 하고 하둡 같은 클라우드 서비스를 이용)
> 데이터 버전 관리(다 모아진 데이터를 학습하는 경우는 거의 없습니다, 수집되는 과정에서 학습을 하기에 데이터 품질을 꾸준히 관리해야 합니다.) 등이 해당됩니다.
2. 모델 개발
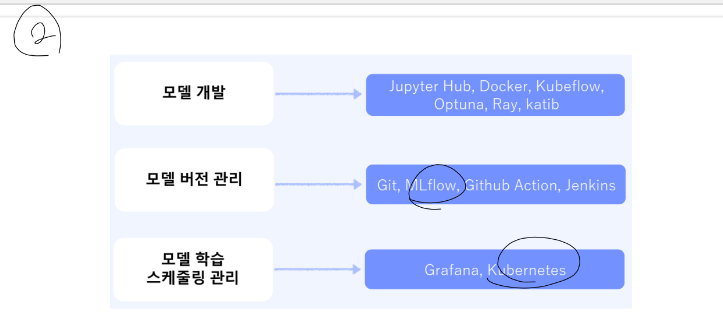
기존 모델을 가져와서 갖다 씁니다. > 모델 버전을 MLflow로 합니다. > 학습 스케쥴링 : 데이터가 크면 한 번에 학습 못 합니다. 그러니 조금씩 돌리고 확인하고 돌리고 확인하는 것을 지속적으로 해야 합니다. + 학습이 12시간 걸리는데 그냥 하염없이 기다릴까요?
> 그냥 쳐다보고 있으면 효율이 떨어지니 끝나면 나에게 알림을 주는 것을 만들 겁니다. + 돌리는 서버가 있어서 학습이 다 끝나면 특정 폴더에 가중치 파일을 생성하게 하고 텔레그램 봇을 만들어서 폴더에 파일이 생성됐나 계속 체크(서버 감시)해서 나에게 알려줍니다 > 이런 게 가장 단순한 MLops 플랫폼입니다.
3. 서빙
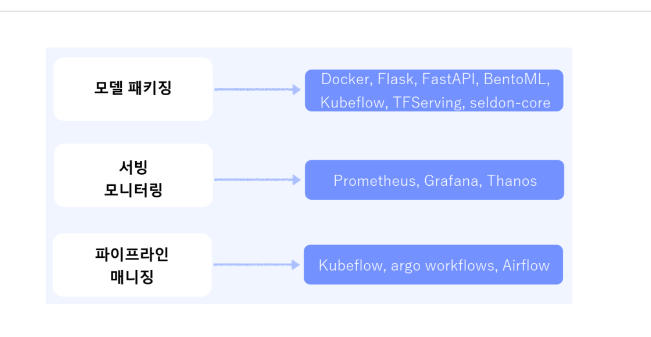
모델을 누군가에게 제공을 해줘야하는데 이때 쿠버플로우, tf서빙, 도커를 씁니다.
- DevOps vs MLOps
일반 SW는 버전 관리 > 테스트 > 모니터링이 중요하여 깃헙, 젠킨스, 레드마인으로 처리했습니다. ML은 일반 SW 개발 방식과 비슷하나 data라는 부분이 큰 영향을 줍니다.
1. Testing
일반적인 단위, 통합 테스트 외에 데이터 검증, 학습된 모델 품질 평가, 모델 검증이 추가로 필요합니다.
2. Deployment
오프라인에서 학습된 ML모델을 배포하는 수준에 그치는 것이 아니라, 새 모델을 재학습하고, 검증하는 과정을 자동화해야 합니다.
3. Production
일반적으로 알고리즘과 로직의 최적화를 통해 최적의 성능을 낼 수 있는 소프트웨어 시스템과 달리, ML 모델은 이에 더해서 지속적으로 진화하는 data profile 자체만으로도 성능이 저하될 수 있습니다.
즉, 기존 소프트웨어 시스템보다 더 다양한 이유로 성능이 손상될 수 있으므로, 데이터의 summary statistics를 꾸준히 추적하고, 모델의 온라인 성능을 모니터링하여 값이 기대치를 벗어나면 알림을 전송하거나 롤백을 할 수 있어야 합니다.
4. CI (Continuous Integration)
CI는 code와 components뿐만 아니라 data, data schema, model에 대해 모두 테스트되고 검증되어야 합니다.
5. CD (Continuous Delivery)
단일 소프트웨어 패키지가 아니라 ML 학습 파이프라인 전체를 배포해야 합니다.
6. CT (Continuous Training)
ML 시스템만의 속성으로, 모델을 자동으로 학습시키고 평가하는 단계입니다.
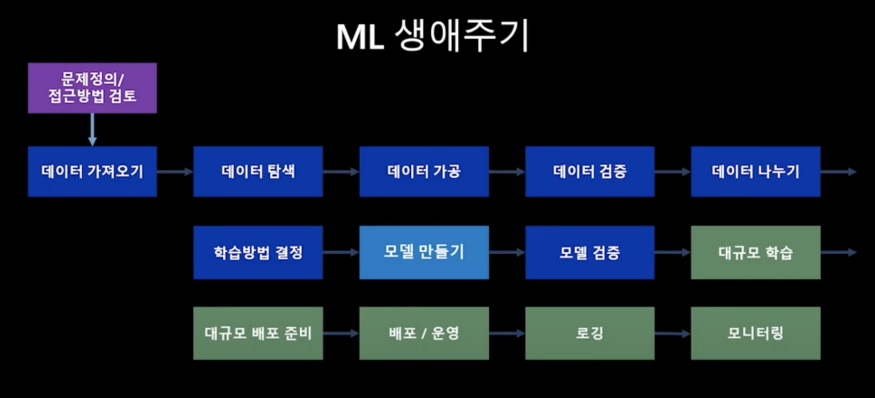
- Data science steps for ML
먼저 business use case와 success criteria들을 정하고 나서 ML 모델을 프로덕션에 배포하기까지, 수동이든 자동이든, 모든 ML 프로젝트에는 다음과 같은 스텝들이 수반됩니다.
1. Data Extraction(데이터 추출) : 데이터 소스에서 관련 데이터 추출
2. Data Analysis(데이터 분석) : 데이터의 이해를 위한 탐사적 데이터 분석(EDA) 수행. 모델에 필요한 데이터 스키마 및 특성 이해
3. Data Preparation(데이터 준비) : 데이터의 학습, 검증, 테스트 세트 분할
4. Model Training(모델 학습) : 다양한 알고리즘 구현, 하이퍼 파라미터 조정 및 적용
5. Model Evaluation(모델 평가) : test set에서 모델을 평가
6. Model Validation(모델 검증) : 기준치 이상의 모델 성능이 검증되고, 배포에 적합한 수준인지 검증
7. Model Serving(모델 서빙) : 온라인 예측을 제공하기 위해 REST API가 포함된 마이크로 서비스
8. Model Monitoring(모델 모니터링) : 모델의 예측 성능을 모니터링
결론
1. 엔터프라이즈 레벨에서 프로덕션 환경에 ML모델을 운영하고자 한다면 MLOps는 선택이 아닌 필수사항이 되어가고 있는 것으로 보입니다.
2. MLops로 최적화된 모델을 도커로 이미지 맞추듯이 저장해서 배포하면 아주 편하겠습니다.
'[개발자] > [교과목]' 카테고리의 다른 글
| 오픈소스 SW PART.도커 심화 (0) | 2022.11.23 |
|---|---|
| 오픈소스 SW PART.MLops mini 프로젝트 설명 및 도입 (0) | 2022.11.09 |
| 오픈소스 SW PART.개발 지원도구 종합 실무 사례 (0) | 2022.10.19 |
| 오픈 소스 SW PART.개발 프로세스, 도커 (0) | 2022.10.12 |
| 오픈 소스 SW PART.CI/CD, 이슈관리 (0) | 2022.10.05 |



